Téměř každý problém s výkonem souvisejícím s počítanými sloupci, na který jsem v průběhu let narazil, měl jednu (nebo více) z následujících hlavních příčin:
- Omezení implementace
- Nedostatek podpory nákladového modelu v optimalizátoru dotazů
- Vypočítané rozšíření definice sloupce před zahájením optimalizace
Příklad omezení implementace není schopen vytvořit filtrovaný index na vypočítaném sloupci (i když trvá). S touto kategorií problémů nemůžeme moc dělat; při čekání na vylepšení produktu musíme používat náhradní řešení.
Chybějící podpora nákladových modelů optimalizátoru znamená, že SQL Server přiřadí skalárním výpočtům malé fixní náklady bez ohledu na složitost nebo implementaci. V důsledku toho se server často rozhodne přepočítat uloženou vypočítanou hodnotu sloupce místo přímého čtení trvalé nebo indexované hodnoty. To je zvláště bolestivé, když je vypočítaný výraz drahý, například když zahrnuje volání skalární uživatelsky definované funkce.
Problémy s rozšířením definic jsou o něco více zapojeny a mají dalekosáhlé účinky.
Problémy rozšiřování vypočítaných sloupců
SQL Server normálně rozšíří vypočítané sloupce do jejich podkladových definic během fáze vazby normalizace dotazu. Toto je velmi raná fáze v procesu kompilace dotazů, dlouho předtím, než jsou učiněna jakákoli rozhodnutí o výběru plánu (včetně triviálního plánu).
Teoreticky by provedení časné expanze mohlo umožnit optimalizace, které by jinak byly promeškany. Optimalizátor může být například schopen použít zjednodušení na základě jiných informací v dotazu a metadatech (např. omezení). Jedná se o stejný druh uvažování, který vede k rozšíření definic zobrazení (pokud NOEXPAND používá se nápověda).
Později v procesu kompilace (ale ještě předtím, než byl zvažován triviální plán), optimalizátor hledá přiřazení zpětných výrazů k trvalým nebo indexovaným vypočítaným sloupcům. Problém je v tom, že aktivity optimalizátoru mezitím mohly změnit rozšířené výrazy tak, že zpětná shoda již není možná.
Když k tomu dojde, konečný plán provádění vypadá, jako by optimalizátor promeškal „zřejmou“ příležitost použít trvalý nebo indexovaný vypočítaný sloupec. V prováděcích plánech je málo podrobností, které mohou pomoci určit příčinu, což z tohoto problému činí potenciálně frustrující problém k ladění a opravě.
Přiřazování výrazů k vypočítaným sloupcům
Zvláště stojí za to ujasnit si, že zde existují dva samostatné procesy:
- Včasné rozšíření počítaných sloupců; a
- Pozdější pokusy o shodu výrazů s vypočítanými sloupci.
Zejména si uvědomte, že jakýkoli výraz dotazu může být později přiřazen k vhodnému vypočítanému sloupci, nikoli pouze výrazům, které vznikly rozšířením vypočítaných sloupců.
Shoda vypočítaného sloupcového výrazu může umožnit vylepšení plánu, i když text původního dotazu nelze upravit. Například vytvoření vypočítaného sloupce, který odpovídá známému výrazu dotazu, umožňuje optimalizátoru použít statistiky a indexy spojené s vypočítaným sloupcem. Tato funkce je koncepčně podobná srovnávání indexovaných pohledů v Enterprise Edition. Vypočítané porovnávání sloupců je funkční ve všech edicích.
Z praktického hlediska je moje vlastní zkušenost taková, že přiřazování obecných výrazů dotazů k vypočteným sloupcům může skutečně prospět výkonu, efektivitě a stabilitě plánu provádění. Na druhou stranu jsem jen zřídka (pokud vůbec) zjistil, že by se vypočítaná expanze sloupců vyplatila. Zdá se, že to nikdy nepřinese žádné užitečné optimalizace.
