Začátkem tohoto měsíce jsem publikoval tip na něco, co bychom si pravděpodobně všichni přáli, abychom nemuseli:třídit nebo odstraňovat duplikáty z řetězců s oddělovači, obvykle zahrnující uživatelsky definované funkce (UDF). Někdy je potřeba seznam znovu sestavit (bez duplikátů) v abecedním pořadí a někdy může být nutné zachovat původní pořadí (může to být například seznam klíčových sloupců ve špatném indexu).
Pro své řešení, které řeší oba scénáře, jsem použil číselnou tabulku spolu s dvojicí uživatelsky definovaných funkcí (UDF) – jedna pro rozdělení řetězce a druhá pro jeho opětovné sestavení. Tento tip můžete vidět zde:
- Odebrání duplikátů z řetězců v SQL Server
Samozřejmě existuje několik způsobů, jak tento problém vyřešit; Poskytoval jsem pouze jednu metodu, kterou jsem mohl vyzkoušet, pokud jste uvízli u těchto strukturních dat. @Phil_Factor z Red-Gate navázal rychlým příspěvkem ukazujícím jeho přístup, který se vyhýbá funkcím a tabulkám čísel a místo toho volí inline manipulaci s XML. Říká, že dává přednost dotazům s jedním příkazem a vyhýbá se jak funkcím, tak zpracování řádku po řádku:
- Odstranění duplicitních seznamů s oddělovači v SQL Server
Poté čtenář Steve Mangiameli zveřejnil řešení smyčkování jako komentář k tipu. Jeho úvaha byla taková, že použití číselné tabulky se mu zdálo přetechnizované.
Všichni tři jsme nedokázali vyřešit jeden aspekt, který bude obvykle docela důležitý, pokud úkol provádíte dostatečně často nebo na jakékoli úrovni:výkon .
Testování
Byl jsem zvědavý, jak dobře by si inline XML a cyklické přístupy vedly ve srovnání s mým řešením založeným na tabulkách čísel, zkonstruoval jsem fiktivní tabulku, abych provedl nějaké testy; mým cílem bylo 5 000 řádků s průměrnou délkou řetězce větší než 250 znaků a alespoň 10 prvků v každém řetězci. S velmi krátkým cyklem experimentů jsem byl schopen dosáhnout něčeho velmi blízkého tomuto s následujícím kódem:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 To vytvořilo tabulku s ukázkovými řádky vypadajícími takto (hodnoty zkráceny):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
Data jako celek měla následující profil, který by měl být dostatečně dobrý, aby odhalil případné problémy s výkonem:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Všimněte si, že jsem přešel na varchar zde z nvarchar v původním článku, protože vzorky, které Phil a Steve dodali, předpokládali varchar , řetězce omezující pouze 255 nebo 8000 znaků, jednoznakové oddělovače atd. Naučil jsem se tvrdě, že pokud převezmete něčí funkci a zahrnete ji do porovnávání výkonu, změníte tak málo, možné – ideálně nic. Ve skutečnosti bych vždy používal nvarchar a nepředpokládejte nic o nejdelším možném řetězci. V tomto případě jsem věděl, že nepřicházím o žádná data, protože nejdelší řetězec má pouze 2 905 znaků a v této databázi nemám žádné tabulky ani sloupce, které používají znaky Unicode.
Dále jsem vytvořil své funkce (které vyžadují tabulku čísel). Čtenář si všiml problému ve funkci v mém tipu, kde jsem předpokládal, že oddělovač bude vždy jeden znak, a zde to opravil. Také jsem převedl téměř vše na varchar(8000) vyrovnat podmínky, pokud jde o typy a délky strun.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO Dále jsem vytvořil jedinou funkci s inline tabulkovou hodnotou, která kombinovala dvě výše uvedené funkce, něco, co bych si nyní přál udělat v původním článku, abych se skalární funkci úplně vyhnul. (I když je pravda, že ne všechny skalární funkce jsou v měřítku hrozné, existuje jen velmi málo výjimek.)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
Vytvořil jsem také samostatné verze inline TVF, které byly vyhrazeny pro každou ze dvou možností řazení, abych se vyhnul nestálosti CASE výraz, ale ukázalo se, že to nemá vůbec dramatický dopad.
Pak jsem vytvořil Stevovy dvě funkce:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
Poté jsem Philovy přímé dotazy vložil do svého testovacího zařízení (všimněte si, že jeho dotazy kódují < jako < chránit je před chybami analýzy XML, ale nekódují > nebo & – Přidal jsem zástupné symboly pro případ, že se potřebujete chránit před řetězci, které mohou potenciálně obsahovat tyto problematické znaky):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
Testovací zařízení byly v podstatě tyto dva dotazy a také následující volání funkcí. Jakmile jsem ověřil, že všechny vracejí stejná data, proložil jsem skript s DATEDIFF výstup a zaprotokoloval jej do tabulky:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above A pak jsem provedl testy výkonu na dvou různých systémech (jeden čtyřjádrový s 8 GB a jeden 8jádrový virtuální počítač s 32 GB) a v každém případě na SQL Server 2012 a SQL Server 2016 CTP 3.2 (13.0.900.73).
