Databáze časových řad, jak název napovídá, jsou navrženy tak, aby ukládaly data, která se mění s časem. Může se jednat o jakýkoli druh dat, která byla shromážděna v průběhu času. Mohou to být metriky shromážděné z některých systémů a vlastně všechny systémy trendů jsou příklady dat časové řady.
Máme různé typy databází časových řad, které bychom měli použít?
V tomto blogu uvidíme, jaké jsou hlavní rozdíly mezi dvěma hlavními možnostmi, TimescaleDB a InfluxDB.
InfluxDB
InfluxDB byl vytvořen InfluxData. Je to vlastní, open-source, NoSQL databáze časové řady napsaná v Go. Datové úložiště poskytuje jazyk podobný SQL pro dotazování na data, zvaný InfluxQL, který vývojářům usnadňuje integraci do jejich aplikací. Má také nový vlastní dotazovací jazyk nazvaný Flux, tento jazyk může některé úkoly usnadnit, ale při používání vlastního dotazovacího jazyka je vždy potřeba se naučit.
Toto je příklad dotazu Flux:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()V této databázi má každé měření časové razítko a přidruženou sadu značek a sadu polí. Pole představuje skutečné hodnoty měření, zatímco značka představuje metadata k popisu měření. Datové typy polí jsou omezeny na float, ints, stringy a booleany a nelze je změnit bez přepsání dat. Hodnoty značek jsou indexovány. Jsou reprezentovány jako řetězce a nelze je aktualizovat.
InfluxDB je docela snadné začít, protože se nemusíte starat o vytváření schémat nebo indexů. Je však poměrně rigidní a omezený, bez možnosti vytvářet další indexy, indexy na souvislých polích, aktualizovat metadata po faktu, vynucovat validaci dat atd.
Není bez schématu. Existuje základní schéma, které je automaticky vytvořeno ze vstupních dat.
InfluxDB musí od začátku implementovat několik nástrojů pro odolnost proti chybám, jako je replikace, vysoká dostupnost a zálohování/obnovení, a je odpovědný za svou spolehlivost na disku. Jsme omezeni na používání těchto nástrojů a mnoho z těchto funkcí, jako je HA, je k dispozici pouze v podnikové verzi.
Zálohovací nástroj InfluxDB může provádět úplné nebo přírůstkové zálohování a lze jej použít pro obnovu v určitém okamžiku.
InfluxDB také nabízí výrazně lepší kompresi na disku než PostgreSQL a TimescaleDB.
TimescaleDB
TimescaleDB je open source databáze časových řad optimalizovaná pro rychlé ingest a složité dotazy, která podporuje plné SQL. Je založen na PostgreSQL a nabízí to nejlepší z NoSQL a relačních světů pro data časových řad.
Toto je příklad dotazu TimescaleDB:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB jako rozšíření PostgreSQL je relační databáze. To umožňuje mít krátkou křivku učení pro nové uživatele a zdědit nástroje jako pg_dump nebo pg_backup pro zálohování a nástroje s vysokou dostupností, což je výhoda oproti jiným databázím časových řad. Podporuje také streamingovou replikaci jako primární metodu replikace, kterou lze použít v nastavení vysoké dostupnosti. Pokud jde o převzetí služeb při selhání a zálohování, můžete tento proces automatizovat pomocí externího systému, jako je ClusterControl.
V TimescaleDB je každé měření časové řady zaznamenáváno ve svém vlastním řádku, s časovým polem následovaným libovolným počtem dalších polí, což mohou být floats, ints, strings, booleans, pole, JSON blob, geoprostorové dimenze, datum/čas/ časová razítka, měny, binární data a další.
Můžete vytvořit indexy pro libovolné pole (standardní indexy) nebo více polí (složené indexy) nebo pro výrazy, jako jsou funkce, nebo dokonce omezit index na podmnožinu řádků (částečný index). Kterékoli z těchto polí lze použít jako cizí klíč k sekundárním tabulkám, které pak mohou ukládat další metadata.
Tímto způsobem si musíte vybrat schéma a rozhodnout, které indexy budete pro svůj systém potřebovat.
Výkon
Pokud mluvíme o výkonu, můžeme se podívat na skvělý srovnávací blog TimescaleDB. Zde máte podrobné srovnání výkonu mezi oběma databázemi s grafy a metrikami. Pojďme se podívat na některé z nejdůležitějších informací z tohoto blogu.