Vypočítaná použití sloupců
Vypočítané sloupce, které nejsou ani jedno trvalé ani indexované mají platná použití. Mohou například podporovat automatickou statistiku, pokud je sloupec deterministický a přesný (žádné prvky s pohyblivou řádovou čárkou). Lze je také použít k úspoře místa v úložišti (na úkor trochu dalšího využití runtime procesoru). Jako poslední příklad mohou poskytnout úhledný způsob, jak zajistit, že jednoduchý výpočet bude vždy proveden správně, místo aby byl pokaždé explicitně zapsán v dotazech.
Přetrvává počítané sloupce byly přidány do produktu specificky, aby umožnily vytvoření indexů na deterministických, ale „nepřesných“ sloupcích (s plovoucí desetinnou čárkou). Podle mých zkušeností je toto zamýšlené použití poměrně vzácné. Možná je to jednoduše proto, že se s daty s pohyblivou řádovou čárkou příliš nesetkávám.
Kromě indexů s pohyblivou řádovou čárkou jsou trvalé sloupce docela běžné. Do určité míry to může být způsobeno tím, že nezkušení uživatelé předpokládají, že vypočítaný sloupec musí být vždy zachován, než může být indexován. Zkušenější uživatelé mohou používat trvalé sloupce jednoduše proto, že zjistili, že výkon bývá tímto způsobem lepší.
Indexováno počítané sloupce (přetrvávající nebo ne) lze použít k uspořádání a efektivní metodě přístupu. Může být užitečné uložit vypočítanou hodnotu do indexu, aniž by byla uložena v základní tabulce. Stejně tak mohou být vhodně vypočítané sloupce zahrnuty do indexů spíše než jako klíčové sloupce.
Nízký výkon
Hlavní příčinou nízkého výkonu je jednoduché selhání použití indexované nebo trvalé vypočítané hodnoty sloupce podle očekávání. Ztratil jsem počet otázek, které jsem za ta léta měl a ptala se, proč by si optimalizátor zvolil hrozný plán provádění, když existuje zjevně lepší plán využívající indexovaný nebo trvalý vypočítaný sloupec.
Přesná příčina se v každém případě liší, ale téměř vždy jde buď o chybné rozhodnutí na základě nákladů (protože skalárům jsou přiřazeny nízké fixní náklady); nebo selhání přiřazení rozšířeného výrazu zpět k trvalému vypočítanému sloupci nebo indexu.
Selhání zpětného dorovnání jsou pro mě obzvláště zajímavé, protože často zahrnují složité interakce s ortogonálními funkcemi enginu. Stejně tak často selhání „zpětného spárování“ zanechá výraz (spíše než sloupec) na pozici v interním stromu dotazů, která brání shodě důležitého optimalizačního pravidla. V obou případech je výsledek stejný:suboptimální plán realizace.
Nyní si myslím, že je spravedlivé říci, že lidé obecně indexují nebo přetrvávají vypočítaný sloupec se silným očekáváním, že uložená hodnota bude skutečně použita. Může to být docela šok, když SQL Server pokaždé přepočítává základní výraz, zatímco ignoruje záměrně poskytnutou uloženou hodnotu. Lidé se ne vždy příliš zajímají o interní interakce a nedostatky modelu nákladů, které vedly k nežádoucímu výsledku. I tam, kde existují náhradní řešení, jejich objevení a testování vyžaduje čas, dovednosti a úsilí.
Stručně řečeno:mnoho lidí by prostě dalo přednost tomu, aby SQL Server používal trvalou nebo indexovanou hodnotu. Vždy.
Nová možnost
Historicky neexistoval způsob, jak přinutit SQL Server, aby vždy používal uloženou hodnotu (žádný ekvivalent NOEXPAND tip na názory). Za určitých okolností bude průvodce plánem fungovat, ale ne vždy je možné nejprve vygenerovat požadovaný tvar plánu a ne všechny prvky plánu a pozice lze vynutit (například filtry a výpočetní skaláry).
Stále neexistuje žádné úhledné, plně zdokumentované řešení, ale nedávná aktualizace SQL Server 2016 poskytla zajímavý nový přístup. Vztahuje se na instance SQL Server 2016 opravené alespoň kumulativní aktualizací 2 pro SQL Server 2016 SP1 nebo kumulativní aktualizací 4 pro SQL Server 2016 RTM.
