V dnešní době je replikace samozřejmostí v prostředí s vysokou dostupností a odolností proti chybám pro téměř jakoukoli databázovou technologii, kterou používáte. Je to téma, které jsme viděli znovu a znovu, ale nikdy nezestárne.
Pokud používáte TimescaleDB, nejběžnějším typem replikace je streamovaná replikace, ale jak to funguje?
V tomto blogu se podíváme na některé koncepty související s replikací a zaměříme se na replikaci streamování pro TimescaleDB, což je funkce zděděná ze základního enginu PostgreSQL. Potom uvidíme, jak nám ClusterControl může pomoci jej nakonfigurovat.
Streamingová replikace je tedy založena na odeslání záznamů WAL a jejich aplikování na záložní server. Nejprve se tedy podívejme, co je WAL.
WAL
Write Ahead Log (WAL) je standardní metoda pro zajištění integrity dat, ve výchozím nastavení je automaticky povolena.
WAL jsou protokoly REDO v TimescaleDB. Ale co jsou to protokoly REDO?
Protokoly REDO obsahují všechny změny, které byly v databázi provedeny a používají se při replikaci, obnově, online zálohování a obnově v určitém okamžiku (PITR). Jakékoli změny, které nebyly aplikovány na datové stránky, lze znovu provést z protokolů REDO.
Použití WAL má za následek výrazně snížený počet zápisů na disk, protože na disk je třeba vyprázdnit pouze soubor protokolu, aby bylo zaručeno, že transakce byla potvrzena, a nikoli každý datový soubor, který transakce změnila.
Záznam WAL bude specifikovat, bit po bitu, změny provedené v datech. Každý záznam WAL bude připojen do souboru WAL. Pozicí vložení je sekvenční číslo protokolu (LSN), což je bajtový posun v protokolech, který se zvyšuje s každým novým záznamem.
WAL jsou uloženy v adresáři pg_wal v adresáři dat. Tyto soubory mají výchozí velikost 16 MB (velikost lze změnit změnou možnosti konfigurace --with-wal-segsize při sestavování serveru). Mají jedinečný přírůstkový název v následujícím formátu:"00000001 00000000 00000000".
Počet souborů WAL obsažených v pg_wal bude záviset na hodnotě přiřazené parametrům min_wal_size a max_wal_size v konfiguračním souboru postgresql.conf.
Jeden parametr, který musíme nastavit při konfiguraci všech našich instalací TimescaleDB, je wal_level. Určuje, kolik informací se zapisuje do WAL. Výchozí hodnota je minimální, která zapisuje pouze informace potřebné k obnově po havárii nebo okamžitém vypnutí. Archive přidává protokolování potřebné pro archivaci WAL; hot_standby dále přidává informace potřebné ke spouštění dotazů pouze pro čtení na pohotovostním serveru; a nakonec logické přidává informace nezbytné pro podporu logického dekódování. Tento parametr vyžaduje restart, takže pokud jsme na to zapomněli, může být obtížné jej změnit při běžících produkčních databázích.
Streamování replikace
Replikace datových proudů je založena na způsobu odesílání protokolu. Záznamy WAL se přímo přesouvají z jednoho databázového serveru na jiný, aby byly použity. Dá se říci, že jde o spojitý PITR.
Tento přenos se provádí dvěma různými způsoby, přenosem záznamů WAL po jednom souboru (segment WAL) po druhém (zasílání protokolů na základě souborů) a přenosem záznamů WAL (soubor WAL se skládá ze záznamů WAL) za chodu (založený na záznamu log shipping), mezi hlavním serverem a jedním nebo několika podřízenými servery, aniž byste čekali na vyplnění souboru WAL.
V praxi se proces zvaný přijímač WAL, běžící na podřízeném serveru, připojí k hlavnímu serveru pomocí připojení TCP/IP. Na hlavním serveru existuje další proces, nazvaný odesílatel WAL, a má na starosti odesílání registrů WAL na podřízený server, jakmile k nim dojde.
