Příspěvek od Dana Holmese, který bloguje na sql.dnhlms.com.
SQL Server Books Online (BOL), whitepapery a mnoho dalších zdrojů vám ukáže, jak a proč budete chtít aktualizovat statistiky v tabulce nebo indexu. Získáte však pouze jeden způsob, jak tyto hodnoty utvářet. Ukážu vám, jak můžete vytvořit statistiky přesně tak, jak chcete, v rámci 200 dostupných kroků.
Odmítnutí odpovědnosti :To mi vyhovuje, protože znám svou aplikaci, databázi a běžné pracovní postupy a vzorce používání aplikací svým uživatelem. Používá však nezdokumentované příkazy a při nesprávném použití může výrazně zhoršit výkon vaší aplikace.V naší aplikaci uživatel Plánování pravidelně čte a zapisuje data, která představují události pro zítřek a několik příštích dní. Plánovač nepoužívá data za dnešek a dříve. První věc ráno, datový soubor pro zítřek začíná na několika stovkách řádků a v poledne může být 1400 a více. Následující graf ilustruje počty řádků. Tato data byla shromážděna ráno ve středu 18. listopadu 2015. Historicky můžete vidět, že běžný počet řádků je přibližně 1 400 s výjimkou víkendových dnů a dalšího dne.
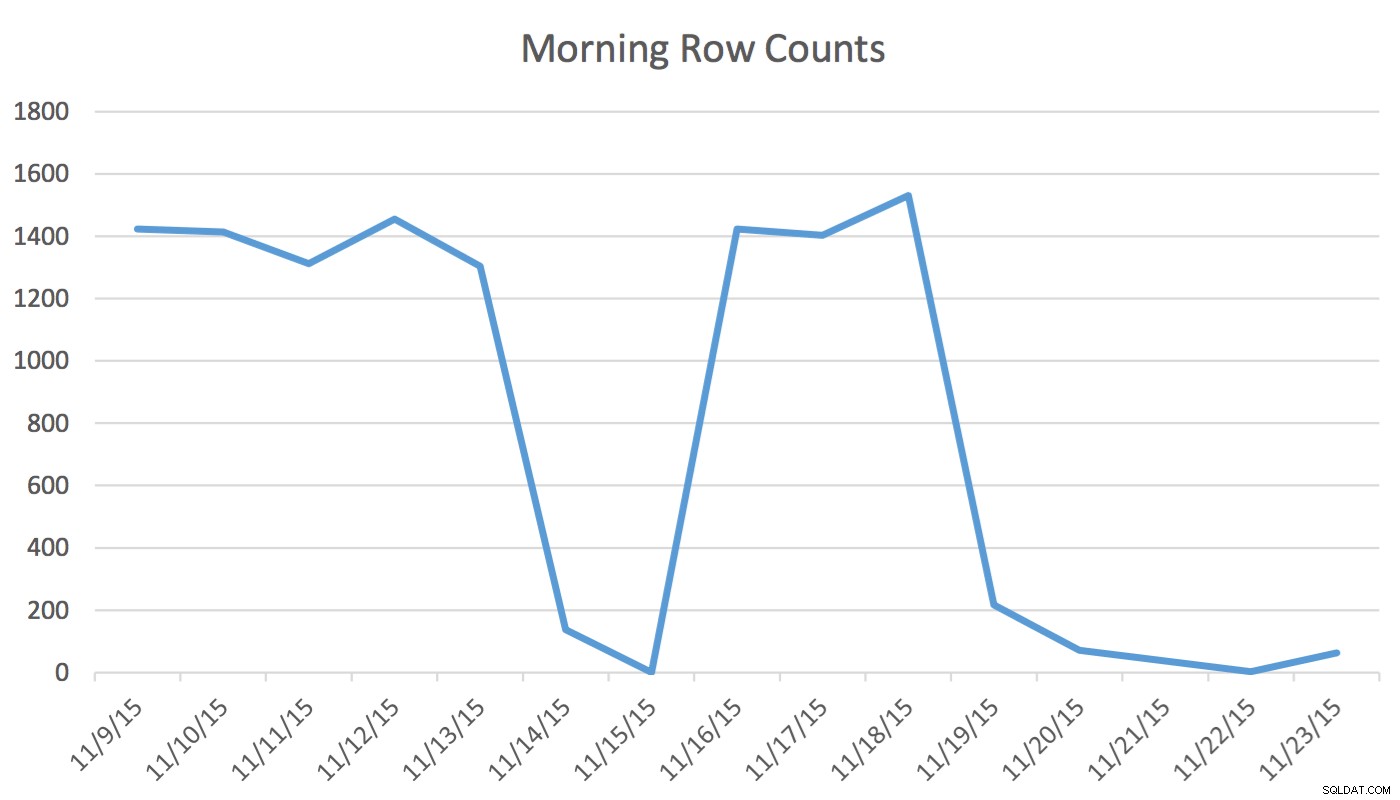
Pro Plánovač jsou jedinými relevantními údaji několik příštích dní. Co se děje dnes a co se stalo včera, není pro jeho činnost relevantní. Jak to tedy způsobuje problém? Tato tabulka má 2 259 205 řádků, což znamená, že změna počtu řádků od rána do poledne nebude stačit ke spuštění aktualizace statistik iniciované SQL Serverem. Navíc ručně naplánovaná úloha, která vytváří statistiky pomocí UPDATE STATISTICS vyplní histogram vzorkem všech dat v tabulce, ale nemusí obsahovat relevantní informace. Tato delta počtu řádků stačí ke změně plánu. Bez aktualizace statistik a přesného histogramu se však plán se změnou dat nezmění k lepšímu.