Příslušná aktualizace je zdokumentována v:OPRAVA:Nelze znovu sestavit oddíl online pro tabulku, která obsahuje vypočítaný sloupec rozdělení na SQL Server 2016
Jako často u podpůrné dokumentace, tato neříká přesně, co bylo v enginu změněno, aby se problém vyřešil. Soudě podle názvu a popisu to rozhodně nevypadá příliš relevantní pro naše současné obavy. Tato oprava nicméně zavádí nový podporovaný příznak trasování 176 , která se kontroluje pomocí kódové metody nazvané FDontExpandPersistedCC . Jak název metody napovídá, zabrání to rozšíření trvalého vypočítaného sloupce.
Existují tři důležitá upozornění:
- Vypočítaný sloupec musí být trvalý . I když je sloupec indexován, musí být zachován.
- Zpětná shoda z obecných výrazů dotazu s trvalými vypočítanými sloupci je zakázaná .
- Dokumentace nepopisuje funkci příznaku trasování a nepředepisuje jej pro žádné jiné použití. Pokud se rozhodnete použít příznak trasování 176, abyste zabránili rozšiřování trvalých vypočítaných sloupců, je to na vaše vlastní riziko.
Tento příznak trasování je účinný při spuštění –T možnost, jak v globálním rozsahu, tak v rozsahu relace pomocí DBCC TRACEON a na dotaz pomocí OPTION (QUERYTRACEON) .
Příklad
Toto je zjednodušená verze otázky (založené na skutečném problému), na kterou jsem před několika lety odpověděl na serveru Database Administrators Stack Exchange. Definice tabulky obsahuje trvalý vypočítaný sloupec:
CREATE TABLE dbo.T( ID celé číslo IDENTITA NENÍ NULL, A varchar(20) NOT NULL, B varchar(20) NOT NULL, C varchar(20) NOT NULL, D datum NULL, Vypočteno JAKO A + '-' + B + '-' + C PERSISTED, CONSTRAINT PK_T_ID PRIMÁRNÍ KLÍČ SE SLUSTROVANÝ (ID),);GOINSERT dbo.T WITH (TABLOCKX) (A, B, C, D)SELECT A =STR(SV.číslo % 10, 2 ), B =STR(SV.číslo % 20, 2), C =STR(SV.číslo % 30, 2), D =DATEADD(DEN, 0 - SV.číslo, SYSUTCDATETIME())FROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P';
Dotaz níže vrátí všechny řádky z tabulky v určitém pořadí a zároveň vrátí další hodnotu sloupce D ve stejném pořadí:
VYBERTE T1.ID, T1.Vypočteno, T1.D, DalšíD =( VYBERTE NAHORU (1) t2.D Z dbo.T JAKO T2 KDE T2.Vypočítáno =T1.Vypočteno A T2.D> T1.D POŘADÍ OD T2.D ASC )OD dbo.T AS T1ORDER BY T1.Computed, T1.D;
Zřejmý krycí index pro podporu konečného řazení a vyhledávání v dílčím dotazu je:
VYTVOŘTE UNIKÁTNÍ NENCLUSTEROVANÝ INDEX IX_T_Computed_D_IDON dbo.T (vypočteno, D, ID);
Plán provádění dodaný optimalizátorem je překvapivý a neuspokojivý:
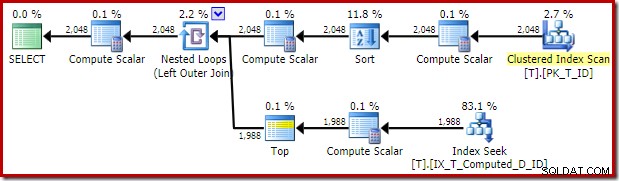
Index Seek na vnitřní straně Nested Loops Join se zdá být v pořádku. Clustered Index Scan and Sort na vnějším vstupu je však neočekávaný. Doufali bychom, že se místo toho dočkáme uspořádaného skenování našeho krycího neshlukovaného indexu.
