Téměř před rokem na den jsem zveřejnil své řešení stránkování na SQL Server, které zahrnovalo použití CTE k vyhledání pouze klíčových hodnot pro danou sadu řádků a následné připojení zpět z CTE ke zdrojové tabulce za účelem získání ostatní sloupce pouze pro tuto "stránku" řádků. To se ukázalo jako nejpřínosnější, když existoval úzký index, který podporoval řazení požadované uživatelem, nebo když bylo řazení založeno na shlukovacím klíči, ale dokonce fungovalo o něco lépe bez indexu, který by podporoval požadované řazení.
Od té doby jsem přemýšlel, zda indexy ColumnStore (shlukované i neklastrované) mohou pomoci některému z těchto scénářů. TL;DR :Na základě tohoto izolovaného experimentu je odpověď na název tohoto příspěvku jasné NE . Pokud nechcete vidět nastavení testu, kód, prováděcí plány nebo grafy, klidně přeskočte na můj souhrn a mějte na paměti, že moje analýza je založena na velmi specifickém případu použití.
Nastavení
Na novém virtuálním počítači s nainstalovaným SQL Server 2016 CTP 3.2 (13.0.900.73) jsem prošel zhruba stejným nastavením jako předtím, ale tentokrát se třemi tabulkami. Za prvé, tradiční tabulka s úzkým shlukovacím klíčem a několika podpůrnými indexy:
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Dále tabulka s seskupeným indexem ColumnStore:
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
A nakonec tabulka s neshlukovaným indexem ColumnStore pokrývajícím všechny sloupce:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); Všimněte si, že u obou tabulek s indexy ColumnStore jsem vynechal index, který by podporoval rychlejší vyhledávání v řazení "PhoneBook" (příjmení, jméno).
Testovací data
Poté jsem naplnil první tabulku 1 000 000 náhodnými řádky na základě skriptu, který jsem znovu použil z předchozích příspěvků:
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; Pak jsem tuto tabulku použil k naplnění dalších dvou přesně stejnými daty a znovu sestavil všechny indexy:
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Celková velikost každé tabulky:
| Tabulka | Rezervováno | Data | Index |
|---|---|---|---|
| Zákazníci | 463 200 kB | 154 344 kB | 308 576 kB |
| Customers_CCI | 117 280 kB | 30 288 kB | 86 536 kB |
| Customers_NCCI | 349 480 kB | 154 344 kB | 194 976 kB |
A počet řádků / počet stránek relevantních indexů (jedinečný index v e-mailu byl pro mě více než cokoli jiného k tomu, abych hlídal můj vlastní skript pro generování dat):
| Tabulka | Index | Řádky | Stránky |
|---|---|---|---|
| Zákazníci | PK_Customers | 1 000 000 | 19 377 |
| Zákazníci | PhoneBook_Customers | 1 000 000 | 17 209 |
| Zákazníci | Active_Customers | 808 012 | 13 977 |
| Customers_CCI | PK_CustomersCCI | 1 000 000 | 2 737 |
| Customers_CCI | Customers_CCI | 1 000 000 | 3 826 |
| Customers_NCCI | PK_CustomersNCCI | 1 000 000 | 19 377 |
| Customers_NCCI | Customers_NCCI | 1 000 000 | 16 971 |
Postupy
Poté, abych zjistil, zda se indexy ColumnStore zapojí a vylepší některý ze scénářů, spustil jsem stejnou sadu dotazů jako předtím, ale nyní proti všem třem tabulkám. Byl jsem alespoň trochu chytřejší a vytvořil jsem dvě uložené procedury s dynamickým SQL, abych přijal zdroj tabulky a pořadí řazení. (Jsem si dobře vědom SQL injection; to není to, co bych dělal ve výrobě, kdyby tyto řetězce pocházely od koncového uživatele, takže to prosím neberte jako doporučení, abych tak učinil. Dost si věřím ve své v uzavřeném prostředí, že se to těchto testů netýká.)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
Pak jsem vybičoval nějaké dynamičtější SQL, abych vygeneroval všechny kombinace volání, které bych potřeboval provést, abych mohl volat staré i nové uložené procedury, ve všech třech požadovaných pořadích řazení a na různých číslech stránek (abych simuloval potřebu stránka poblíž začátku, středu a konce pořadí řazení). Abych mohl zkopírovat PRINT výstup a vložte jej do SQL Sentry Plan Explorer, abych získal metriky za běhu, spustil jsem tuto dávku dvakrát, jednou pomocí procedures CTE pomocí P_Old a poté znovu pomocí P_CTE .
DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
Výsledkem byl výstup podobný tomuto (celkem 36 volání staré metody (P_Old ) a volá 36 novou metodu (P_CTE )):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
Vím, je to všechno velmi těžkopádné; brzy se dostaneme k pointě, slibuji.
Výsledky
Vzal jsem tyto dvě sady 36 příkazů a zahájil dvě nové relace v Průzkumníkovi plánu, každou sadu jsem spustil několikrát, abych se ujistil, že získáváme data z teplé mezipaměti a bereme průměry (mohl jsem porovnat i studenou a teplou mezipaměť, ale myslím, že existují dost proměnných zde).
Mohu vám hned zkraje říct pár jednoduchých faktů, aniž bych vám ukázal podpůrné grafy nebo plány:
- V žádném případě „stará“ metoda nepřekonala novou metodu CTE Ve svém předchozím příspěvku jsem propagoval, bez ohledu na to, jaký typ indexů byl přítomen. Díky tomu je snadné prakticky ignorovat polovinu výsledků, alespoň pokud jde o trvání (což je metrika, o kterou se koncoví uživatelé nejvíce zajímají).
- Žádnému indexu ColumnStore se při stránkování ke konci výsledku nevedlo dobře – výhody poskytovaly pouze na začátku a pouze v několika případech.
- Při řazení podle primárního klíče (seskupené nebo ne), přítomnost indexů ColumnStore nepomohla – opět z hlediska trvání.
Když už jsou tato shrnutí z cesty, pojďme se podívat na několik průřezů dat o trvání. Za prvé, výsledky dotazu seřazené podle křestního jména sestupně, potom e-mailu, bez naděje na použití existujícího indexu pro řazení. Jak můžete vidět v grafu, výkon byl nekonzistentní – s nižším počtem stránek se nejlépe dařilo neklastrovanému ColumnStore; při vyšších číslech stránek vždy zvítězil tradiční index:
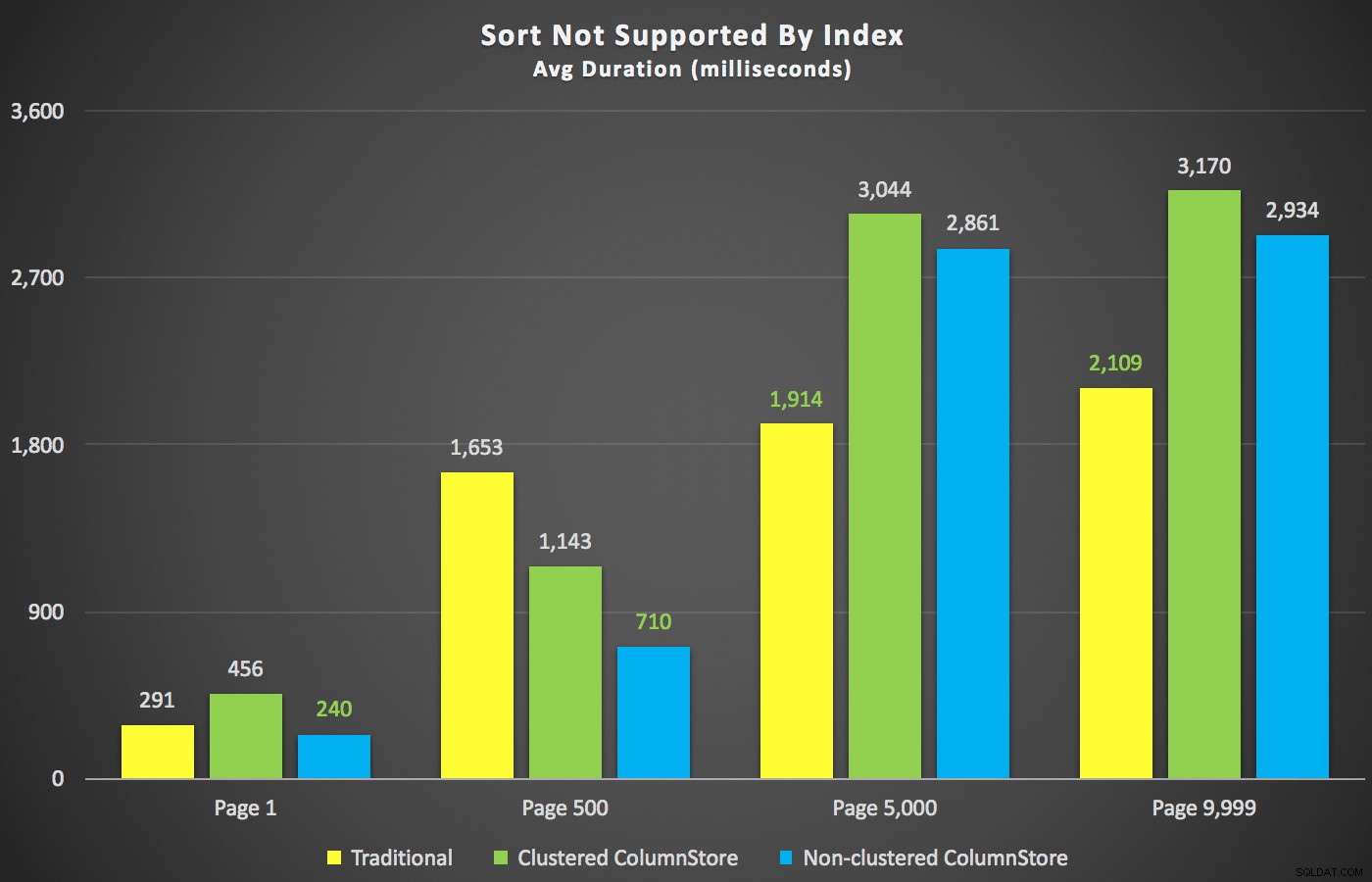 Délka (milisekundy) pro různá čísla stránek a různé typy indexů
