Poznámka:Tento příspěvek byl původně publikován pouze v naší elektronické knize, High Performance Techniques for SQL Server, Volume 2. O našich elektronických knihách se můžete dozvědět zde.
Shrnutí:Tento článek zkoumá některé překvapivé chování spouštěčů INSTEAD OF a odhaluje závažnou chybu odhadu mohutnosti v SQL Server 2014.
Spouštěče a verzování řádků
Pouze spouštěče DML AFTER používají verzování řádků (v SQL Server 2005 a novější) k poskytování vložených a smazáno pseudo-tabulky uvnitř spouštěcí procedury. Tento bod není jasně uveden ve velké části oficiální dokumentace. Na většině míst dokumentace jednoduše říká, že k vytvoření vložené se používá verzování řádků a smazáno tabulky ve spouštěčích bez kvalifikace (příklady níže):
Použití prostředků pro správu verzí
Porozumění úrovním izolace na základě správy verzí
Řízení spouštění spouštění při hromadném importu dat
Původní verze těchto záznamů byly pravděpodobně napsány předtím, než byly do produktu přidány spouštěče INSTEAD OF, a nikdy nebyly aktualizovány. Buď to, nebo je to jednoduché (ale opakované) přehlédnutí.
Každopádně způsob, jakým verzování řádků funguje se spouštěči AFTER, je docela intuitivní. Tyto spouštěče se spouštějí po příslušné úpravy byly provedeny, takže je snadné vidět, jak udržování verzí upravených řádků umožňuje databázovému stroji poskytovat vložené a smazáno pseudotabulky. smazáno pseudotabulka je vytvořena z verzí dotčených řádků před provedením úprav; vložené pseudotabulka je vytvořena z verzí ovlivněných řádků v době zahájení procedury spouštění.
Místo spouštěčů
Spouštěče INSTEAD OF jsou jiné, protože tento typ spouštěčů DML zcela nahrazuje spuštěnou akci. vloženo a smazáno pseudotabulky nyní představují změny, které by měly Pokud byl spouštěcí příkaz skutečně proveden. Pro tyto spouštěče nelze použít verzování řádků, protože podle definice nedošlo k žádným úpravám. Pokud tedy nepoužíváte verze řádků, jak to SQL Server dělá?
Odpověď zní, že SQL Server upraví plán provádění pro spouštěcí příkaz DML, pokud existuje spouštěč INSTEAD OF. Spíše než přímou úpravu ovlivněných tabulek plán provádění zapíše informace o změnách do skryté pracovní tabulky. Tato pracovní tabulka obsahuje všechna data potřebná k provedení původních změn, typ úprav, které se mají provést na každém řádku (smazání nebo vložení), a také veškeré informace potřebné ve spouštěči pro klauzuli OUTPUT.
Plán provádění bez spouštěče
Abychom toto vše viděli v akci, nejprve spustíme jednoduchý test bez přítomnosti spouštěče:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Prováděcí plán pro odstranění je velmi přímočarý:
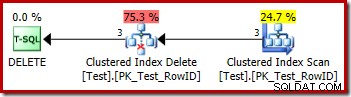
Každý řádek, který splňuje podmínky, je předán přímo operátoru Clustered Index Delete, který jej odstraní. Snadno.
Plán provádění se spouštěčem MÍSTO spouštěče
Nyní upravme test tak, aby zahrnoval spouštěč MÍSTO DELETE (který pro zjednodušení pouze provádí stejnou akci odstranění):
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Prováděcí plán pro DELETE je nyní zcela odlišný:
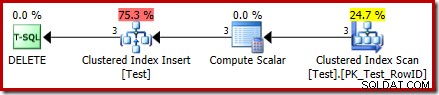
Operátor mazání seskupeného indexu byl nahrazen seskupeným indexem Vložit . Toto je vložení do skryté pracovní tabulky, která je přejmenována (ve veřejné reprezentaci plánu provádění) na název základní tabulky ovlivněné odstraněním. K přejmenování dochází, když je plán zobrazení XML generován z reprezentace interního plánu provádění, takže neexistuje žádný zdokumentovaný způsob, jak vidět skrytý pracovní stůl.
V důsledku této změny se tedy zdá, že plán provádí vložení do základní tabulky za účelem smazání řádky z něj. To je matoucí, ale alespoň to odhaluje přítomnost spouště MÍSTO spouště. Nahrazení operátoru Insert operátorem Delete může být ještě více matoucí. Možná by byla ideální nová grafická ikona pro pracovní stůl MÍSTO spouště? Každopádně je to, co to je.
