Minulý rok jsem představil řešení pro simulaci čitelných sekundárních stránek Availability Group bez investice do Enterprise Edition. Abychom lidem zabránili v nákupu Enterprise Edition, protože existuje spousta výhod mimo AG, ale spíše pro ty, kteří nemají šanci mít Enterprise Edition na prvním místě:
- Sekundární články čitelné s rozpočtem
Snažím se být neúnavným zastáncem zákazníka Standard Edition; je to skoro vtip, že – vzhledem k počtu funkcí, které má v každém novém vydání – je tato edice jako celek na cestě k ukončení podpory. Na soukromých schůzkách se společností Microsoft jsem prosazoval, aby byly funkce zahrnuty také do Standard Edition, zejména s funkcemi, které jsou mnohem výhodnější pro malé podniky než ty s neomezeným rozpočtem na hardware.
Zákazníci edice Enterprise využívají výhod správy a výkonu, které nabízí dělení tabulek, ale tato funkce není k dispozici ve verzi Standard. Nedávno mě napadla myšlenka, že existuje způsob, jak dosáhnout alespoň některých výhod dělení na libovolné edici, a nezahrnuje to rozdělené pohledy. To neznamená, že rozdělené pohledy nejsou životaschopnou možností, která stojí za zvážení; tyto dobře popsali jiní, včetně Daniela Hutmachera (Rozdělené pohledy na rozdělení tabulek) a Kimberly Tripp (Rozdělené tabulky v. Rozdělené pohledy – Proč jsou vůbec stále k dispozici?). Můj nápad je jen trochu jednodušší na provedení.
Váš nový hrdina:Filtrované indexy
Vím, že tato funkce je pro některé čtyřpísmenné slovo; než půjdete dál, měli byste být spokojeni s filtrovanými indexy nebo si alespoň vědomi jejich omezení. Trochu čtení, abych vám poskytl slušnou rovnováhu, než se vám je pokusím prodat:
- Hovořím o několika nedostatcích v části Jak by filtrované indexy mohly být výkonnější funkcí a poukazuji na spoustu položek Connect, pro které můžete hlasovat;
- Paul White (@SQL_Kiwi) hovoří o problémech s laděním v Omezení optimalizátoru s filtrovanými indexy a také v Neočekávaném vedlejším účinku přidání filtrovaného indexu; a,
- Jes Borland (@grrl_geek) nám říká, co můžete (a co nemůžete) dělat s filtrovanými indexy.
Přečíst všechny? A ty jsi ještě tady? Skvělé.
TL;DR toho spočívá v tom, že můžete použít filtrované indexy, abyste udrželi všechna svá „horká data“ v samostatné fyzické struktuře a dokonce i na samostatném základním hardwaru (můžete mít k dispozici rychlý disk SSD nebo PCIe, ale nemůže t držet celý stůl).
Rychlý příklad
Existuje mnoho případů použití, kdy je část dat dotazována mnohem častěji než zbytek – vzpomeňte si na maloobchodní prodejnu spravující objednávky, pekařství plánující dodávky svatebních dortů nebo fotbalový stadion, který měří návštěvnost a údaje o koncesích. V těchto případech se většina nebo veškerá každodenní aktivita dotazů týká „aktuálních“ dat.
Nechme to jednoduché; vytvoříme databázi s velmi úzkou tabulkou Objednávky:
CREATE DATABASE PoorManPartition;GO USE PoorManPartition;GO CREATE TABLE dbo.Orders( OrderID INT IDENTITY(1,1) PRIMÁRNÍ KLÍČ, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8,2) --, . .další sloupce...);
Nyní řekněme, že máte na svém rychlém úložišti dostatek místa, abyste si uchovali měsíc dat (se spoustou volného prostoru pro zohlednění sezónnosti a budoucího růstu). Můžeme přidat novou skupinu souborů a umístit datový soubor na rychlý disk.
