AKTUALIZACE:2. září 2021 (Původně publikováno 26. července 2012.)
V průběhu několika hlavních verzí naší oblíbené databázové platformy se mnoho věcí změní. SQL Server 2016 nám přinesl STRING_SPLIT, nativní funkci, která eliminuje potřebu mnoha vlastních řešení, která jsme dříve potřebovali. Je to také rychlé, ale není to dokonalé. Například podporuje pouze jednoznakový oddělovač a nevrací nic, co by udávalo pořadí vstupních prvků. Od napsání tohoto příspěvku jsem napsal několik článků o této funkci (a STRING_AGG, které dorazilo na SQL Server 2017):
- Překvapení a předpoklady výkonu:STRING_SPLIT()
- STRING_SPLIT() v SQL Server 2016:Následná akce č. 1
- STRING_SPLIT() v SQL Server 2016:Následná akce č. 2
- Kód SQL Server pro nahrazení rozděleného řetězce kódem STRING_SPLIT
- Porovnání metod dělení / zřetězení řetězců
- Vyřešte staré problémy pomocí nových funkcí STRING_AGG a STRING_SPLIT SQL Serveru
- Zacházení s jednoznakovým oddělovačem ve funkci STRING_SPLIT serveru SQL Server
- Pomozte prosím s vylepšeními STRING_SPLIT
- Způsob, jak zlepšit STRING_SPLIT v SQL Server – a vy můžete pomoci
Níže uvedený obsah zde ponechám pro budoucí generace a pro historickou relevanci a také proto, že některé z metodologií testování jsou relevantní pro jiné problémy kromě dělení řetězců, ale podívejte se prosím na některé z výše uvedených odkazů, kde najdete informace o tom, jak byste měli rozdělovat strings v moderních podporovaných verzích SQL Server – stejně jako tento příspěvek, který vysvětluje, proč rozdělení řetězců možná není problém, který chcete, aby databáze vyřešila na prvním místě, ať už jde o novou funkci nebo ne.
- Rozdělení řetězců:Nyní s méně T-SQL
Vím, že mnoho lidí je znuděno problémem „rozdělených řetězců“, ale stále se zdá, že se objevuje téměř denně na fóru a na stránkách Q &A, jako je Stack Overflow. Toto je problém, kdy lidé chtějí předat řetězec, jako je tento:
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
Uvnitř procedury chtějí udělat něco takového:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); Toto nefunguje, protože @FavoriteTeams je jeden řetězec a výše uvedené znamená:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); SQL Server se proto pokusí najít tým s názvem Patriots,Red Sox,Bruins , a předpokládám, že žádný takový tým neexistuje. To, co zde skutečně chtějí, je ekvivalent:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); Ale protože SQL Server nemá žádný typ pole, takto se proměnná vůbec neinterpretuje – stále je to jednoduchý, jediný řetězec, který náhodou obsahuje nějaké čárky. Pomineme-li sporný návrh schématu, v tomto případě je třeba seznam oddělený čárkami „rozdělit“ na jednotlivé hodnoty – a to je otázka, která často podnítí spoustu „nových“ debat a komentářů o nejlepším řešení, jak toho dosáhnout.
Zdá se, že odpověď téměř vždy zní, že byste měli používat CLR. Pokud nemůžete používat CLR – a vím, že je mezi vámi mnoho, kteří to neumí, kvůli firemní politice, špičatému šéfovi nebo tvrdohlavosti – pak použijete jedno z mnoha možných řešení. A existuje mnoho náhradních řešení.
Který byste ale měli použít?
Porovnám výkon několika řešení – a zaměřím se na otázku, kterou si každý vždy klade:„Které je nejrychlejší?“ Nebudu rozebírat diskuzi o *všech* potenciálních metodách, protože několik již bylo eliminováno kvůli skutečnosti, že se jednoduše neškálují. A možná to v budoucnu znovu navštívím, abych prozkoumal dopad na jiné metriky, ale nyní se zaměřím pouze na trvání. Zde jsou uchazeči, které hodlám porovnat (s použitím SQL Server 2012, 11.00.2316, na virtuálním počítači Windows 7 se 4 CPU a 8 GB RAM):
CLR
Pokud chcete používat CLR, rozhodně byste si měli vypůjčit kód od kolegy MVP Adama Machanice, než začnete přemýšlet o napsání vlastního (o znovuvynalézání kola jsem psal již dříve a týká se to i bezplatných úryvků kódu, jako je tento). Strávil spoustu času dolaďováním této funkce CLR, aby efektivně analyzoval řetězec. Pokud v současné době používáte funkci CLR a není to ona, důrazně doporučuji ji nasadit a porovnat – testoval jsem ji proti mnohem jednodušší rutině CLR založené na VB, která byla funkčně ekvivalentní, ale přístup VB fungoval asi třikrát hůře než Adamův.