Délka (milisekundy) pro různá čísla stránek a různé typy indexů
A pak tři plány představující tři různé typy indexů (se stupni šedi přidanými Photoshopem, aby se zvýraznily hlavní rozdíly mezi plány):
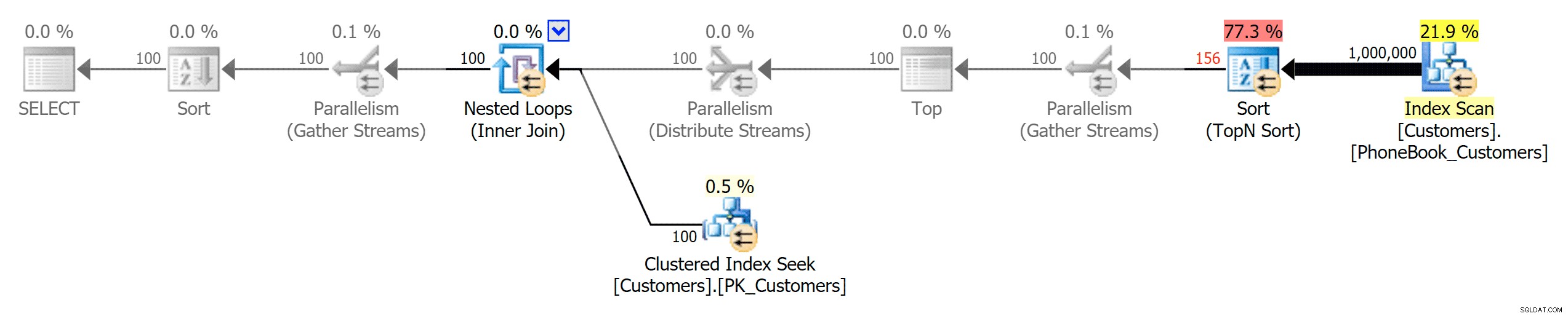 Plán pro tradiční index
Plán pro tradiční index
 Plán pro seskupený index ColumnStore
Plán pro seskupený index ColumnStore
 Plán pro neklastrovaný index ColumnStore
Plán pro neklastrovaný index ColumnStore
Scénář, který mě více zajímal, ještě než jsem začal testovat, byl přístup k třídění podle telefonního seznamu (příjmení, jméno). V tomto případě byly indexy ColumnStore ve skutečnosti docela škodlivé pro výkon výsledku:
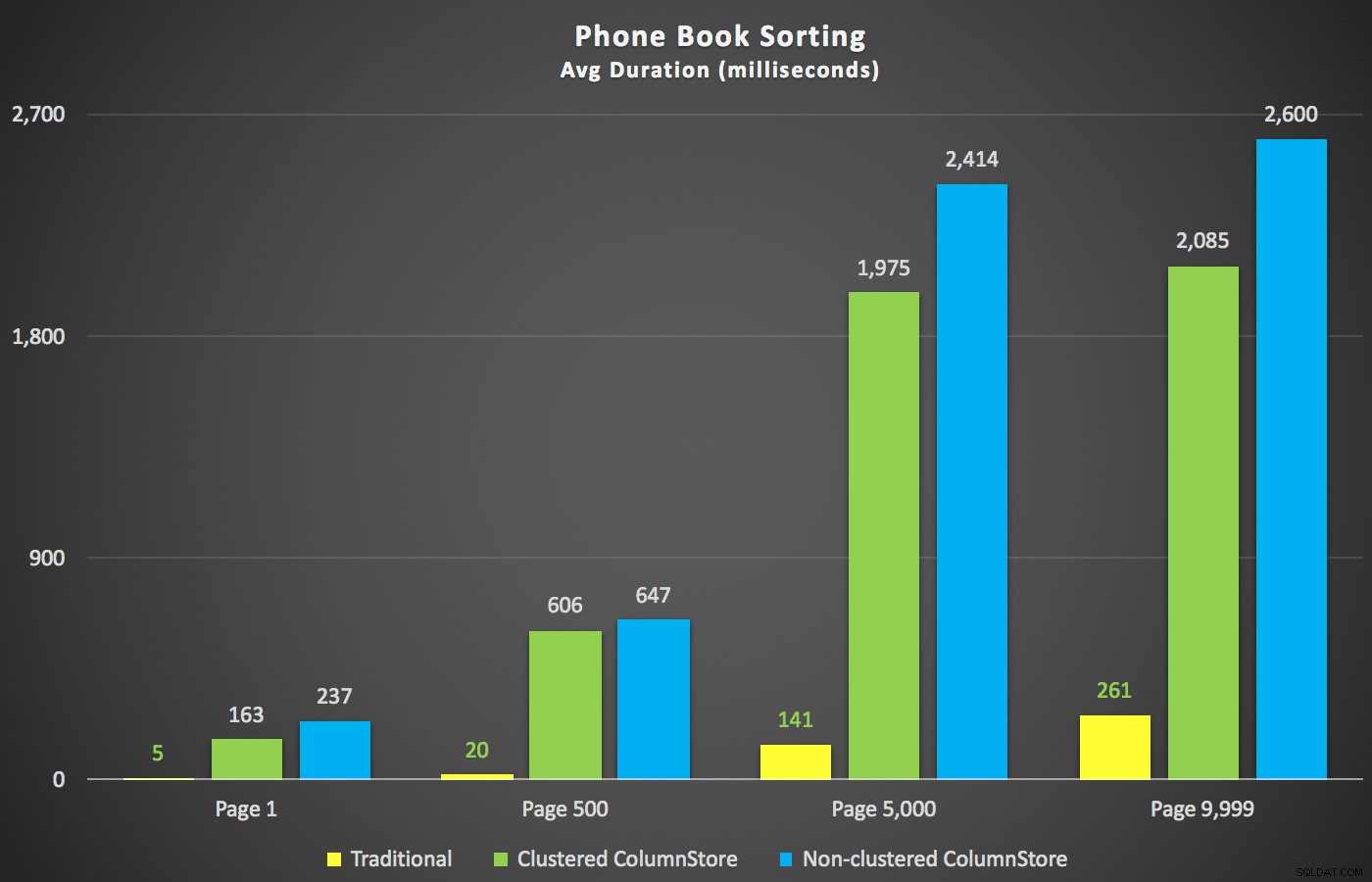
Plány ColumnStore zde jsou téměř zrcadlové obrazy dvou plánů ColumnStore uvedených výše pro nepodporované řazení. Důvod je v obou případech stejný:drahé skenování nebo řazení kvůli nedostatku indexu podporujícího řazení.