Replikace datových proudů může být znázorněna následovně:
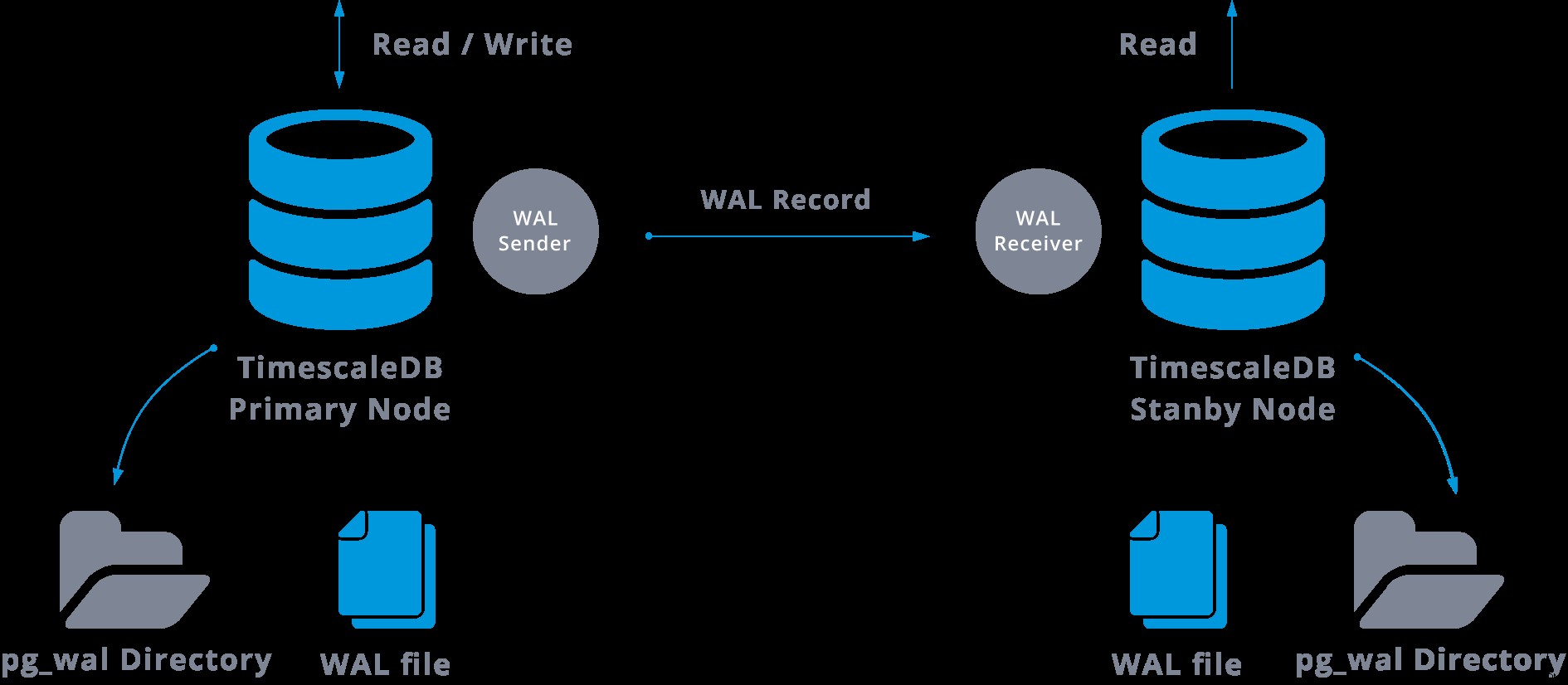
Při pohledu na výše uvedený diagram si můžeme myslet, co se stane, když selže komunikace mezi odesílatelem WAL a přijímačem WAL?
Při konfiguraci streamované replikace máme možnost povolit archivaci WAL.
Tento krok ve skutečnosti není povinný, ale je extrémně důležitý pro robustní nastavení replikace, protože je nutné zabránit tomu, aby hlavní server recykloval staré soubory WAL, které ještě nebyly aplikovány na podřízenou jednotku. Pokud k tomu dojde, budeme muset repliku vytvořit znovu od začátku.