Nový operátor Compute Scalar definuje typ akce provedené na každém řádku. Tento kód akce je celé číslo s následujícím významem:
- 3 =ODSTRANIT
- 4 =INSERT
- 259 =DELETE v plánu SLOUČENÍ
- 260 =VLOŽIT do plánu SLOUČENÍ
Pro tento dotaz je akce konstantní 3, což znamená, že každý řádek má být smazán :
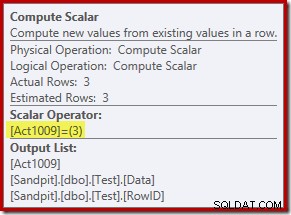
Akce aktualizace
Kromě toho plán provádění NAMÍSTO AKTUALIZACE nahrazuje jeden operátor aktualizace dva Clustered Index Vloží do stejné skryté pracovní tabulky – jednu pro vložené řádky pseudotabulky a jeden pro smazané řádky pseudotabulky. Příklad plánu provedení:

SLOUČENÍ, které provádí UPDATE, také vytvoří plán provádění se dvěma vložkami do stejné základní tabulky z podobných důvodů:

Plán spuštění spouštěče
Prováděcí plán pro tělo spouště má také některé zajímavé funkce:
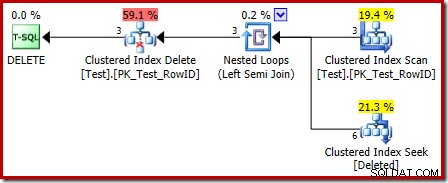
První věc, které je třeba si všimnout, je, že grafická ikona použitá pro odstraněnou tabulku není stejná jako ikona použitá v plánech PO spuštění:
Reprezentací ve spouštěcím plánu NAMÍSTO OF je Clustered Index Seek. Základní objekt je stejný interní pracovní stůl, jaký jsme viděli dříve, i když zde je pojmenován smazáno místo toho, aby dostal název základní tabulky, pravděpodobně kvůli nějaké konzistenci se spouštěči AFTER.
Operace hledání na smazáno tabulka nemusí být to, co jste očekávali (pokud jste očekávali vyhledávání na RowID):
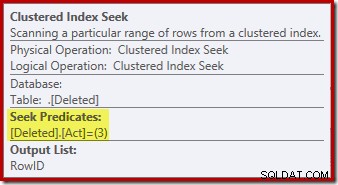
Toto „hledání“ vrátí všechny řádky z pracovního stolu, které mají kód akce 3 (smazat), což je přesně ekvivalentní Vymazané skenování operátor viděný v plánech PO spuštění. Pro obě vložené se používá stejná interní pracovní tabulka a smazáno pseudo-tabulky v MÍSTO spouštěčů. Ekvivalentem vloženého skenu je hledání kódu akce 4 (což je možné při smazání trigger, ale výsledek bude vždy prázdný). Na interním pracovním stole nejsou žádné indexy kromě nejedinečného seskupeného indexu v akci sloup sám. Kromě toho nejsou s tímto interním indexem spojeny žádné statistiky.
Dosavadní analýza vás možná nechá přemýšlet, kde se provádí spojení mezi sloupci RowID. K tomuto srovnání dochází u operátoru Nested Loops Left Semi Join jako zbytkový predikát:
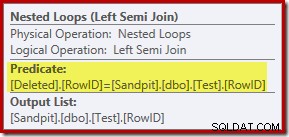
Nyní, když víme, že „hledání“ je v podstatě úplné prohledání smazaných plán provádění zvolený optimalizátorem dotazů se zdá být značně neefektivní. Celkový tok plánu provádění spočívá v tom, že každý řádek z testovací tabulky je potenciálně porovnán s celou sadou smazaných řádky, což zní hodně jako kartézský součin.
Úspora spočívá v tom, že spojení je poloviční spojení, což znamená, že proces porovnání se pro daný testovací řádek zastaví, jakmile je první smazán řádek splňuje reziduální predikát. Nicméně strategie se zdá být zvláštní. Možná by byl plán provádění lepší, kdyby tabulka Test obsahovala více řádků?