Dále jsem vytvořil podpůrné indexy „PhoneBook“ na tabulkách také s indexy ColumnStore, abych zjistil, zda bych v některém z těchto scénářů mohl přemluvit jiný plán a/nebo rychlejší doby provádění. Vytvořil jsem tyto dva indexy a poté jsem je znovu sestavil:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Zde byly nové doby trvání:
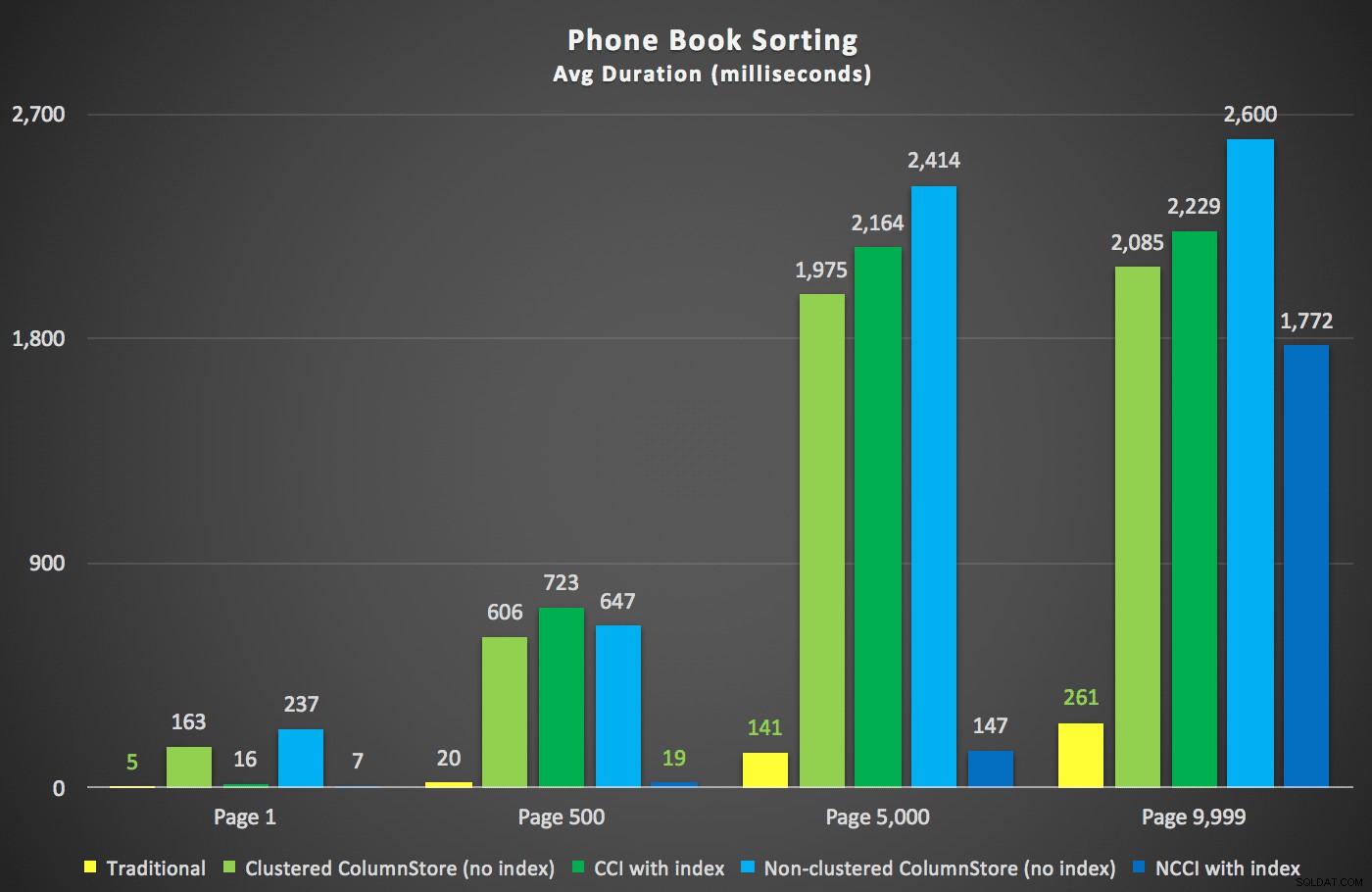
Nejzajímavější je, že nyní se zdá, že stránkovací dotaz na tabulku s neklastrovaným indexem ColumnStore drží krok s tradičním indexem, dokud se nedostaneme za střed tabulky. Při pohledu na plány můžeme vidět, že na stránce 5 000 se používá tradiční skenování indexu a index ColumnStore je zcela ignorován:
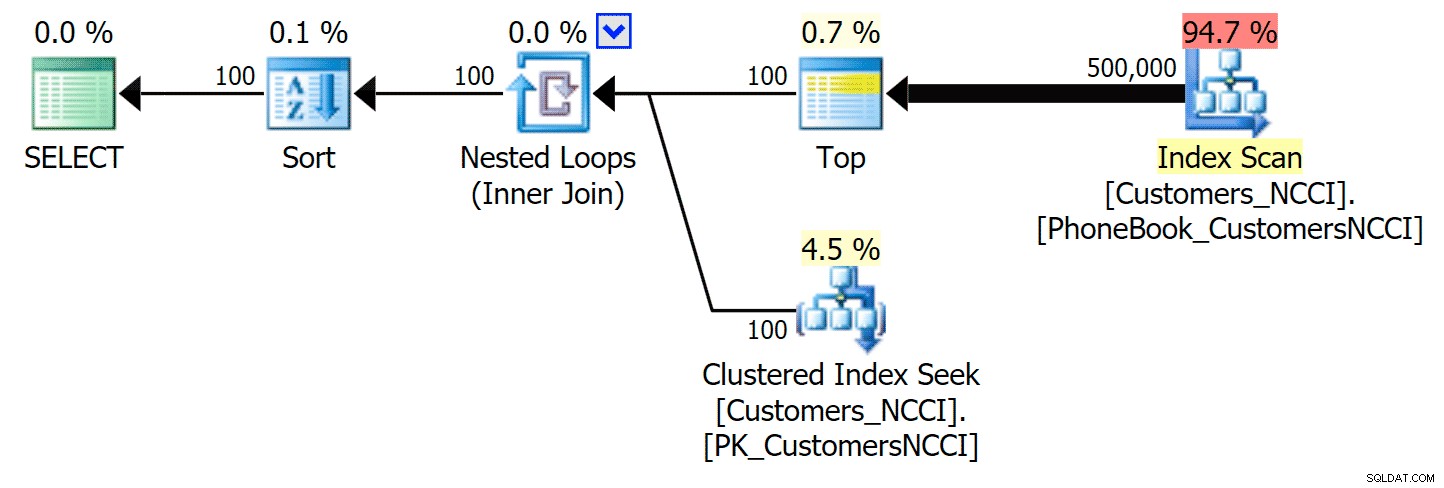 Plán telefonního seznamu ignoruje index ColumnStore bez klastrů
Plán telefonního seznamu ignoruje index ColumnStore bez klastrů
Ale někde mezi středem 5 000 stránek a „koncem“ tabulky na 9 999 stránkách optimalizátor narazil na jakýsi bod zlomu a – pro úplně stejný dotaz – nyní volí skenování neshlukovaného indexu ColumnStore. :
