Pokud jde o grafické plány provádění, na serveru SQL Server je pouze jedna ikona pro fyzické řazení:

Stejná ikona se používá pro tři logické operátory řazení:Sort, Top N Sort a Odlišné řazení:
Když půjdeme o úroveň hlouběji, existují čtyři různé implementace Sort v prováděcím jádru (nepočítáme-li dávkové třídění pro optimalizovaná spojení smyček, což není úplné řazení a stejně není vidět v plánech). Pokud používáte SQL Server 2014, počet implementací řazení prováděcího modulu se zvýší na sedm:
- CQScanSortNew
- CQScanTopSortNew
- CQScanIndexSortNew
- CQScanPartitionSortNew (pouze SQL Server 2014)
- CQScanInMemSortNew
- In-Memory OLTP (Hekaton) nativně kompilovaná procedura Top N Sort (pouze SQL Server 2014)
- In-Memory OLTP (Hekaton) nativně kompilovaná procedura General Sort (pouze SQL Server 2014)
Tento článek se zabývá těmito implementacemi řazení a kdy se každá používá na serveru SQL Server. První část pokrývá první čtyři položky na seznamu.
1. CQScanSortNew
Toto je nejobecnější třída třídy, která se používá, když nelze použít žádnou z ostatních dostupných možností. Obecné řazení používá přidělení paměti pracovního prostoru vyhrazené těsně před zahájením provádění dotazu. Tento grant je úměrný odhadům mohutnosti a průměrné velikosti řádků a nelze ho zvýšit po zahájení provádění dotazu.
Zdá se, že současná implementace používá různé druhy interního slučovacího řazení (možná binární slučovací řazení), přechod na externí slučovací řazení (v případě potřeby s více průchody), pokud se rezervovaná paměť ukáže jako nedostatečná. Externí slučovací řazení používá fyzickou tempdb prostor pro řazení, které se nevejdou do paměti (běžně známé jako sort spill). Obecné řazení lze také nakonfigurovat tak, aby během operace řazení bylo použito odlišnosti.
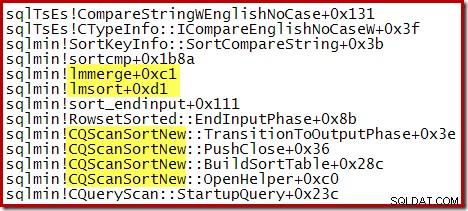
Následující částečné trasování zásobníku ukazuje příklad CQScanSortNew třídy třídící řetězce pomocí interního slučovacího řazení:
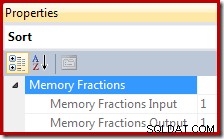
V plánech provádění poskytuje řazení informace o části celkového přidělení paměti pracovního prostoru dotazu, která je k dispozici třídění při čtení záznamů (vstupní fáze), a části dostupné při spotřebování setříděného výstupu operátory nadřazeného plánu (výstupní fáze ).
Zlomek přidělené paměti je číslo mezi 0 a 1 (kde 1 =100 % přidělené paměti) a je viditelný v SSMS po zvýraznění položky Seřadit a v okně Vlastnosti. Níže uvedený příklad byl převzat z dotazu pouze s jedním operátorem řazení, takže má k dispozici plné přidělení paměti pracovního prostoru dotazu během vstupní i výstupní fáze:
Paměťové zlomky odrážejí skutečnost, že během své vstupní fáze musí řazení sdílet celkové přidělení paměti dotazu se souběžně vykonávajícími operátory spotřebovávajícími paměť pod ním v plánu provádění. Podobně během výstupní fáze musí řazení sdílet přidělenou paměť se souběžně vykonávajícími operátory spotřebovávajícími paměť nad ním v plánu provádění.
Procesor dotazů je dostatečně chytrý na to, aby věděl, že někteří operátoři blokují (stop-and-go), čímž účinně označují hranice, kde lze přidělení paměti recyklovat a znovu použít. V paralelních plánech je zlomek přidělení paměti dostupný pro obecné řazení rozdělen rovnoměrně mezi vlákna a nelze jej za běhu znovu vyvážit v případě zkreslení (běžná příčina rozlití v plánech paralelního řazení).
SQL Server 2012 a novější obsahuje další informace o minimálním přidělení paměti pracovního prostoru požadovaném k inicializaci operátorů plánu náročných na paměť a požadovaných přidělení paměti (odhaduje se "ideální" množství paměti potřebné k dokončení celé operace v paměti). V plánu provádění po spuštění ("skutečném") jsou také nové informace o jakýchkoli zpožděních při získávání přidělení paměti, maximálním množství skutečně použité paměti a způsobu, jakým byla rezervace paměti distribuována mezi uzly NUMA.
