Tento článek se zabývá některými méně známými funkcemi a omezeními optimalizátoru dotazů a vysvětluje důvody extrémně nízkého výkonu spojení hash v konkrétním případě.
Ukázková data
Následující skript pro vytváření ukázkových dat se opírá o existující tabulku čísel. Pokud ještě jeden z nich nemáte, níže uvedený skript lze použít k jeho efektivnímu vytvoření. Výsledná tabulka bude obsahovat jeden celočíselný sloupec s čísly od jednoho do jednoho milionu:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
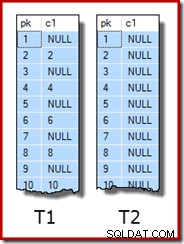
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Samotná vzorová data se skládají ze dvou tabulek, T1 a T2. Oba mají sloupec sekvenčního celočíselného primárního klíče s názvem pk a druhý sloupec s možnou hodnotou Null s názvem c1. Tabulka T1 má 600 000 řádků, kde sudé řádky mají stejnou hodnotu pro c1 jako sloupec pk a liché řádky jsou prázdné. Tabulka c2 má 32 000 řádků, přičemž sloupec c1 má v každém řádku hodnotu NULL. Následující skript vytvoří a naplní tyto tabulky:
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; Prvních deset řádků ukázkových dat v každé tabulce vypadá takto:
Spojení dvou stolů
Tento první test zahrnuje spojení dvou tabulek ve sloupci c1 (nikoli ve sloupci pk) a vrácení hodnoty pk z tabulky T1 pro spojované řádky:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
Dotaz ve skutečnosti nevrátí žádné řádky, protože sloupec c1 má ve všech řádcích tabulky T2 hodnotu NULL, takže žádné řádky nemohou odpovídat predikátu spojení rovnosti. Může to znít jako zvláštní věc, ale jsem si jist, že je to založeno na skutečném produkčním dotazu (velmi zjednodušené pro snadnou diskusi).
Všimněte si, že tento prázdný výsledek nezávisí na nastavení ANSI_NULLS, protože to řídí pouze to, jak jsou zpracovávána srovnání s nulovým literálem nebo proměnnou. U porovnávání sloupců predikát rovnosti vždy odmítá hodnoty null.
Prováděcí plán pro tento jednoduchý spojovací dotaz má některé zajímavé funkce. Nejprve se podíváme na plán před provedením („odhadovaný“) v SQL Sentry Plan Explorer:
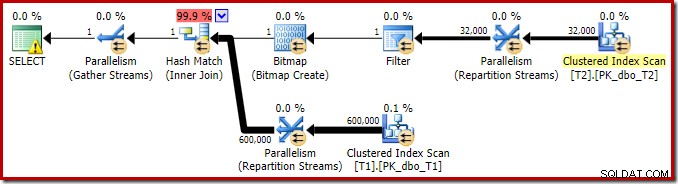
Upozornění na ikoně SELECT si stěžuje na chybějící index v tabulce T1 pro sloupec c1 (s pk jako zahrnutým sloupcem). Návrh indexu je zde irelevantní.
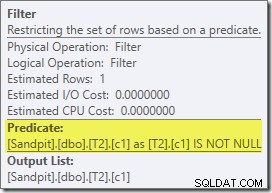
První skutečnou položkou tohoto plánu je Filtr:
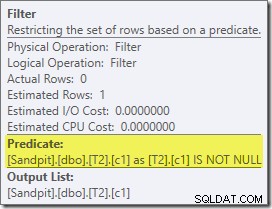
Tento predikát NENÍ NULL se ve zdrojovém dotazu neobjeví, ačkoli je implicitní v predikátu spojení, jak bylo zmíněno dříve. Je zajímavé, že byl rozdělen jako explicitní zvláštní operátor a umístěn před operací spojení. Všimněte si, že i bez filtru by dotaz stále poskytoval správné výsledky – samotné spojení by stále odmítalo nuly.
