Rostoucí poptávka po systémech s vysokou dostupností a přísnými SLA nás nutí nahradit manuální postupy automatizovanými řešeními. Máte však čas a potřebné zdroje na to, abyste se sami vypořádali se složitostí operací převzetí služeb při selhání? Obětujete prostoje produkční databáze, abyste se to naučili tvrdě?
ClusterControl poskytuje pokročilou podporu pro detekci a řešení poruch. Používá jej mnoho podnikových organizací a udržuje nejkritičtější produkční systémy v provozu v režimu 24/7.
Toto řešení pro správu databází vás také podporuje s nasazením různých zátěžových proxy. Tyto proxy hrají klíčovou roli v zásobníku HA, takže není potřeba upravovat připojovací řetězec aplikace nebo záznam DNS pro přesměrování připojení aplikací na nový hlavní uzel.
Když je zjištěno selhání, ClusterControl provede veškerou práci na pozadí, aby zvolil nový hlavní server, nasadil záložní podřízené servery a nakonfiguroval nástroje pro vyrovnávání zátěže. V tomto blogu se dozvíte, jak dosáhnout automatického převzetí služeb při selhání TimescaleDB ve vašich produkčních systémech.
Nasazení celých topologií replikace
Počínaje ClusterControl 1.7.2 můžete nasadit celé nastavení replikace TimescaleDB stejným způsobem, jako byste nasadili PostgreSQL:můžete použít nabídku „Deploy Cluster“ k nasazení primárního a jednoho nebo více serverů TimescaleDB v pohotovostním režimu. Podívejme se, jak to vypadá.
Nejprve musíte definovat podrobnosti přístupu při nasazování nových clusterů pomocí ClusterControl. Vyžaduje přístup pomocí hesla root nebo sudo ke všem uzlům, na kterých bude váš nový cluster nasazen.
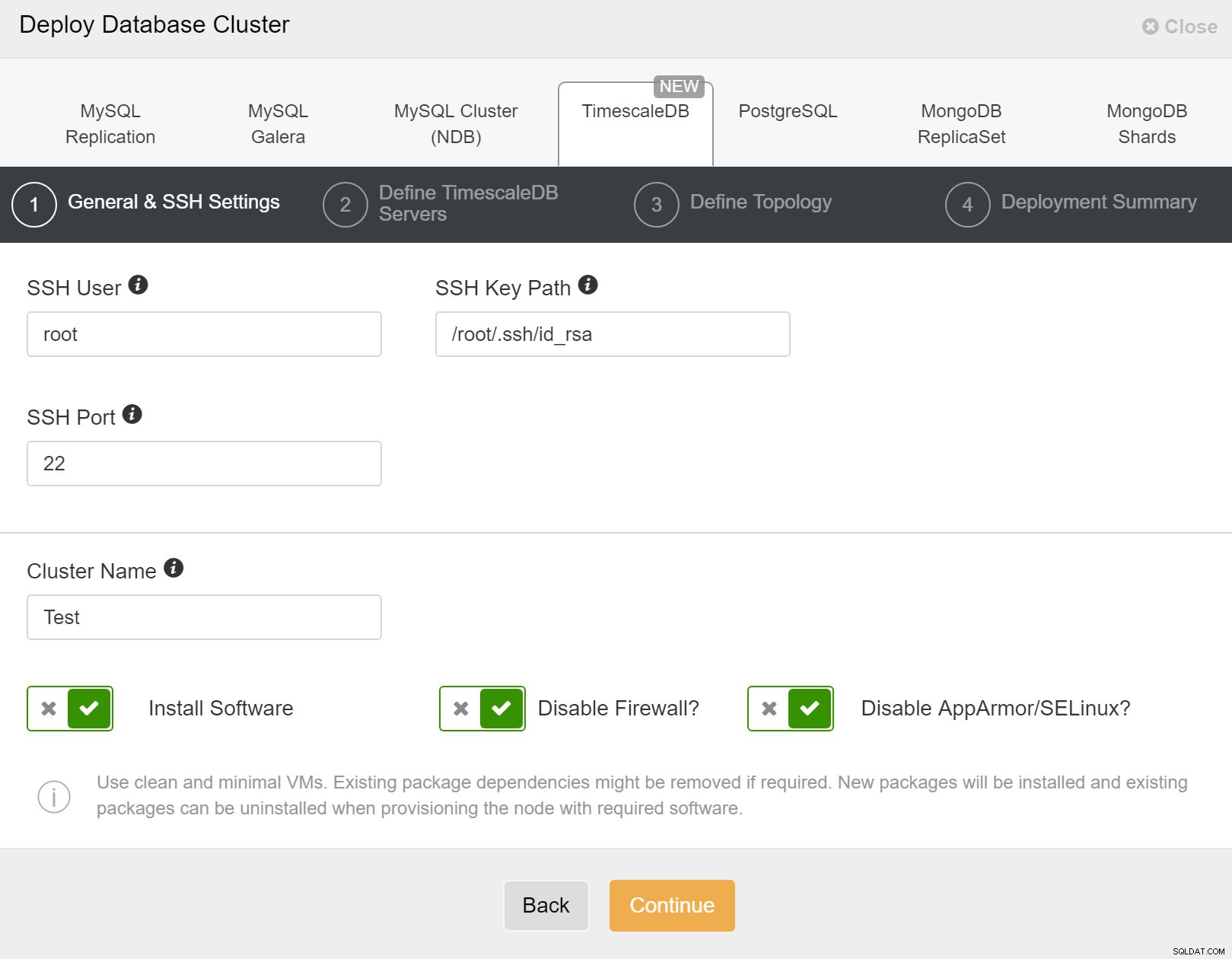 ClusterControl:Nasazení nového clusteru
ClusterControl:Nasazení nového clusteru Dále musíme definovat uživatele a heslo pro uživatele TimescaleDB.
