V předchozích blozích jsme vám s kolegy ukázali, jak můžete monitorovat výkon, spravovat a nasazovat clustery, spouštět zálohy a dokonce povolit automatické převzetí služeb při selhání pro TimescaleDB.
V tomto blogu vám ukážeme, jak škálovat vaši jedinou instanci TimescaleDB na cluster s více uzly v několika jednoduchých krocích.
Začneme běžným nastavením, instancí jednoho uzlu běžící na CentosOS. Uzel je v provozu a již je monitorován a spravován pomocí ClusterControl.
Pokud byste se chtěli dozvědět, jak nasadit nebo importovat svou instanci TimescaleDB, podívejte se na blog, který napsal můj kolega Sebastian Insausti, „Jak snadno nasadit TimescaleDB.“
Nastavení vypadá následovně...
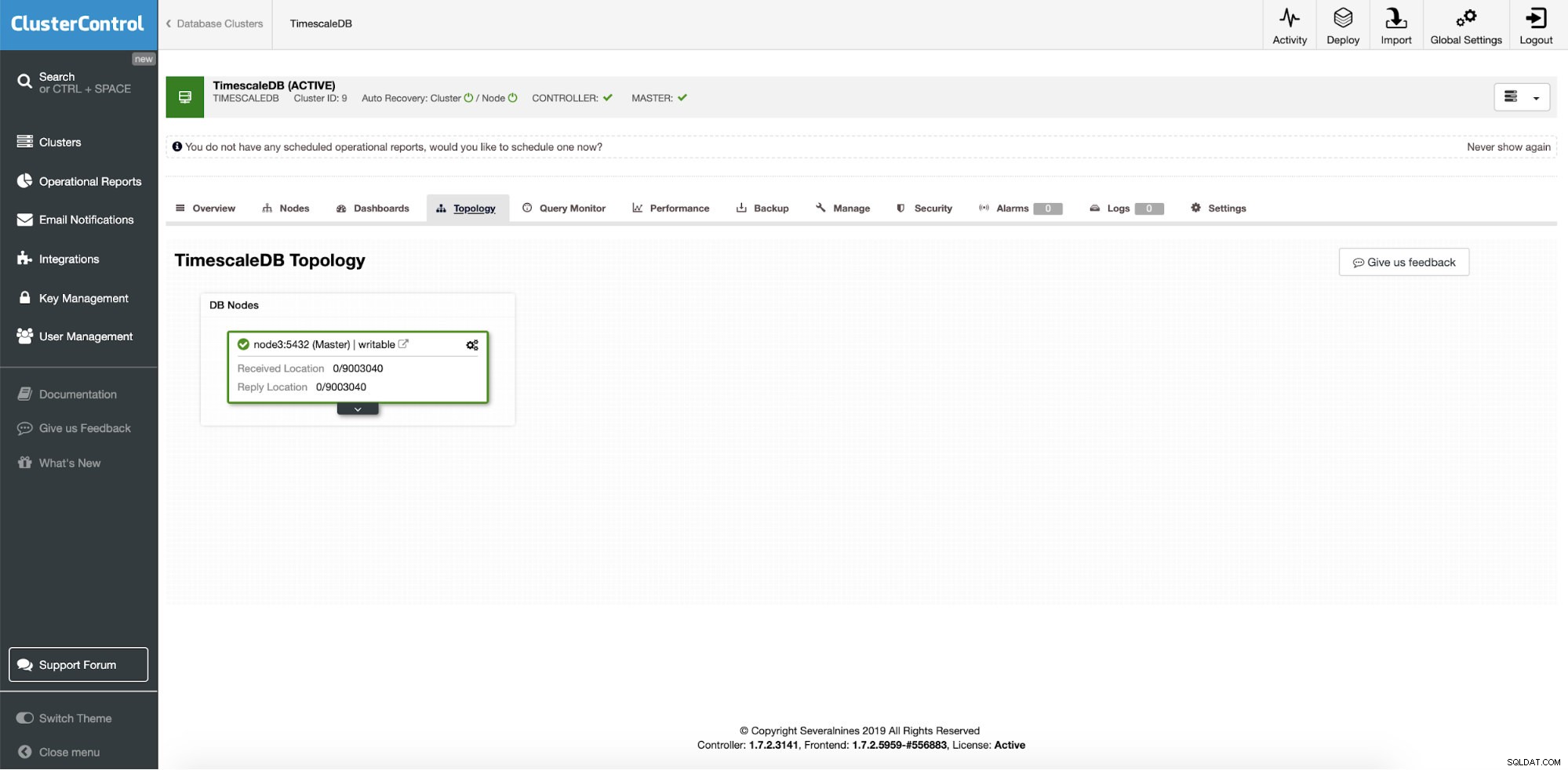 ClusterControl:Jedna instance TimescaleDB
ClusterControl:Jedna instance TimescaleDB Jde tedy o jedinou produkční instanci a my ji chceme převést na cluster bez prostojů. Naším hlavním cílem je škálovat operace čtení aplikací na jiné stroje s možností použít je jako přípravné HA servery při havárii serveru při zápisu.
