Databáze jsou navrženy různými způsoby. Většinu času můžeme použít „školní příklady“:normalizovat databázi a vše bude fungovat dobře. Jsou ale situace, které budou vyžadovat jiný přístup. Můžeme odstranit reference, abychom získali větší flexibilitu. Ale co když musíme zlepšit výkon, když vše bylo provedeno podle knihy? V takovém případě je denormalizace technika, kterou bychom měli zvážit. V tomto článku probereme výhody a nevýhody denormalizace a jaké situace ji mohou odůvodnit.
Co je denormalizace?
Denormalizace je strategie používaná na dříve normalizované databázi ke zvýšení výkonu. Smyslem toho je přidat nadbytečná data tam, kde si myslíme, že nám to pomůže nejvíce. Můžeme použít extra atributy ve stávající tabulce, přidat nové tabulky nebo dokonce vytvořit instance existujících tabulek. Obvyklým cílem je zkrátit dobu běhu vybraných dotazů zpřístupněním dat pro dotazy nebo generováním souhrnných sestav v samostatných tabulkách. Tento proces může přinést nové problémy a probereme je později.
Normalizovaná databáze je výchozím bodem pro proces denormalizace. Je důležité odlišit databázi, která nebyla normalizována, a databázi, která byla nejprve normalizována a poté denormalizována později. Druhý je v pořádku; první je často výsledkem špatného návrhu databáze nebo nedostatku znalostí.
Příklad:Normalizovaný model pro velmi jednoduché CRM
Jako příklad nám poslouží model níže:
Pojďme se rychle podívat na tabulky:
user_accounttabulka ukládá údaje o uživatelích, kteří se přihlásí do naší aplikace (zjednodušení modelu, role a uživatelská práva jsou z ní vyloučeny).clienttabulka obsahuje základní údaje o našich klientech.producttabulka uvádí produkty nabízené našim klientům.tasktabulka obsahuje všechny úkoly, které jsme vytvořili. Každý úkol si můžete představit jako soubor souvisejících akcí vůči klientům. Každý úkol má související hovory, schůzky a seznamy nabízených a prodávaných produktů.callameetingtabulky ukládají data o všech hovorech a schůzkách a spojují je s úkoly a uživateli.- Slovníky
task_outcome,meeting_outcomeacall_outcomeobsahovat všechny možné možnosti pro konečný stav úkolu, schůzky nebo hovoru. product_offeredukládá seznam všech produktů, které byly klientům nabídnuty při určitých úkolech v doběproduct_soldobsahuje seznam všech produktů, které klient skutečně zakoupil.supply_ordertabulka ukládá údaje o všech objednávkách, které jsme zadali, aproducts_on_ordertabulka uvádí produkty a jejich množství pro konkrétní objednávky.writeofftabulka je seznam produktů, které byly odepsány v důsledku nehod nebo podobně (např. rozbitá zrcátka).
Databáze je zjednodušená, ale je dokonale normalizovaná. Nenajdete žádné propouštění a mělo by to fungovat. V žádném případě bychom neměli zaznamenat žádné problémy s výkonem, pokud pracujeme s relativně malým množstvím dat.
Kdy a proč používat denormalizaci
Jako téměř u všeho si musíte být jisti, proč chcete použít denormalizaci. Musíte si být také jisti, že zisk z jeho používání převáží jakoukoli škodu. Existuje několik situací, kdy byste rozhodně měli myslet na denormalizaci:
- Udržování historie: Data se mohou v průběhu času měnit a my musíme uchovávat hodnoty, které byly platné, když byl záznam vytvořen. Jaké změny máme na mysli? No, jméno a příjmení osoby se může změnit; klient může také změnit své obchodní jméno nebo jakékoli jiné údaje. Podrobnosti úkolu by měly obsahovat hodnoty, které byly aktuální v okamžiku vytvoření úkolu. Pokud by se tak nestalo, nebyli bychom schopni správně znovu vytvořit minulá data. Tento problém bychom mohli vyřešit přidáním tabulky obsahující historii těchto změn. V takovém případě by výběrový dotaz vracející úlohu a platné jméno klienta byl komplikovanější. Možná není další stůl tím nejlepším řešením.
