serializovatelný úroveň izolace poskytuje kompletní ochranu z efektů souběžnosti, které mohou ohrozit integritu dat a vést k nesprávným výsledkům dotazů. Použití serializovatelné izolace znamená, že pokud transakce, u které lze prokázat, že přináší správné výsledky bez souběžné aktivity, bude nadále fungovat správně, když bude soutěžit s jakoukoli kombinací souběžných transakcí.
Toto je velmi silná záruka a takový, který pravděpodobně odpovídá intuitivnímu očekávání izolace transakcí mnoha programátorů T-SQL (ačkoli ve skutečnosti relativně málo z nich bude běžně používat serializovatelnou izolaci v produkci).
Standard SQL definuje tři další úrovně izolace, které nabízejí mnohem slabší ACID izolace garantuje než serializovatelná, výměnou za potenciálně vyšší souběžnost a méně potenciálních vedlejších efektů, jako je blokování, zablokování a přerušení doby odevzdání.
Na rozdíl od serializovatelné izolace jsou ostatní úrovně izolace definovány výhradně z hlediska určitých souběžných jevů, které lze pozorovat. Další nejsilnější ze standardních úrovní izolace po serializovatelném se nazývá opakovatelné čtení . Standard SQL specifikuje, že transakce na této úrovni umožňují jediný jev souběžnosti známý jako fantom .
Stejně jako jsme dříve viděli důležité rozdíly mezi běžným intuitivním významem vlastností transakcí ACID a realitou, fantomový fenomén zahrnuje širší škálu chování, než je často uznáváno.
Tento příspěvek v seriálu se zabývá skutečnými zárukami, které poskytuje opakovatelné čtení úroveň izolace a ukazuje některá fantomová chování, se kterými se lze setkat. Pro ilustraci některých bodů se odkážeme na následující jednoduchý příklad dotazu, kde je jednoduchým úkolem spočítat celkový počet řádků v tabulce:
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
Opakovatelné čtení
Jedna zvláštní věc na úrovni izolace opakovatelného čtení je, že není skutečně zaručují, že čtení jsou opakovatelná , alespoň v jednom běžně srozumitelném smyslu. Toto je další příklad, kdy samotný intuitivní význam může být zavádějící. Provedení stejného dotazu dvakrát v rámci stejné opakovatelné transakce čtení může skutečně vrátit různé výsledky.
Navíc implementace opakovatelného čtení na SQL Serveru znamená, že při jediném čtení sady dat může chybět několik řádků to by logicky mělo být zohledněno ve výsledku dotazu. I když je toto chování nepopiratelně specifické pro implementaci, je plně v souladu s definicí opakovatelného čtení obsaženou ve standardu SQL.
Poslední věc, kterou bych chtěl rychle poznamenat, než se ponořím do podrobností, je, že opakovatelné čtení na serveru SQL ne poskytují časový pohled na data.
Neopakovatelné čtení
Opakovatelná úroveň izolace čtení poskytuje záruku, že se data nezmění po dobu trvání transakce po přečtení poprvé.
V této definici je obsaženo několik jemností. Za prvé, umožňuje změnu dat po transakce začne, ale dříve, než jsou data první zpřístupněno. Za druhé, neexistuje žádná záruka, že transakce skutečně narazí na všechna logicky vyhovující data. Brzy uvidíme příklady obou z nich.
Je zde ještě jeden předběžný krok, který musíme rychle uhnout z cesty, který souvisí s příkladem dotazu, který budeme používat. Upřímně řečeno, sémantika tohoto dotazu je trochu nejasná. S rizikem, že to bude znít lehce filozoficky, co to znamená spočítat počet řádků v tabulce? Měl by výsledek odrážet stav tabulky, jaký byl v určitém konkrétním okamžiku? Měl by tento okamžik být začátkem nebo koncem transakce nebo něčím jiným?
