V tomto článku vysvětlím, jak přesunout tabulku z primární skupiny souborů do sekundární skupiny souborů. Nejprve si ujasněme, co jsou datový soubor, skupina souborů a typ skupin souborů.
Soubory databáze a skupiny souborů
Když je SQL Server nainstalován na libovolném serveru, vytvoří primární datový soubor a soubor protokolu pro ukládání dat. Primární datový soubor ukládá data a databázové objekty, jako jsou tabulky, index, uložené procedury atd. Soubory protokolu ukládají informace potřebné k obnovení transakcí. Datové soubory lze spojovat do skupin souborů.
SQL Server má tři typy souborů
- Primární soubor :Vytvoří se při instalaci SQL serveru a obsahuje databázová metadata a informace. Uživatelská data, objekty mohou být uloženy v primárních datových souborech. Primární soubor má příponu .mdf.
- Sekundární soubor :Sekundární soubory jsou definovány uživatelem. Ukládají uživatelská data, objekty vytvořené uživatelem. Mají příponu .ndf.
- Soubor protokolu transakcí s:Soubory T-Logs zaznamenávají všechny transakce provedené za účelem obnovení databáze. Přípona souboru protokolu v .ldf.
Jak jsem uvedl výše, datové soubory lze seskupit do skupiny souborů. Při instalaci serveru SQL Server vytvoří skupinu primárních souborů, která má primární datový soubor. Sekundární skupiny souborů jsou definovány uživatelem. Mají sekundární datové soubory. Když vytvoříme novou databázi, můžeme vytvořit sekundární datové soubory a skupiny souborů. Přidání sekundárních datových souborů pomáhá zlepšit výkon. Může být vytvořen na různých diskových jednotkách nebo samostatných diskových oddílech, což snižuje čekání na vstup a výstup a latenci čtení a zápisu.
Je doporučeno uchovávat tabulky a indexy v samostatných skupinách souborů. Také uchovávání velkých tabulek v samostatných souborech zlepšuje výkon.
Existují tři typy skupin souborů:
- Skupina souborů řádků :Skupina souborů řádků, známá také jako skupina primárních souborů, obsahuje primární datový soubor. Objekt SQL, data, systémové tabulky se přidělují primární skupině souborů.
- Skupina souborů s optimalizovanou pamětí :Skupina souborů optimalizovaná pro paměť obsahuje tabulky a data optimalizovaná pro paměť. Abychom povolili OLTP v paměti, musíme vytvořit skupinu souborů optimalizovanou pro paměť.
- FileStream :Skupina souborů toku souborů obsahuje data toku souborů, jako jsou obrázky, dokumenty, spustitelné soubory atd. Primární skupina souborů nemůže obsahovat data toku souborů, musíme vytvořit skupinu souborů FileStream. Obsahuje data FileStream.
Nastavení ukázky
V této ukázce jsem vytvořil „DemoDatabase“ na instanci SQL Server 2017. V databázi byly vytvořeny karty „Records“ a „PatientData“. Primární klíč „PK_CIDX_Records_ID“ byl vytvořen v tabulce „Records“ a klastrovaný index „CIDX_PatientData_ID“ byl vytvořen v tabulce „PatientData“. V této ukázce přesunu tabulky „Records“ a „PatientData“ z primární skupiny souborů do sekundární skupiny souborů.
Za tímto účelem musíme provést následující:
- Vytvořte sekundární skupinu souborů.
- Přidejte datové soubory do sekundární skupiny souborů.
- Přesuňte tabulku do sekundární skupiny souborů přesunutím seskupeného indexu s omezením primárního klíče.
- Přesuňte tabulky do sekundární skupiny souborů přesunutím seskupeného indexu bez primárního klíče.