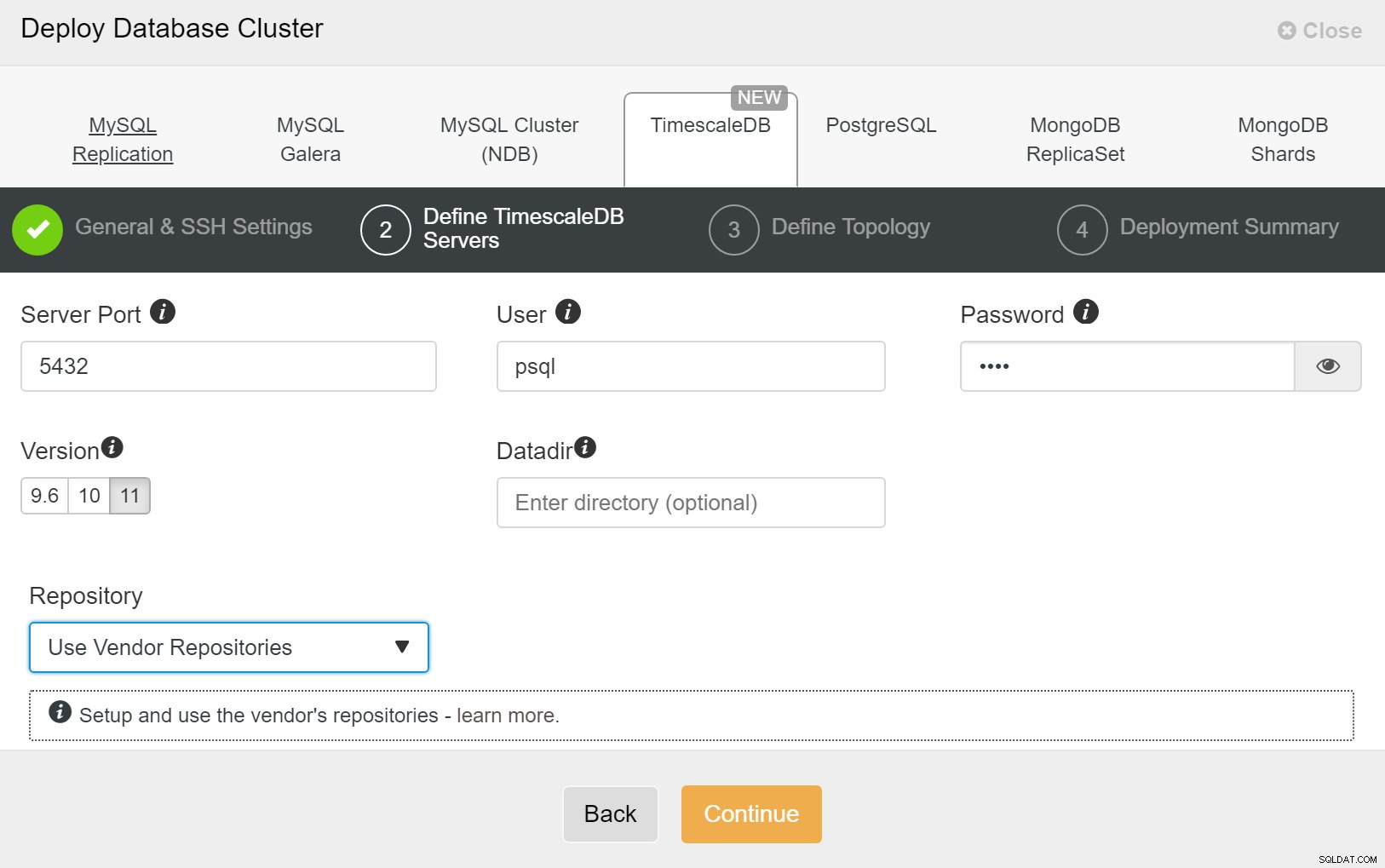 ClusterControl:Nasazení databázového clusteru
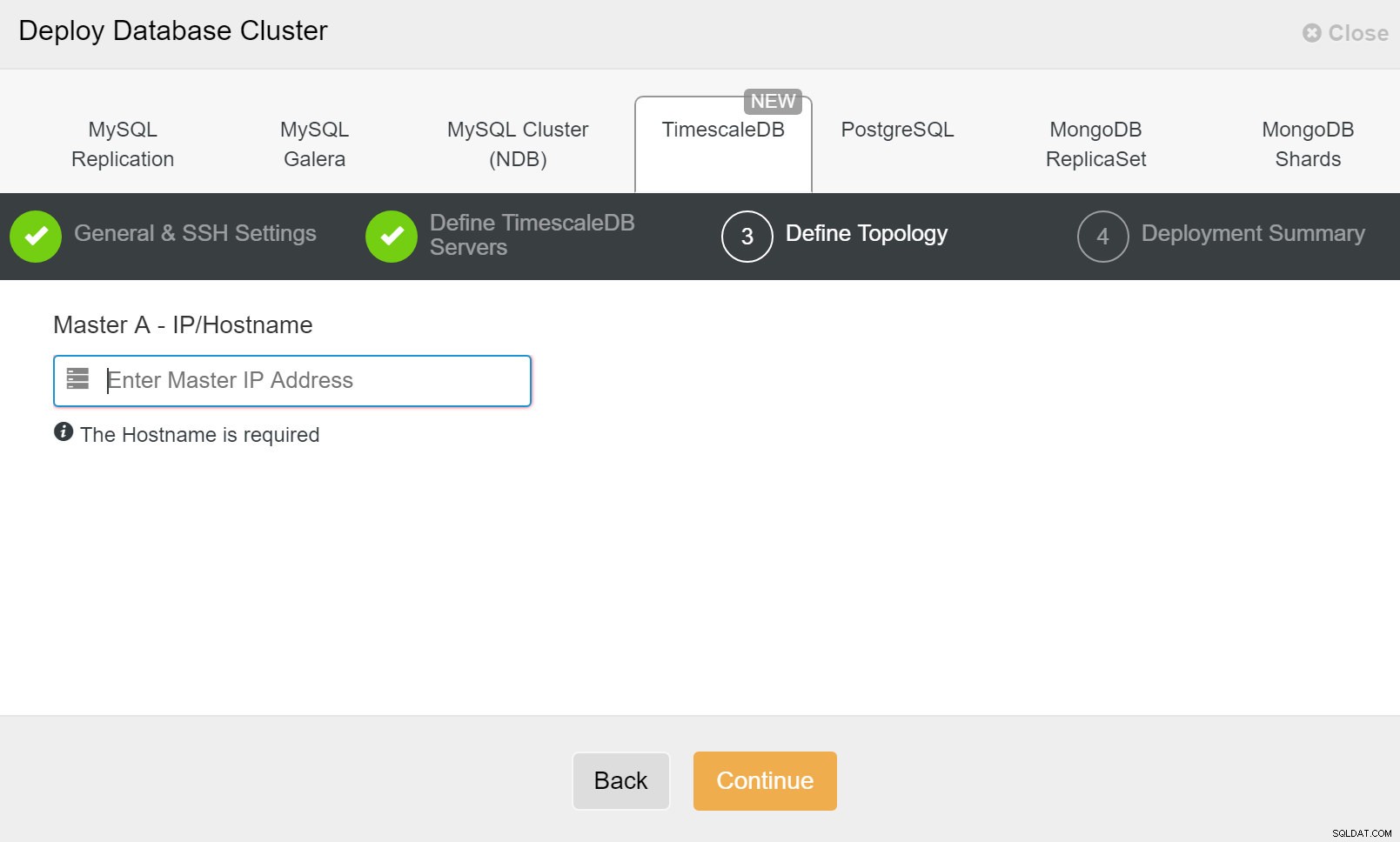
ClusterControl:Nasazení databázového clusteru Nakonec chcete definovat topologii – který hostitel by měl být primární a který hostitel by měl být nakonfigurován jako pohotovostní. Zatímco definujete hostitele v topologii, ClusterControl zkontroluje, zda přístup ssh funguje podle očekávání – to vám umožní včas zachytit jakékoli problémy s připojením. Na poslední obrazovce budete dotázáni na typ replikace synchronní nebo asynchronní.