Filtr je zajímavý i z jiných důvodů. Jeho odhadované náklady jsou přesně nulové (i když se očekává, že bude fungovat na 32 000 řádcích) a nebyl posunut dolů do Clustered Index Scan jako zbytkový predikát. Optimalizátor to obvykle velmi rád dělá.
Obě tyto věci jsou vysvětleny skutečností, že tento filtr je zaveden v přepisu po optimalizaci. Poté, co optimalizátor dotazů dokončí zpracování založené na nákladech, existuje relativně malý počet přepsání pevného plánu, které jsou brány v úvahu. Jeden z nich je zodpovědný za zavedení filtru.
Můžeme vidět výstup výběru plánu založeného na nákladech (před přepsáním) pomocí nezdokumentovaných příznaků trasování 8607 a známého 3604 pro nasměrování textového výstupu do konzole (karta zpráv v SSMS):
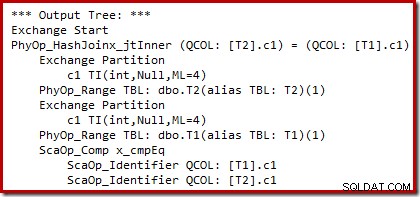
Výstupní strom ukazuje spojení hash, dvě skenování a některé operátory paralelismu (výměny). Ve sloupci c1 tabulky T2 není žádný filtr odmítající hodnotu null.
Konkrétní přepis po optimalizaci se zaměřuje výhradně na vstup sestavení spojení hash. V závislosti na svém posouzení situace může přidat explicitní filtr k odmítnutí řádků, které mají v klíči spojení hodnotu null. Vliv filtru na odhadovaný počet řádků je také zapsán do plánu provádění, ale protože optimalizace založená na nákladech je již dokončena, náklady na filtr se nepočítají. V případě, že to není zřejmé, jsou výpočetní náklady ztrátou úsilí, pokud již byla učiněna všechna rozhodnutí založená na nákladech.
Filtr zůstává přímo na vstupu sestavení, místo aby byl posunut dolů do Clustered Index Scan, protože hlavní optimalizační aktivita byla dokončena. Přepisy po optimalizaci jsou v podstatě vylepšeními dokončeného plánu realizace na poslední chvíli.
Druhý a zcela samostatný přepis po optimalizaci je zodpovědný za bitmapový operátor v konečném plánu (možná jste si všimli, že také chyběl ve výstupu 8607):
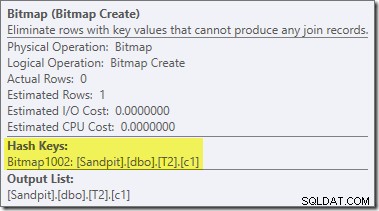
Tento operátor má také nulové odhadované náklady na I/O i CPU. Další věc, která jej identifikuje jako operátora zavedeného pozdním vylepšením (spíše než během optimalizace založené na nákladech), je to, že jeho název je Bitmap následovaný číslem. Během optimalizace založené na nákladech byly představeny další typy bitmap, jak uvidíme o něco později.
Pro tuto chvíli je důležité, že tato bitmapa zaznamenává hodnoty c1 viděné během fáze sestavení spojení hash. Dokončená bitmapa je posunuta na stranu sondy spojení, když hash přechází z fáze sestavení do fáze sondy. Bitmapa se používá k provedení časné redukce semi-spojení, čímž se ze strany sondy vyloučí řádky, které se nemohou spojit. pokud o tom potřebujete více podrobností, přečtěte si můj předchozí článek na toto téma.