Vytvořit sekundární skupinu souborů
Sekundární skupinu souborů lze vytvořit pomocí T-SQL NEBO pomocí Průvodce přidáním souboru z SQL Server Management Studio. Chcete-li přidat skupinu souborů pomocí SSMS, otevřete SSMS a vyberte databázi, kde je třeba vytvořit skupinu souborů. Klikněte pravým tlačítkem na databázi a vyberte „Vlastnosti ”>> vyberte “Skupiny souborů “ a klikněte na „Přidat skupinu souborů ” jak je znázorněno na následujícím obrázku:
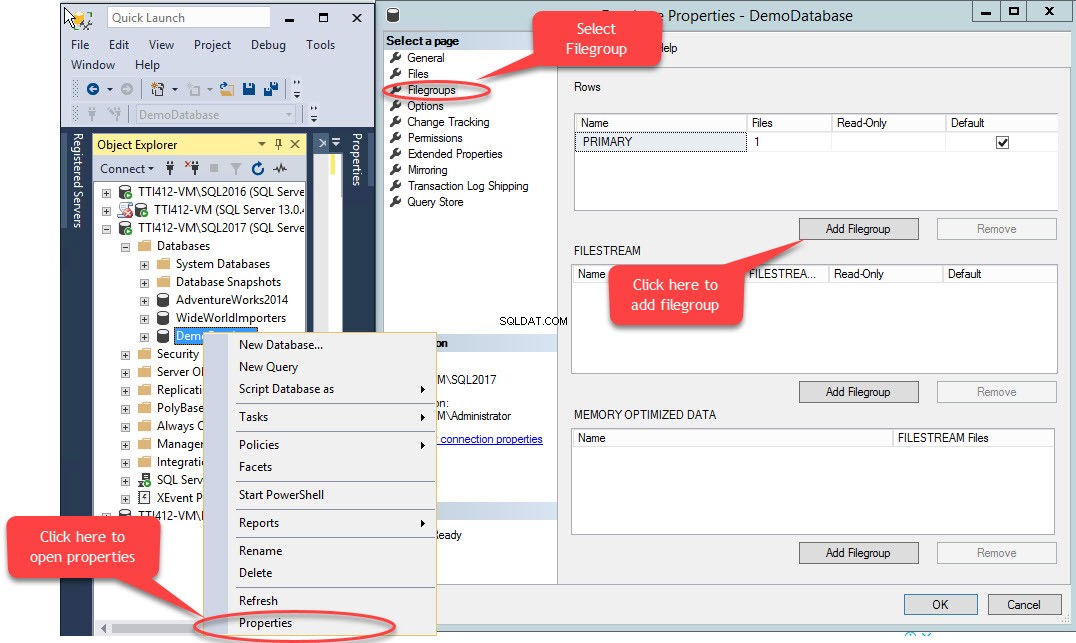
Když klikneme na „Přidat skupinu souborů “, do pole „Řádky bude přidán řádek “mřížka. V části „Řádky “, zadejte do pole „Název příslušný název skupiny souborů “. Filegroup není pouze pro čtení ani výchozí; proto ponechte možnost Pouze pro čtení a Výchozí zaškrtávací políčka pro novou skupinu souborů zrušena. Viz následující obrázek:
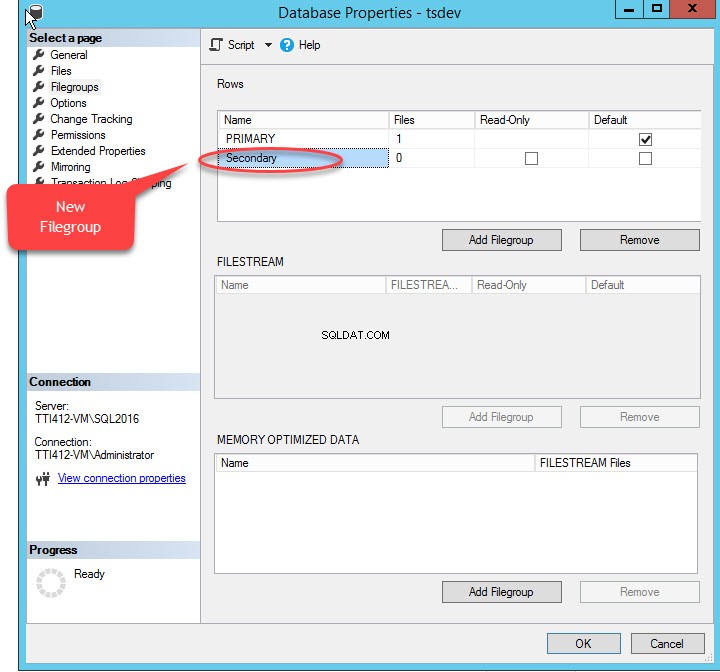
Klepnutím na tlačítko OK zavřete dialogové okno.