Všechny následující příklady AdventureWorks používají CQScanSortNew obecné řazení:
-- Obyčejné řazení (CQScanSortNew)SELECT P.Jméno, P.MiddleName, P.LastNameFROM Person.Person AS PORDER BY P.FirstName, P.MiddleName, P.LastName; -- Odlišné řazení (také CQScanSortNew) SELECT DISTINCT P.Jméno, P.MiddleName, P.LastNameFROM Person.Person AS PORDER BY P.FirstName, P.MiddleName, P.LastName; -- Stejný dotaz vyjádřený pomocí GROUP BY -- Stejný plán provedení řazení (CQScanSortNew) SELECT P.Jméno, P.MiddleName, P.LastNameFROM Person.Person AS PGROUP BY P.FirstName, P.MiddleName, P.LastNameORDER BY P.FirstName , P.MiddleName, P.LastName;
První dotaz (nerozlišující řazení) vytvoří následující plán provádění:
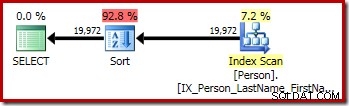
Druhý a třetí (ekvivalentní) dotaz vytvoří tento plán:
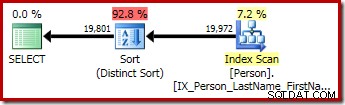
CQScanSortNew lze použít jak pro logické obecné řazení, tak pro logické odlišné řazení.
2. CQScanTopSortNew
CQScanTopSortNew je podtřídou CQScanSortNew používá se k implementaci řazení Top N (jak název napovídá). CQScanTopSortNew deleguje většinu základní práce na CQScanSortNew , ale upravuje podrobné chování různými způsoby v závislosti na hodnotě N.
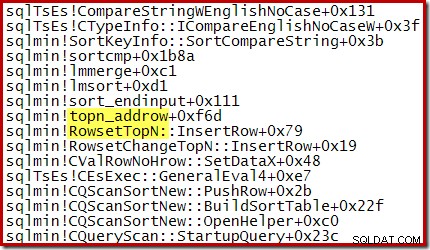
Pro N> 100, CQScanTopSortNew je v podstatě jen běžný CQScanSortNew řazení, které automaticky zastaví vytváření seřazených řádků po N řádcích. Pro N <=100, CQScanTopSortNew uchovává pouze aktuální výsledky Top N během operace řazení a sleduje nejnižší klíčovou hodnotu, která aktuálně splňuje podmínky.
Například během optimalizovaného řazení Top N (kde N <=100) obsahuje zásobník volání RowsetTopN zatímco u obecného řazení v sekci 1 jsme viděli RowsetSorted :
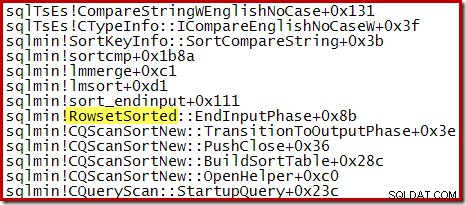
Pro Top N řazení, kde N> 100, je zásobník volání ve stejné fázi provádění stejný jako obecné řazení uvedené dříve:
Všimněte si, že CQScanTopSortNew název třídy se neobjeví v žádném z těchto trasování zásobníku. Je to jednoduše způsobeno tím, jak funguje podtřídění. V ostatních bodech během provádění těchto dotazů CQScanTopSortNew metody (např. Open, GetRow a CreateTopNTable) se explicitně objevují v zásobníku volání. Následující příklad byl použit později při provádění dotazu a zobrazuje CQScanTopSortNew název třídy:
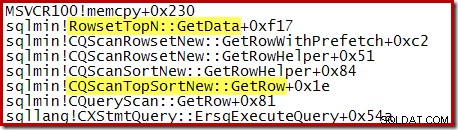
Top N řazení a optimalizátor dotazů
Optimalizátor dotazů neví nic o Top N Sort, což je pouze operátor prováděcího modulu. Když optimalizátor vytvoří výstupní strom s fyzickým operátorem Top bezprostředně nad (nerozlišeným) fyzickým řazením, přepis po optimalizaci může sbalit dvě fyzické operace do jediného operátoru řazení Top N. I v případě N> 100 to představuje úsporu při procházení řádků iterativně mezi výstupem Sort a vstupem Top.