- Zlepšení výkonu dotazů: Některé z dotazů mohou používat více tabulek pro přístup k datům, která často potřebujeme. Představte si situaci, kdy bychom potřebovali spojit 10 stolů, abychom vrátili jméno klienta a produkty, které mu byly prodány. Některé tabulky podél cesty mohou také obsahovat velké množství dat. V takovém případě by možná bylo rozumné přidat
client_idatribut přímo doproducts_soldstůl. - Urychlení hlášení: Velmi často potřebujeme určité statistiky. Jejich vytváření z živých dat je poměrně časově náročné a může ovlivnit celkový výkon systému. Řekněme, že chceme sledovat prodeje klientů za určité roky u některých nebo všech klientů. Generování takových reportů z živých dat by „prokopalo“ téměř celou databázi a hodně ji zpomalilo. A co se stane, když tuto statistiku používáme často?
- Výpočet běžně potřebných hodnot předem: Chceme mít některé hodnoty předem spočítané, abychom je nemuseli generovat v reálném čase.
Je důležité zdůraznit, že není nutné používat denormalizaci, pokud nejsou žádné problémy s výkonem v aplikaci. Ale pokud si všimnete, že se systém zpomaluje – nebo pokud si uvědomujete, že by se to mohlo stát – měli byste o použití této techniky přemýšlet. Než se do toho pustíte, zvažte další možnosti, jako je optimalizace dotazů a správné indexování. Můžete také použít denormalizaci, pokud již jste ve výrobě, ale je lepší řešit problémy ve fázi vývoje.
Jaké jsou nevýhody denormalizace?
Je zřejmé, že největší výhodou procesu denormalizace je zvýšený výkon. Ale musíme za to zaplatit cenu a ta cena se může skládat z:
- Místo na disku: To se očekává, protože budeme mít duplicitní data.
- Datové anomálie: Musíme si být vědomi skutečnosti, že data lze nyní měnit na více než jednom místě. Musíme odpovídajícím způsobem upravit každý kus duplicitních dat. To platí i pro vypočtené hodnoty a reporty. Toho můžeme dosáhnout použitím spouštěčů, transakcí a/nebo procedur pro všechny operace, které musí být dokončeny společně.
- Dokumentace: Musíme řádně zdokumentovat každé denormalizační pravidlo, které jsme aplikovali. Pokud později upravíme návrh databáze, budeme se muset podívat na všechny naše výjimky a znovu je vzít v úvahu. Možná je už nepotřebujeme, protože jsme problém vyřešili. Nebo možná potřebujeme přidat ke stávajícím denormalizačním pravidlům. (Například:Do tabulky klientů jsme přidali nový atribut a chceme uložit jeho hodnotu historie spolu se vším, co již ukládáme. Abychom toho dosáhli, budeme muset změnit stávající denormalizační pravidla).
- Zpomalení dalších operací: Můžeme očekávat, že zpomalíme operace vkládání, úprav a mazání dat. Pokud k těmto operacím dochází relativně zřídka, může to být přínosem. V podstatě bychom jeden pomalý výběr rozdělili na větší počet pomalejších vkládání/aktualizace/mazání dotazů. I když by technicky velmi složitý výběrový dotaz mohl znatelně zpomalit celý systém, zpomalení více „menších“ operací by nemělo poškodit použitelnost naší aplikace.
- Další kódování: Pravidla 2 a 3 budou vyžadovat dodatečné kódování, ale zároveň hodně zjednoduší některé výběrové dotazy. Pokud denormalizujeme existující databázi, budeme muset tyto vybrané dotazy upravit, abychom získali výhody naší práce. Také budeme muset aktualizovat hodnoty v nově přidaných atributech pro stávající záznamy. I to bude vyžadovat trochu více kódování.
Ukázkový model, denormalizovaný
V níže uvedeném modelu jsem aplikoval některá z výše uvedených denormalizačních pravidel. Růžové stoly byly upraveny, zatímco světle modrý stůl je zcela nový.