Při konfiguraci replikace s nepřetržitou archivací začínáme od zálohy a abychom dosáhli stavu synchronizace s hlavním serverem, musíme použít všechny změny hostované ve WAL, ke kterým došlo po zálohování. Během tohoto procesu pohotovostní režim nejprve obnoví všechny dostupné WAL v umístění archivu (provede se voláním restore_command). Příkaz restore_command selže, když dosáhneme posledního archivovaného záznamu WAL, takže poté se pohotovostní režim podívá do adresáře pg_wal, aby zjistil, zda tam změna existuje (ve skutečnosti se to dělá, aby se předešlo ztrátě dat při zhroucení hlavních serverů a některých změny, které již byly přesunuty do repliky a použity tam, ještě nebyly archivovány).
Pokud se to nezdaří a požadovaný záznam tam neexistuje, začne komunikovat s hlavním serverem prostřednictvím streamingové replikace.
Kdykoli selže streamovací replikace, vrátí se zpět ke kroku 1 a znovu obnoví záznamy z archivu. Tato smyčka načítání z archivu, pg_wal, a prostřednictvím streamingové replikace pokračuje, dokud není server zastaven nebo není spuštěno převzetí služeb při selhání spouštěcím souborem.
Toto bude schéma takové konfigurace:
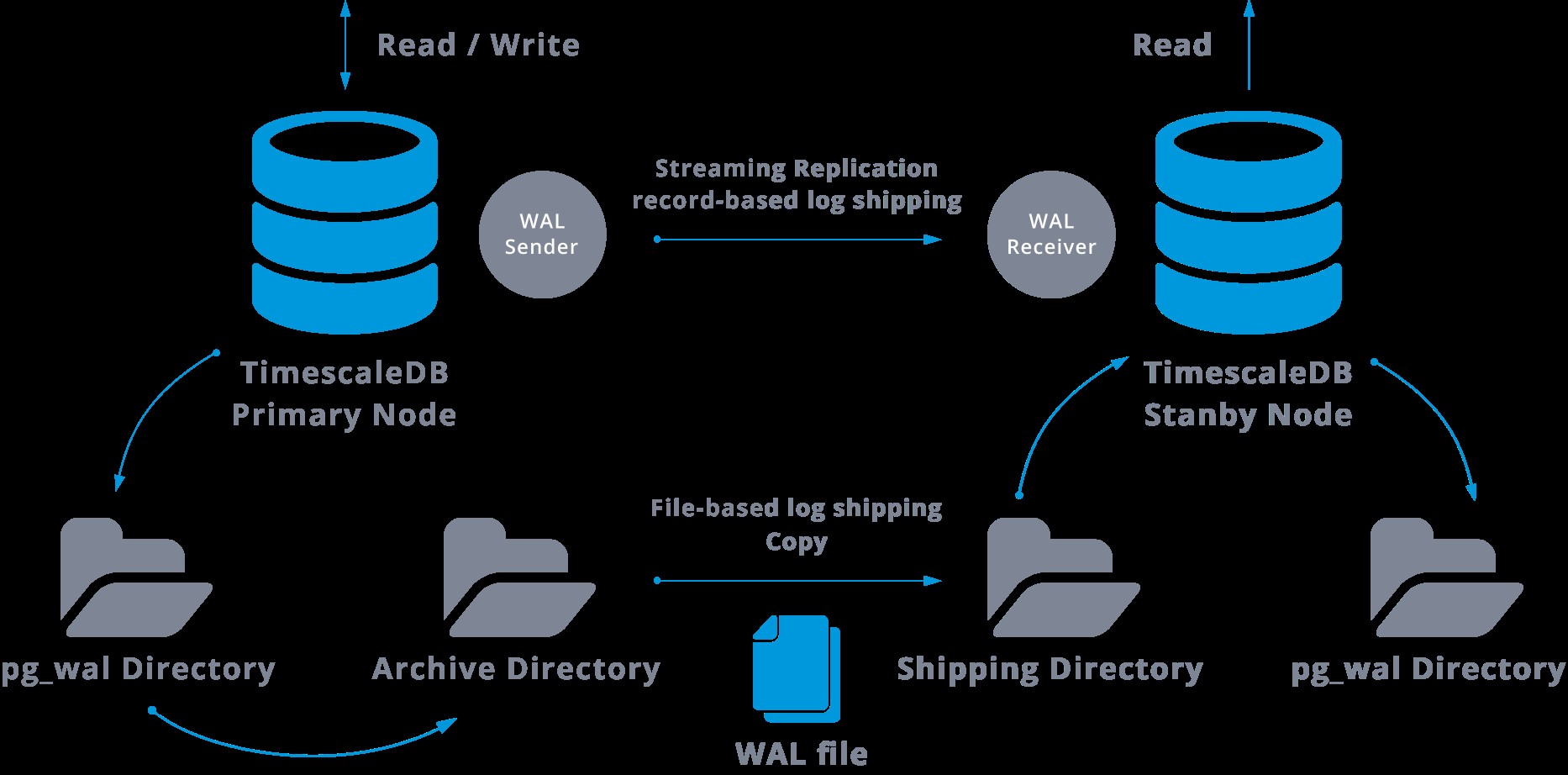
Streamová replikace je ve výchozím nastavení asynchronní, takže v určitém okamžiku můžeme mít nějaké transakce, které lze potvrdit na hlavním serveru a ještě nereplikovat na záložní server. To znamená určitou potenciální ztrátu dat.