Můžeme přinutit optimalizátor, aby použil neshlukovaný index s nápovědou k tabulce:
VYBERTE T1.ID, T1.Vypočteno, T1.D, DalšíD =( VYBERTE NAHORU (1) t2.D Z dbo.T JAKO T2 KDE T2.Vypočítáno =T1.Vypočteno A T2.D> T1.D POŘADÍ BY T2.D ASC )OD dbo.T AS T1 S (INDEX(IX_T_Computed_D_ID)) -- Novinka! ORDER BY T1.Computed, T1.D;
Výsledný plán provádění je:
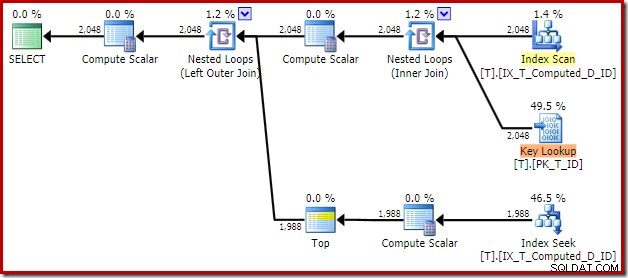
Skenování neklastrovaného indexu odstraní řazení, ale přidá vyhledávání klíčů! Vyhledávání v tomto novém plánu jsou překvapivá, vzhledem k tomu, že náš index rozhodně pokrývá všechny sloupce potřebné pro dotaz.
Při pohledu na vlastnosti operátoru vyhledávání klíčů:
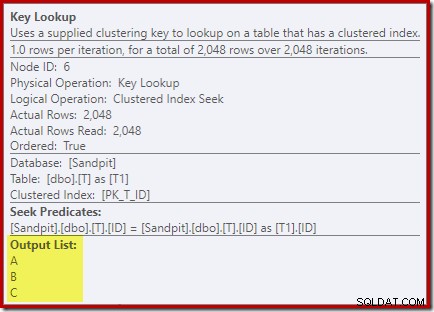
Z nějakého důvodu se optimalizátor rozhodl, že tři sloupce, které nejsou uvedeny v dotazu, je třeba načíst ze základní tabulky (protože nejsou přítomny v našem neklastrovaném indexu podle návrhu).
Když se rozhlédneme po prováděcím plánu, zjistíme, že vyhledané sloupce potřebuje vnitřní strana Index Seek:

První část tohoto predikátu vyhledávání odpovídá korelaci T2.Computed = T1.Computed v původním dotazu. Optimalizátor rozšířil definice obou počítaných sloupců, ale podařilo se mu vrátit zpět pouze trvalý a indexovaný počítaný sloupec pro vnitřní boční alias T1 . Opuštění T2 reference expandovala vedlo k tomu, že vnější strana spojení musela poskytnout základní sloupce tabulky (A , B a C ) potřebné k výpočtu tohoto výrazu pro každý řádek.
Jak už to někdy bývá, je možné tento dotaz přepsat tak, aby problém zmizel (jedna možnost je uvedena v mé staré odpovědi na otázku Stack Exchange). Pomocí SQL Server 2016 můžeme také vyzkoušet příznak trasování 176, abychom zabránili rozbalení vypočítaných sloupců:
VYBERTE T1.ID, T1.Vypočteno, T1.D, DalšíD =( VYBERTE NAHORU (1) t2.D Z dbo.T JAKO T2 KDE T2.Vypočítáno =T1.Vypočteno A T2.D> T1.D POŘADÍ BY T2.D ASC )OD dbo.T AS T1ORDER BY T1.Computed, T1.DOPTION (QUERYTRACEON 176); -- Novinka!
Prováděcí plán je nyní mnohem vylepšen:
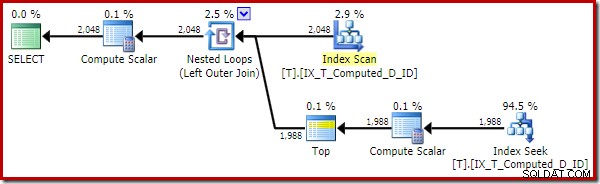
Tento plán provádění obsahuje pouze odkazy na vypočítané sloupce. Compute Scalars nedělají nic užitečného a byly by vyčištěny, kdyby byl optimalizátor v domě trochu uklizenější.
Důležitým bodem je, že optimální index je nyní používán správně a bylo odstraněno řazení a vyhledávání klíčů. To vše tím, že zabráníme SQL Serveru dělat něco, co bychom od něj nikdy nečekali (rozšíření trvalého a indexovaného vypočítaného sloupce).