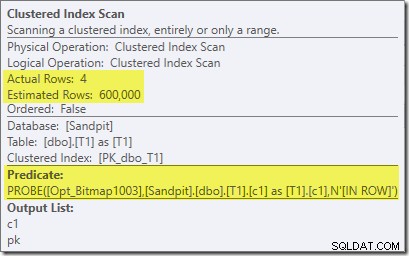
Druhý efekt bitmapy lze vidět na skenování clusteru indexu na straně sondy:
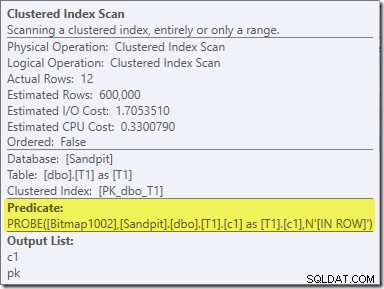
Snímek obrazovky výše ukazuje dokončenou bitmapu, která se kontroluje jako součást Clustered Index Scan na tabulce T1. Vzhledem k tomu, že zdrojový sloupec je celé číslo (fungovalo by i velké číslo), je bitmapová kontrola vložena celou cestu do úložiště (jak je indikováno kvalifikátorem 'INROW'), místo aby byla kontrolována procesorem dotazu. Obecněji lze bitmapu použít na libovolného operátora na straně sondy, od výměny dolů. Jak daleko může procesor dotazů posunout bitmapu, závisí na typu sloupce a verzi serveru SQL.
Abychom dokončili analýzu hlavních rysů tohoto prováděcího plánu, musíme se podívat na plán po provedení ('skutečný'):
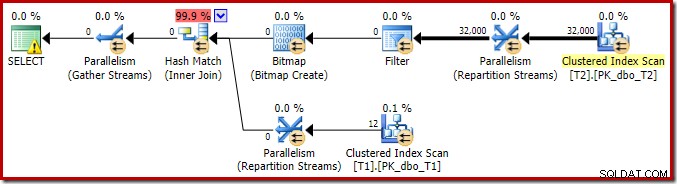
První věc, které je třeba si všimnout, je rozložení řádků mezi vlákny mezi skenováním T2 a výměnou toků přerozdělení bezprostředně nad ním. Při jednom testovacím běhu jsem na systému se čtyřmi logickými procesory viděl následující distribuci:
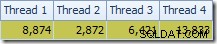
Distribuce není nijak zvlášť rovnoměrná, jak je tomu často v případě paralelního skenování na relativně malém počtu řádků, ale alespoň všechna vlákna dostala nějakou práci. Distribuce vláken mezi stejnou výměnou toků přerozdělení a filtrem je velmi odlišná:
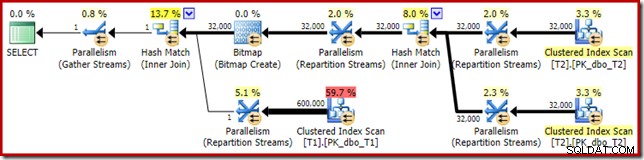
To ukazuje, že všech 32 000 řádků z tabulky T2 bylo zpracováno jedním vláknem. Abychom zjistili proč, musíme se podívat na vlastnosti výměny:

Tato výměna, stejně jako ta na testovací straně spojení hash, musí zajistit, aby řádky se stejnými hodnotami klíče spojení skončily ve stejné instanci spojení hash. Na DOP 4 jsou čtyři hashovací spojení, z nichž každý má svou vlastní hashovací tabulku. Pro správné výsledky musí řádky na straně sestavení a řádky na straně sondy se stejnými klíči spojení dospět ke stejnému spojení hash; jinak bychom mohli zkontrolovat řádek na straně sondy proti nesprávné hashovací tabulce.
V paralelním plánu v režimu řádků toho SQL Server dosáhne přerozdělením obou vstupů pomocí stejné hashovací funkce ve sloupcích spojení. V tomto případě je spojení ve sloupci c1, takže vstupy jsou distribuovány mezi vlákna aplikací hashovací funkce (typ rozdělení:hash) na sloupec klíče spojení (c1). Problém je v tom, že sloupec c1 obsahuje pouze jednu hodnotu – null – v tabulce T2, takže všem 32 000 řádkům je přiřazena stejná hodnota hash, takže všechny skončí ve stejném vláknu.
