Existuje mnoho případů použití pro generování posloupnosti hodnot v SQL Server. Nemluvím o přetrvávající IDENTITY sloupec (nebo nový SEQUENCE v SQL Server 2012), ale spíše přechodnou sadu, která se má používat pouze po dobu životnosti dotazu. Nebo dokonce v nejjednodušších případech – jako je pouhé připojení čísla řádku ke každému řádku v sadě výsledků – které mohou zahrnovat přidání ROW_NUMBER() funkce na dotaz (nebo ještě lépe v prezentační vrstvě, která stejně musí procházet výsledky řádek po řádku).
Mluvím o trochu složitějších případech. Můžete mít například sestavu, která zobrazuje prodeje podle data. Typický dotaz může být:
SELECT OrderDate = CONVERT(DATE, OrderDate), OrderCount = COUNT(*) FROM dbo.Orders GROUP BY CONVERT(DATE, OrderDate) ORDER BY OrderDate;
Problém s tímto dotazem je, že pokud v určitý den nebudou žádné objednávky, nebude pro tento den žádný řádek. To může vést ke zmatkům, zavádějícím údajům nebo dokonce k nesprávným výpočtům (předpokládejme denní průměry) pro následné spotřebitele dat.
Je tedy potřeba vyplnit tyto mezery daty, která v datech nejsou. A někdy lidé nacpou svá data do #temp tabulky a použijí WHILE smyčka nebo kurzor k doplnění chybějících dat jeden po druhém. Nebudu zde tento kód ukazovat, protože nechci obhajovat jeho použití, ale viděl jsem to všude.
Než se však dostaneme příliš hluboko k datům, promluvme si nejprve o číslech, protože k odvození posloupnosti dat můžete vždy použít posloupnost čísel.
Tabulka čísel
Dlouho jsem byl zastáncem ukládání pomocné "tabulky čísel" na disk (a když už na to přijde, tak i kalendářové tabulky).
Zde je jeden způsob, jak vygenerovat jednoduchou číselnou tabulku s 1 000 000 hodnotami:
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id])) INTO dbo.Numbers FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 OPTION (MAXDOP 1); CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n) -- WITH (DATA_COMPRESSION = PAGE) ;
Proč MAXDOP 1? Podívejte se na blogový příspěvek Paula Whitea a jeho položku Connect týkající se cílů řádků.
Mnoho lidí je však proti přístupu pomocné tabulky. Jejich argument:proč ukládat všechna ta data na disk (a do paměti), když mohou generovat data za běhu? Moje počítadlo je být realistický a přemýšlet o tom, co optimalizujete; výpočet může být drahý a jste si jisti, že výpočet řady čísel za běhu bude vždy levnější? Pokud jde o místo, tabulka Numbers zabírá pouze asi 11 MB komprimovaná a 17 MB nekomprimovaná. A pokud se na tabulku odkazuje dostatečně často, měla by být vždy v paměti, aby byl přístup rychlý.
Podívejme se na několik příkladů a některé z běžnějších přístupů používaných k jejich uspokojení. Doufám, že se všichni shodneme na tom, že ani při 1000 hodnotách nechceme tyto problémy řešit pomocí smyčky nebo kurzoru.
Generování sekvence 1 000 čísel
Začněme jednoduše, vygenerujme sadu čísel od 1 do 1 000.
Tabulka čísel
Samozřejmě s tabulkou čísel je tento úkol docela jednoduchý:
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
Plán:
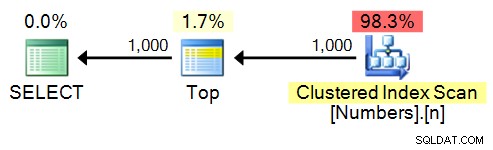
spt_values
Toto je tabulka, kterou používají interní uložené procedury pro různé účely. Jeho použití online se zdá být docela převládající, i když je nezdokumentované, nepodporované, může jednoho dne zmizet, a protože obsahuje pouze konečný, nejedinečný a nesouvislý soubor hodnot. SQL Server 2008 R2 má 2 164 jedinečných a 2 508 celkových hodnot; v roce 2012 je jich 2 167 unikátních a 2 515 celkem. To zahrnuje duplikáty, záporné hodnoty, a to i v případě použití DISTINCT , spousta mezer, jakmile se dostanete za číslo 2 048. Řešením je tedy použít ROW_NUMBER() vygenerovat souvislou sekvenci začínající na 1 na základě hodnot v tabulce.