Relevantní výběr histogramu pro tuto tabulku ze zálohy datované 4. 11. 2015 může vypadat takto:
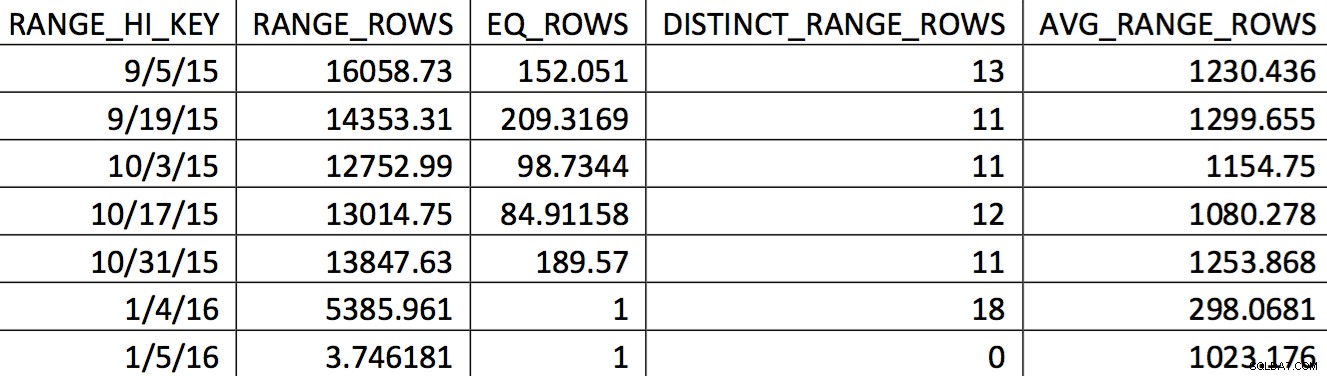
Požadované hodnoty se v histogramu neodrážejí přesně. To, co by bylo použito pro datum 5. 11. 2015, by byla vysoká hodnota 4. 1. 2016. Na základě grafu tento histogram zjevně není dobrým zdrojem informací pro optimalizátor k datu zájmu. Vynucení hodnot použití do histogramu není spolehlivé, jak to tedy můžete udělat? Můj první pokus byl opakovaně používat WITH SAMPLE možnost UPDATE STATISTICS a dotazujte se na histogram, dokud v histogramu nebudou hodnoty, které jsem potřeboval (snaha je podrobně popsána zde). Nakonec se tento přístup ukázal jako nespolehlivý.
Tento histogram může vést k plánu s tímto typem chování. Podcenění řádků způsobí spojení Nested Loop a hledání indexu. Hodnoty jsou následně vyšší, než by měly být kvůli této volbě plánu. To bude mít také vliv na trvání výpisu.
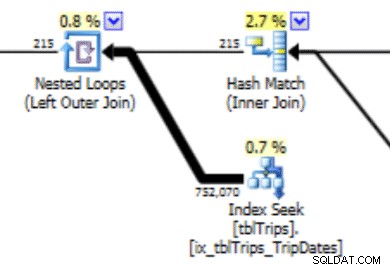
Mnohem lepší by bylo vytvořit data přesně tak, jak je chcete, a zde je návod, jak to udělat.
Existuje nepodporovaná možnost UPDATE STATISTICS :STATS_STREAM . Toto používá podpora zákazníků společnosti Microsoft k exportu a importu statistik, aby mohli znovu vytvořit optimalizátor, aniž by měli všechna data v tabulce. Tuto funkci můžeme použít. Cílem je vytvořit tabulku, která napodobuje DDL statistiky, kterou chceme přizpůsobit. Příslušné údaje jsou přidány do tabulky. Statistiky se exportují a importují do původní tabulky.
V tomto případě se jedná o tabulku s 200 řádky s daty, která nejsou NULL, a 1 řádek, který obsahuje hodnoty NULL. Navíc je v této tabulce index, který odpovídá indexu, který má špatné hodnoty histogramu.