Dobrou zprávou je, že nic z toho pro tento dotaz opravdu nezáleží. Filtr přepisu po optimalizaci eliminuje všechny řádky dříve, než je vykonáno velké množství práce. Na mém notebooku se výše uvedený dotaz provede (neprodukuje žádné výsledky, jak se očekávalo) přibližně za 70 ms .
Spojení tří stolů
Pro druhý test přidáme další spojení z tabulky T2 k sobě na primární klíč:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
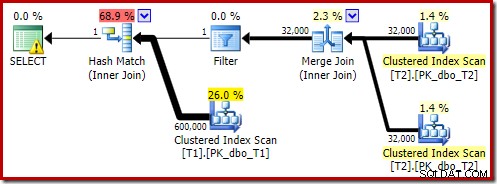
Tím se nezmění logické výsledky dotazu, ale změní se plán provádění:
Jak se očekávalo, vlastní spojení tabulky T2 v jejím primárním klíči nemá žádný vliv na počet řádků, které se kvalifikují z této tabulky:
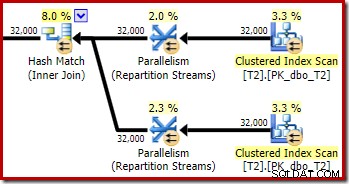
Rozložení řádků napříč vlákny je v této části plánu také dobré. U prověřování je to podobné jako dříve, protože paralelní prohledávání rozděluje řádky do vláken na vyžádání. Přerozdělení výměn na základě hash klíče spojení, což je tentokrát sloupec pk. Vzhledem k rozsahu různých hodnot pk je výsledné rozdělení vláken také velmi rovnoměrné:
Když přejdeme k zajímavější části odhadovaného plánu, existují určité rozdíly oproti testu se dvěma tabulkami:

Výměna na straně sestavení opět skončí směrováním všech řádků do stejného vlákna, protože c1 je klíč spojení, a tedy i rozdělovací sloupec pro výměny toků rozdělení (nezapomeňte, že c1 je null pro všechny řádky v tabulce T2).
V této části plánu jsou ve srovnání s předchozím testem další dva důležité rozdíly. Za prvé, neexistuje žádný filtr, který by odstranil řádky null-c1 ze strany sestavení spojení hash. Vysvětlení toho je spojeno s druhým rozdílem – bitmapa se změnila, i když to z obrázku výše není zřejmé:
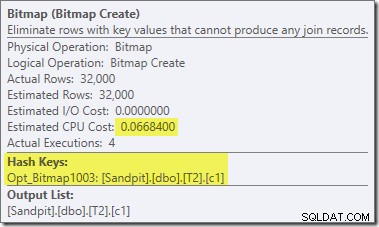
Toto je Opt_Bitmap, nikoli Bitmap. Rozdíl je v tom, že tato bitmapa byla zavedena během optimalizace založené na nákladech, nikoli přepsáním na poslední chvíli. Mechanismus, který bere v úvahu optimalizované bitmapy, je spojen se zpracováním dotazů typu star-join. Logika hvězdicového spojení vyžaduje alespoň tři spojené tabulky, takže to vysvětluje, proč optimalizované bitmapa nebyla uvažována v příkladu spojení dvou tabulek.
