Zvýraznění přístupů je funkce, kterou si mnoho lidí přeje, aby fulltextové vyhledávání SQL Serveru nativně podporovalo. Zde můžete vrátit celý dokument (nebo úryvek) a poukázat na slova nebo fráze, které pomohly přiřadit daný dokument k hledání. Udělat to účinným a přesným způsobem není snadný úkol, jak jsem zjistil z první ruky.
Jako příklad zvýraznění hitů:když provádíte vyhledávání v Google nebo Bing, zobrazí se klíčová slova tučně jak v názvu, tak v úryvku (kliknutím na kterýkoli obrázek jej zvětšíte):

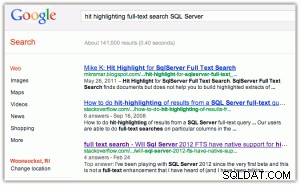
[Kromě toho zde považuji dvě věci za zábavné:(1) že Bing upřednostňuje vlastnosti Microsoftu mnohem více než Google a (2) že Bing se obtěžuje vrátit 2,2 milionu výsledků, z nichž mnohé jsou pravděpodobně irelevantní.]
Tyto úryvky se běžně nazývají „úryvky“ nebo „souhrny založené na dotazech“. Požadujeme tuto funkci na SQL Server již nějakou dobu, ale zatím jsme od společnosti Microsoft neslyšeli žádné dobré zprávy:
- Connect #295100 :Souhrny fulltextového vyhledávání (zvýraznění požadavků)
- Connect #722324 :Bylo by hezké, kdyby SQL Full Text Search poskytoval podporu úryvků / zvýraznění
Na Stack Overflow se čas od času také objeví otázka:
- Jak provést zvýraznění výsledků z fulltextového dotazu SQL Server
- Bude mít Sql Server 2012 FTS nativní podporu pro zvýraznění přístupů?
Existuje několik dílčích řešení. Tento skript od Mika Kramara například vytvoří zvýrazněný úryvek, ale nepoužije stejnou logiku (jako jsou dělení slov pro konkrétní jazyk) na samotný dokument. Používá také absolutní počet znaků, takže úryvek může začínat a končit částečnými slovy (jak krátce předvedu). To se dá docela snadno opravit, ale dalším problémem je, že načte celý dokument do paměti, místo aby prováděl jakýkoli druh streamování. Mám podezření, že ve fulltextových indexech s velkými velikostmi dokumentů to bude znatelný výkon. Prozatím se zaměřím na relativně malou průměrnou velikost dokumentu (35 KB).
Jednoduchý příklad
Řekněme tedy, že máme velmi jednoduchou tabulku s definovaným fulltextovým indexem:
VYTVOŘIT FULLTEXTOVÝ KATALOG [FTSDemo];PŘEJÍT VYTVOŘIT TABULKU [dbo].[Dokument]( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Datum] DATE NOT NULL , [Název] NVARCHAR(200) NENÍ NULL, [Obsah] NVARCHAR(MAX) NENÍ NULL, OMEZENÍ PRIMÁRNÍ KLÍČ PK_DOCUMENT (ID));VYTVOŘTE FULLTEXTOVÝ INDEX NA [dbo].[Dokument]( [Obsah] JAZYK [angličtina] , [Název] JAZYK [Angličtina]) INDEX KLÍČŮ [PK_Document] ZAPNUTO ([FTSDemo]);
Tato tabulka je vyplněna několika dokumenty (konkrétně 7), jako je Deklarace nezávislosti a projev Nelsona Mandely „Jsem připraven zemřít“. Typické fulltextové vyhledávání podle této tabulky může být:
SELECT d.Title, d.[Content]FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID =t.[KEY] OBJEDNAT PODLE [RANK] DESC;
Výsledek vrátí 4 řádky ze 7:

Nyní pomocí funkce UDF jako Mike Kramar:
SELECT d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80)FROM dbo.[Document] AS dINNER JOIN CONTAINSTABLE(dbo.[Document ], *, N'states') AS tON d.ID =t.[KLÍČ]POŘADÍ PODLE [POŘADÍ] DESC;
Výsledky ukazují, jak úryvek funguje:a <SPAN> značka se vloží do prvního klíčového slova a úryvek se vyřízne na základě odsazení od této pozice (bez ohledu na použití celých slov):

(Opět jde o něco, co lze opravit, ale chci si být jistý, že správně reprezentuji to, co je teď venku.)
ThinkHighlight
Eran Meyuchas z Interactive Thoughts vyvinul komponentu, která mnohé z těchto problémů řeší. ThinkHighlight je implementován jako CLR Assembly se dvěma skalárními funkcemi CLR:
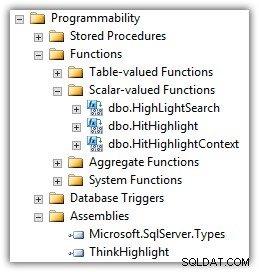
(V seznamu funkcí také uvidíte UDF Mika Kramara.)
Nyní, aniž bychom se museli zabývat všemi podrobnostmi o instalaci a aktivaci sestavy ve vašem systému, zde je návod, jak by byl výše uvedený dotaz reprezentován pomocí ThinkHighlight:
SELECT d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Dokument] JAKO DINNER JOIN CONTAINSTABLE(dbo.[Dokument], *, N'stavy') AS tON d.ID =t.[KEY]ORD BY t.[RANK] DESC; Výsledky ukazují, jak jsou zvýrazněna nejrelevantnější klíčová slova, a z toho je odvozen úryvek na základě celých slov a odsazení od zvýrazněného výrazu:

Mezi další výhody, které jsem zde neukázal, patří možnost vybrat si různé strategie sumarizace, ovládání prezentace každého klíčového slova (spíše než všech) pomocí jedinečného CSS, stejně jako podpora více jazyků a dokonce i dokumentů v binárním formátu (většina IFilterů jsou podporovány).
Výsledky výkonu
Zpočátku jsem testoval metriky běhu pro tři dotazy pomocí SQL Sentry Plan Explorer proti 7řádkové tabulce. Výsledky byly:

Dále jsem chtěl vidět, jak se budou porovnávat na mnohem větší velikosti dat. Vložil jsem tabulku do sebe, dokud jsem nebyl na 4 000 řádcích, pak jsem spustil následující dotaz:
SET STATISTICS TIME ON;GO SELECT /* FTS */ d.Title, d.[Content]FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KLÍČ]POŘADÍ PODLE [HRANICE] DESC;GO SELECT /* UDF */ d.Title, úryvek =dbo.HighLightSearch(d.[Obsah], N'states', 'váha písma:bold', 100)FROM dbo.[Document] AS dINNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORD BY [RANK] DESC;GO SELECT / * ThinkHighlight */ d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Dokument] JAKO DINNER JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') AS tON d.ID =t.[KLÍČ] OBJEDNAT PODLE t.[HRANICE] DESC;GO NASTAVIT STATISTIKY ČAS VYPNUTO;JÍT
Během běhu dotazů jsem také sledoval sys.dm_exec_memory_grants, abych zjistil případné nesrovnalosti v přidělení paměti. Výsledky v průměru za 10 běhů:
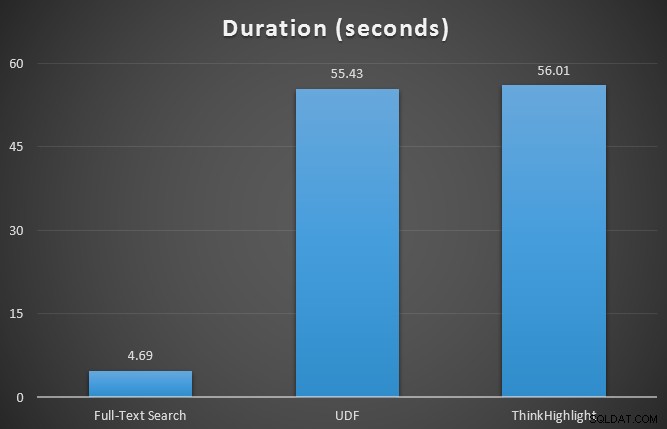
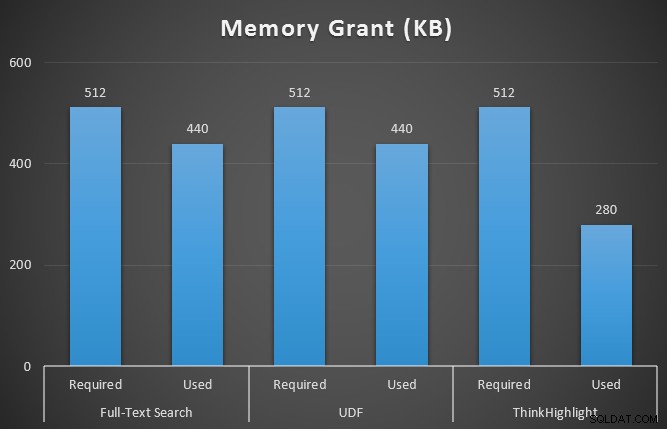
Zatímco obě možnosti zvýraznění hitů jsou značně znevýhodněny tím, že nebudou zvýrazněny vůbec, řešení ThinkHighlight – s flexibilnějšími možnostmi – představuje velmi marginální přírůstkové náklady, pokud jde o trvání (~1 %), přičemž využívá výrazně méně paměti (36 %). než varianta UDF.
Závěr
Nemělo by být překvapením, že zvýraznění hitů je nákladná operace a na základě složitosti toho, co musí být podporováno (předpokládejme více jazyků), existuje jen velmi málo řešení. Myslím, že Mike Kramar odvedl skvělou práci při vytváření základního UDF, které vám poskytne dobrý způsob, jak problém vyřešit, ale byl jsem příjemně překvapen, když jsem našel robustnější komerční nabídku – a zjistil jsem, že je velmi stabilní, dokonce i ve formě beta. Mám v plánu provést důkladnější testy s použitím širší škály velikostí a typů dokumentů. Mezitím, pokud je zvýraznění hitů součástí vašich požadavků na aplikaci, měli byste vyzkoušet UDF Mika Kramara a zvážit použití ThinkHighlight na testovací jízdu.