Chcete-li vytvořit skupinu souborů pomocí skriptu T-SQL, spusťte následující skript.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
Přidávání souborů do skupiny souborů
Chcete-li přidat soubory do skupiny souborů, otevřete vlastnosti databáze, vyberte „soubory“ a klikněte na „Přidat“. Jak ukazuje následující obrázek:
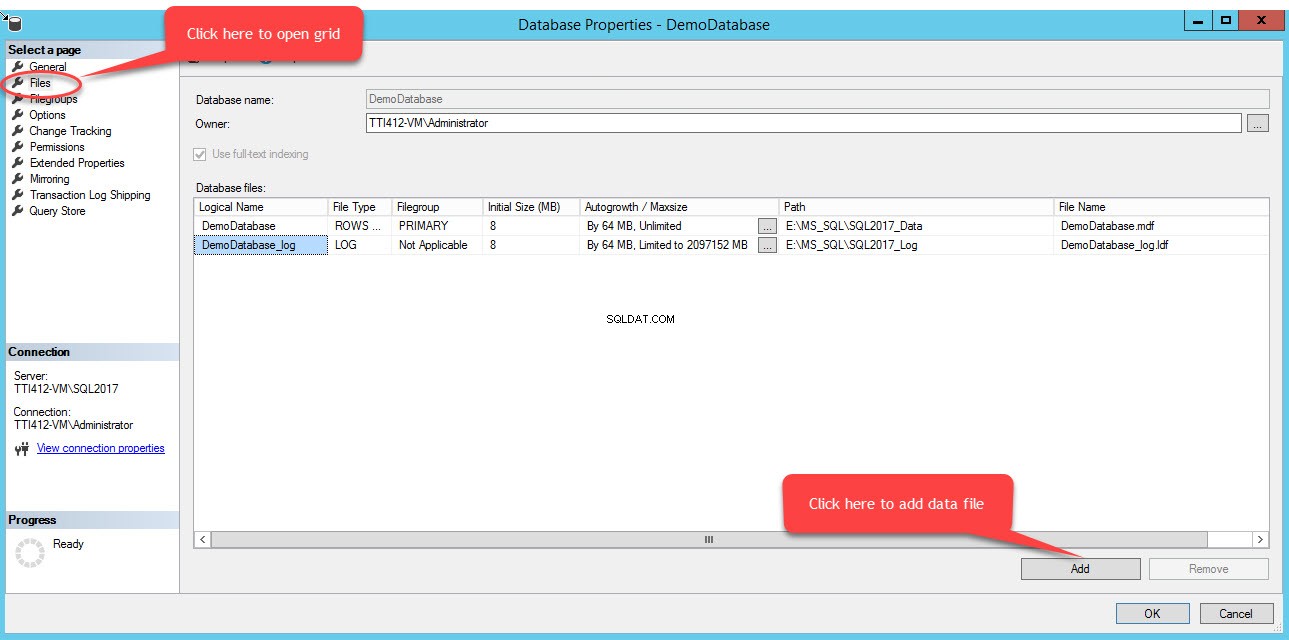
Do Souborů databáze bude přidán prázdný řádek zobrazení mřížky. V zobrazení mřížky zadejte vhodný logický název do pole Logický název vyberte Data řádků zTyp souboru v rozevíracím seznamu vyberte sekundární ze Skupiny souborů v rozevíracím seznamu nastavte počáteční velikost souboru v Počáteční velikost sloupce, nastavte parametr automatického růstu a maximální velikosti v Autogrowth/Maxsize ve sloupci Cesta zadejte fyzické umístění sekundárního datového souboru a zadejte příslušný název souboru do Název souboru sloupec. Viz následující obrázek:
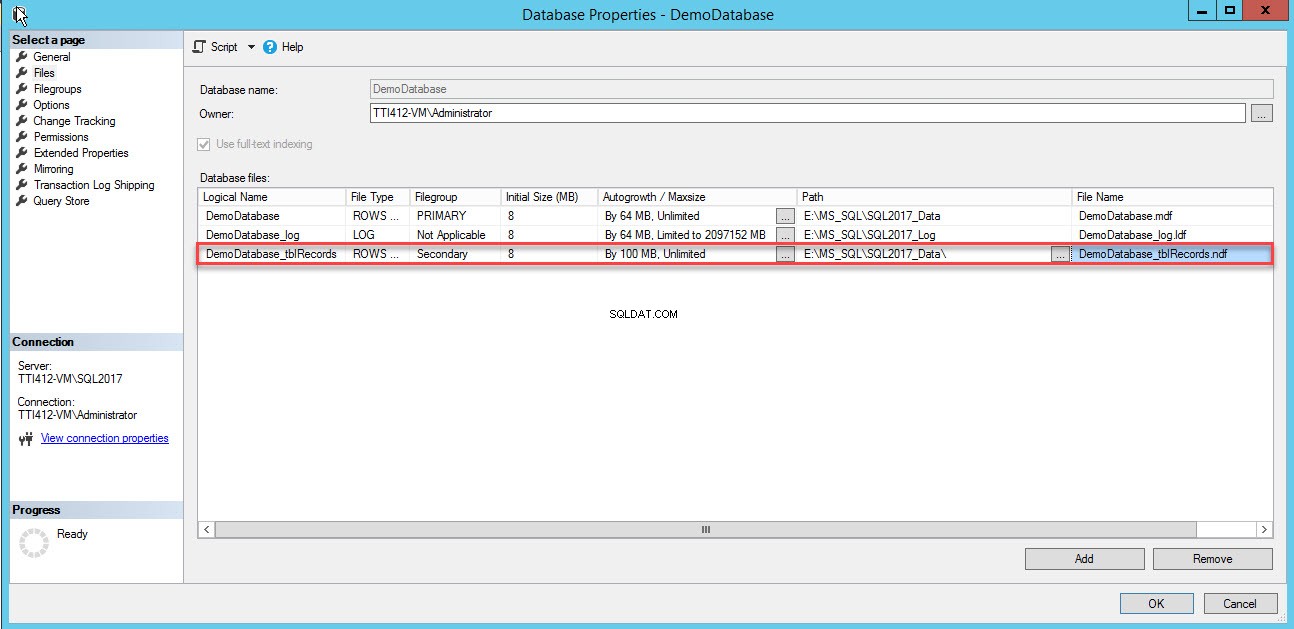
Pomocí následujícího skriptu T-SQL vytvořte sekundární datový soubor.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
Sekundární datový soubor byl vytvořen. Viz následující obrázek:
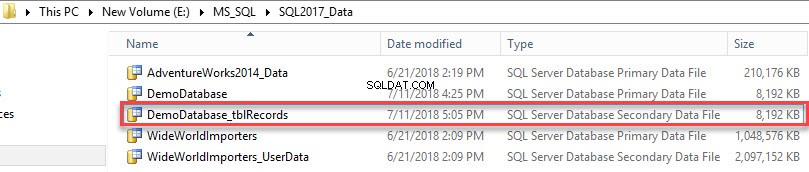
Chcete-li zobrazit seznam skupin souborů vytvořených v databázi, proveďte následující dotaz.
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
Níže je výstup dotazu.

Přenos existující tabulky z primární skupiny souborů do sekundární skupiny souborů
Existující tabulku můžeme přesunout do jiné skupiny souborů přesunutím seskupeného indexu do jiné skupiny souborů. Jak víme, listový uzel seskupeného indexu má aktuální data; přesun klastrovaného indexu tedy může přesunout celou tabulku do jiné skupiny souborů. Přesouvání indexu má omezení:pokud je index primárním klíčem nebo jedinečným omezením, nemůžete index přesunout pomocí SQL Server Management Studio. K přesunutí těchto indexů musíme použít vytvořit index a s DROP_Existing=ON možnost.
Posouvání seskupeného indexu s omezením primárního klíče.
Primární klíč vynucuje jedinečné hodnoty, a proto vytváří jedinečný seskupený index. Klíčový sloupec je PRN. Chcete-li jej vytvořit v sekundární skupině souborů, nastavte DROP_EXISTING=ON možnost a skupina souborů by měla být sekundární. Spusťte následující skript.