Více uzlů by také mělo snížit prostoje údržby aplikací. Stejně jako záplatování aplikované v režimu postupného restartu – jeden uzel je záplatován současně, zatímco ostatní uzly obsluhují databázová připojení.
Posledním požadavkem je vytvořit jedinou adresu pro náš nový cluster, aby naše nové uzly byly pro aplikaci viditelné z jednoho místa.

Náš akční plán můžeme shrnout do dvou hlavních kroků:
- Přidání repliky přečtení
- Nainstalujte a nakonfigurujte Haproxy
Přidání repliky čtení
Pokud přejdeme na akce clusteru a vybereme „Add Replication Slave“, můžeme buď vytvořit novou repliku od začátku, nebo přidat existující databázi TimescaleDB jako repliku.
 ClusterControl:Přidání replikačního slave
ClusterControl:Přidání replikačního slave 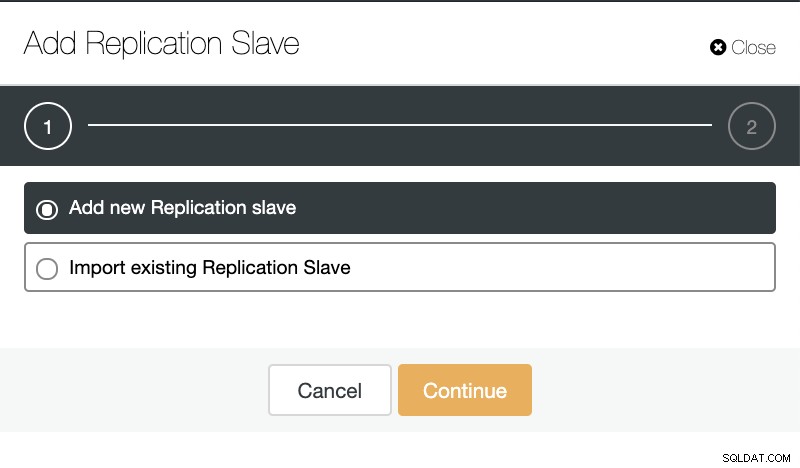 ClusterControl:Přidat nový slave replikace, importovat existující slave replikace