Předpokládá se však, že toto zpoždění mezi potvrzením a dopadem změn v replice bude opravdu malé (několik milisekund), samozřejmě za předpokladu, že replikační server je dostatečně výkonný, aby držel krok se zátěží.
Pro případy, kdy ani riziko malé ztráty dat není tolerovatelné, můžeme použít funkci synchronní replikace.
Při synchronní replikaci bude každé potvrzení transakce zápisu čekat, dokud není přijato potvrzení, že potvrzení bylo zapsáno do protokolu pro zápis na disk primárního i záložního serveru.
Tato metoda minimalizuje možnost ztráty dat, protože k tomu potřebujeme, aby selhal hlavní i záložní režim současně.
Zjevnou nevýhodou této konfigurace je, že doba odezvy pro každou transakci zápisu se zvyšuje, protože musíme čekat, dokud všechny strany nezareagují. Takže čas pro odevzdání je minimálně okružní cesta mezi masterem a replikou. Transakce pouze pro čtení tím nebudou ovlivněny.
K nastavení synchronní replikace potřebujeme, aby každý z pohotovostních serverů uvedl název_aplikace v primárním_conninfo souboru recovery.conf:primary_conninfo ='...název_aplikace=slaveX'.
Potřebujeme také specifikovat seznam záložních serverů, které se chystají zúčastnit synchronní replikace:synchronous_standby_name ='slaveX,slaveY'.
Můžeme nastavit jeden nebo několik synchronních serverů a tento parametr také určuje, kterou metodu (PRVNÍ a LIBOVOLNOU) vybrat synchronní pohotovostní režimy z uvedených.
K nasazení TimescaleDB s nastavením streamování replikace (synchronní nebo asynchronní) můžeme použít ClusterControl, jak vidíme zde.
Poté, co nakonfigurujeme naši replikaci a bude spuštěna, budeme potřebovat nějaké další funkce pro monitorování a správu zálohování. ClusterControl nám umožňuje monitorovat a spravovat zálohy/uchovávání našeho clusteru TimescaleDB ze stejného místa bez jakéhokoli externího nástroje.
Jak nakonfigurovat replikaci streamování na TimescaleDB
Nastavení streamingové replikace je úkol, který vyžaduje důkladné provedení některých kroků. Pokud jej chcete nakonfigurovat ručně, můžete sledovat náš blog na toto téma.
Můžete však nasadit nebo importovat aktuální TimescaleDB na ClusterControl a poté můžete nakonfigurovat replikaci streamování pomocí několika kliknutí. Podívejme se, jak to můžeme udělat.
Pro tento úkol budeme předpokládat, že svůj cluster TimescaleDB spravujete pomocí ClusterControl. Přejděte do ClusterControl -> Vybrat klastr -> Akce klastru -> Přidat slave replikace.