To se může zdát trochu náročné, ale otázka je platná v jakékoli databázi, která podporuje souběžné čtení a úpravy dat. Provedení našeho vzorového dotazu může trvat libovolně dlouho (vzhledem k dostatečně velké tabulce nebo například omezení zdrojů), takže souběžné změny jsou nejen možné, ale mohou být nevyhnutelné .
Základním problémem je zde potenciál pro fenomén souběžnosti označovaný jako fantom ve standardu SQL. Zatímco počítáme řádky v tabulce, další souběžná transakce může vložit nové řádky na místě, které jsme již zkontrolovali nebo změnili řádek, který jsme ještě nezkontrolovali tak, aby se přesunul na místo, které jsme si již prohlédli. Lidé si často představují fantomy jako řádky, které se mohou magicky objevit při druhém čtení v samostatném prohlášení, ale účinky mohou být mnohem jemnější.
Příklad souběžného vložení
Tento první příklad ukazuje, jak mohou souběžné vložky vytvořit neopakovatelné číst a/nebo vést k přeskakování řádků. Představte si, že naše testovací tabulka zpočátku obsahuje pět řádků s hodnotami uvedenými níže:

Nyní nastavíme úroveň izolace na opakovatelné čtení, spustíme transakci a spustíme náš dotaz na počítání. Jak byste očekávali, výsledkem je pět . Zatím žádná velká záhada.
Stále probíhá uvnitř stejné opakovatelné čtecí transakce , spustíme dotaz na počítání znovu, ale tentokrát ve chvíli, kdy druhá souběžná transakce vkládá nové řádky do stejné tabulky. Níže uvedený diagram ukazuje sekvenci událostí, přičemž druhá transakce přidává řádky s hodnotami 2 a 6 (možná jste si všimli, že tyto hodnoty byly nápadné tím, že těsně nad nimi chyběly):
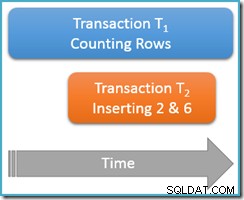
Pokud by náš dotaz na počítání běžel na serializovatelné úroveň izolace by bylo zaručeno napočítat buď pět nebo sedm řádky (viz předchozí článek v této sérii, pokud si potřebujete zopakovat, proč tomu tak je). Jak běží běh na méně izolované opakovatelná úroveň čtení ovlivňuje věci?
No, opakovatelné čtení izolace zaručuje, že při druhém spuštění počítacího dotazu budou vidět všechny dříve přečtené řádky a ty budou ve stejném stavu jako předtím. Háček je v tom, že opakovatelná izolace čtení nic neříká o tom, jak by transakce měla zacházet s novými řádky (s fantomy).
Představte si, že naše transakce počítání řádků (T1 ) má strategii fyzického provádění, kde jsou řádky prohledávány ve vzestupném pořadí indexu. Toto je běžný případ, například když prováděcí stroj používá dopředu uspořádané skenování indexu b-stromu. Nyní, těsně po transakci T1 počítá řádky 1 a 3 ve vzestupném pořadí, transakce T2 se může vplížit dovnitř, vložit nové řádky 2 a 6 a poté potvrdit svou transakci.
Ačkoli v tomto bodě myslíme primárně na logické chování, měl bych zmínit, že v implementaci zamykání opakovatelného čtení SQL Server není nic, co by zabránilo transakce T2 z toho dělat. Sdílené zámky přijaté transakcí T1 na dříve přečtených řádcích zabrání změně těchto řádků, ale nezabrání novým řádkům před vložením do rozsahu hodnot testovaného naším dotazem na počítání (na rozdíl od zámků rozsahu klíčů v zamykání serializovatelné izolace).
Každopádně se dvěma novými řádky transakce T1 pokračuje v hledání ve vzestupném pořadí a nakonec narazí na řádky 4, 5, 6 a 7. Všimněte si, že T1 vidí v tomto scénáři nový řádek 6, ale ne nový řádek 2 (kvůli uspořádanému vyhledávání a jeho pozici, kdy došlo k vložení).