Jaké změny byly použity a proč?

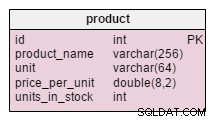
Jediná změna v product tabulka je přidáním units_in_stock atribut. V normalizovaném modelu bychom mohli tato data vypočítat jako objednané jednotky – prodané jednotky – (nabízené jednotky) – odepsané jednotky . Výpočet bychom opakovali pokaždé, když klient o daný produkt požádá, což by bylo extrémně časově náročné. Místo toho spočítáme hodnotu předem; když nás zákazník požádá, budeme to mít připravené. To samozřejmě výběrový dotaz hodně zjednodušuje. Na druhé straně units_in_stock atribut musí být upraven po každém vložení, aktualizaci nebo smazání v products_on_order , writeoff , product_offered a product_sold tabulky.
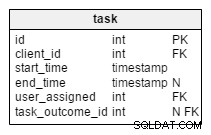
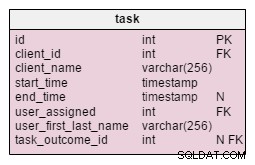
V upraveném task tabulky, najdeme dva nové atributy:client_name a user_first_last_name . Oba ukládají hodnoty při vytvoření úkolu. Důvodem je, že obě tyto hodnoty se mohou v průběhu času měnit. Uchováme také cizí klíč, který je spojuje s původním ID klienta a uživatele. Existuje více hodnot, které bychom chtěli uložit, jako je adresa klienta, DIČ atd.




Denormalizovaný product_offered tabulka má dva nové atributy, price_per_unit a price . price_per_unit atribut je uložen, protože potřebujeme uložit skutečnou cenu, kdy byl produkt nabízen . Normalizovaný model by ukazoval pouze svůj aktuální stav, takže když se změní cena produktu, změní se i naše „historie“ ceny. Naše změna nejen zrychlí běh databáze, ale také zlepší její fungování. price atribut je vypočítaná hodnota units_sold * price_per_unit . Přidal jsem to sem, abych se vyhnul výpočtu pokaždé, když se chceme podívat na seznam nabízených produktů. Je to malá cena, ale zlepšuje výkon.
Změny provedené na product_sold tabulky jsou velmi podobné. Struktura tabulky je stejná, ale ukládá seznam prodaných položek.
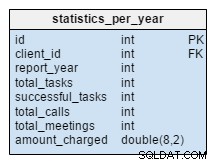
statistics_per_year stůl je u našeho modelu zcela nový. Měli bychom se na to dívat jako na denormalizovanou tabulku, protože všechna její data lze vypočítat z ostatních tabulek. Myšlenkou této tabulky je ukládat počet úkolů, úspěšných úkolů, schůzek a hovorů souvisejících s daným klientem. Zpracovává také celkovou částku účtovanou za každý rok. Po vložení, aktualizaci nebo smazání čehokoli v task , meeting , call a product_sold tabulky, měli bychom přepočítat data této tabulky pro daného klienta a odpovídající rok. Dá se očekávat, že změny budeme mít většinou jen pro aktuální rok. Přehledy za předchozí roky by se neměly měnit.
Hodnoty v této tabulce jsou vypočítány předem, takže ve chvíli, kdy potřebujeme výsledek výpočtu, strávíme méně času a prostředků. Myslete na hodnoty, které budete často potřebovat. Možná je nebudete pravidelně všechny potřebovat a můžete riskovat, že některé z nich budete používat naživo.
Denormalizace je velmi zajímavý a mocný koncept. I když to není první, co byste měli mít na mysli pro zlepšení výkonu, v některých situacích to může být nejlepší nebo dokonce jediné řešení.
Než se rozhodnete použít denormalizaci, ujistěte se, že ji chcete. Proveďte nějakou analýzu a sledujte výkon. Pravděpodobně se rozhodnete přejít k denormalizaci poté, co jste již uvedli do provozu. Nebojte se to používat, ale sledujte změny a neměli byste zaznamenat žádné problémy (tj. obávané datové anomálie).