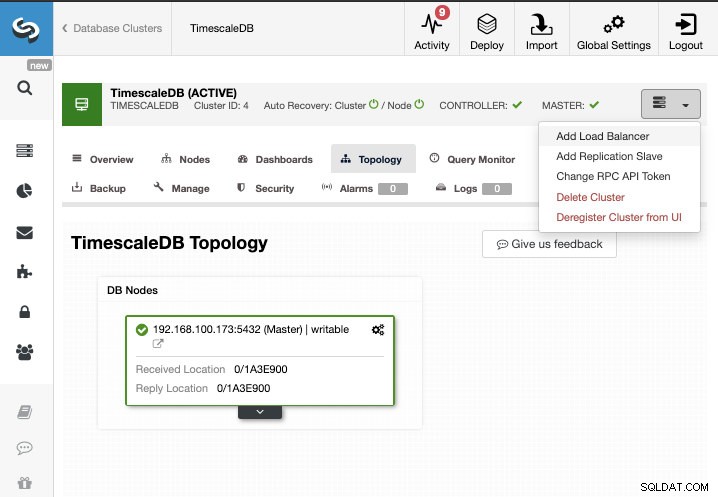
Můžeme vytvořit nový replikační slave (pohotovostní režim) nebo můžeme importovat existující. V tomto případě vytvoříme nový.
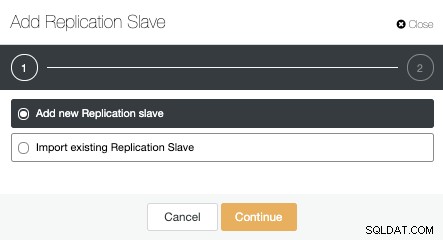
Nyní musíme vybrat hlavní uzel, přidat IP adresu nebo název hostitele pro nový pohotovostní server a port databáze. Můžeme také určit, zda chceme, aby ClusterControl nainstaloval software, a zda chceme nakonfigurovat synchronní nebo asynchronní streamovací replikaci.
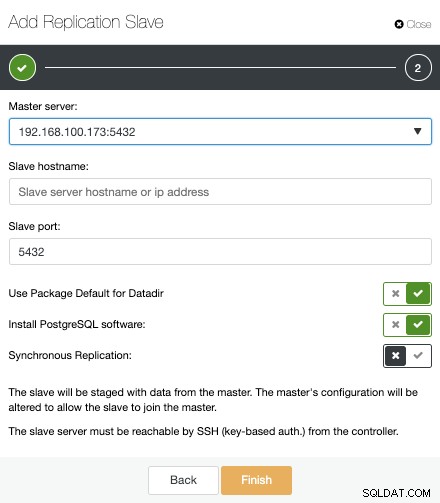
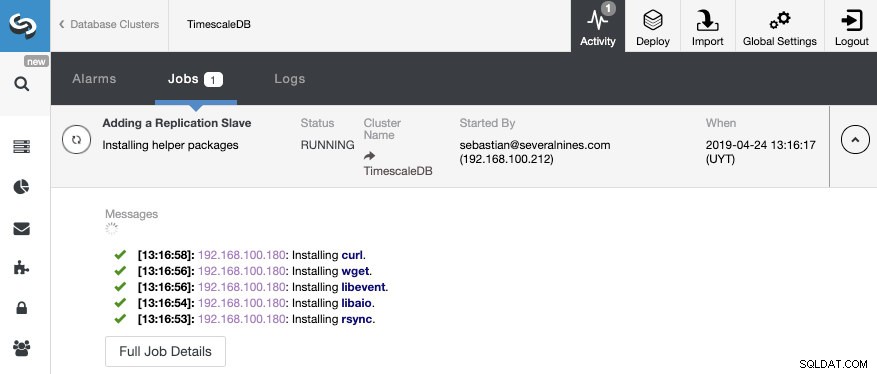
To je vše. Musíme pouze počkat, až ClusterControl dokončí úlohu. Stav můžeme sledovat ze sekce Aktivita.