Tato optimalizovaná bitmapa má nenulové odhadované náklady na CPU a přímo ovlivňuje celkový plán zvolený optimalizátorem. Jeho vliv na odhad mohutnosti na straně sondy lze vidět u operátora Repartition Streams:
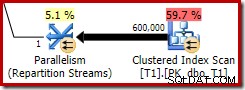
Všimněte si, že efekt mohutnosti je vidět na výměně, i když je bitmapa nakonec zatlačena úplně dolů do úložiště ('INROW'), jak jsme viděli v prvním testu (ale všimněte si nyní reference Opt_Bitmap):
Plán po provedení ('skutečný') je následující:
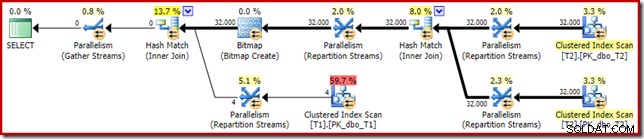
Předpokládaná účinnost optimalizované bitmapy znamená, že se nepoužije samostatné přepisování po optimalizaci pro nulový filtr. Osobně si myslím, že je to nešťastné, protože brzké odstranění nul pomocí filtru by negovalo potřebu sestavit bitmapu, naplnit hašovací tabulky a provést skenování tabulky T1 vylepšené bitmapou. Optimalizátor však rozhodne jinak a v tomto případě se s ním prostě nelze dohadovat.
Navzdory zvláštnímu samostatnému spojení tabulky T2 a práci navíc spojenou s chybějícím filtrem tento plán provádění stále poskytuje očekávaný výsledek (žádné řádky) v rychlém čase. Typické spuštění na mém notebooku trvá přibližně 200 ms .
Změna typu dat
U tohoto třetího testu změníme datový typ sloupce c1 v obou tabulkách z celého čísla na desítkový. Na této volbě není nic zvláštního; stejný efekt lze pozorovat u libovolného číselného typu, který není celočíselný ani velký.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
Opětovné použití dotazu spojení se třemi spojeními:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
Odhadovaný plán provádění vypadá velmi povědomě:
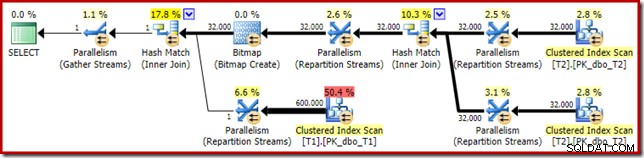
Kromě toho, že optimalizovanou bitmapu již nelze použít 'INROW' storage enginem kvůli změně datového typu, je plán provádění v podstatě identický. Snímek níže ukazuje změnu vlastností skenování:
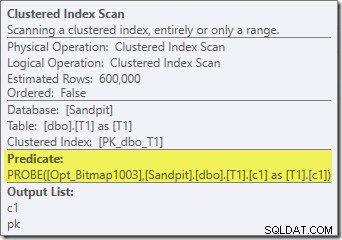
Výkon je bohužel značně ovlivněn. Tento dotaz se nespustí za 70 ms nebo 200 ms, ale přibližně za 20 minut . V testu, který vytvořil následující plán po provedení, byla doba běhu ve skutečnosti 22 minut a 29 sekund:

Nejviditelnější rozdíl je v tom, že Clustered Index Scan v tabulce T1 vrátí 300 000 řádků i po použití optimalizovaného bitmapového filtru. To dává určitý smysl, protože bitmapa je postavena na řádcích, které ve sloupci c1 obsahují pouze hodnoty null. Bitmapa odebere nenulové řádky ze skenování T1 a ponechá pouze 300 000 řádků s hodnotami null pro c1. Pamatujte, že polovina řádků v T1 je nulová.
I tak se zdá divné, že spojení 32 000 řádků s 300 000 řádky by mělo trvat více než 20 minut. V případě, že by vás to zajímalo, jedno jádro CPU bylo fixováno na 100 % po celou dobu provádění. Vysvětlení tohoto slabého výkonu a extrémního využití zdrojů staví na některých nápadech, které jsme prozkoumali dříve:
Už například víme, že i přes ikonky paralelního spouštění končí všechny řádky z T2 na stejném vláknu. Připomínáme, že paralelní spojení hash v režimu řádků vyžaduje přerozdělení na spojovacích sloupcích (c1). Všechny řádky z T2 mají stejnou hodnotu – null – ve sloupci c1, takže všechny řádky skončí na stejném vláknu. Podobně všechny řádky z T1, které projdou bitmapovým filtrem, mají také hodnotu null ve sloupci c1, takže se také přerozdělí do stejného vlákna. To vysvětluje, proč veškerou práci dělá jediné jádro.