Následující dotaz používá několik nezdokumentovaných příznaků trasování k zobrazení výstupu optimalizátoru a přepisu po optimalizaci v akci:
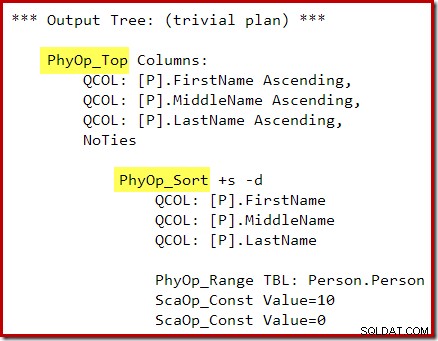
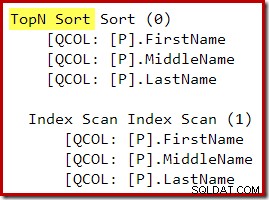
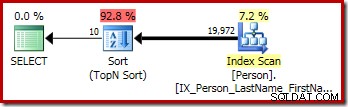
SELECT TOP (10) P.FirstName, P.MiddleName, P.LastNameFROM Person.Person AS PORDER BY P.FirstName, P.MiddleName, P.LastNameOPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON);Výstupní strom optimalizátoru zobrazuje samostatné fyzické operátory Top a Sort:
Po přepsání po optimalizaci byly Top a Sort sbaleny do jediného Top N řazení:
Grafický plán provádění pro dotaz T-SQL výše ukazuje jediný operátor řazení Top N:
Prolomení přepisu řazení nahoře N
Pooptimalizační přepis Top N seřazení může sbalit pouze sousední Top N a nerozlišené řazení do Top N seřazení. Přidání DISTINCT (nebo ekvivalentní klauzule GROUP BY) do dotazu výše zabrání přepsání Top N řazení:
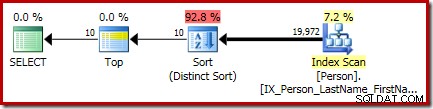
VYBERTE DISTINCT TOP (10) P.Jméno, P.MiddleName, P.LastNameFROM Person.Person AS ORDER BY P.FirstName, P.MiddleName, P.LastName;Konečný plán provádění tohoto dotazu obsahuje samostatné operátory Top a Sort (Distinct Sort):
Třídění je obecné CQScanSortNew třída běžící v odlišném režimu, jak je vidět v části 1 dříve.
Druhým způsobem, jak zabránit přepsání na Top N Sort, je zavést jeden nebo více dalších operátorů mezi Top a Sort. Například:
VYBERTE NEJLEPŠÍ (10) P.Jméno, P.Příjmení, P.Příjmení, rn =POŘADÍ() NAD (POŘADÍ PODLE P.Jméno)OD Osoby.Osoby JAKO POŘADÍ PODLE P.Jméno, P.MiddleName, P. Příjmení;Výstup optimalizátoru dotazů má nyní operaci mezi Top a Sort, takže Top N seřazení není generováno během fáze přepisu po optimalizaci:
Prováděcí plán je:
Výpočetní sekvence (implementovaná jako dva segmenty a sekvenční projekt) mezi Top a Sort zabraňuje kolapsu Top a Sort na jediný operátor Top N Sort. Z tohoto plánu bude samozřejmě stále dosaženo správných výsledků, ale provádění může být o něco méně efektivní, než by mohlo být s kombinovaným operátorem Top N Sort.
3. CQScanIndexSortNew
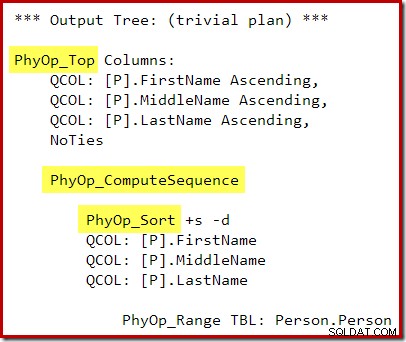
CQScanIndexSortNew se používá pouze pro třídění v plánech vytváření indexů DDL. Znovu používá některé z obecných třídicích zařízení, které jsme již viděli, ale přidává specifické optimalizace pro vkládání indexů. Je to také jediná třídicí třída, která může dynamicky požadovat více paměti po zahájení provádění.