 Nasazení ClusterControl
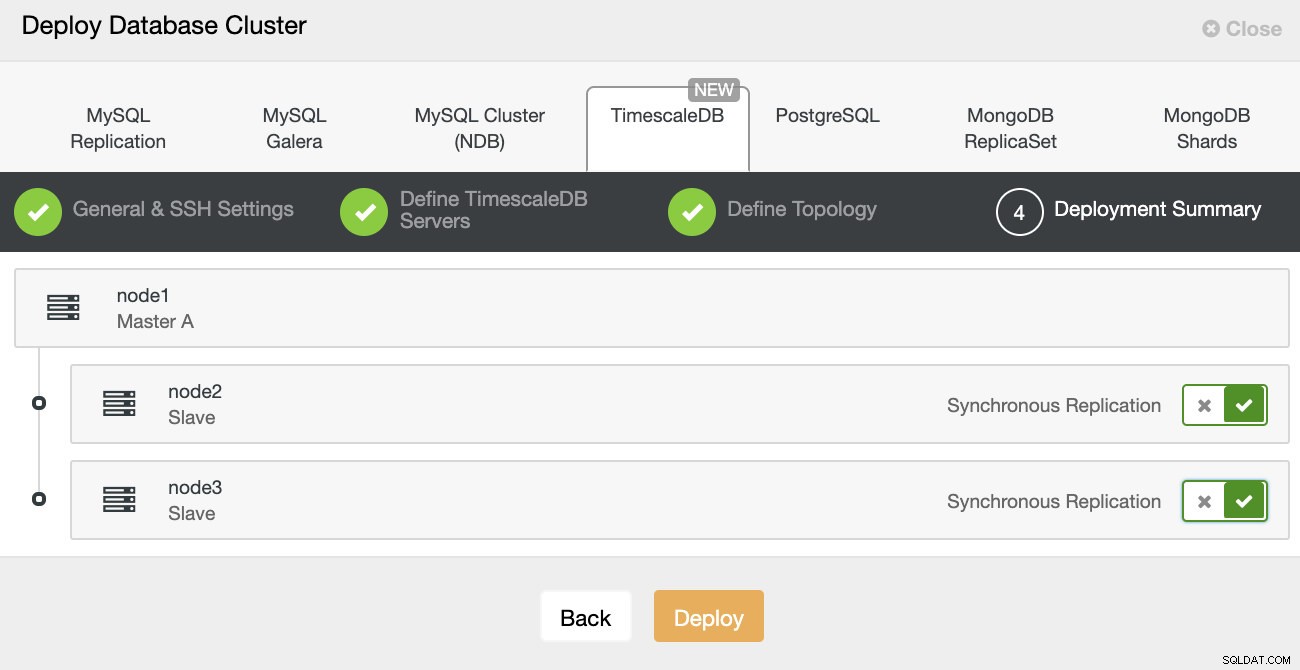
Nasazení ClusterControl To je vše, pak je otázkou zahájení nasazení. V ClusterControl se vytvoří úloha a vy budete moci sledovat průběh.
 ClusterControl:Definice topologie pro cluster TimescleDb
ClusterControl:Definice topologie pro cluster TimescleDb Po dokončení uvidíte nastavení topologie s rolemi v clusteru. Všimněte si, že jsme také přidali nástroj pro vyrovnávání zatížení (HAProxy) před instance databáze, takže automatické převzetí služeb při selhání nebude vyžadovat změny v nastavení připojení k databázi.