Stále se může zdát nerozumné, že hašovací spojení 32 000 řádků s 300 000 řádky by mělo trvat 20 minut, zejména proto, že spojovací sloupce na obou stranách jsou prázdné a stejně se nespojí. Abychom to pochopili, musíme se zamyslet nad tím, jak toto spojení hash funguje.
Vstup sestavení (32 000 řádků) vytvoří hašovací tabulku pomocí sloupce spojení c1. Protože každý řádek na straně sestavení obsahuje stejnou hodnotu (null) pro spojovací sloupec c1, znamená to, že všech 32 000 řádků skončí ve stejném segmentu hash. Když se spojení hash přepne na hledání shod, každý řádek na straně sondy s nulovým sloupcem c1 také hashuje do stejného segmentu. Hašovací spojení pak musí zkontrolovat shodu všech 32 000 záznamů v daném segmentu.
Kontrola 300 000 řádků sondy má za následek 32 000 porovnání provedených 300 000krát. Toto je nejhorší případ pro spojení hash:Všechny postranní řádky sestavení hashují do stejného segmentu, což má za následek to, co je v podstatě kartézský produkt. To vysvětluje dlouhou dobu provádění a konstantní 100% využití procesoru, protože hash následuje dlouhý řetězec segmentu hash.
Tento slabý výkon pomáhá vysvětlit, proč existuje přepis po optimalizaci za účelem odstranění nulových hodnot na vstupu sestavení do spojení hash. Je nešťastné, že v tomto případě nebyl použit filtr.
Řešení
Optimalizátor zvolí tento tvar plánu, protože nesprávně odhadne, že optimalizovaná bitmapa odfiltruje všechny řádky z tabulky T1. I když je tento odhad zobrazen v přerozdělovacích tocích namísto skenování sdružených indexů, toto je stále základem rozhodnutí. Pro připomenutí je zde opět příslušná část předexekučního plánu:
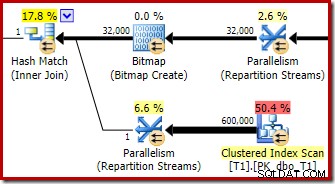
Pokud by se jednalo o správný odhad, zpracování spojení hash by nezabralo vůbec žádný čas. Je nešťastné, že odhad selektivity pro optimalizovanou bitmapu je tak velmi špatný, když datový typ není jednoduché celé číslo nebo bigint. Zdá se, že bitmapa postavená na celočíselném nebo bigintovém klíči je také schopna odfiltrovat prázdné řádky, které se nemohou spojit. Pokud tomu tak skutečně je, je to hlavní důvod, proč preferovat celočíselné nebo bigintové sloupce.
Řešení, která následují, jsou z velké části založena na myšlence odstranění problematických optimalizovaných bitmap.
Sériové spuštění
Jedním ze způsobů, jak zabránit zvažování optimalizovaných bitmap, je vyžadovat neparalelní plán. Bitmapové operátory v režimu řádků (optimalizované nebo jiné) jsou vidět pouze v paralelních plánech:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); Tento dotaz je vyjádřen pomocí mírně odlišné syntaxe s nápovědou FORCE ORDER pro generování tvaru plánu, který je snadněji srovnatelný s předchozími paralelními plány. Základní funkcí je nápověda MAXDOP 1.