ALTER DATABASE PoorManPartition PŘIDAT FILEGROUP HotData;PŘEJÍT ZMĚNIT DATABÁZI PoorManPartition PŘIDAT SOUBOR ( Název =N'HotData', Název souboru =N'Z:\folder\HotData.mdf', Velikost =100 MB, Růst souboru =25 MB HotDataFID) TO
Nyní vytvoříme filtrovaný index v naší skupině souborů HotData, kde filtr zahrnuje vše od začátku listopadu 2015 a běžné sloupce zahrnuté v dotazech založených na čase jsou v seznamu klíčů nebo zahrnutí:
VYTVOŘIT INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE (OrderTotal) WHERE OrderDate>='20151101' AND OrderDate <'20151201' ON HotData;
Můžeme vložit několik řádků a zkontrolovat plán provádění, abychom se ujistili, že zahrnuté dotazy mohou ve skutečnosti používat index:
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');GO SELECT index_id, řádky FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders); /* Výsledky:řádky index_id -------- ---- 1 3 2 2*/ SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151102' AND OrderDate <'20151106';
Výsledný plán provádění samozřejmě používá filtrovaný index (i když predikát filtru v dotazu přesně neodpovídá definici indexu):
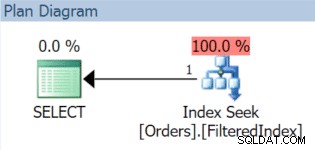
Nyní se blíží 1. prosinec a je čas vyměnit naše listopadová data a nahradit je prosincovými. Můžeme jednoduše znovu vytvořit filtrovaný index s novým predikátem filtru a použít DROP_EXISTING možnost:
VYTVOŘIT INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE (OrderTotal) WHERE OrderDate>='20151201' AND OrderDate <'20160101' S (DROP_EXISTING =ON) ON HotData;
Nyní můžeme přidat několik dalších řádků, zkontrolovat statistiky oddílu a spustit náš předchozí dotaz a nový, abychom zkontrolovali použité indexy:
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');GO SELECT index_id, řádky FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders'); /* Výsledky:řádky index_id -------- ---- 1 5 2 2*/ SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151102' AND OrderDate <'20151106'; SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151202' AND OrderDate <'20151204';
V tomto případě získáme skenování clusteru indexu pomocí listopadového dotazu:
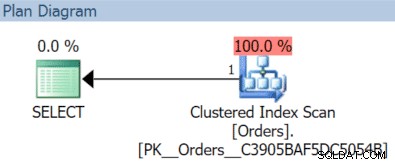
(To by ale bylo jiné, kdybychom měli samostatný, nefiltrovaný index s klíčem OrderDate.)
A znovu to neukážu, ale s prosincovým dotazem dostaneme stejný filtrovaný index hledání jako předtím.
Můžete také udržovat více indexů, jeden pro aktuální měsíc, jeden pro předchozí měsíc atd., a můžete je spravovat samostatně (1. prosince prostě index z října vypustíte a necháte například listopadový) . Můžete také udržovat více indexů kratších nebo delších časových úseků (aktuální a předchozí týden, aktuální a předchozí čtvrtletí) atd. Řešení je poměrně flexibilní.
Vzhledem k omezením filtrovaných indexů se to nebudu snažit prosadit jako dokonalé řešení, ani úplnou náhradu za rozdělení tabulek nebo rozdělené pohledy. Vypnutí oddílu je například operace metadat, zatímco znovu vytvoříte index pomocí DROP_EXISTING může mít mnoho protokolování (a protože nejste na Enterprise Edition, nelze jej spustit online). Můžete také zjistit, že dělené pohledy jsou rychlejší – je zde více práce s udržováním samostatných fyzických tabulek a omezení, která dělený pohled umožňují, ale přínos z hlediska výkonu dotazů může být v některých případech lepší.
Automatizace
Akt opětovného vytvoření indexu lze zautomatizovat poměrně snadno pomocí jednoduché úlohy, která jednou za měsíc udělá něco takového (nebo jaká je velikost vašeho "horkého" okna):
DECLARE @sql NVARCHAR(MAX), @dt DATUM =DATEADD(DEN, 1-DEN(GETDATE()), GETDATE()); SET @sql =N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE (OrderTotal) WHERE OrderDate>=''' + CONVERT(CHAR(8), @dt, 112) + N''' WITH (DROP_EXISTING =ON ) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
Můžete také vytvářet více indexů měsíce předem, podobně jako vytváření budoucích oddílů předem – budoucí indexy koneckonců nezaberou žádné místo, dokud nebudou k dispozici data relevantní pro jejich predikáty. A můžete jednoduše vypustit indexy, které segmentovaly starší data, která nyní chcete zchladit.
Pohled zpět
Po dokončení tohoto článku jsem samozřejmě narazil na další příspěvek Kimberly Tripp, který byste si měli přečíst, než budete pokračovat v čemkoli, co zde obhajuji (a které jsem četl, než jsem začal):
- Co takhle filtrované indexy místo dělení?
Z mnoha důvodů je Kimberly mnohem více nakloněna rozděleným pohledům, aby implementovala něco podobného jako rozdělení ve Standard Edition; nicméně pro určité scénáře mě použití filtrovaných indexů stále fascinuje natolik, abych v experimentování pokračoval. Jednou z oblastí, kde mohou být filtrované indexy přínosné, je, když vaše „horká“ data mají více kritérií – nejen rozdělená podle data, ale také podle dalších atributů (možná budete chtít rychlé dotazy na všechny objednávky z tohoto měsíce, které jsou pro určitou úroveň zákazníka nebo nad určitou částku v dolarech).
Další…
V budoucím příspěvku si s tímto konceptem pohraju na systému vyšší třídy s určitým objemem a pracovní zátěží v reálném světě. Chci zjistit výkonnostní rozdíly mezi tímto řešením, nefiltrovaným krycím indexem, rozděleným pohledem a rozdělenou tabulkou. Uvnitř virtuálního počítače na notebooku s dostupnými pouze SSD by pravděpodobně nebyly realistické nebo spravedlivé testy v měřítku.