Vzal jsem tedy Adamovu funkci, zkompiloval kód do DLL (pomocí csc) a nasadil právě tento soubor na server. Poté jsem do své databáze přidal následující sestavení a funkci:
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
Toto je typická funkce, kterou používám pro jednorázové scénáře, kde vím, že vstup je „bezpečný“, ale nedoporučuji ji pro produkční prostředí (více o tom níže).
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO Spolu s přístupem XML musí jít o velmi silné upozornění:lze jej použít pouze tehdy, pokud můžete zaručit, že váš vstupní řetězec neobsahuje žádné nelegální znaky XML. Jedno jméno s <,> nebo &a funkce vybuchne. Takže bez ohledu na výkon, pokud se chystáte použít tento přístup, uvědomte si omezení – nemělo by být považováno za životaschopnou možnost pro obecný rozdělovač řetězců. Zahrnuji to do tohoto shrnutí, protože můžete mít případ, kdy můžete důvěřovat vstupu – lze jej například použít pro seznamy celých čísel nebo GUID oddělených čárkami.
Tabulka čísel
Toto řešení používá tabulku Numbers, kterou si musíte sestavit a naplnit sami. (Vestavěnou verzi požadujeme už věky.) Tabulka Čísla by měla obsahovat dostatek řádků, aby přesáhla délku nejdelšího řetězce, který budete rozdělovat. V tomto případě použijeme 1 000 000 řádků:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (Použití komprese dat drasticky sníží počet požadovaných stránek, ale samozřejmě byste tuto možnost měli používat pouze v případě, že používáte Enterprise Edition. V tomto případě komprimovaná data vyžadují 1 360 stránek oproti 2 102 stránkám bez komprese – úspora asi 35 %. )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
Běžný tabulkový výraz
Toto řešení využívá rekurzivní CTE k extrakci každé části řetězce ze „zbytku“ předchozí části. Jako rekurzivní CTE s lokálními proměnnými si všimnete, že se muselo jednat o vícepříkazovou funkci s tabulkovou hodnotou, na rozdíl od ostatních, které jsou všechny inline.
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO
Rozbočovač Jeffa Modena Funkce založená na splitteru Jeffa Modena s drobnými změnami pro podporu delších strun
Na SQLServerCentral představil Jeff Moden funkci rozdělovače, která konkurovala výkonu CLR, takže jsem si myslel, že je spravedlivé zahrnout do tohoto shrnutí variaci využívající podobný přístup. Musel jsem provést několik menších změn v jeho funkci, abych zvládl náš nejdelší řetězec (500 000 znaků), a také konvence pojmenování byly podobné:
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; Kromě toho pro ty, kteří používají řešení Jeffa Modena, můžete zvážit použití tabulky čísel, jak je uvedeno výše, a experimentování s mírnou variací Jeffovy funkce:
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (Tím se vymění mírně vyšší hodnoty za mírně nižší CPU, takže může být lepší v závislosti na tom, zda je váš systém již vázán na CPU nebo I/O.)
Kontrola zdravého rozumu
Abychom se ujistili, že jsme na správné cestě, můžeme ověřit, že všech pět funkcí vrací očekávané výsledky:
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
A ve skutečnosti jsou to výsledky, které vidíme ve všech pěti případech…

Testovací data
Nyní, když víme, že se funkce chovají podle očekávání, můžeme přejít k zábavnější části:testování výkonu na různém počtu řetězců, které se liší délkou. Ale nejdřív potřebujeme stůl. Vytvořil jsem následující jednoduchý objekt:
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
Tuto tabulku jsem naplnil sadou řetězců různých délek, přičemž jsem se ujistil, že pro každý test bude použita zhruba stejná sada dat – nejprve 10 000 řádků, kde je řetězec dlouhý 50 znaků, potom 1 000 řádků, kde má řetězec 500 znaků. , 100 řádků, kde je řetězec dlouhý 5 000 znaků, 10 řádků, kde je řetězec dlouhý 50 000 znaků, a tak dále až do 1 řádku o délce 500 000 znaků. Udělal jsem to proto, abych porovnal stejné množství celkových dat zpracovávaných funkcemi, a také proto, abych se pokusil udržet časy testování poněkud předvídatelné.