Tento odhadovaný plán ukazuje obnovení filtru přepisu po optimalizaci:
Verze plánu po provedení ukazuje, že odfiltruje všechny řádky ze vstupu sestavení, což znamená, že boční skenování sondy lze úplně přeskočit:
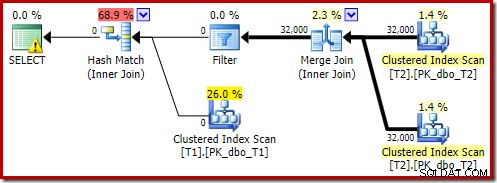
Jak byste očekávali, tato verze dotazu se provádí velmi rychle – pro mě průměrně asi 20 ms. Podobného efektu můžeme dosáhnout bez nápovědy FORCE ORDER a přepsání dotazu:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
Optimalizátor v tomto případě zvolí jiný tvar půdorysu s filtrem umístěným přímo nad skenem T2:
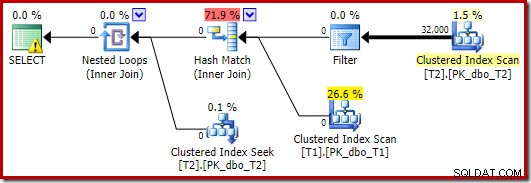
To se provádí ještě rychleji – asi za 10 ms – jak by se dalo očekávat. Přirozeně by to nebyla dobrá volba, pokud by počet přítomných (a spojitelných) řádků byl mnohem větší.
Vypnutí optimalizovaných bitmap
Neexistuje žádný náznak dotazu na vypnutí optimalizovaných bitmap, ale stejného efektu můžeme dosáhnout pomocí několika nezdokumentovaných příznaků trasování. Jako vždy se jedná pouze o úrokovou hodnotu; nikdy byste je nechtěli používat ve skutečném systému nebo aplikaci:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);
Výsledný plán provádění je:
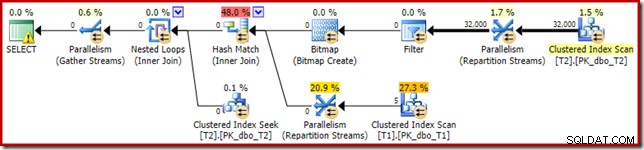
Bitmapa je bitmapa pro přepsání po optimalizaci, nikoli optimalizovaná bitmapa:
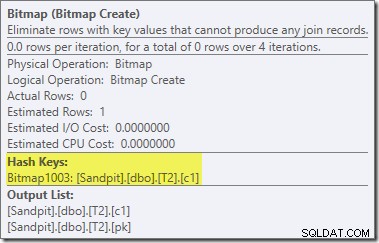
Všimněte si nulových odhadů nákladů a názvu bitmapy (spíše než Opt_Bitmap). bez optimalizované bitmapy, která by zkreslila odhady nákladů, se aktivuje přepis po optimalizaci tak, aby zahrnoval nulový filtr. Tento plán provádění se spustí přibližně za 70 ms .
Stejný plán provádění (s filtrem a neoptimalizovanou bitmapou) lze také vytvořit deaktivací pravidla optimalizátoru odpovědného za generování bitmapových plánů hvězdicového spojení (opět přísně nezdokumentované a ne pro použití v reálném světě):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
Včetně explicitního filtru
Toto je nejjednodušší možnost, ale člověk by si to myslel, jen pokud by si byl vědom problémů, o kterých se dosud hovořilo. Nyní, když víme, že potřebujeme odstranit hodnoty null z T2.c1, můžeme to přidat přímo do dotazu:
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
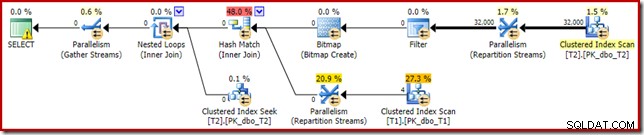
T2.c1 IS NOT NULL; -- New! Výsledný odhadovaný plán provedení možná není úplně takový, jaký byste mohli očekávat:
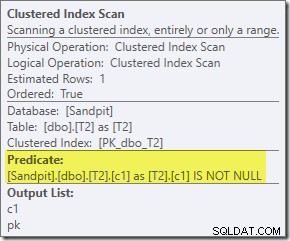
Extra predikát, který jsme přidali, byl vložen do prostředního Clustered Index Scan T2:
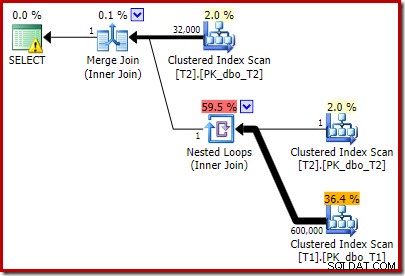
Plán po provedení je:
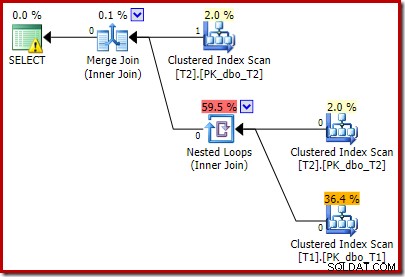