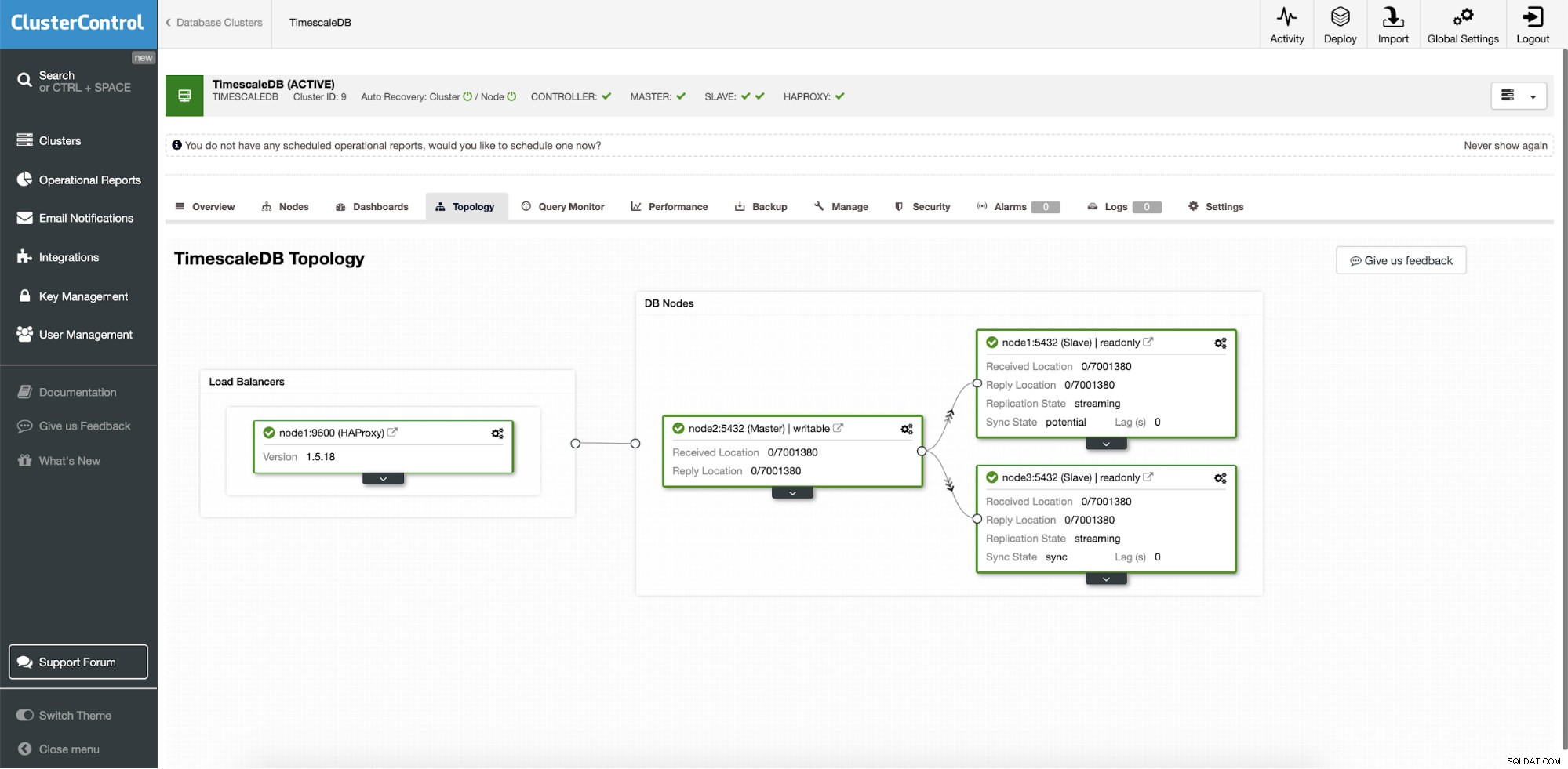 ClusterControl:Topologie
ClusterControl:Topologie Když je pomocí ClusterControl nasazena Timescale, je ve výchozím nastavení povolena automatická obnova. Stav lze zkontrolovat na liště clusteru.
 ClusterControl:Auto Recovery Cluster and Node state
ClusterControl:Auto Recovery Cluster and Node state Konfigurace převzetí služeb při selhání
Po nasazení nastavení replikace je ClusterControl schopen monitorovat nastavení a automaticky obnovit všechny neúspěšné servery. Může také organizovat změny v topologii.
Automatické převzetí služeb při selhání ClusterControl bylo navrženo s následujícími principy:
- Před převzetím služeb při selhání se ujistěte, že je hlavní server skutečně mrtvý
- Přechod při selhání pouze jednou
- Nepřebírejte na nekonzistentní slave
- Pište pouze hlavnímu serveru
- Neobnovujte automaticky neúspěšnou hlavní stránku
Díky vestavěným algoritmům lze převzetí služeb při selhání často provést velmi rychle, takže si můžete zajistit nejvyšší SLA pro vaše databázové prostředí.
Proces je konfigurovatelný. Dodává se s několika parametry, které můžete použít k přizpůsobení obnovy specifikům vašeho prostředí.