Odhad mohutnosti je pro plán vytváření indexu často přesný, protože celkový počet řádků v tabulce je obvykle známá veličina. To neznamená, že přidělení paměti pro řazení plánu vytváření indexu bude vždy přesné; jen to trochu zjednodušuje demo. Následující příklad tedy používá nezdokumentované, ale poměrně dobře známé rozšíření příkazu UPDATE STATISTICS, aby oklamal optimalizátor, aby si myslel, že tabulka, na které vytváříme index, má pouze jeden řádek:
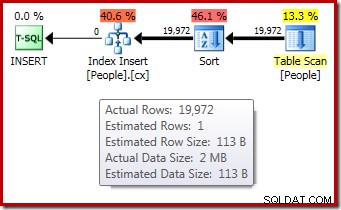
-- Testovací tabulkaCREATE TABLE dbo.People( Jméno dbo.Jméno NOT NULL, Příjmení dbo.Name NOT NULL);GO-- Zkopírujte řádky z Person.PersonINSERT dbo.People WITH (TABLOCKX)( Jméno, Příjmení)SELECT P .FirstName, P.LastNameFROM Person.Person AS P;GO-- Předstírejte, že tabulka má pouze 1 řádek a 1 stránku. (LastName, FirstName);GO-- Tidy upDROP TABLE dbo.People;Plán provádění po spuštění ("skutečný") pro sestavení indexu nezobrazuje upozornění na rozlité řazení (při spuštění na serveru SQL Server 2012 nebo novějším), navzdory odhadu 1 řádku a skutečně seřazených 19 972 řádků:
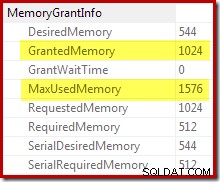
Potvrzení, že počáteční přidělení paměti bylo dynamicky rozšířeno, pochází z pohledu na vlastnosti kořenového iterátoru. Dotazu bylo původně přiděleno 1024 kB paměti, ale nakonec bylo spotřebováno 1576 kB:
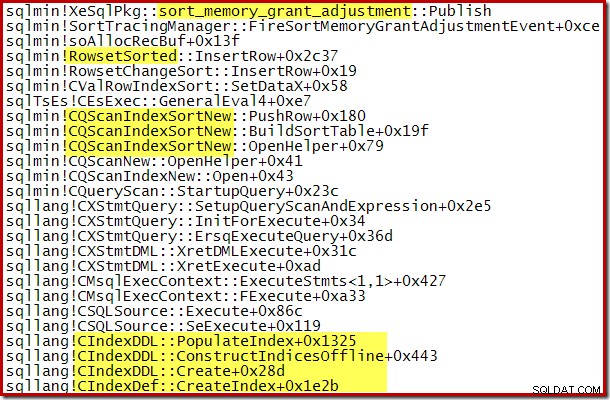
Dynamický nárůst přidělené paměti lze také sledovat pomocí rozšířené události kanálu ladění sort_memory_grant_adjustment. Tato událost je generována pokaždé, když se alokace paměti dynamicky zvyšuje. Pokud je tato událost monitorována, můžeme zachytit trasování zásobníku, když je publikována, buď prostřednictvím Extended Events (s nějakou nepohodlnou konfigurací a příznakem trasování) nebo z připojeného ladicího programu, jak je uvedeno níže:
Dynamické rozšíření přidělení paměti může také pomoci s paralelními plány sestavení indexu, kde je rozložení řádků mezi vlákny nerovnoměrné. Množství paměti, které lze tímto způsobem spotřebovat, však není neomezené. SQL Server kontroluje pokaždé, když je potřeba rozšíření, aby zjistil, zda je požadavek přiměřený vzhledem k prostředkům dostupným v danou chvíli.
Určitý přehled o tomto procesu lze získat povolením příznaku nedokumentovaného trasování 1504 spolu s 3604 (pro výstup zpráv do konzoly) nebo 3605 (výstup do protokolu chyb SQL Server). Pokud je plán sestavení indexu paralelní, je efektivní pouze 3605, protože paralelní pracovníci nemohou do konzole posílat zprávy sledování napříč vlákny.