Používám #temp tabulku, abych mohl jednoduše použít GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
Vytvoření a naplnění této tabulky trvalo na mém počítači asi 20 sekund a tabulka představuje přibližně 6 MB dat (asi 500 000 znaků krát 2 bajty, neboli 1 MB na typ_řetězce plus režii řádku a indexu). Není to velká tabulka, ale měla by být dostatečně velká, aby zvýraznila rozdíly ve výkonu mezi funkcemi.
Testy
S funkcemi na svém místě a se stolem řádně nacpaným velkými řetězci, které lze žvýkat, můžeme konečně provést několik skutečných testů, abychom viděli, jak si různé funkce vedou se skutečnými daty. Abych změřil výkon bez zohlednění režie sítě, použil jsem SQL Sentry Plan Explorer, každou sadu testů jsem spustil 10krát, shromáždil metriky trvání a vytvořil průměr.
První test jednoduše vytáhl položky z každého řetězce jako sadu:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
Výsledky ukazují, že jak se struny zvětšují, výhoda CLR skutečně září. Na spodním konci byly výsledky smíšené, ale opět by měla mít metoda XML vedle sebe hvězdičku, protože její použití závisí na použití bezpečného vstupu XML. Pro tento konkrétní případ použití měla tabulka Numbers trvale nejhorší výsledky:
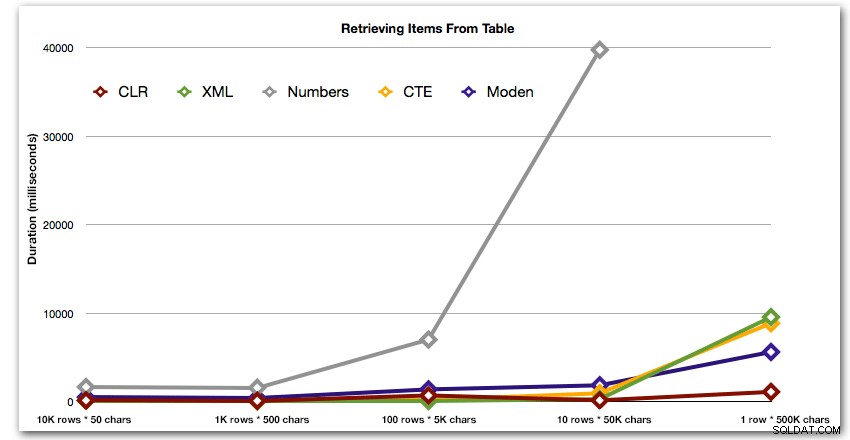
Trvání v milisekundách
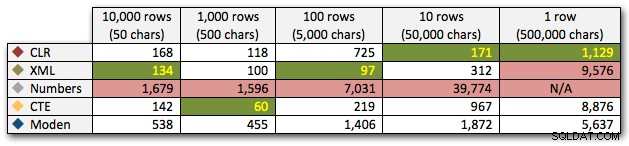
Po hyperbolickém 40sekundovém výkonu pro tabulku čísel proti 10 řádkům po 50 000 znacích jsem ji vypustil z běhu na poslední test. Abych lépe ukázal relativní výkon čtyř nejlepších metod v tomto testu, úplně jsem z grafu vypustil výsledky Numbers:
Dále porovnejme, kdy provádíme vyhledávání podle hodnoty oddělené čárkami (např. vrátíme řádky, kde je jeden z řetězců 'foo'). Opět použijeme pět výše uvedených funkcí, ale také porovnáme výsledek s vyhledáváním provedeným za běhu pomocí LIKE, místo abychom se obtěžovali rozdělováním.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
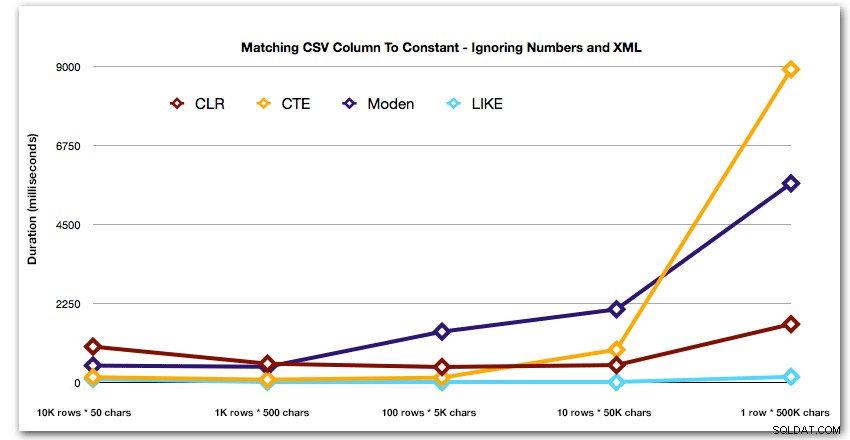
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; Tyto výsledky ukazují, že pro malé řetězce bylo CLR ve skutečnosti nejpomalejší a že nejlepším řešením bude provedení skenování pomocí LIKE, aniž by se vůbec obtěžovalo rozdělovat data. Znovu jsem vypustil řešení tabulky Numbers z 5. přístupu, když bylo jasné, že jeho trvání se bude exponenciálně prodlužovat, jak se bude zvětšovat velikost řetězce:
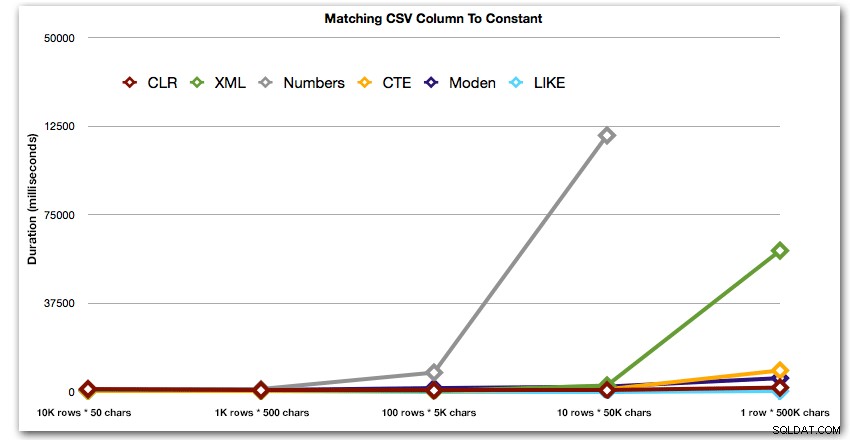
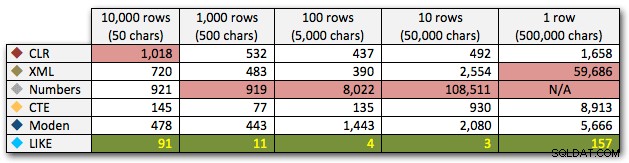
Trvání v milisekundách
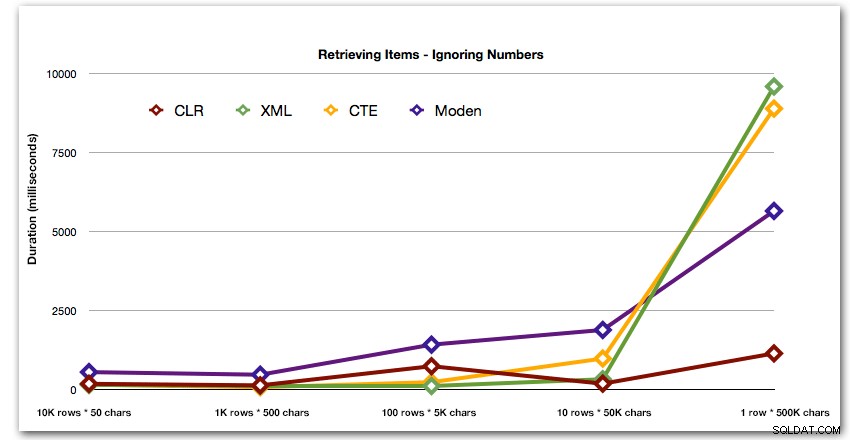
A abych lépe demonstroval vzory pro první 4 výsledky, odstranil jsem z grafu řešení Numbers a XML:
Dále se podívejme na replikaci případu použití ze začátku tohoto příspěvku, kde se snažíme najít všechny řádky v jedné tabulce, které existují v předávaném seznamu. Stejně jako u dat v tabulce, kterou jsme vytvořili výše, 'bude vytvářet řetězce různé délky od 50 do 500 000 znaků, uložit je do proměnné a poté zkontrolovat, zda v seznamu neexistuje běžné zobrazení katalogu.