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number) FROM [master]..spt_values ORDER BY n;
Plán:

To znamená, že pouze pro 1 000 hodnot můžete napsat o něco jednodušší dotaz pro vygenerování stejné sekvence:
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
To samozřejmě vede k jednoduššímu plánu, ale velmi rychle se rozpadne (když vaše sekvence musí mít více než 2 048 řádků):
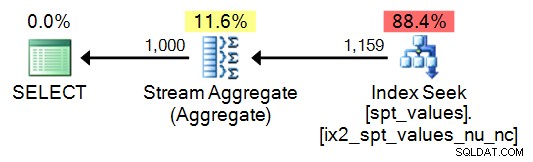
V žádném případě použití této tabulky nedoporučuji; Zahrnuji to pro účely srovnání, jen proto, že vím, kolik toho je venku a jak lákavé by mohlo být znovu použít kód, na který narazíte.
sys.all_objects
Dalším přístupem, který byl v průběhu let jedním z mých oblíbených, je použití sys.all_objects . Jako spt_values , neexistuje žádný spolehlivý způsob, jak přímo vygenerovat souvislou sekvenci, a máme stejné problémy, které se týkají konečné množiny (necelých 2 000 řádků v SQL Server 2008 R2 a něco málo přes 2 000 řádků v SQL Server 2012), ale pro 1 000 řádků můžeme použít stejné ROW_NUMBER() trik. Důvod, proč se mi tento přístup líbí, je ten, že (a) existuje menší obava, že tento pohled v brzké době zmizí, (b) samotný pohled je zdokumentován a podporován a (c) poběží na jakékoli databázi na jakékoli verzi od SQL Server 2005 bez nutnosti překračovat hranice databáze (včetně obsažených databází).
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
Plán:

Naskládané CTE
Věřím, že Itzik Ben-Gan si za tento přístup zaslouží nejvyšší uznání; v podstatě vytvoříte CTE s malou sadou hodnot, pak vytvoříte kartézský součin proti sobě, abyste vygenerovali počet řádků, které potřebujete. A znovu, místo abychom se pokoušeli vygenerovat souvislou sadu jako součást základního dotazu, stačí použít ROW_NUMBER() ke konečnému výsledku.
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n; Plán:
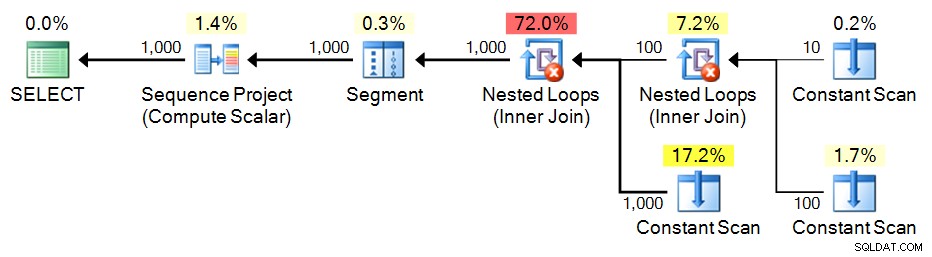
Rekurzivní CTE
Nakonec máme rekurzivní CTE, který používá 1 jako kotvu a přidává 1, dokud nedosáhneme maxima. Pro bezpečnost uvádím maximum v obou WHERE klauzule rekurzivní části a v MAXRECURSION nastavení. V závislosti na tom, kolik čísel potřebujete, možná budete muset nastavit MAXRECURSION na 0 .