Vložky
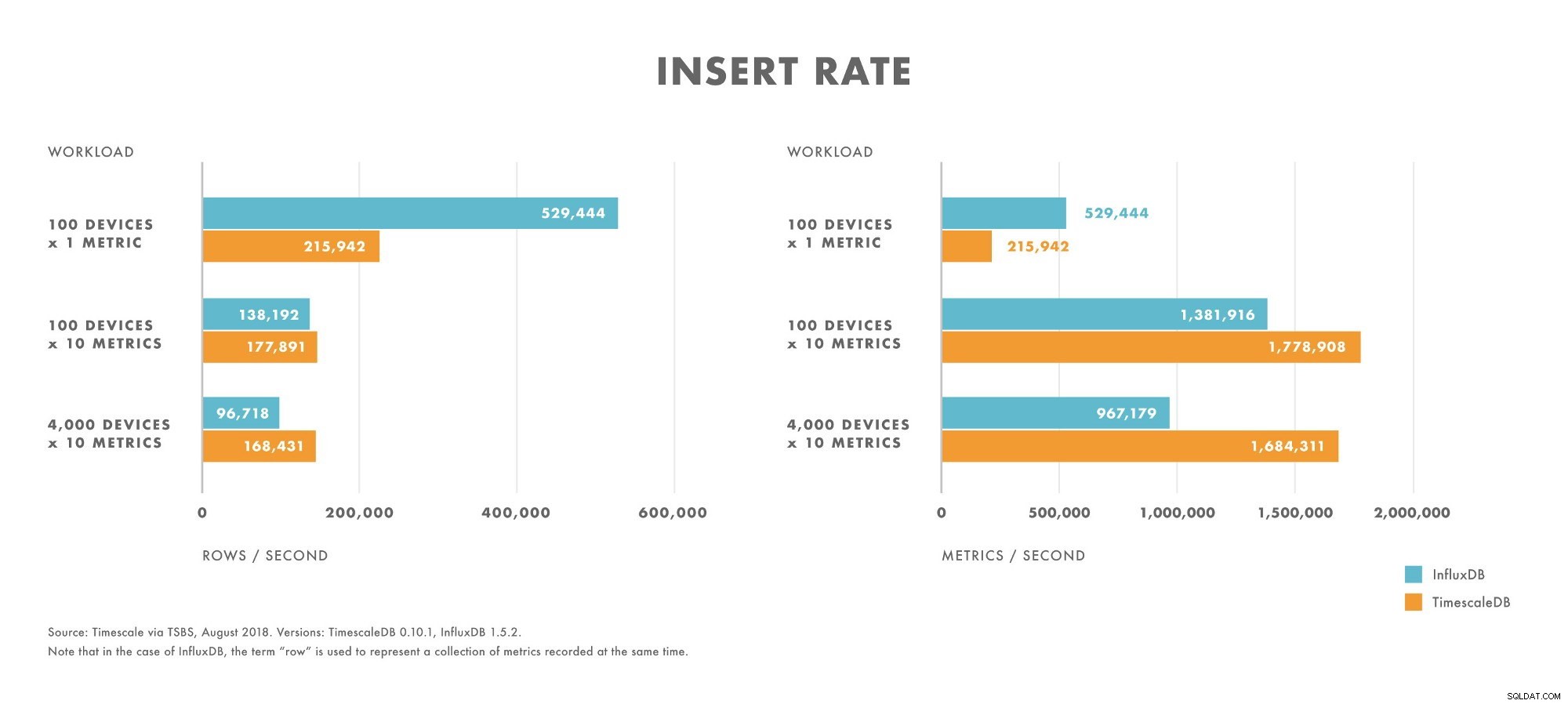
- U pracovních zátěží s velmi nízkou mohutností (např. 100 zařízení) InfluxDB překonává TimescaleDB.
- S rostoucí mohutností klesá výkon vložek InfluxDB rychleji než u TimescaleDB.
- U úloh se střední až vysokou mohutností (např. 100 zařízení odesílající 10 metrik) TimescaleDB překonává InfluxDB.