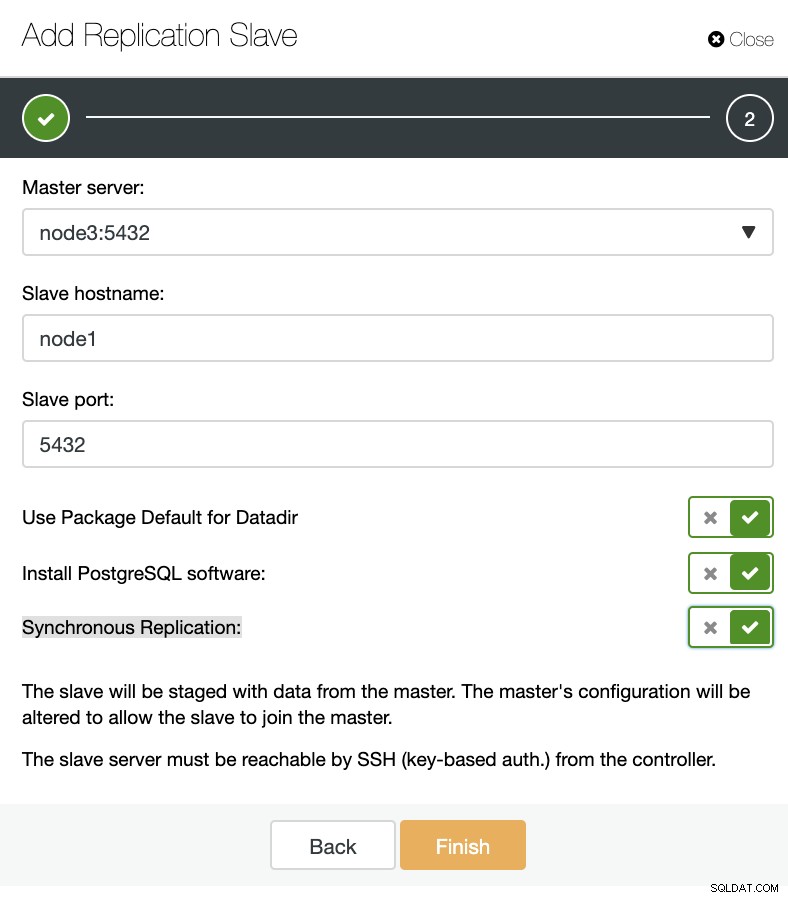
ClusterControl:Přidat nový slave replikace, importovat existující slave replikace Jak můžete vidět na obrázku níže, musíme pouze vybrat náš hlavní server, zadat IP adresu našeho nového podřízeného serveru a port databáze.
 ClusterControl:Přidat replikaci slave
ClusterControl:Přidat replikaci slave Poté si můžeme vybrat, zda chceme, aby ClusterControl nainstaloval software za nás a zda má být replikační slave synchronní nebo asynchronní. Když importujete existující podřízený server, můžete použít možnost importu následovně:
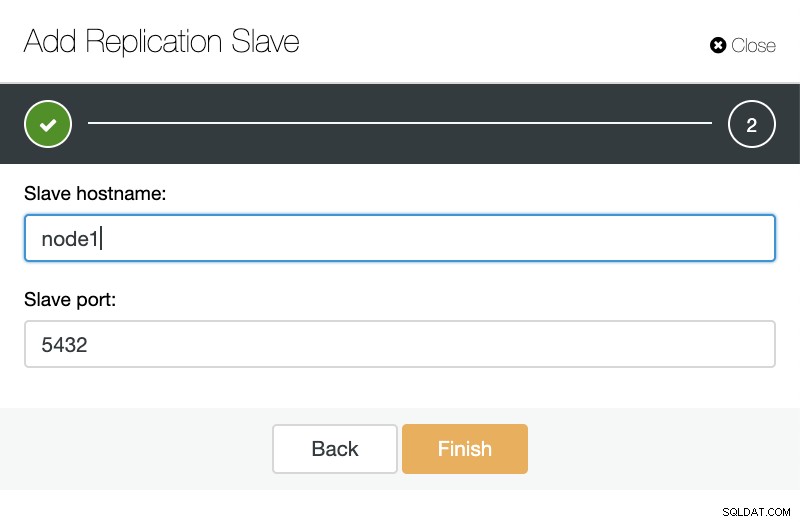 ClusterControl:Import replikace slave pro TimescaleDB
ClusterControl:Import replikace slave pro TimescaleDB Oběma způsoby můžeme přidat tolik replik, kolik chceme. V našem příkladu přidáme dva uzly. CusterControl vytvoří interní úlohu a postará se o všechny nezbytné kroky s jedním žádným.