Výsledkem je opakovatelné čtení počítání dotazu hlásí, že tabulka obsahuje šest řádků (hodnoty 1, 3, 4, 5, 6 a 7). Tento výsledek není konzistentní s předchozím výsledkem pěti řádků získané v rámci stejné transakce . Druhé čtení počítalo fiktivní řádek 6, ale minul fiktivní řádek 2. Tolik k intuitivnímu významu opakovatelného čtení!
Příklad souběžné aktualizace
Podobná situace může nastat při souběžné aktualizaci místo vložky. Představte si, že naše testovací tabulka je resetována tak, aby obsahovala stejných pět řádků jako dříve:

Tentokrát spustíme dotaz na počítání pouze jednou při opakovatelném čtení úroveň izolace, zatímco druhá souběžná transakce aktualizuje řádek s hodnotou 5 na hodnotu 2:
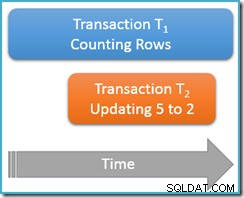
Transakce T1 znovu začne počítat řádky (ve vzestupném pořadí) jako první narazí na řádky 1 a 3. Nyní vklouzne transakce T2, změní hodnotu řádku 5 na 2 a potvrdí:

Aktualizovaný řádek jsem ukázal na stejné pozici jako předtím, aby byla změna jasná, ale index b-stromu, který skenujeme, zachovává data v logickém pořadí, takže skutečný obrázek je blíže tomuto:

Jde o to, že transakce T1 současně skenuje stejnou strukturu v dopředném pořadí a aktuálně je umístěn těsně po záznam pro hodnotu 3. Počítací dotaz pokračuje ve skenování vpřed od tohoto bodu a najde řádky 4 a 7 (ale ne samozřejmě řádek 5).
Abych to shrnul, dotaz na počítání viděl v tomto scénáři řádky 1, 3, 4 a 7. Uvádí počet čtyř řádků – což je zvláštní, protože se zdá, že tabulka obsahovala pět řádků po celou dobu!
Druhé spuštění počítacího dotazu v rámci stejné opakovatelné transakce čtení by hlásilo pět řádků, z podobných důvodů jako dříve. Závěrečná poznámka, pokud vás to zajímá, souběžné mazání neposkytují příležitost pro fantomovou anomálii v izolaci opakovatelného čtení.
Poslední myšlenky
Oba předchozí příklady používaly skenování struktury indexu ve vzestupném pořadí, aby poskytly jednoduchý pohled na druh efektů, které mohou mít fantomy na opakovatelné čtení dotaz. Je důležité pochopit, že tyto ilustrace se žádným důležitým způsobem nespoléhají na směr skenování nebo na skutečnost, že byl použit index b-stromu. Prosím ne vytvořit názor, že objednaná skenování jsou nějakým způsobem zodpovědná, a proto je třeba se jim vyhnout!
Stejné souběžné efekty lze pozorovat při skenování indexové struktury v sestupném pořadí nebo v řadě jiných scénářů fyzického přístupu k datům. Obecným bodem je, že fantomové jevy jsou specificky povoleny (i když nejsou vyžadovány) standardem SQL pro transakce na úrovni izolace opakovatelného čtení.
Ne všechny transakce vyžadují úplnou záruku izolace poskytovanou serializovatelnou izolací a jen málo systémů by mohlo tolerovat vedlejší účinky, pokud by to dělaly. Přesto se vyplatí dobře porozumět tomu, co přesně zaručuje různé úrovně izolace.
Příště
Další část této série se zabývá ještě slabšími zárukami izolace, které nabízí výchozí úroveň izolace SQL Serveru, přečíst .
[ Viz rejstřík pro celou sérii ]