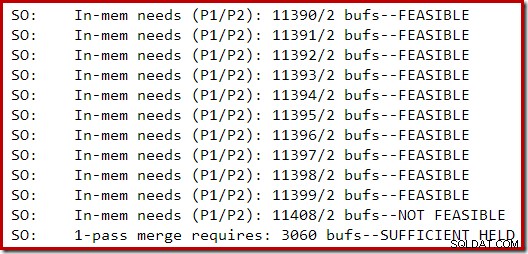
Při vytváření středně velkého indexu na instanci SQL Server 2014 s omezenou pamětí byla zachycena následující část výstupu trasování:
Rozšiřování paměti pro řazení pokračovalo, dokud nebyl požadavek považován za neproveditelný. V tomto okamžiku bylo zjištěno, že již bylo zadrženo dostatek paměti pro dokončení jednoprůchodového řazení.
4. CQScanPartitionSortNew
Tento název třídy může naznačovat, že tento typ řazení se používá pro data dělených tabulek nebo při vytváření indexů na dělených tabulkách, ale ani jedno z toho ve skutečnosti není. Třídění dělených dat používá CQScanSortNew nebo CQScanTopSortNew jako normálně; řazení řádků pro vložení do rozděleného indexu obecně používá CQScanIndexSortNew jak je vidět v části 3.
CQScanPartitionSortNew třída sort je přítomna pouze v SQL Server 2014. Používá se pouze při řazení řádků podle ID oddílu před vložením do rozděleného clusterovaného indexu columnstore . Všimněte si, že se používá pouze pro rozdělené clustered columnstore; běžné (nerozdělené) klastrované plány vložení sloupcového úložiště nemají prospěch z řazení.
Vložení do rozděleného seskupeného indexu columnstore nebude vždy obsahovat řazení. Je to rozhodnutí založené na nákladech, které závisí na odhadovaném počtu řádků, které mají být vloženy. Pokud optimalizátor odhadne, že stojí za to seřadit vložky podle oddílu pro optimalizaci I/O, operátor vložení columnstore bude mít DMLRequestSort vlastnost nastavena na true a CQScanPartitionSortNew řazení se může objevit v prováděcím plánu.
Demo v této sekci používá stálou tabulku sekvenčních čísel. Pokud žádný z nich nemáte, můžete jej vytvořit pomocí následujícího skriptu:
-- Generátor řádků Itzika Ben-Gana S L0 AS (SELECT 1 AS c UNION ALL SELECT 1), L1 AS (SELECT 1 AS c Z L0 AS A CROSS JOIN L0 AS B), L2 AS (SELECT 1 AS c FROM L1 JAKO PŘIPOJENÍ L1 JAKO B), L3 JAKO (VYBRAT 1 JAKO c Z L2 JAKO SPOJE DO KŘÍŽU L2 JAKO B), L4 AS (VYBRAT 1 JAKO C Z L3 JAKO PŘÍČNÉ SPOJENÍ L3 JAKO B), L5 JAKO (VYBRAT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B), Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)SELECT -- Typ cílového sloupce integer NOT NULL ISNULL(CONVERT(integer, N.n), 0) AS nINTO dbo.NumbersFROM Nums AS NWHERE N.n >=1AND N.n <=1000000OPTION (MAXDOP 1);BRANKÁŘSKÁ TABULKA dbo.Čísla PŘIDAT OMEZENÍ PK_Numbers_n,PRIMÁRNÍ_TERMÍN1MP. =100);Samotné demo zahrnuje vytvoření rozdělené klastrované indexované tabulky columnstore a vložení dostatečného množství řádků (z výše uvedené tabulky Numbers), aby přesvědčil optimalizátor, aby použil řazení před vložením oddílu:
VYTVOŘENÍ FUNKCE ODDĚLENÍ PF (celé číslo) JAKO ROZSAH SPRÁVNÝ PRO HODNOTY (1 000, 2 000, 3 000);GOCREATE SCHÉMA ROZDĚLENÍ ODDĚLENÍ PSAS PFALL TO ([PRIMÁRNÍ]);GO-- Rozdělená haldaCREATE NOTABLE TABLE( dbo.Partitioned NULL, col2 celé číslo NOT NULL VÝCHOZÍ ABS(CHECKSUM(NEWID())), col3 celé číslo NOT NULL VÝCHOZÍ ABS(CHECKSUM(NEWID())))ON PS (col1);GO-- Převést hromadu na rozdělený clusterovaný columnstoreCREATE CLUSTERED CLUSTERED INDEX STOLE ccsiON dbo.PartitionedON PS (col1);GO-- Přidejte řádky do rozdělené tabulky klastrovaného úložiště sloupcůINSERT dbo.Partitioned (col1)SELECT N.nFROM dbo.Numbers AS NWHERE N.n BETWEEN 1 AND 4000;Plán provádění pro vložení ukazuje řazení použité k zajištění toho, aby řádky dorazily do klastrovaného iterátoru vložení sloupcového úložiště v pořadí ID oddílu:
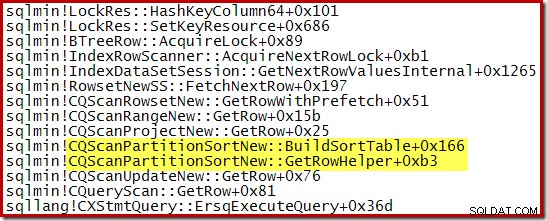
Zásobník volání zachycený během CQScanPartitionSortNew řazení probíhalo je uvedeno níže:
Na této třídě je ještě něco zajímavého. Třídění normálně spotřebuje celý svůj vstup při volání metody Open. Po seřazení vrátí řízení svému nadřazenému operátorovi. Později třídění začne produkovat seřazené výstupní řádky jeden po druhém obvyklým způsobem pomocí volání GetRow. CQScanPartitionSortNew je jiný, jak můžete vidět v zásobníku volání výše:Nespotřebovává svůj vstup během své metody Open – čeká, až bude GetRow zavolán svým rodičem poprvé.