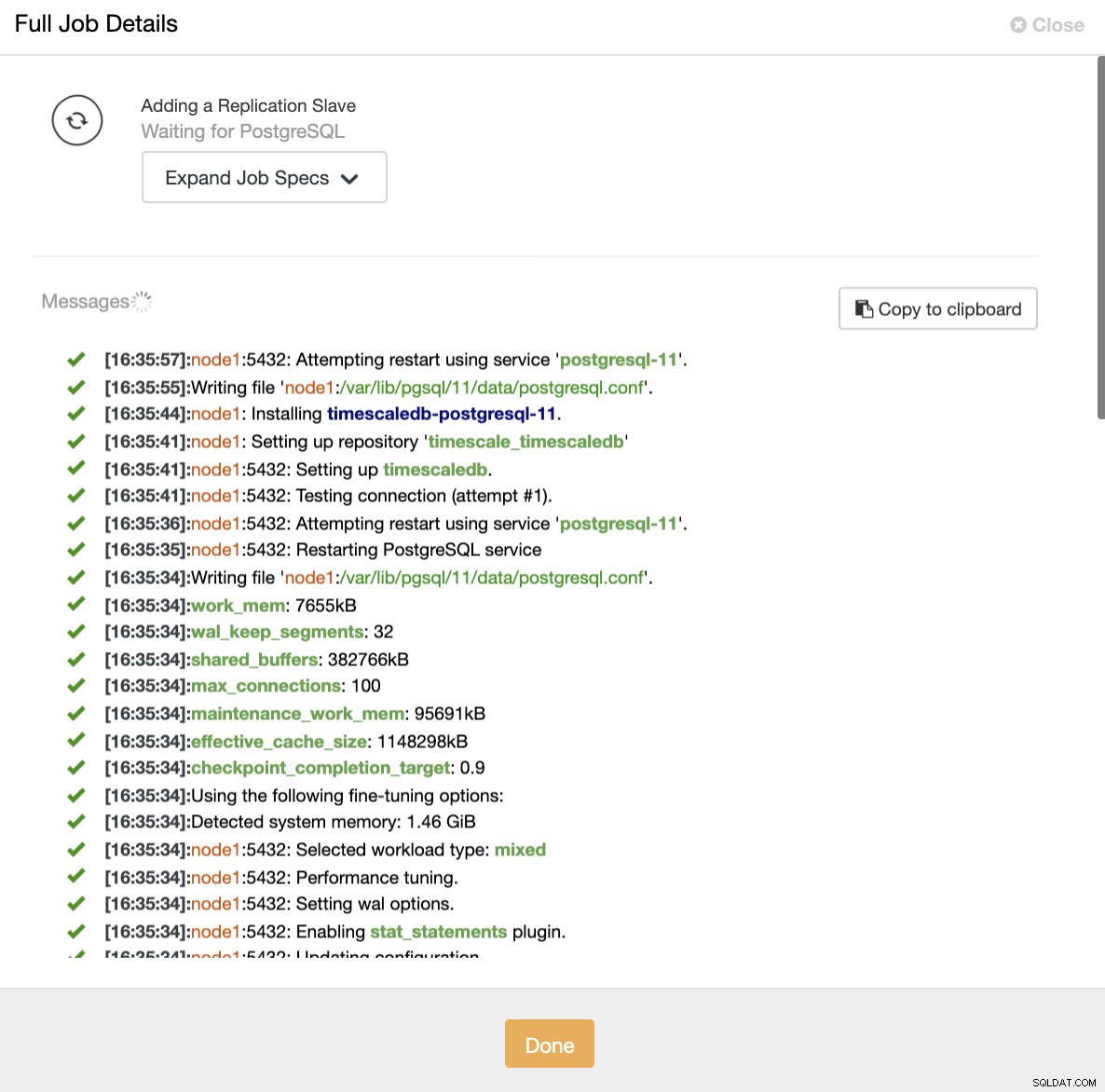 ClusterControl:přidat repliku pro čtení
ClusterControl:přidat repliku pro čtení Přidání nástroje pro vyrovnávání zatížení do TimescaleDB
V tomto okamžiku jsou naše data distribuována mezi více uzly nebo datovými středisky, pokud se rozhodnete přidat replikační podřízené uzly v jiném umístění. Cluster je zmenšen pomocí dvou dalších čtených replikových uzlů.