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000); Plán:
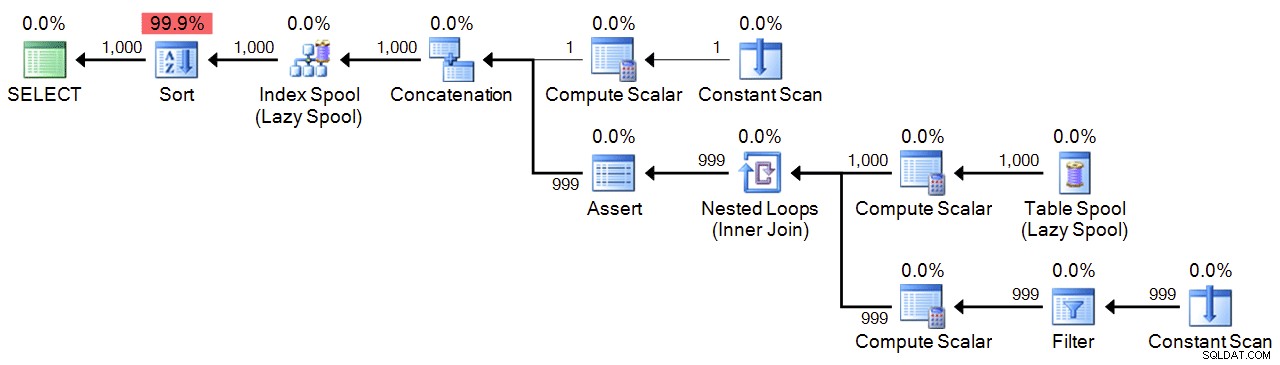
Výkon
Samozřejmě s 1 000 hodnotami jsou rozdíly ve výkonu zanedbatelné, ale může být užitečné podívat se, jak fungují tyto různé možnosti:
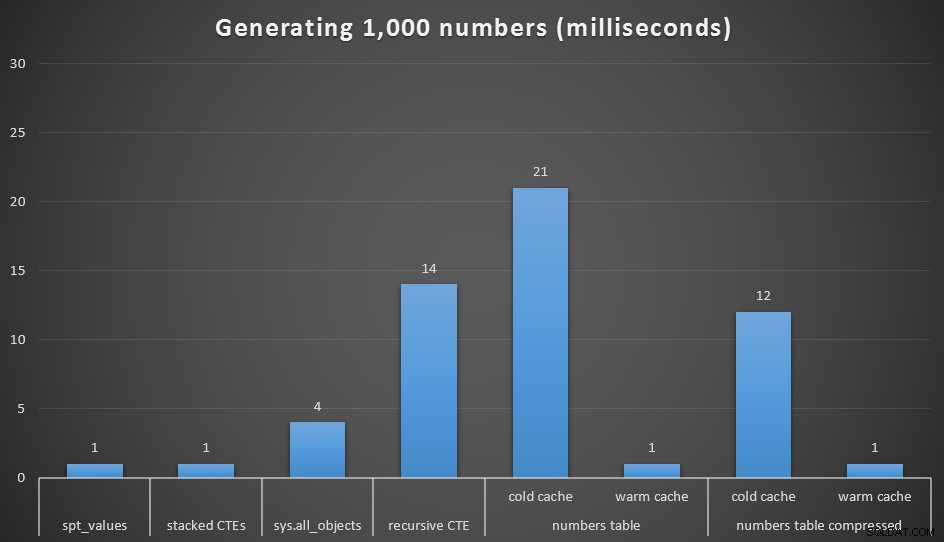
Běh v milisekundách pro vygenerování 1 000 po sobě jdoucích čísel
Spustil jsem každý dotaz 20krát a zabral jsem průměrné doby běhu. Také jsem testoval dbo.Numbers tabulky, v komprimovaném i nekomprimovaném formátu a s chladnou i teplou mezipamětí. Díky teplé mezipaměti se velmi těsně vyrovná ostatním nejrychlejším možnostem (spt_values , nedoporučované a naskládané CTE), ale první zásah je poměrně drahý (i když se tomu tak říkám skoro směji).
Pokračování…
Pokud je toto váš typický případ použití a nebudete se pouštět daleko za 1 000 řádků, pak doufám, že jsem ukázal nejrychlejší způsoby, jak tato čísla generovat. Pokud je váš případ použití větší číslo nebo pokud hledáte řešení pro generování sekvencí dat, zůstaňte naladěni. Později v této sérii prozkoumám generování sekvencí 50 000 a 1 000 000 čísel a rozsahů dat od týdne do roku.
[ Část 1 | Část 2 | Část 3 ]