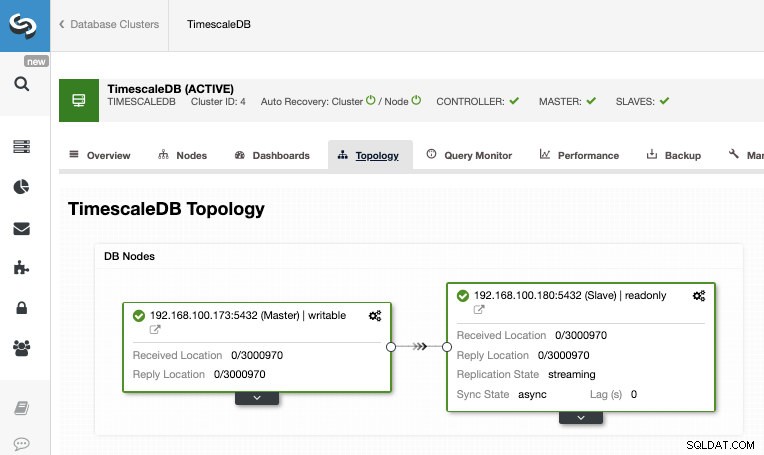
Po dokončení úlohy bychom měli mít nakonfigurovanou streamovací replikaci a novou topologii můžeme zkontrolovat v sekci ClusterControl Topology View.
Pomocí ClusterControl můžete také provádět několik úkolů správy na vaší TimescaleDB, jako je zálohování, monitorování a upozornění, automatické převzetí služeb při selhání, přidávat uzly, přidávat nástroje pro vyrovnávání zatížení a ještě více.
Přepnutí při selhání
Jak jsme viděli, TimescaleDB používá proud záznamů protokolu WAL (Write-ahead log) k udržení synchronizace rezervních databází. Pokud hlavní server selže, pohotovostní režim obsahuje téměř všechna data hlavního serveru a lze jej rychle změnit na nový hlavní databázový server. To může být synchronní nebo asynchronní a lze to provést pouze pro celý databázový server.
K efektivnímu zajištění vysoké dostupnosti nestačí mít architekturu master-standby. Potřebujeme také povolit nějakou automatickou formu převzetí služeb při selhání, takže pokud něco selže, můžeme mít co nejmenší zpoždění při obnovení normální funkčnosti.
TimescaleDB nezahrnuje automatický mechanismus převzetí služeb při selhání, který by identifikoval selhání v hlavní databázi a upozornil podřízenou jednotku, aby převzala vlastnictví, takže to bude vyžadovat trochu práce na straně DBA. Budete také mít funkční pouze jeden server, takže je třeba provést znovu vytvoření architektury master-standby, abychom se dostali zpět do stejné normální situace, jakou jsme měli před problémem.
ClusterControl obsahuje funkci automatického převzetí služeb při selhání pro TimescaleDB pro zlepšení střední doby opravy (MTTR) ve vašem prostředí s vysokou dostupností. V případě selhání ClusterControl povýší nejpokročilejší slave na master a překonfiguruje zbývající slave(y) tak, aby se připojily k novému masteru. HAProxy lze také nasadit automaticky, aby aplikacím nabídl jeden koncový bod databáze, takže na ně nebude mít vliv změna hlavního serveru.
Omezení
Související zdroje ClusterControl for TimescaleDB Jak snadno nasadit TimescaleDB PostgreSQL Streaming Replication – hluboký ponorPři používání replikace streamování máme některá známá omezení:
- Nemůžeme replikovat do jiné verze nebo architektury
- Na pohotovostním serveru nemůžeme nic změnit
- Nemáme příliš podrobné informace o tom, co můžeme replikovat
Abychom tato omezení překonali, máme funkci logické replikace. Chcete-li se dozvědět více o tomto typu replikace, můžete se podívat na následující blog.
Závěr
Topologie master-standby má mnoho různých použití, jako je analytika, zálohování, vysoká dostupnost, převzetí služeb při selhání. V každém případě je nutné pochopit, jak funguje replikace streamování na TimescaleDB. Je také užitečné mít systém pro správu celého clusteru a dát vám možnost vytvořit tuto topologii jednoduchým způsobem. V tomto blogu jsme viděli, jak toho dosáhnout pomocí ClusterControl, a zopakovali jsme si některé základní koncepty streamovací replikace.