Latence čtení
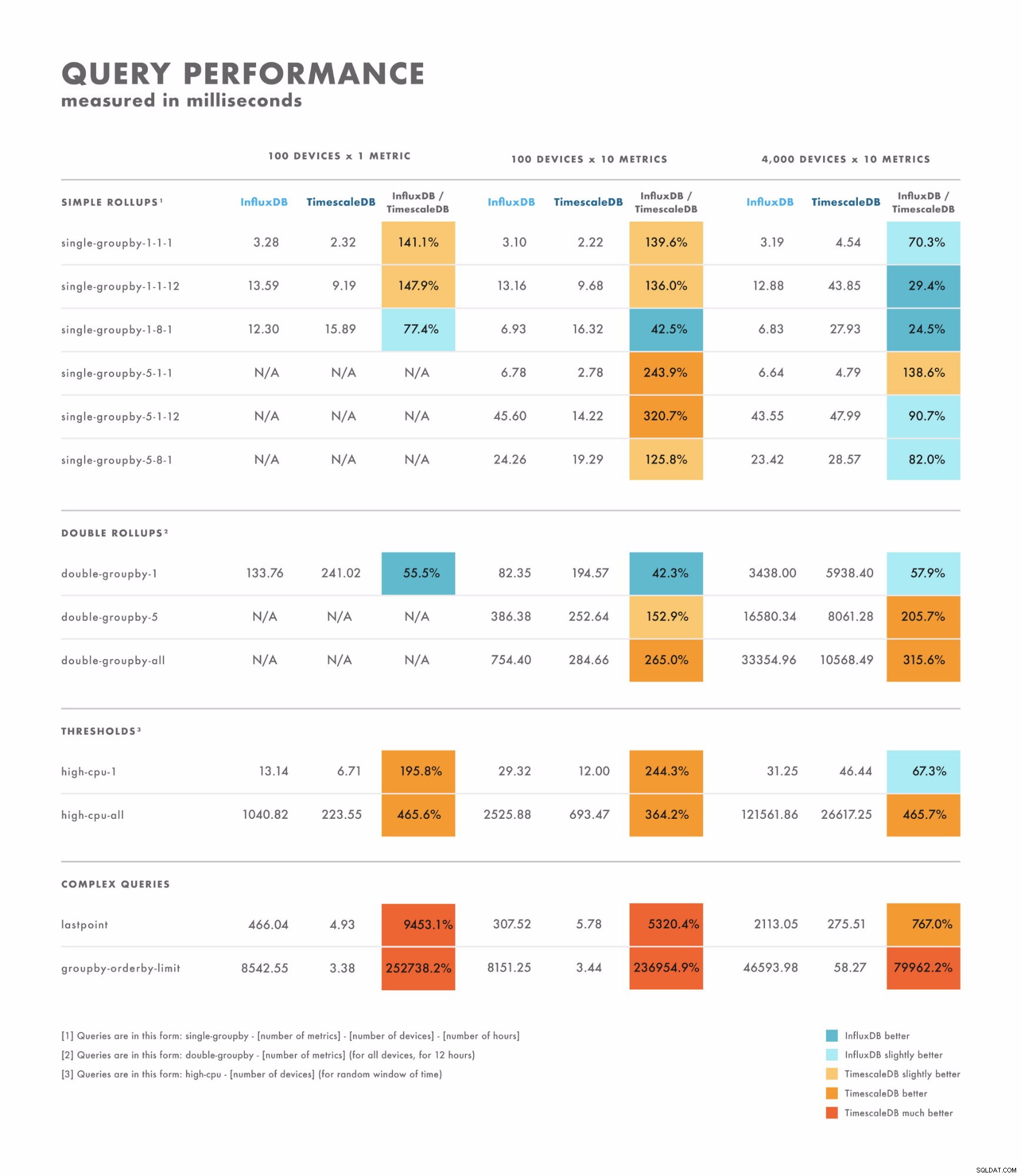
- U jednoduchých dotazů se výsledky dost liší:existují některé, kde je jedna databáze jednoznačně lepší než druhá, zatímco jiné závisí na mohutnosti vaší datové sady. Rozdíl je zde často v rozsahu jednociferných až dvouciferných milisekund.
- U komplexních dotazů TimescaleDB výrazně překonává InfluxDB a podporuje širší škálu typů dotazů. Rozdíl se zde často pohybuje v řádu sekund až desítek sekund.
- S ohledem na to je nejlepším způsobem správného testování provést srovnávání pomocí dotazů, které plánujete provést.
Problémy se stabilitou
- InfluxDB má problémy se stabilitou a výkonem při vysokých (100 000+) mohutnostech.
Závěr
Pokud vaše data zapadají do datového modelu InfluxDB a neočekáváte, že se v budoucnu změní, měli byste zvážit použití InfluxDB, protože s tímto modelem je snazší začít a jako většina databází, které používají přístup orientovaný na sloupce, nabízí lepší kompresi na disku než PostgreSQL a TimescaleDB.
Relační model je však všestrannější a nabízí více funkčnosti, flexibility a kontroly než model InfluxDB. To je zvláště důležité, protože se vaše aplikace vyvíjí. A při plánování vašeho systému byste měli zvážit jeho současné i budoucí potřeby.
V tomto blogu jsme mohli vidět krátké srovnání mezi TimescaleDB a InfluxDB a mohli bychom říci, že TimescaleDB jako rozšíření PostgreSQL vypadá docela vyspěle a má bohaté funkce, protože toho hodně zdědí z PostgreSQL. Můžete se však rozhodnout sami na základě výhod a nevýhod uvedených dříve v tomto blogu a ujistěte se, že srovnáváte svou vlastní pracovní zátěž. Hodně štěstí v tomto novém světě databází časových řad!