Test spouštění s 1 000 řádky
Následující skript lze použít k otestování spouštěče s větším počtem řádků. Začneme s 1 000:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Plán provádění pro tělo spouště je nyní:
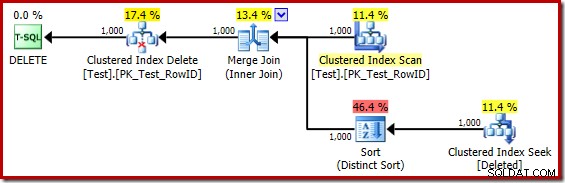
Po mentálním nahrazení (zavádějícího) hledání seskupeného indexu smazaným skenem vypadá plán obecně docela dobře. Optimalizátor zvolil spojení jedna k mnoha místo spojení Nested Loops Semi Join, což se zdá rozumné. Distinct Sort je však zvláštní doplněk:
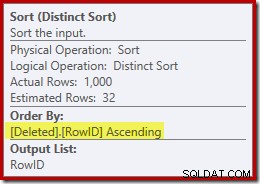
Tento druh plní dvě funkce. Za prvé, poskytuje slučovací spojení s seřazeným vstupem, který potřebuje, což je dostatečně spravedlivé, protože na interním pracovním stole není žádný index, který by poskytoval potřebné pořadí. Druhá věc, kterou řazení dělá, je rozlišování na RowID. To se může zdát zvláštní, protože RowID je primární klíč základní tabulky.
Problém je v tom, že řádky v smazány tabulka jsou jednoduše kandidátské řádky, které identifikoval původní dotaz DELETE. Na rozdíl od spouštěče AFTER nebyly tyto řádky dosud zkontrolovány na porušení omezení nebo klíče, takže procesor dotazů nemá žádnou záruku, že jsou ve skutečnosti jedinečné.
Obecně je to velmi důležitý bod, který je třeba mít na paměti u spouštěčů NAMÍSTO OF:neexistuje žádná záruka, že poskytnuté řádky splňují jakékoli z omezení v základní tabulce (včetně NOT NULL). To je důležité nejen pro autora spouště, aby si to zapamatoval; také omezuje zjednodušení a transformace, které může optimalizátor dotazů provádět.
Druhý problém zobrazený ve vlastnostech řazení výše, ale nezvýrazněný, je, že odhad výstupu je pouze 32 řádků. K interní pracovní tabulce nejsou přidruženy žádné statistiky, takže optimalizátor hádá v důsledku operace Distinct. „Víme“, že hodnoty RowID jsou jedinečné, ale bez jakýchkoli obtížných informací, které by mohly pokračovat, optimalizátor špatně odhadne. Tento problém nás bude pronásledovat v příštím testu.
Test spouštění s 5 000 řádky
Nyní upravte testovací skript tak, aby vygeneroval 5 000 řádků:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Plán provádění spouštěče je:
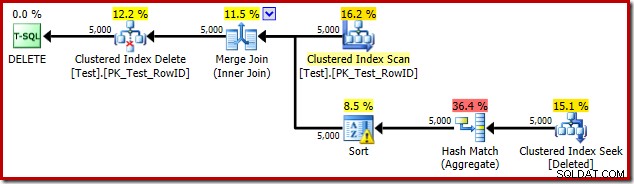
Tentokrát se optimalizátor rozhodl rozdělit jednotlivé operace a operace řazení. Rozlišení na RowID provádí operátor Hash Match (Aggregate):
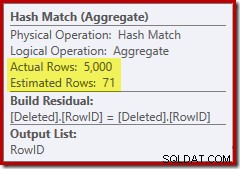
Všimněte si, že odhad optimalizátoru pro výstup je 71 řádků. Ve skutečnosti všech 5 000 řádků přežije rozdíl, protože RowID je jedinečné. Nepřesný odhad znamená, že třídění je přidělena neadekvátní část přidělené paměti dotazu, která se nakonec přelije do tempdb :
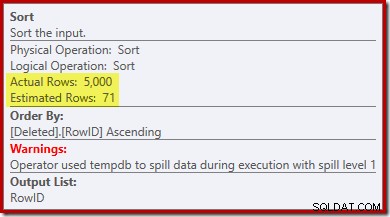
Tento test je nutné provést na serveru SQL Server 2012 nebo vyšším, aby se v plánu provádění zobrazilo upozornění na řazení. V předchozích verzích plán neobsahuje žádné informace o únikech – k odhalení by bylo potřeba trasování Profileru na události Sort Warnings (a museli byste to nějak korelovat zpět ke zdrojovému dotazu).