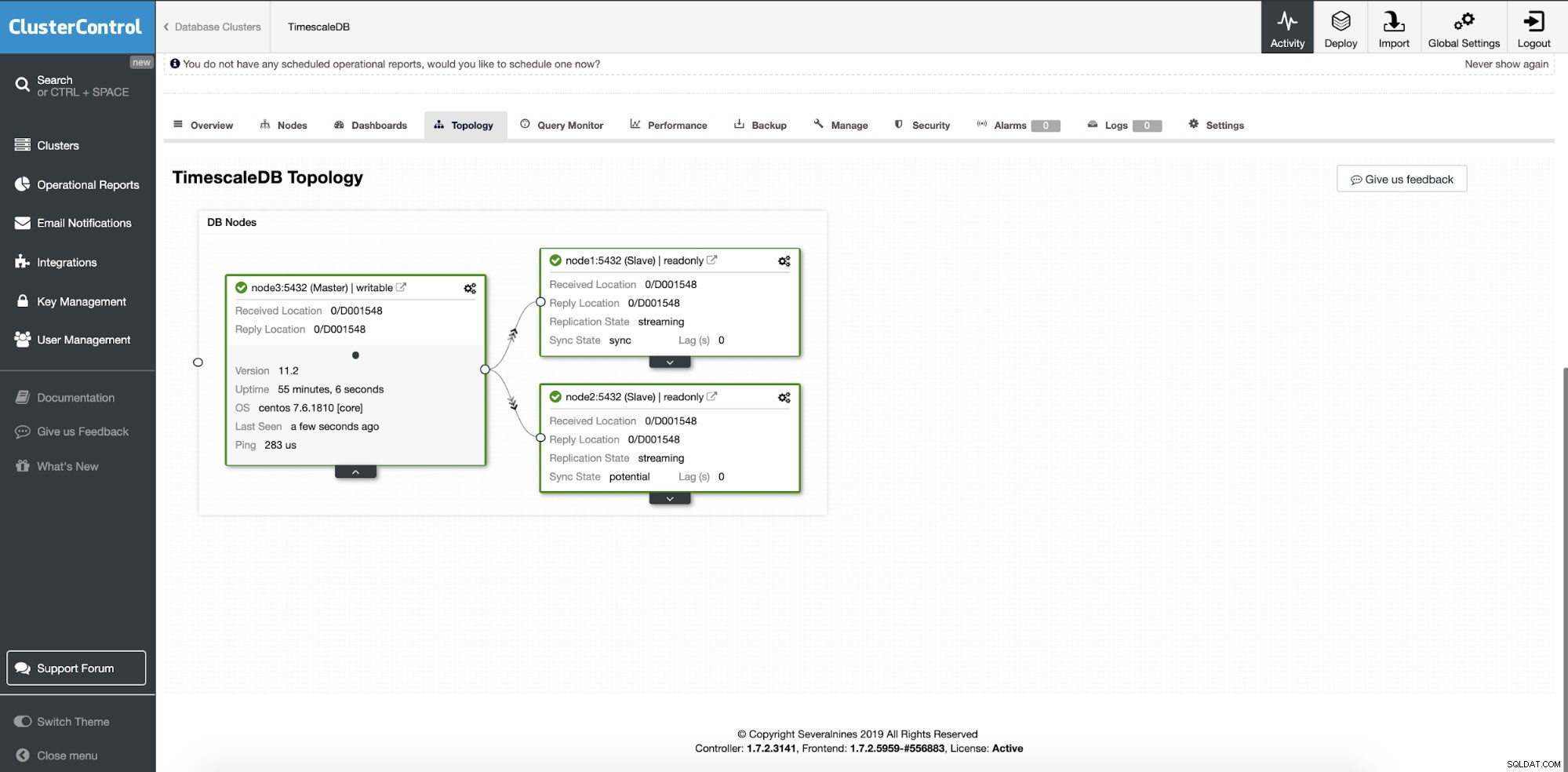 ClusterControl:Byly přidány dva uzly
ClusterControl:Byly přidány dva uzly Otázkou je, jak aplikace ví, ke kterému databázovému uzlu má přistupovat? Pro operace zápisu a čtení budeme používat HAProxy a různé porty.
V clusteru TimescaleDB vyberte z kontextové nabídky přidat nástroj pro vyrovnávání zatížení.

Nyní potřebujeme zadat umístění serveru, kde by měl být Haproxy nainstalován, jaké zásady chceme použít pro připojení k databázi a které uzly se účastní konfigurace Haproxy.