Ne každé řazení podle ID oddílu, které se objeví v prováděcím plánu vkládajícím řádky do rozděleného seskupeného indexu columnstore, bude CQScanPartitionSortNew třídit. Pokud se řazení objeví hned napravo od operátora pro vložení indexu columnstore, je velká pravděpodobnost, že se jedná o CQScanPartitionSortNew seřadit.
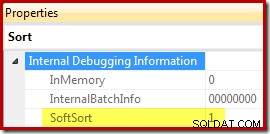
Nakonec CQScanPartitionSortNew je jednou z pouze dvou tříd řazení, která nastavuje vlastnost Soft Sort, která se zobrazí, když jsou vlastnosti plánu provádění operátora řazení generovány s nezdokumentovaným příznakem trasování 8666:
Význam „soft sort“ v tomto kontextu je nejasný. Je sledována jako vlastnost v rámci optimalizátoru dotazů a zdá se, že pravděpodobně souvisí s optimalizovanými vložkami rozdělených dat, ale určení toho, co přesně to znamená, vyžaduje další výzkum. Mezitím lze tuto vlastnost použít k odvození, že řazení je implementováno pomocí CQScanPartitionSortNew bez připojení debuggeru. Význam příznaku vlastnosti InMemory zobrazený výše bude popsán v části 2. není označte, zda bylo v paměti provedeno pravidelné řazení či nikoli.
Shrnutí první části


- CQScanSortNew je obecná třída třídy používaná, když není použitelná žádná jiná možnost. Zdá se, že používá různé interní řazení v paměti, přechází na externí řazení pomocí tempdb pokud se pracovní prostor přidělené paměti ukáže jako nedostatečný. Tuto třídu lze použít pro obecné třídění a odlišné třídění.
- CQScanTopSortNew implementuje Top N Sort. Kde N <=100, provede se interní řazení sloučení v paměti a nikdy se nerozlije do tempdb . Během řazení je v paměti zachováno pouze aktuálních n položek. Pro N> 100 CQScanTopSortNew je ekvivalentní CQScanSortNew řazení, které se automaticky zastaví po výstupu N řádků. Třídění N> 100 se může přenést do tempdb v případě potřeby.
- Top N řazení viděné v plánech provádění je přepsání po optimalizaci po dotazu. Pokud optimalizátor dotazů vytvoří výstupní strom se sousedním Top N a nerozlišeným řazením, tento přepis může sbalit dva fyzické operátory do jediného operátoru Top N řazení.
- CQScanIndexSortNew se používá pouze při vytváření indexů plánů DDL. Je to jediná standardní třídicí třída, která může dynamicky získat více paměti během provádění. Seřazení vytváření indexů se může za určitých okolností stále přelévat na disk, včetně případů, kdy SQL Server rozhodne, že požadované navýšení paměti není kompatibilní s aktuální zátěží.
- CQScanPartitionSortNew je přítomen pouze v SQL Server 2014 a používá se pouze k optimalizaci vložení do rozděleného clusterového indexu columnstore. Poskytuje „měkké třídění“.
Druhá část tohoto článku se bude zabývat CQScanInMemSortNew a dvě nativně zkompilované uložené procedury In-Memory OLTP.