Pomocí LEAD
Původní otázka Stack Exchange byla zaměřena na SQL Server 2008, kde LEAD není k dispozici. Zkusme vyjádřit požadavek na SQL Server 2016 pomocí novější syntaxe:
Plán provádění SQL Server 2016 je:
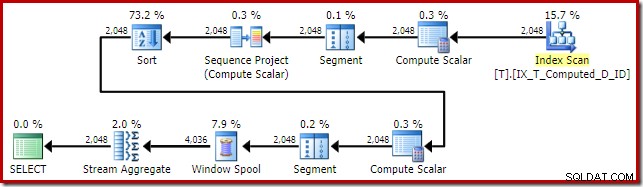
Tento půdorysný tvar je zcela typický pro jednoduchou funkci okna v režimu řádků. Jedinou neočekávanou položkou je operátor Sort uprostřed. Pokud by byla datová sada velká, toto řazení by mohlo mít velký dopad na výkon a využití paměti.
Problémem je opět vypočítaná expanze sloupců. V tomto případě je jeden z rozšířených výrazů umístěn v pozici, která brání normální logice optimalizátoru zjednodušit řazení.
Pokus o přesně stejný dotaz s příznakem trasování 176:
Vytvoří plán:
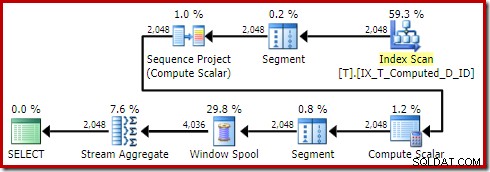
Sort zmizel, jak měl. Všimněte si také, že tento dotaz byl vhodný pro triviální plán, který se zcela vyhýbá optimalizaci založené na nákladech.
Zakázáno porovnávání obecných výrazů
Jednou z dříve zmíněných námitek bylo, že příznak trasování 176 také zakazuje shodu výrazů ve zdrojovém dotazu s trvalými vypočítanými sloupci.
Pro ilustraci zvažte následující verzi příkladu dotazu. LEAD výpočet byl odstraněn a odkazy na vypočítaný sloupec v SELECT a ORDER BY klauzule byly nahrazeny základními výrazy. Nejprve jej spusťte bez příznaku trasování 176:
VYBERTE T1.ID, Vypočteno =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.C;
Výrazy jsou porovnávány s trvalým vypočítaným sloupcem a plán provádění je jednoduchým uspořádaným skenováním neshlukovaného indexu:
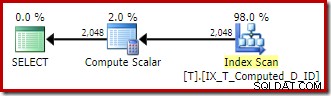
Compute Scalar tam je opět jen pozůstatek architektonického odpadu.
Nyní zkuste stejný dotaz s povoleným příznakem trasování 176:
VYBERTE T1.ID, Vypočteno =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.COPTION (QUERYTRACEON 176); -- Novinka!
Nový plán provádění je:
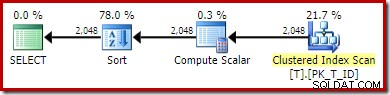
Skenování indexu bez clusterů bylo nahrazeno skenováním indexu s clustery. Compute Scalar vyhodnotí výraz a Sort seřadí podle výsledku. Optimalizátor nemůže používat trvalou hodnotu ani neshlukovaný index, protože nemá možnost přiřazovat výrazy k trvalým vypočítaným sloupcům.
Upozorňujeme, že omezení shody výrazů se vztahuje pouze na trvalé vypočítané sloupce, když je aktivní příznak trasování 176. Pokud uděláme vypočítaný sloupec indexovaný, ale netrvalý, porovnávání výrazů funguje správně.