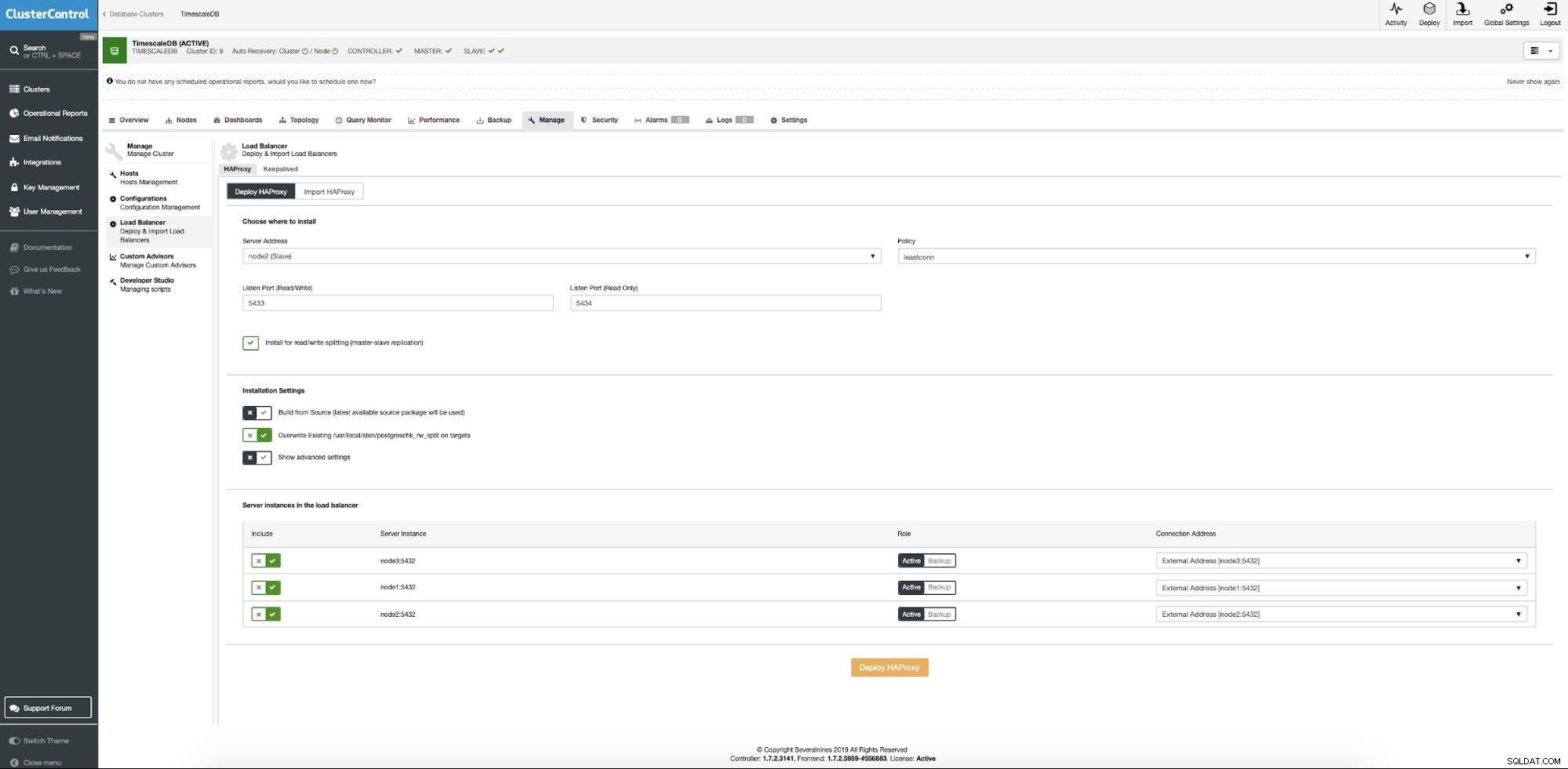
Když je vše nastaveno, stiskněte tlačítko nasazení. Po několika minutách bychom měli připravit konfiguraci clusteru. ClusterControl se postará o všechny předpoklady a konfigurace pro nasazení nástroje pro vyrovnávání zatížení.
Po úspěšném nasazení můžeme vidět topologii našeho nového clusteru; s vyvažováním zátěže a dalšími čtecími uzly. S více integrovanými uzly ClusterControl automaticky umožňuje automatické obnovení. Tímto způsobem, když hlavní uzel selže, operace převzetí služeb při selhání se sama spustí.