| max_replication_lag | Maximální povolené zpoždění replikace v sekundách před |
| replication_stop_on_error | Procedury převzetí služeb při selhání/přepnutí selžou, pokud dojde k chybám, které mohou způsobit ztrátu dat. Ve výchozím nastavení povoleno. 0 znamená vypnout, |
| replication_auto_rebuild_slave | Pokud je SQL THREAD zastaveno a chybový kód je nenulový, pak bude slave automaticky přestavěn. 1 znamená povolení, 0 znamená zakázání (výchozí). |
| replication_failover_blacklist | Čárkami oddělený seznam párů název hostitele:port. Servery na černé listině nebudou během převzetí služeb při selhání považovány za kandidáty. replication_failover_blacklist je ignorován, pokud je nastavena replication_failover_whitelist. |
| replication_failover_whitelist | Čárkami oddělený seznam párů název hostitele:port. Během převzetí služeb při selhání budou za kandidáty považovány pouze servery ze seznamu povolených. Pokud žádný server na seznamu povolených není dostupný (připojený/připojený), převzetí služeb při selhání se nezdaří. replication_failover_blacklist je ignorován, pokud je nastavena replication_failover_whitelist. |
Ovládání převzetí služeb při selhání
Když je detekováno selhání hlavního serveru, je vytvořen seznam hlavních kandidátů a jeden z nich je vybrán jako nový master. Je možné mít bílou listinu serverů, které mají být povýšeny na primární, a také černou listinu serverů, které nelze povýšit na primární. Zbývající podřízené jednotky jsou nyní podřízeny nové primární jednotce a stará primární jednotka není restartována.
Níže můžeme vidět simulaci selhání uzlu.
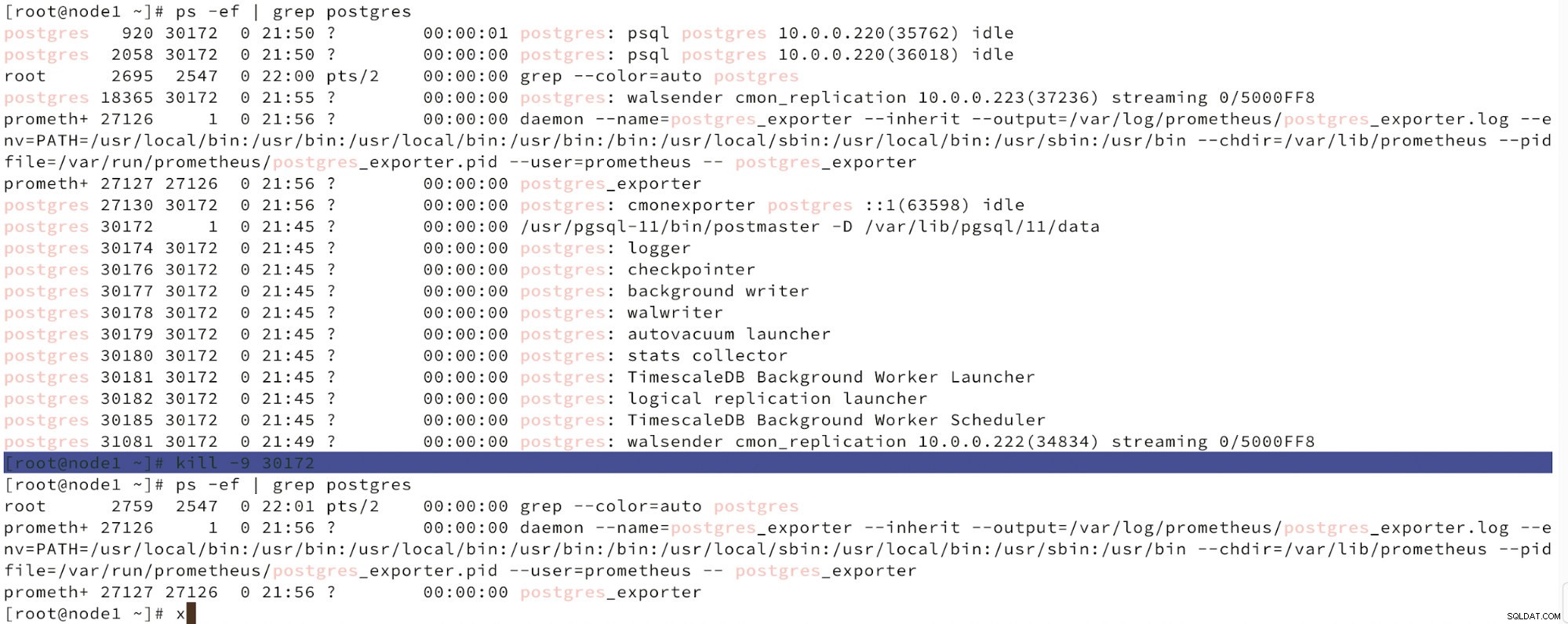 Simulace selhání hlavního uzlu pomocí zabíjení
Simulace selhání hlavního uzlu pomocí zabíjení Když je detekována porucha uzlů a je detekována automatická obnova, ClusterControl spustí úlohu k provedení převzetí služeb při selhání. Níže jsou uvedeny akce provedené k obnovení clusteru.
