TimescaleDB je open-source databáze vynalezená, aby umožnila škálovatelnost SQL pro data časových řad. Je to relativně nový databázový systém. TimescaleDB byla uvedena na trh před dvěma lety a v září 2018 dosáhla verze 1.0. Přesto je navržena na vrcholu vyspělého systému RDBMS.
TimescaleDB je zabalen jako rozšíření PostgreSQL. Veškerý kód je licencován pod open-source licencí Apache-2, s výjimkou některých zdrojových kódů souvisejících s podnikovými funkcemi time-series licencovanými pod licencí Timescale License (TSL).
Jako databáze časových řad poskytuje automatické rozdělení podle data a hodnot klíče. Nativní podpora SQL TimescaleDB z něj dělá dobrou volbu pro ty, kteří plánují ukládat data časových řad a již mají solidní znalosti jazyka SQL.
Pokud hledáte databázi časových řad, která může využívat bohaté SQL, HA, solidní zálohovací řešení, replikaci a další podnikové funkce, tento blog vás možná navede na správnou cestu.
Kdy použít TimescaleDB
Než začneme s funkcemi TimescaleDB, podívejme se, kam se vejde. TimescaleDB byl navržen tak, aby nabízel to nejlepší z relačních i NoSQL, se zaměřením na časové řady. Ale co jsou data časových řad?
Data časových řad jsou jádrem internetu věcí, monitorovacích systémů a mnoha dalších řešení zaměřených na často se měnící data. Jak název „časová řada“ napovídá, mluvíme o datech, která se mění s časem. Možnosti takového typu DBMS jsou nekonečné. Můžete jej použít v různých průmyslových případech IoT ve výrobě, těžbě, těžbě ropy a zemního plynu, maloobchodu, zdravotnictví, monitorování vývoje nebo sektoru finančních informací. Může se také skvěle hodit do kanálů strojového učení nebo jako zdroj pro obchodní operace a zpravodajství.
Není pochyb o tom, že poptávka po IoT a podobných řešeních poroste. Díky tomu můžeme také očekávat potřebu analyzovat a zpracovávat data mnoha různými způsoby. Data časových řad se obvykle pouze připojují – je docela nepravděpodobné, že budete aktualizovat stará data. Obvykle nemažete konkrétní řádky, na druhou stranu možná budete chtít nějakou agregaci dat v průběhu času. Nechceme pouze ukládat, jak se naše data mění s časem, ale také je analyzovat a učit se z nich.
Problémem nových typů databázových systémů je, že obvykle používají svůj vlastní dotazovací jazyk. Než se uživatelé naučí nový jazyk, nějakou dobu trvá. Největší rozdíl mezi TimescaleDB a dalšími populárními databázemi časových řad je podpora SQL. TimescaleDB podporuje celou řadu funkcí SQL včetně časově založených agregací, spojení, poddotazů, okenních funkcí a sekundárních indexů. Navíc, pokud vaše aplikace již používá PostgreSQL, nejsou potřeba žádné změny v kódu klienta.
Základy architektury
TimescaleDB je implementován jako rozšíření PostgreSQL, což znamená, že databáze s časovým měřítkem běží v rámci celkové instance PostgreSQL. Model rozšíření umožňuje databázi využívat mnoho atributů PostgreSQL, jako je spolehlivost, bezpečnost a konektivita k široké škále nástrojů třetích stran. TimescaleDB zároveň využívá vysoký stupeň přizpůsobení dostupný pro rozšíření přidáním háčků hluboko do plánovače dotazů PostgreSQL, datového modelu a prováděcího motoru.
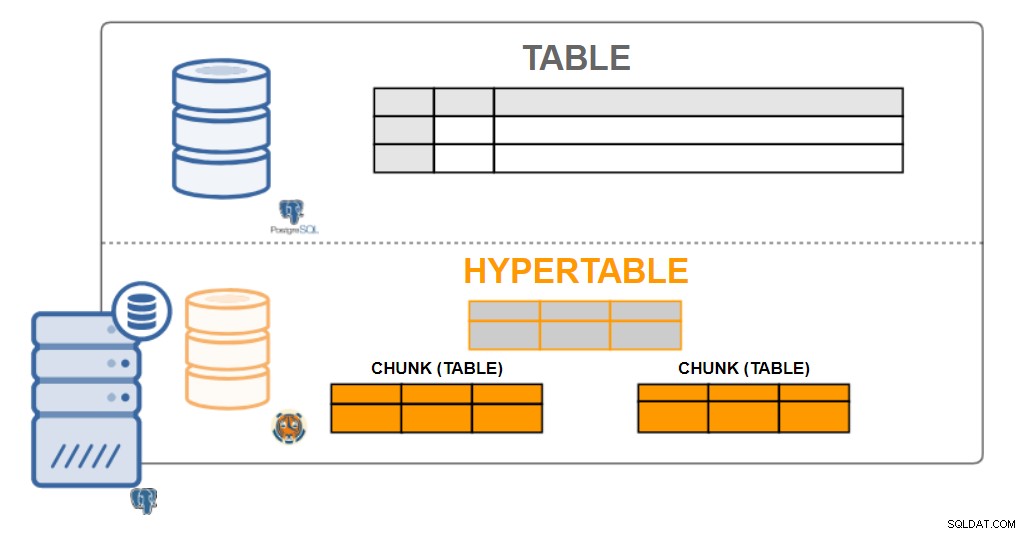 Architektura TimescaleDB
Architektura TimescaleDB Hypertabulky
Z uživatelského hlediska vypadají data TimescaleDB jako singulární tabulky, nazývané hypertabulky. Hypertabulky jsou konceptem nebo implicitním pohledem na mnoho jednotlivých tabulek obsahujících data nazývaná kusy. Data hypertabulky mohou být jednorozměrná nebo dvourozměrná. Lze jej agregovat podle časového intervalu a podle (volitelné) hodnoty „klíče oddílu“.