Test spouštění s 5 000 řádky na serveru SQL Server 2014
Pokud je předchozí test opakován na SQL Server 2014 v databázi nastavené na úroveň kompatibility 120, takže je použit nový estimátor mohutnosti (CE), plán provádění spouště se opět liší:
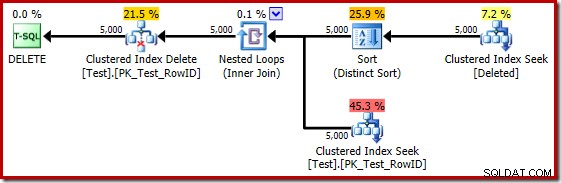
V některých ohledech se tento plán realizace jeví jako zlepšení. (nepotřebné) Distinct Sort je stále k dispozici, ale celková strategie se zdá přirozenější:pro každého odlišného kandidáta RowID v deleted tabulky, připojte se k základní tabulce (takže ověřte, že kandidátský řádek skutečně existuje) a poté jej odstraňte.
Plán na rok 2014 je bohužel založen na horších odhadech mohutnosti, než jaké jsme viděli v SQL Server 2012. Přepnutí SQL Sentry Plan Explorer pro zobrazení odhadovaného počet řádků jasně ukazuje problém:
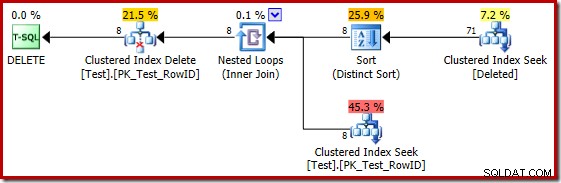
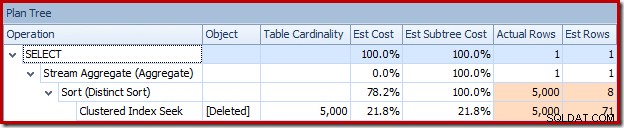
Optimalizátor zvolil pro spojení strategii Nested Loops, protože očekával velmi malý počet řádků na svém horním vstupu. K prvnímu problému dochází při hledání seskupeného indexu. Optimalizátor ví, že odstraněná tabulka v tuto chvíli obsahuje 5 000 řádků, jak můžeme vidět přepnutím do zobrazení Plán stromu a přidáním volitelného sloupce Kardinality tabulky (který bych si přál, aby byl zahrnut ve výchozím nastavení):
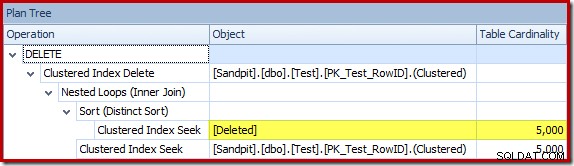
„Starý“ odhad mohutnosti v SQL Server 2012 a dřívějších verzích je dostatečně chytrý, aby věděl, že „hledání“ na interním pracovním stole vrátí všech 5 000 řádků (takže zvolilo sloučení spojení). Nový CE není tak chytrý. Vidí pracovní stůl jako „černou skříňku“ a odhaduje účinek hledání na kód akce =3:
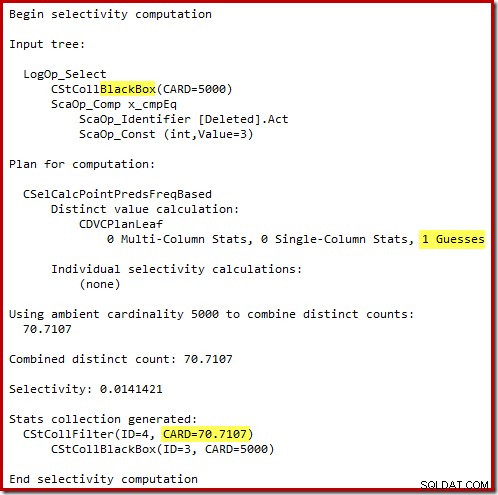
Odhad 71 řádků (zaokrouhleno nahoru) je dost mizerný výsledek, ale chyba se ještě znásobí, když nový CE odhadne řádky pro odlišnou operaci na těchto 71 řádcích:
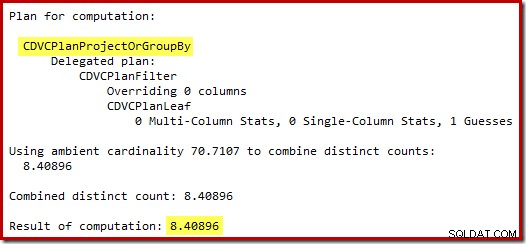
Na základě očekávaných 8 řádků optimalizátor zvolí strategii Nested Loops. Dalším způsobem, jak zobrazit tyto chyby odhadu, je přidat do těla spouštěče následující příkaz (pouze pro účely testu):
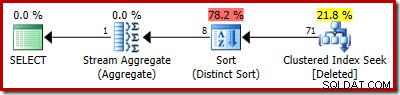
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
Odhadovaný plán jasně ukazuje chyby odhadu:
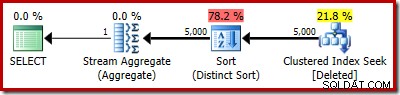