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
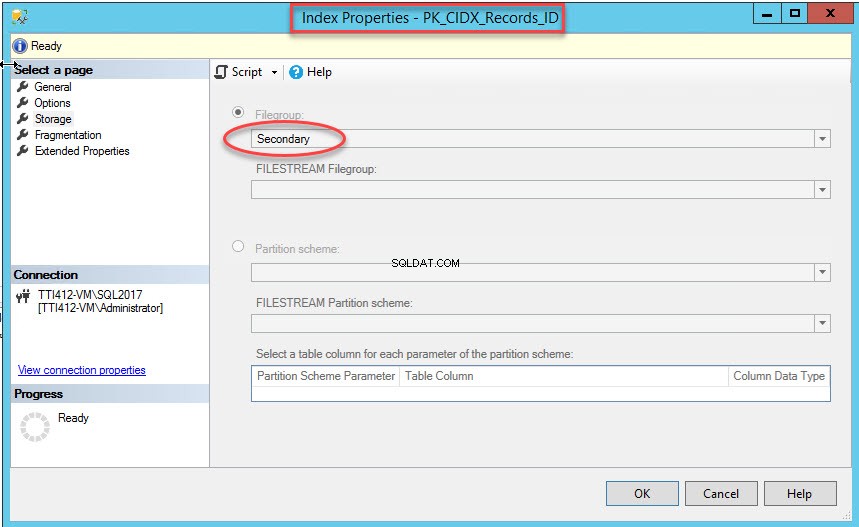
Po úspěšném provedení příkazu ověřte, zda byl vytvořen index v sekundární skupině souborů. Chcete-li to provést, klikněte pravým tlačítkem na Úložiště možnost v Vlastnosti indexu dialogové okno. Chcete-li otevřít vlastnosti indexu, rozbalte DemoDatabázi databáze>> rozbalte Tabulky>> rozbalte Indexy . Klikněte pravým tlačítkem na PK_CIDX_Records_ID , jak je znázorněno na následujícím obrázku:
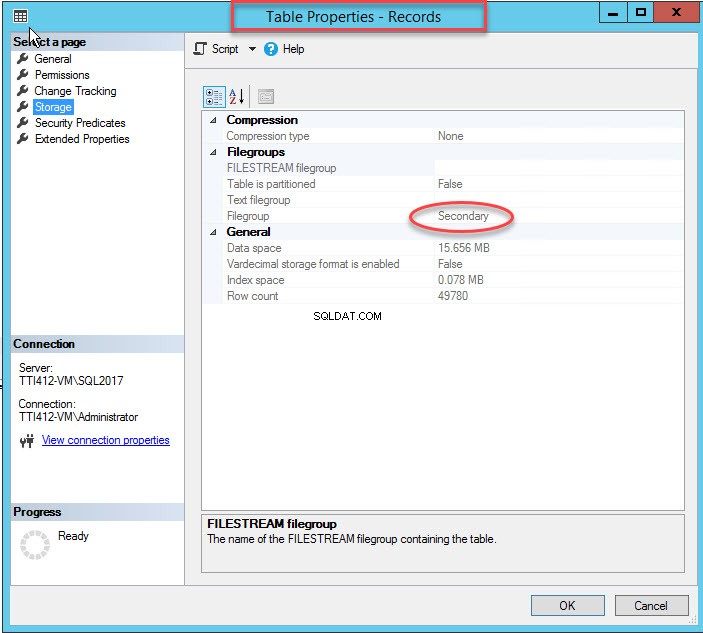
Jak jsem zmínil, jakmile se clusterovaný index přesune do sekundární skupiny souborů, tabulka se přesune do sekundární skupiny souborů. Chcete-li to ověřit, klikněte pravým tlačítkem na Úložiště možnost vVlastnosti tabulky dialogové okno. Chcete-li otevřít vlastnosti indexu, rozbalte DemoDatabázi databáze>> rozbalte Tabulku s>> klepněte pravým tlačítkem na Záznamy a vyberte úložiště jak je znázorněno na následujícím obrázku:
Přesun seskupeného indexu bez primárního klíče
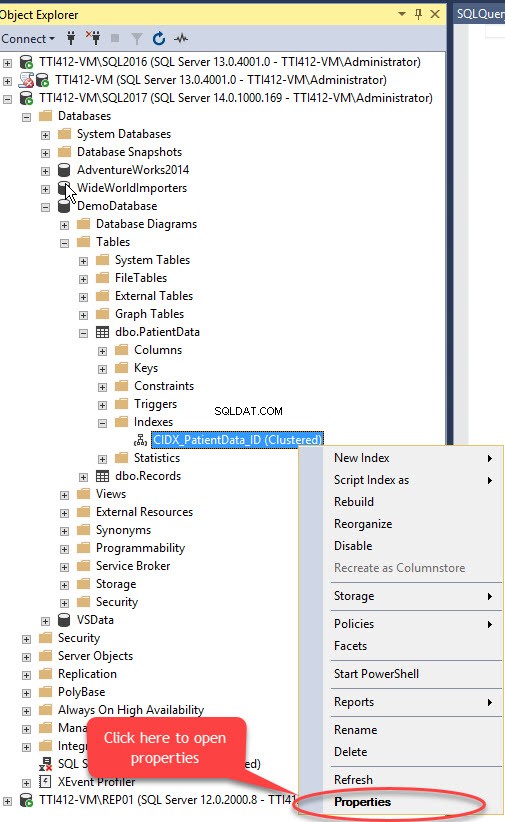
Clusterový index můžeme přesunout bez primárního klíče pomocí SQL Server Management Studio. Chcete-li to provést, rozbalte Demodatabázi databáze>> rozbalte Tabulky>> rozbalte Index s>> klikněte pravým tlačítkem na CIDX_PatientData_ID index a vyberte Vlastnosti jak je znázorněno na následujícím obrázku:
Vlastnosti indexu otevře se dialogové okno. V dialogovém okně vyberte Úložiště a v okně Úložiště klikněte na Skupinu souborů v rozevíracím seznamu vyberte Sekundární skupina souborů a klikněte na OK jak je znázorněno na následujícím obrázku:
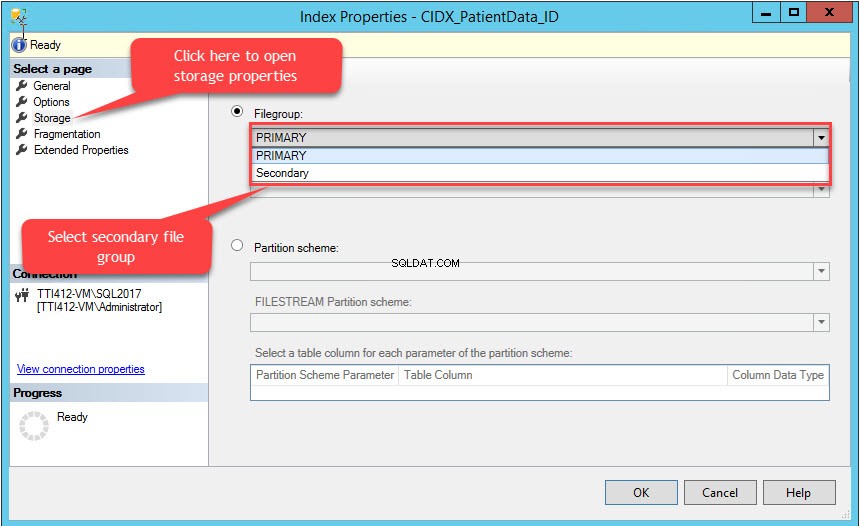
Změna skupiny souborů indexu znovu vytvoří celý index. Po opětovném vytvoření indexu otevřete Vlastnosti tabulky a vyberte úložiště.
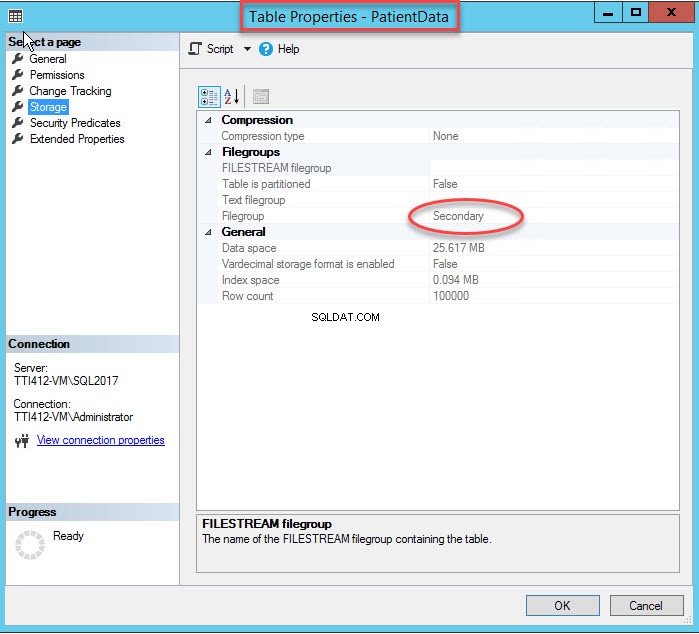
Jak můžete vidět na obrázku výše, spolu s přesunem CIDX_PatientData_ID seskupený index do sekundární skupiny souborů, PacientData tabulka se také přesune do Sekundární skupina souborů.
Spuštěním následujícího dotazu můžete najít seznam objektů vytvořených v jiné skupině souborů:
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go Níže je výstup dotazu:
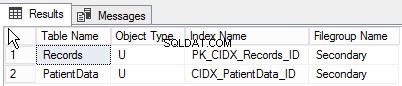
Shrnutí
V tomto článku jsem vysvětlil
-
- Základy datových souborů a skupin souborů.
- Jak vytvořit sekundární skupinu souborů a přidat do ní sekundární datový soubor.
- Přesuňte tabulku do sekundární skupiny souborů přesunutím:
- Primární klíč.
- Shlukovaný index.