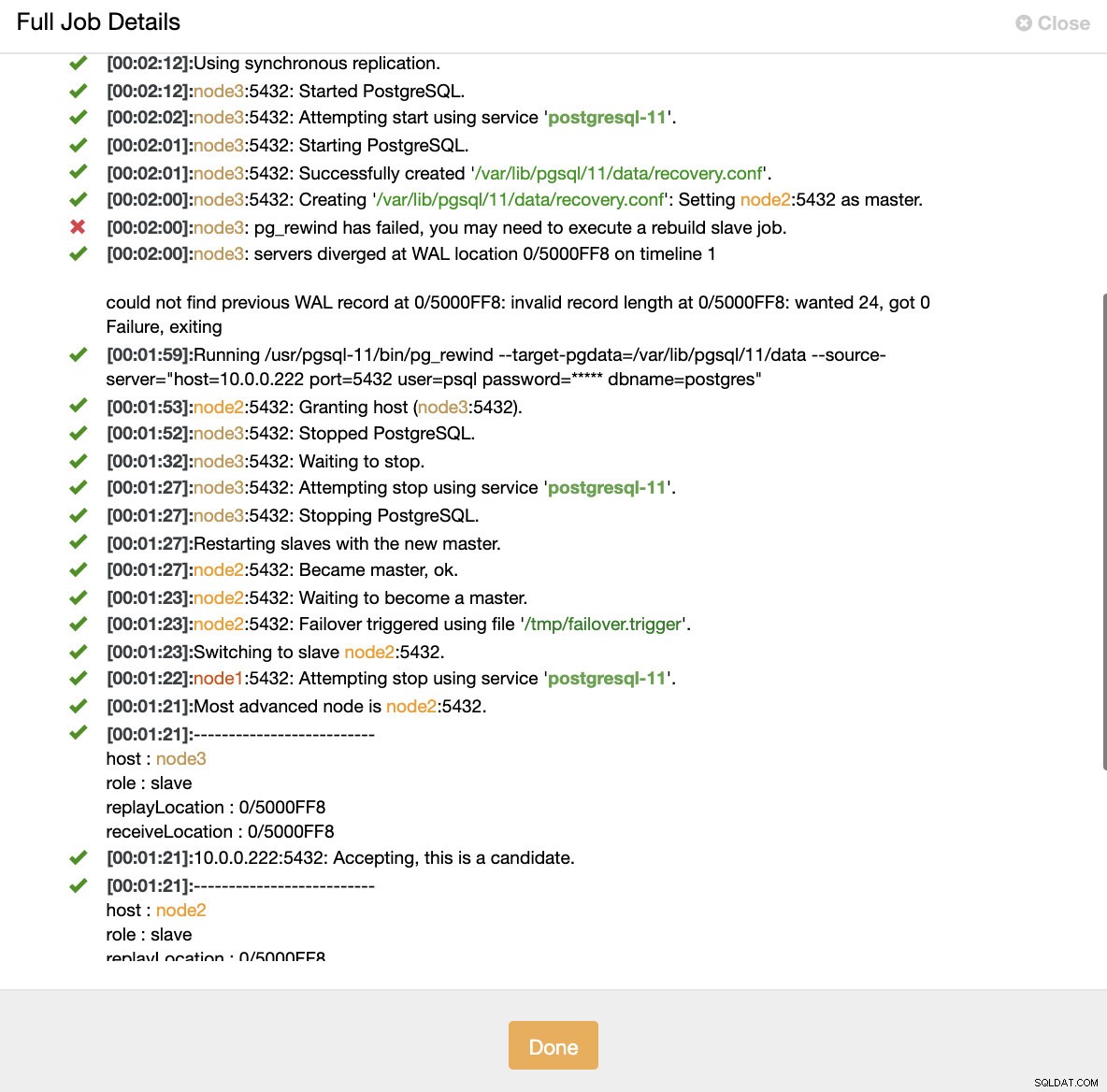 ClusterControl:Úloha spuštěna za účelem opětovného sestavení clusteru
ClusterControl:Úloha spuštěna za účelem opětovného sestavení clusteru ClusterControl záměrně udržuje starý primární server offline, protože se může stát, že některá data nebyla přenesena na záložní servery. V takovém případě je primární hostitel jediným hostitelem obsahujícím tato data a možná budete chtít chybějící data obnovit ručně. Pro ty, kteří si chtějí nechat automaticky znovu sestavit neúspěšné primární, existuje možnost v konfiguračním souboru cmon:replication_auto_rebuild_slave. Ve výchozím nastavení je zakázáno, ale když jej uživatel povolí, neúspěšný primární prvek bude znovu vytvořen jako slave nového primárního. Samozřejmě, pokud budou chybět nějaká data, která existují pouze na neúspěšném primárním disku, budou tato data ztracena.