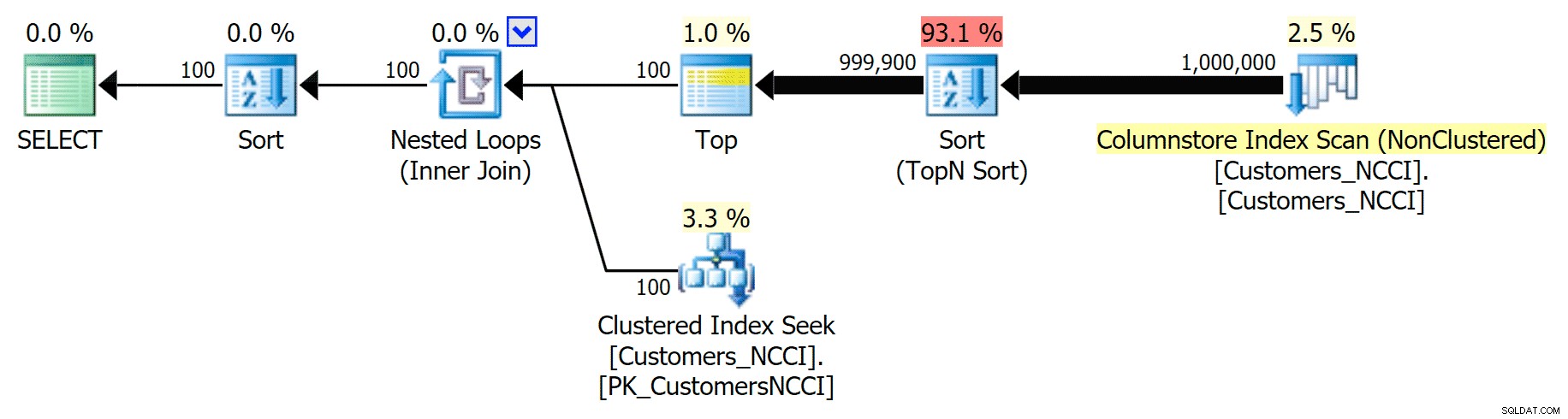 Tipy pro plán telefonního seznamu a používá index ColumnStore
Tipy pro plán telefonního seznamu a používá index ColumnStore
To se ukázalo jako nepříliš skvělé rozhodnutí optimalizátoru, především kvůli nákladům na operaci řazení. Můžete vidět, o kolik se trvání prodlouží, když naznačíte běžný index:
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... Výsledkem je následující plán, téměř identický s prvním plánem výše (i když o něco vyšší náklady na skenování, jednoduše proto, že je zde více výstupu):
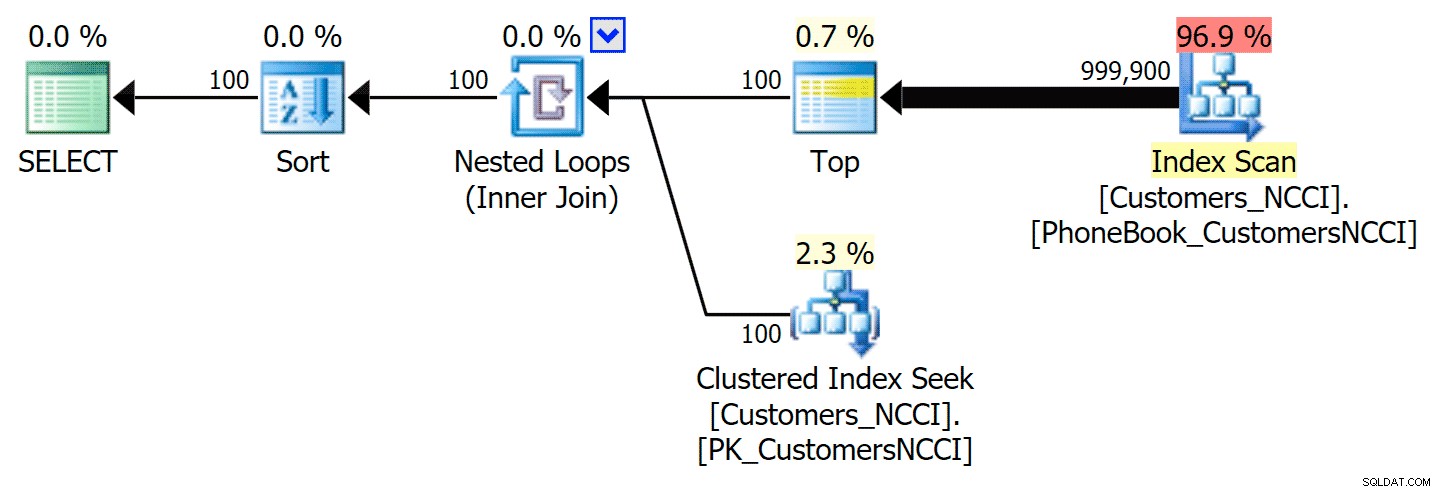 Plán telefonního seznamu s naznačeným rejstříkem
Plán telefonního seznamu s naznačeným rejstříkem
Toho můžete dosáhnout pomocí OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) místo explicitní nápovědy indexu. Jen mějte na paměti, že je to stejné, jako kdybyste tam neměli index ColumnStore.
Závěr