Všimněte si, že spojení Merge Join se vypne po přečtení jednoho řádku z horního vstupu a poté, co se nepodařilo najít řádek na spodním vstupu, kvůli účinku predikátu, který jsme přidali. Clustered Index Scan tabulky T1 se nikdy vůbec neprovede, protože spojení Nested Loops nikdy nezíská řádek na svém řídicím vstupu. Tento závěrečný formulář dotazu se provede za jednu nebo dvě milisekundy.
Poslední myšlenky
Tento článek pokrývá značnou část půdy, aby prozkoumal některá méně známá chování optimalizátoru dotazů a vysvětlil důvody extrémně nízkého výkonu spojení hash v konkrétním případě.
Mohlo by být lákavé zeptat se, proč optimalizátor před spojením rovnosti rutinně nepřidává filtry odmítající hodnotu null. Lze se jen domnívat, že by to v dostatečně běžných případech nebylo přínosné. U většiny spojení se neočekává mnoho odmítnutí null =null a rutinní přidávání predikátů by se mohlo rychle stát kontraproduktivním, zvláště pokud je přítomno mnoho sloupců spojení. U většiny spojení je odmítnutí nul v operátoru spojení pravděpodobně lepší volbou (z hlediska nákladového modelu) než zavádění explicitního filtru.
Zdá se, že existuje snaha zabránit tomu, aby se projevily ty nejhorší případy prostřednictvím přepisu po optimalizaci navrženého k odmítnutí řádků s nulovým spojením, než dosáhnou vstupu sestavení spojení hash. Zdá se, že mezi účinkem optimalizovaných bitmapových filtrů a aplikací tohoto přepisu existuje nešťastná interakce. Je také nešťastné, že když se tento problém s výkonem vyskytne, je velmi obtížné jej diagnostikovat pouze z plánu provádění.
V tuto chvíli se zdá být nejlepší možností si uvědomit tento potenciální problém s výkonem se spojeními hash ve sloupcích s možnou hodnotou Null a přidat explicitní predikáty odmítající hodnotu null (s komentářem!), aby se v případě potřeby zajistil účinný plán provádění. Použití nápovědy MAXDOP 1 může také odhalit alternativní plán s přítomným kontrolním filtrem.
Obecným pravidlem je, že dotazy, které se spojují ve sloupcích typu celočíselné a hledají existující data, obvykle lépe odpovídají možnostem optimalizačního modelu a prováděcího jádra než alternativám.
Poděkování
Chci poděkovat SQL_Sasquatchovi (@sqL_handLe) za jeho svolení reagovat na jeho původní článek technickou analýzou. Zde použitá ukázková data jsou silně založena na tomto článku.
Chci také poděkovat Robu Farleymu (blog | twitter) za naše technické diskuse v průběhu let, a zejména za tu v lednu 2015, kde jsme diskutovali o důsledcích extra nulových predikátů pro ekvi-spojení. Rob psal o souvisejících tématech několikrát, včetně inverzních predikátů – než přejdete, podívejte se na obě strany.