Abychom odstranili trvalý atribut, musíme nejprve zrušit neklastrovaný index. Jakmile je změna provedena, můžeme index vrátit rovnou zpět (protože výraz je deterministický a přesný):
PUSTIT INDEX IX_T_Computed_D_ID NA dbo.T;BRANKÁŘSKÁ TABULKA dbo.TALTER SLOUPEC VypočítánDROP PERSISTED;GCREATE UNIQUE NENCLUSTERED INDEX IX_T_Computed_D_IDON dbo.T (vypočteno, D, ID);
Optimalizátor nyní nemá žádné problémy s přiřazování výrazu dotazu k vypočítanému sloupci, když je aktivní příznak trasování 176:
-- Vypočítaný sloupec již nepřetrvává-- ale stále indexován. TF 176 aktivní.VYBRAT T1.ID, Vypočteno =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T JAKO T1ORDER BY T1.A + '-' + T1. B + '-' + T1.COPTION (QUERYTRACEON 176);
Plán provádění se vrátí k optimálnímu skenování indexu bez klastrů bez řazení:
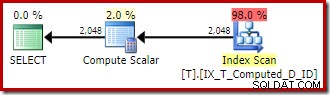
Abychom to shrnuli:Příznak trasování 176 zabraňuje trvalé expanzi vypočítaného sloupce. Jako vedlejší efekt to také zabraňuje přiřazování výrazu dotazu pouze k trvalým vypočítaným sloupcům.
Metadata schématu se načtou pouze jednou, během fáze vazby. Příznak trasování 176 zabraňuje expanzi, takže vypočítaná definice sloupce není v tu chvíli načtena. Pozdější porovnávání výrazů se sloupci nemůže fungovat bez vypočítané definice sloupce, se kterou se má porovnávat.
Počáteční načtení metadat přináší všechny sloupce, nejen ty, na které odkazuje dotaz (optimalizace se provádí později). Díky tomu jsou všechny vypočítané sloupce dostupné pro párování, což je obecně dobrá věc. Bohužel, pokud jeden z načtených počítaných sloupců obsahuje skalární uživatelsky definovanou funkci, její přítomnost znemožní paralelismus pro celý dotaz, i když se problematický sloupec nepoužívá. Příznak trasování 176 může pomoci i s tím, pokud je dotyčný sloupec trvalý. Tím, že se definice nenačte, nikdy není přítomna skalární uživatelsky definovaná funkce, takže paralelismus není zakázán.
Poslední myšlenky
Zdá se mi, že svět SQL Serveru je lepší místo, pokud optimalizátor zpracovává trvalé nebo indexované vypočítané sloupce spíše jako běžné sloupce. Téměř ve všech případech by to lépe odpovídalo očekáváním vývojářů než současné uspořádání. Rozšíření vypočítaných sloupců do jejich základních výrazů a pozdější pokusy o jejich přiřazení zpět nejsou v praxi tak úspěšné, jak by teorie mohla naznačovat.
Dokud SQL Server neposkytne specifickou podporu, která zabrání trvalému nebo indexovanému rozšiřování vypočítaných sloupců, nový příznak trasování 176 je pro uživatele SQL Server 2016 lákavou možností, i když nedokonalou. Je trochu nešťastné, že jako vedlejší efekt zakazuje shodu obecných výrazů. Je také škoda, že vypočítaný sloupec musí být při indexování zachován. Pak existuje riziko použití příznaku trasování pro jiný než zdokumentovaný účel, který je třeba zvážit.
Je spravedlivé říci, že většinu problémů s počítanými dotazy na sloupce lze nakonec vyřešit jinými způsoby, pokud bude dostatek času, úsilí a odborných znalostí. Na druhou stranu se zdá, že příznak trasování 176 často funguje jako kouzlo. Volba, jak se říká, je na vás.
Na závěr uvádíme některé zajímavé problémy s vypočítanými sloupci, které využívají příznak trasování 176:
- Nepoužívá se vypočítaný index sloupce
- Vypočítaný sloupec PERSISTED se nepoužívá při rozdělování funkcí okna
- Přetrvávající vypočítaný sloupec způsobující skenování
- Vypočítaný index sloupce se nepoužívá s MAX datovými typy
- Závažný problém s výkonem s přetrvávajícími vypočítanými sloupci a spojeními
- Proč SQL Server "vypočítává skalární", když VYBERU trvalý vypočítaný sloupec?
- Používají se základní sloupce namísto trvalých vypočítaných sloupců podle modulu
- Vypočítaný sloupec s UDF zakáže paralelismus pro dotazy na *ostatní* sloupce