Prakticky všechny interakce uživatelů s TimescaleDB jsou s hypertabulkami. Vytváření tabulek, indexů, úpravy tabulek, výběr dat, vkládání dat... to vše by mělo být prováděno na hypertabulce.
TimescaleDB provádí toto rozsáhlé dělení jak na nasazení s jedním uzlem, tak na nasazení v clusteru (ve vývoji). I když se dělení tradičně používá pouze pro škálování na více strojích, umožňuje nám také škálovat na vysoké rychlosti zápisu (a vylepšené paralelizované dotazy) i na jednom stroji.
Podpora relačních dat
Jako relační databáze má plnou podporu pro SQL. TimescaleDB podporuje flexibilní datové modely, které lze optimalizovat pro různé případy použití. Tím se Timescale poněkud liší od většiny ostatních databází časových řad. DBMS je optimalizován pro rychlé ingest a složité dotazy, je založen na PostgreSQL a v případě potřeby máme přístup k robustnímu zpracování časových řad.
Instalace
TimescaleDB podobně jako PostgreSQL podporuje mnoho různých způsobů instalace, včetně instalace na Ubuntu, Debian, RHEL/Centos, Windows nebo cloudové platformy.
Jedním z nejpohodlnějších způsobů hraní s TimescaleDB je obrázek dockeru.
Níže uvedený příkaz stáhne obraz Dockeru z Docker Hub, pokud ještě nebyl nainstalován, a poté jej spustí.
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=severalnines timescale/timescaledbPrvní použití
Vzhledem k tomu, že naše instance je v provozu, je čas vytvořit naši první databázi timescaledb. Jak můžete vidět níže, připojujeme se přes standardní konzoli PostgreSQL, takže pokud máte lokálně nainstalované klientské nástroje PostgreSQL (např. psql), můžete je použít k přístupu k instanci dokovacího zařízení TimescaleDB.
psql -U postgres -h localhost
CREATE DATABASE severalnines;
\c severalnines
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;Každodenní provoz
Z hlediska použití i správy TimescaleDB prostě vypadá a působí jako PostgreSQL a lze jej jako takový spravovat a dotazovat.
Hlavní odrážky pro každodenní operace jsou:
- Koexistuje s jinými databázemi TimescaleDB a PostgreSQL na serveru PostgreSQL.
- Používá SQL jako jazyk rozhraní.
- Používá běžné konektory PostgreSQL k nástrojům třetích stran pro zálohování, konzoli atd.
Nastavení TimescaleDB
Okamžitá nastavení PostgreSQL jsou obvykle příliš konzervativní pro moderní servery a TimescaleDB. Měli byste se ujistit, že vaše nastavení postgresql.conf je vyladěno, buď pomocí timescaledb-tune, nebo to uděláte ručně.
$ timescaledb-tuneSkript vás požádá o potvrzení změn. Tyto změny jsou poté zapsány do vašeho postgresql.conf a projeví se po restartu.
Nyní se podívejme na některé základní operace z výukového programu TimescaleDB, který vám může poskytnout představu, jak pracovat s novým databázovým systémem.
Chcete-li vytvořit hypertabulku, začnete s běžnou tabulkou SQL a poté ji převedete na hypertabulku pomocí funkce create_hypertable.
-- Create extension timescaledb
CREATE EXTENSION timescaledb;
Create a regular table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);Převést jej na hypertable je jednoduché jako:
SELECT create_hypertable('conditions', 'time');Vkládání dat do hypertabulky se provádí pomocí běžných SQL příkazů:
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);Výběr dat je staré dobré SQL.
SELECT * FROM conditions ORDER BY time DESC LIMIT 10;Jak vidíme níže, můžeme provádět skupiny podle, seřadit podle a funkce. TimescaleDB navíc obsahuje funkce pro analýzu časových řad, které nejsou přítomné ve vanilla PostgreSQL.
SELECT time_bucket('15 minutes', time) AS fifteen_min,
location, COUNT(*),
MAX(temperature) AS max_temp,
MAX(humidity) AS max_hum
FROM conditions
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, location
ORDER BY fifteen_min DESC, max_temp DESC;