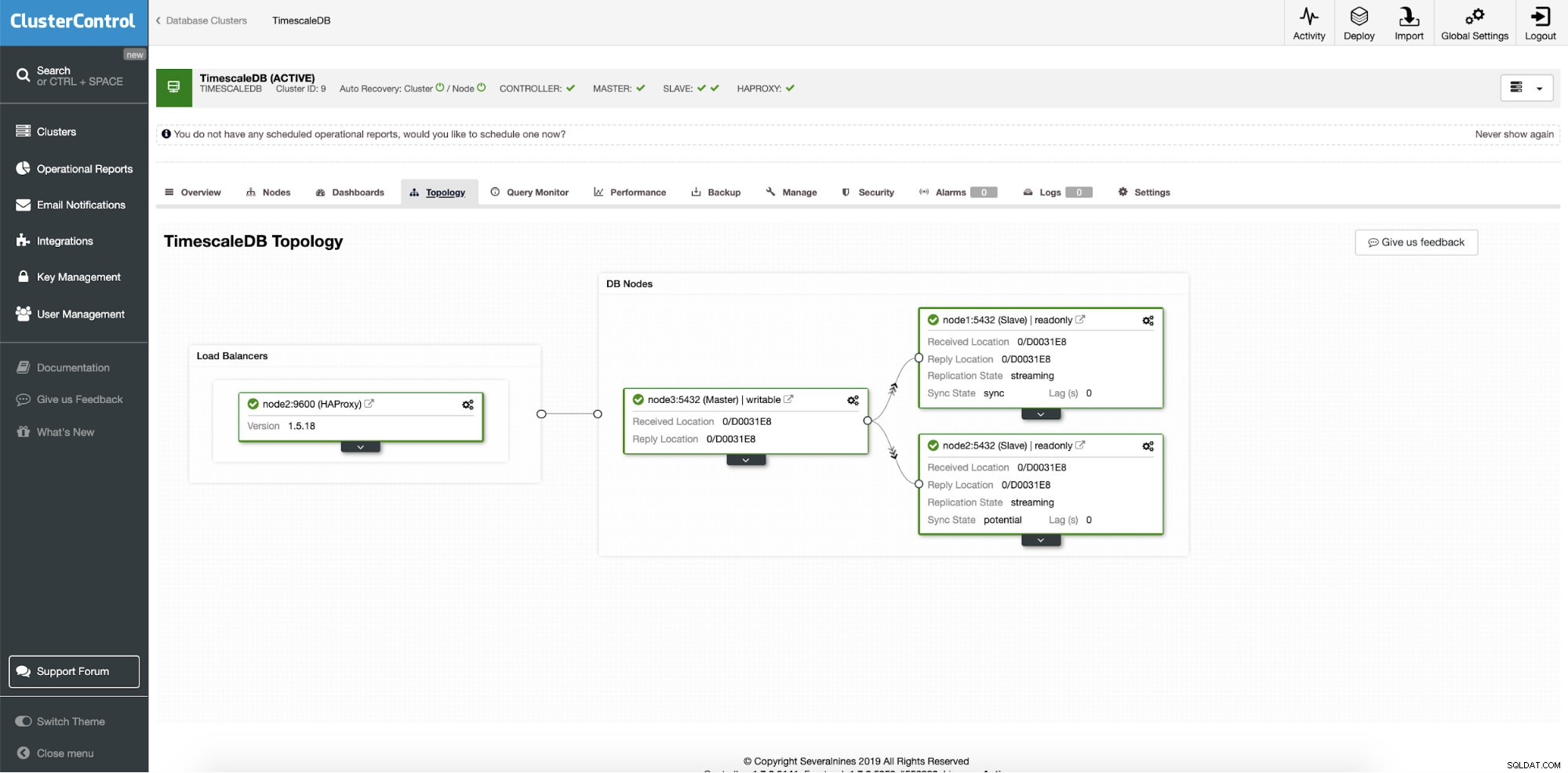 ClusterControl:Finální topologie
ClusterControl:Finální topologie Závěr
TimescaleDB je open-source databáze vynalezená, aby umožnila škálovatelnost SQL pro data časových řad. Mít automatizovaný způsob rozšíření jejich clusteru je klíčem k dosažení výkonu a efektivity. Jak jsme viděli výše, TimescaleDB můžete nyní snadno škálovat pomocí ClusterControl.