Skutečný plán samozřejmě stále ukazuje 5 000 řádků:
Nebo můžete porovnat odhad se skutečností ve stejnou dobu v zobrazení Strom plánu:
Milion řádků…
Špatné odhady odhadů při použití estimátoru mohutnosti 2014 způsobí, že optimalizátor vybere strategii vnořených smyček, i když testovací tabulka obsahuje milion řádků. Nový CE 2014 odhad plán tohoto testu je:
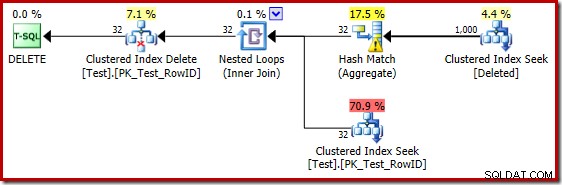
'Hledat' odhaduje 1 000 řádků ze známé mohutnosti 1 000 000 a zřetelný odhad je 32 řádků. Plán po provedení odhaluje účinek na paměť vyhrazenou pro hash Match:
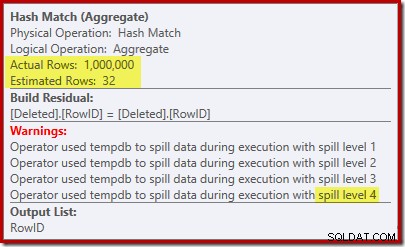
Hash Match očekává pouze 32 řádků a dostává se do skutečných problémů, rekurzivně rozlévá svou hašovací tabulku, než se nakonec dokončí.
Poslední myšlenky
I když je pravda, že spouštěč by nikdy neměl být napsán, aby udělal něco, čeho lze dosáhnout s deklarativní referenční integritou, je také pravda, že dobře napsaný spouštěč, který používá efektivní plán provádění může být z hlediska výkonu srovnatelný s náklady na údržbu dalšího neshlukovaného indexu.
Výše uvedené tvrzení má dva praktické problémy. Za prvé (a s nejlepší vůlí na světě) lidé ne vždy píší dobrý spouštěcí kód. Za druhé, získat dobrý plán provádění z optimalizátoru dotazů za všech okolností může být obtížné. Povaha spouštěčů je taková, že jsou volány se širokou škálou vstupních mohutností a distribucí dat.
I pro spouštěče AFTER chybí indexy a statistiky o smazaných a vloženo pseudotabulky znamenají, že výběr plánu je často založen na odhadech nebo dezinformacích. I když je zpočátku vybrán dobrý plán, pozdější provedení mohou znovu použít stejný plán, pokud by byla lepší volbou rekompilace. Existují způsoby, jak obejít omezení, především pomocí dočasných tabulek a explicitních indexů/statistik, ale i tam je zapotřebí velká opatrnost (protože spouštěče jsou formou uložené procedury).
S MÍSTO spouštěčů mohou být rizika ještě větší, protože obsah vložených a smazáno tabulky jsou neověření kandidáti – optimalizátor dotazů nemůže použít omezení na základní tabulce ke zjednodušení a upřesnění plánu provádění. Nový estimátor mohutnosti v SQL Server 2014 také představuje skutečný krok zpět, pokud jde o plány spouštění NAMÍSTO. Odhadnout účinek operace vyhledávání, kterou motor sám představil, je překvapivým a nevítaným nedopatřením.