Název tabulky je tblTripsScheduled . Má neshlukovaný index na (id, TheTripDate) a seskupený index na TheTripDate . Existuje několik dalších sloupců, ale důležité jsou pouze ty, které jsou součástí indexu.
Vytvořte tabulku (pokud chcete dočasnou tabulku), která napodobuje tabulku a index. Tabulka a index vypadají takto:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate);
Dále je potřeba naplnit tabulku 200 řádky dat, na kterých by měla být statistika založena. V mé situaci je to den, který trvá příštích šedesát dní. Minulost a více než 60 dní je vyplněno „náhodným“ výběrem každých 10 dní. (cnt hodnota v CTE je hodnota ladění. V konečných výsledcích to nehraje roli.) Sestupné pořadí pro rn sloupec zajišťuje, že bude zahrnuto 60 dní a poté co nejvíce z minulosti.
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
Naše tabulka je nyní naplněna každým řádkem, který je pro dnešního uživatele cenný, a výběrem historických řádků. Pokud je sloupec TheTripdate bylo možné nulovat, vložka by také obsahovala následující:
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
Dále aktualizujeme statistiky indexu naší dočasné tabulky.
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
Nyní exportujte tyto statistiky do dočasné tabulky. Ta tabulka vypadá takto. Odpovídá výstupu DBCC SHOW_STATISTICS WITH HISTOGRAM .
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS má možnost exportovat statistiky jako stream. To je ten proud, který chceme. Tento stream je také stejný jako UPDATE STATISTICS využívá možnost streamu. Chcete-li to provést:
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); Posledním krokem je vytvoření SQL, který aktualizuje statistiky naší cílové tabulky, a poté jej spustit.
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); V tuto chvíli jsme histogram nahradili naším vlastním. Můžete to ověřit kontrolou histogramu:
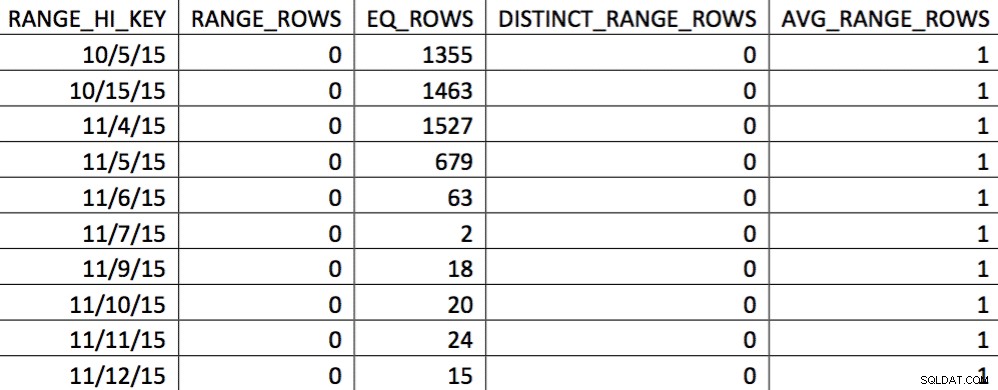
V tomto výběru dat 4. 11. jsou zastoupeny všechny dny od 4. 11. a historická data jsou reprezentována a přesná. Když se znovu podíváte na část plánu dotazů uvedenou dříve, můžete vidět, že optimalizátor udělal lepší volbu na základě opravených statistik:
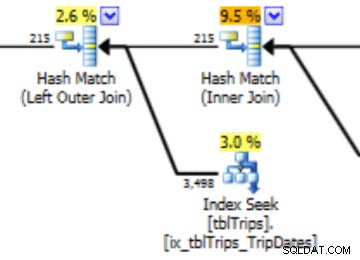
Importované statistiky přináší výhodu výkonu. Náklady na výpočet statistik jsou v „offline“ tabulce. Jediným výpadkem produkční tabulky je trvání importu streamu.
Tento proces používá nezdokumentované funkce a zdá se, že by mohl být nebezpečný, ale pamatujte, že je snadné vrátit zpět:prohlášení o aktualizaci statistik. Pokud se něco pokazí, statistiky lze vždy aktualizovat pomocí standardního T-SQL.
Naplánování pravidelného spouštění tohoto kódu může výrazně pomoci optimalizátoru vytvořit lepší plány vzhledem k datové sadě, která se v průběhu bodu zlomu mění, ale nestačí ke spuštění aktualizace statistik.
Když jsem dokončil první návrh tohoto článku, počet řádků v tabulce v prvním grafu se změnil z 217 na 717. To je 300% změna. To stačí ke změně chování optimalizátoru, ale nestačí to ke spuštění aktualizace statistik. Tato změna dat by zanechala špatný plán. Tento problém je vyřešen zde popsaným postupem.
Reference:
- AKTUALIZOVAT STATISTIKY (Knihy online)
- Statistika SQL 2008 Whitepaper
- Hledání bodu zlomu