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
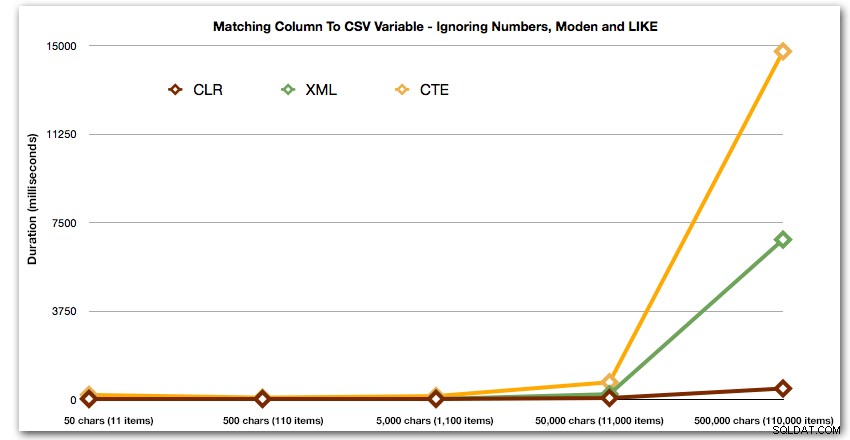
ORDER BY [object_id]; Tyto výsledky ukazují, že u tohoto vzoru několik metod exponenciálně prodlužuje dobu trvání, jak se zvětšuje velikost řetězce. Na spodním konci XML drží dobré tempo s CLR, ale to se také rychle zhoršuje. CLR je zde trvale jasným vítězem:
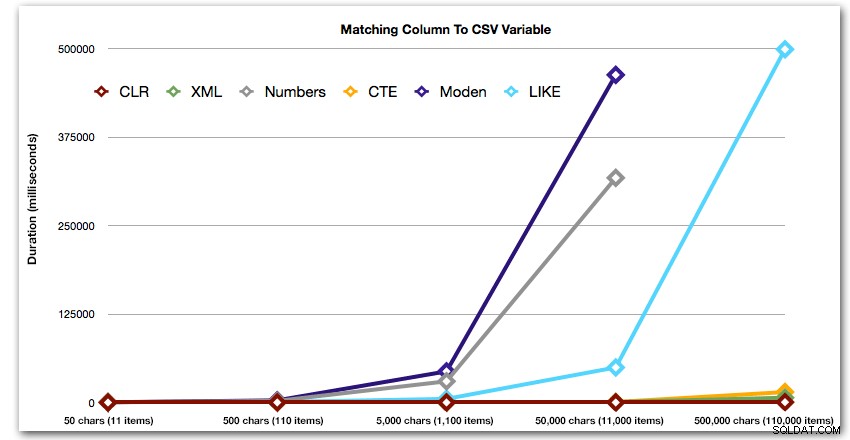
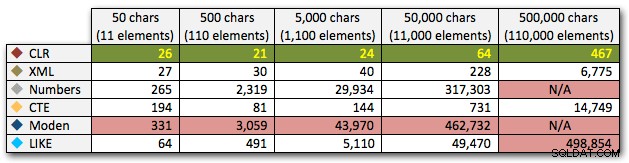
Trvání v milisekundách
A opět bez metod, které explodují z hlediska trvání:
Nakonec porovnejme náklady na získávání dat z jedné proměnné různé délky, přičemž ignorujeme náklady na čtení dat z tabulky. Opět vygenerujeme řetězce různé délky, od 50 do 500 000 znaků, a pak vrátíme hodnoty jako sadu:
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
Tyto výsledky také ukazují, že CLR je z hlediska délky trvání poměrně vyrovnaný, a to až do 110 000 položek v sadě, zatímco ostatní metody si udrží slušné tempo až nějakou dobu po 11 000 položkách:
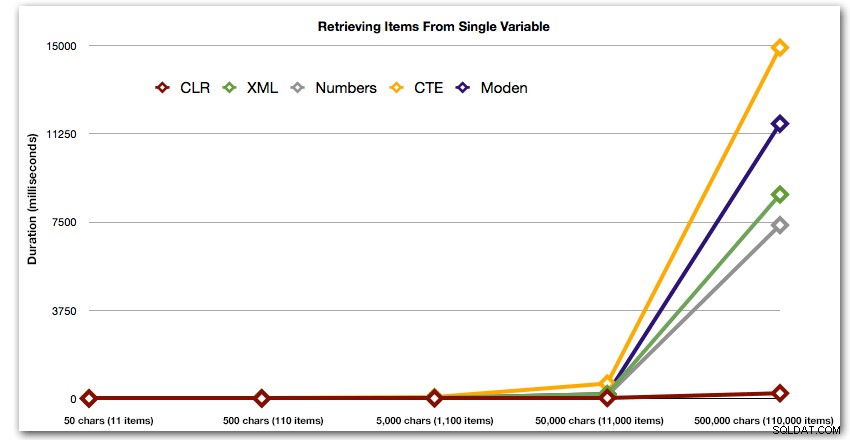
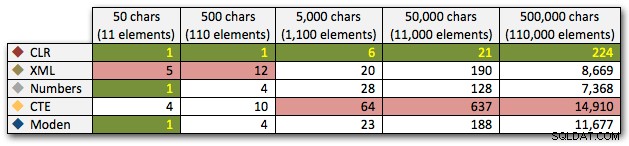
Trvání v milisekundách
Závěr
Téměř ve všech případech řešení CLR jasně předčí ostatní přístupy – v některých případech jde o drtivé vítězství, zvláště když se zvětší velikost strun; v několika dalších je to fotografická úprava, která může spadnout jakkoli. V prvním testu jsme viděli, že XML a CTE překonaly CLR na nižší úrovni, takže pokud se jedná o typický případ použití *a* jste si jisti, že vaše řetězce jsou v rozsahu 1 – 10 000 znaků, jeden z těchto přístupů by mohl být lepší variantou. Pokud jsou vaše velikosti řetězců méně předvídatelné, CLR je pravděpodobně stále vaší nejlepší sázkou celkově – ztratíte několik milisekund na spodním konci, ale získáte hodně na horním konci. Zde jsou možnosti, které bych udělal v závislosti na úkolu, přičemž druhé místo je zvýrazněno pro případy, kdy CLR není možností. Všimněte si, že XML je mou preferovanou metodou, pouze pokud vím, že vstup je bezpečný pro XML; tyto nemusí být nutně vaše nejlepší alternativy, pokud méně důvěřujete svému příspěvku.
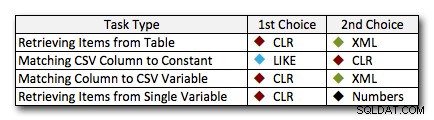