I když výše existuje několik okrajových případů, kdy by se index ColumnStore mohl (sotva) vyplatit, nezdá se mi, že by se pro tento konkrétní scénář stránkování dobře hodily. Myslím, že nejdůležitější je, že zatímco ColumnStore vykazuje značné úspory místa díky kompresi, výkon za běhu není fantastický kvůli požadavkům na řazení (i když se odhaduje, že tato řazení poběží v dávkovém režimu, což je nová optimalizace pro SQL Server 2016).
Obecně by to mohlo znamenat mnohem více času stráveného výzkumem a testováním; na pozadí předchozích článků jsem chtěl změnit co nejméně. Rád bych například našel ten bod zlomu a také bych rád uznal, že to nejsou zrovna rozsáhlé testy (kvůli velikosti virtuálního počítače a omezení paměti) a že jsem vás nechal hádat o spoustě metriky za běhu (většinou pro stručnost, ale nevím, že by vám opravdu napověděla tabulka čtení, která nejsou vždy úměrná trvání). Tyto testy také předpokládají luxus SSD, dostatečnou paměť, vždy teplou mezipaměť a prostředí pro jednoho uživatele. Opravdu bych rád provedl větší baterii testů proti většímu množství dat, na větších serverech s pomalejšími disky a instancemi s menší pamětí, a to vše při simulovaném souběžném běhu.
To znamená, že to může být také jen scénář, který ColumnStore není navržen tak, aby pomohl vyřešit v první řadě, protože základní řešení s tradičními indexy je již docela účinné při vytahování úzké sady řádků – ne zrovna kormidelna ColumnStore. Možná další proměnná, kterou je třeba do matice přidat, je velikost stránky – všechny výše uvedené testy vytáhnou 100 řádků najednou, ale co když jsme po 10 000 nebo 100 000 řádcích najednou, bez ohledu na to, jak velká je podkladová tabulka?
Máte situaci, kdy se vaše zátěž OLTP zlepšila pouhým přidáním indexů ColumnStore? Vím, že jsou navrženy pro pracovní zátěž ve stylu datových skladů, ale pokud jste viděli výhody jinde, rád bych slyšel o vašem scénáři a zjistil, zda mohu do svého testovacího zařízení začlenit nějaké odlišovače.