Přestavba pohotovostních serverů
Odlišnou funkcí je úloha „Rebuild Replication Slave“, která je dostupná pro všechny podřízené (nebo záložní servery) v nastavení replikace. To lze použít například, když chcete vymazat data v pohotovostním režimu a znovu je sestavit s novou kopií dat primárního zařízení. Může být užitečné, pokud se záložní server z nějakého důvodu nemůže připojit a replikovat z primárního.
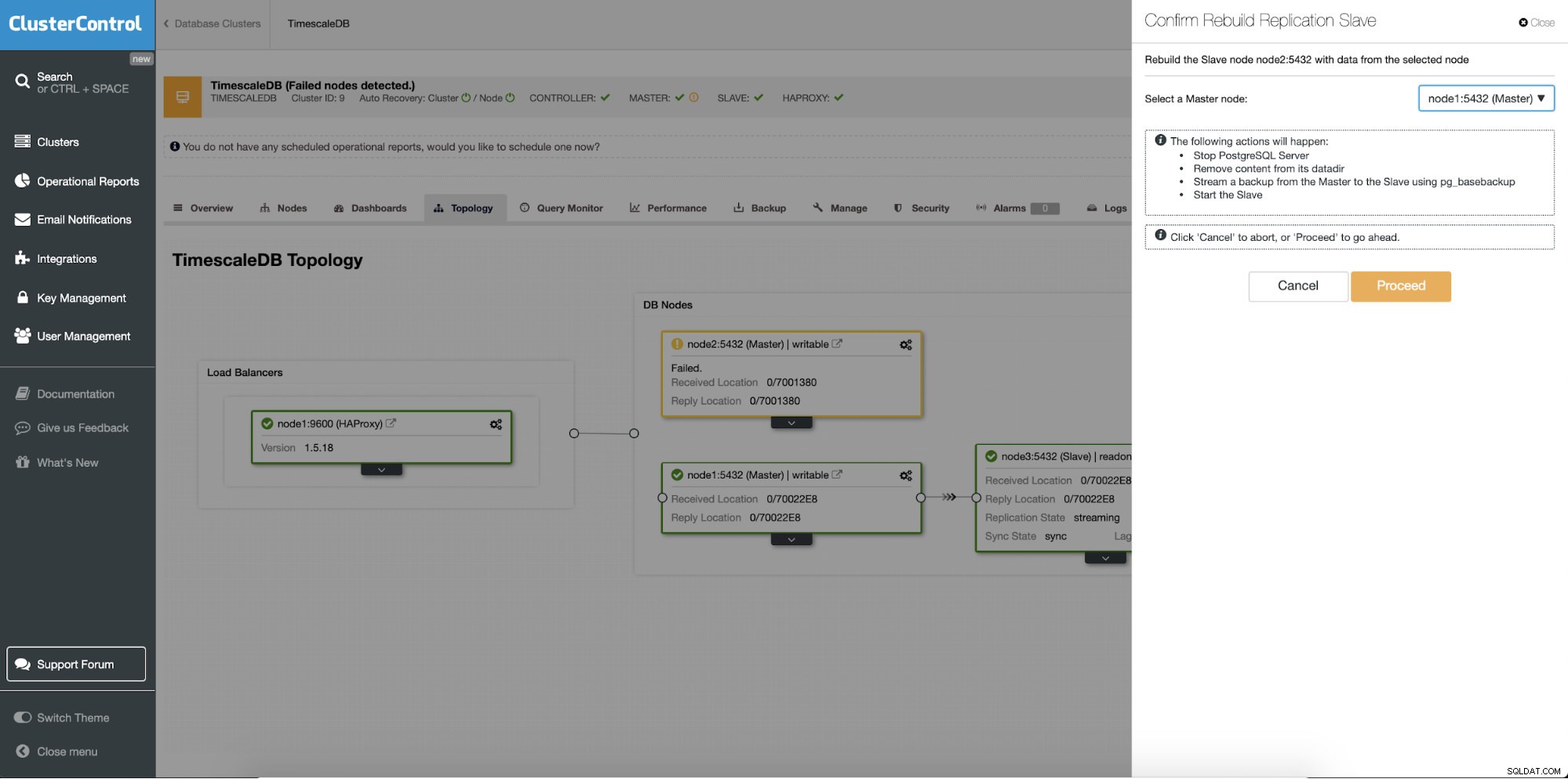 ClusterControl:Znovu sestavení replikačního slave
ClusterControl:Znovu sestavení replikačního slave  ClusterControl:Znovu sestavit slave
ClusterControl:Znovu sestavit slave