Jedinou skutečnou výjimkou, kdy CLR není mou volbou, je případ, kdy ve skutečnosti ukládáte seznamy oddělené čárkami do tabulky a pak hledáte řádky, kde je v tomto seznamu definovaná entita. V tomto konkrétním případě bych pravděpodobně nejprve doporučil přepracovat a řádně normalizovat schéma, aby se tyto hodnoty ukládaly odděleně, spíše než to používat jako výmluvu, proč k rozdělení nepoužívat CLR.
Pokud nemůžete použít CLR z jiných důvodů, neexistuje jednoznačné „druhé místo“ odhalené těmito testy; mé odpovědi výše byly založeny na celkovém měřítku a ne na konkrétní velikosti řetězce. Každé řešení zde bylo na druhém místě alespoň v jednom scénáři – takže zatímco CLR je jednoznačně volbou, kdy jej můžete použít, to, co byste měli použít, když nemůžete, je spíše odpověď „záleží“ – budete muset posoudit na základě vaše případy použití a výše uvedené testy (nebo vytvořením vlastních testů), která alternativa je pro vás lepší.
Dodatek :Alternativa k rozdělení na prvním místě
Výše uvedené přístupy nevyžadují žádné změny ve vaší stávající aplikaci (aplikacích), za předpokladu, že již sestavují řetězec oddělený čárkami a vhazují jej do databáze, aby se s ním vypořádali. Jednou z možností, kterou byste měli zvážit, pokud buď CLR není možností a/nebo můžete upravit aplikaci (aplikace), je použití tabulkových parametrů (TVP). Zde je rychlý příklad, jak využít TVP ve výše uvedeném kontextu. Nejprve vytvořte typ tabulky s jedním sloupcem řetězce:
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
Potom může uložená procedura vzít tento TVP jako vstup a připojit se k obsahu (nebo jej použít jiným způsobem – toto je jen jeden příklad):
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO Nyní ve svém kódu C#, například namísto vytváření řetězce odděleného čárkami, naplňte DataTable (nebo použijte jakoukoli kompatibilní kolekci, která již obsahuje vaši sadu hodnot):
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} Můžete to považovat za prequel k následnému příspěvku.
Samozřejmě to nehraje dobře s JSON a dalšími API – dost často je to důvod, proč se na SQL Server předává řetězec oddělený čárkami.