Výsledky
Výsledky, které jsem pozoroval, jsou shrnuty v následujícím grafu, který ukazuje trvání každého typu dotazu v milisekundách, zprůměrované v abecedním a původním pořadí, čtyři kombinace server/verze a sérii 15 spuštění pro každou permutaci. Kliknutím zvětšíte:
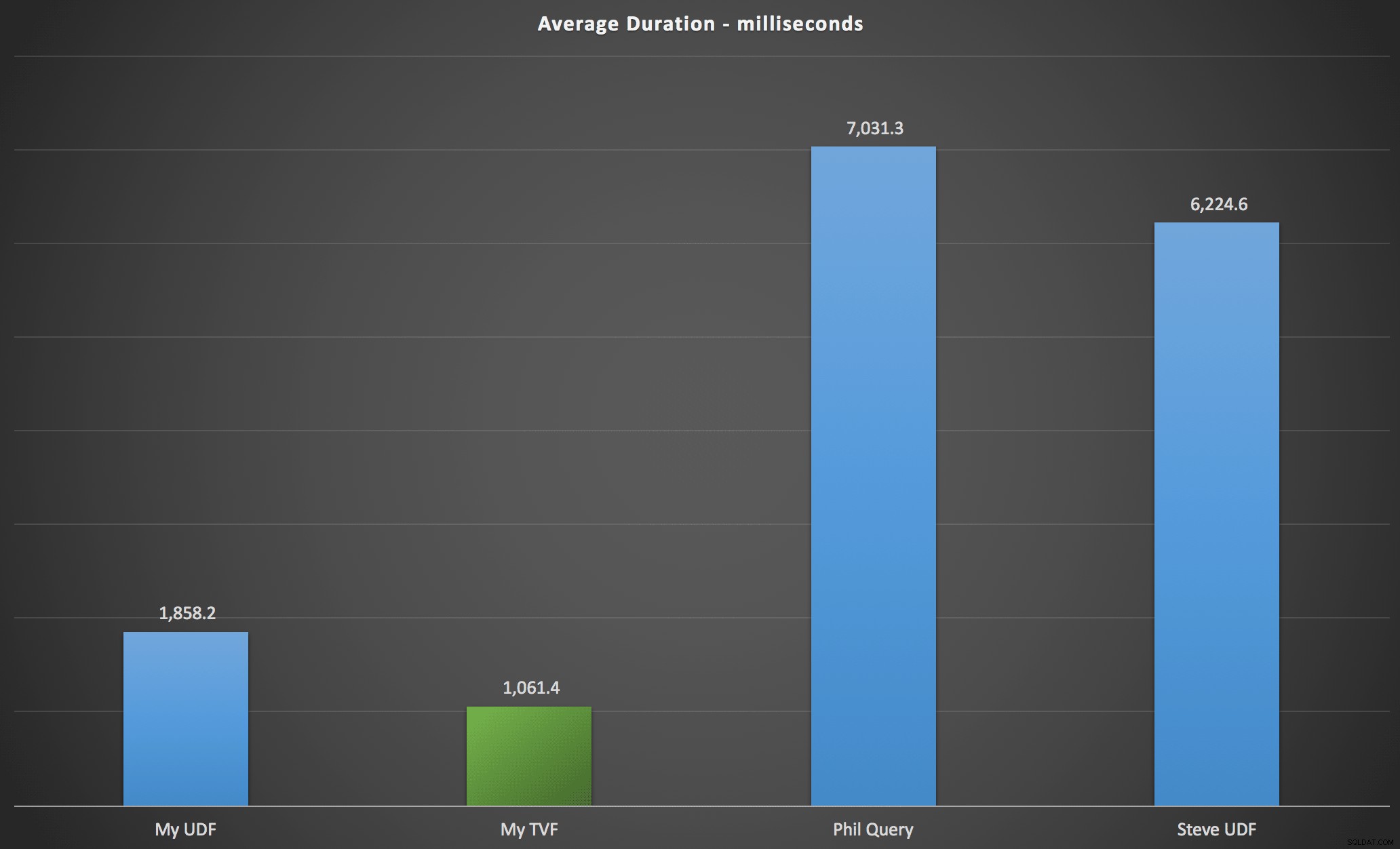
To ukazuje, že tabulka s čísly, přestože byla považována za přepracovanou, ve skutečnosti poskytla nejúčinnější řešení (alespoň pokud jde o trvání). To bylo samozřejmě lepší s jediným TVF, který jsem implementoval nedávno, než s vnořenými funkcemi z původního článku, ale obě řešení se pohybují kolem dvou alternativ.
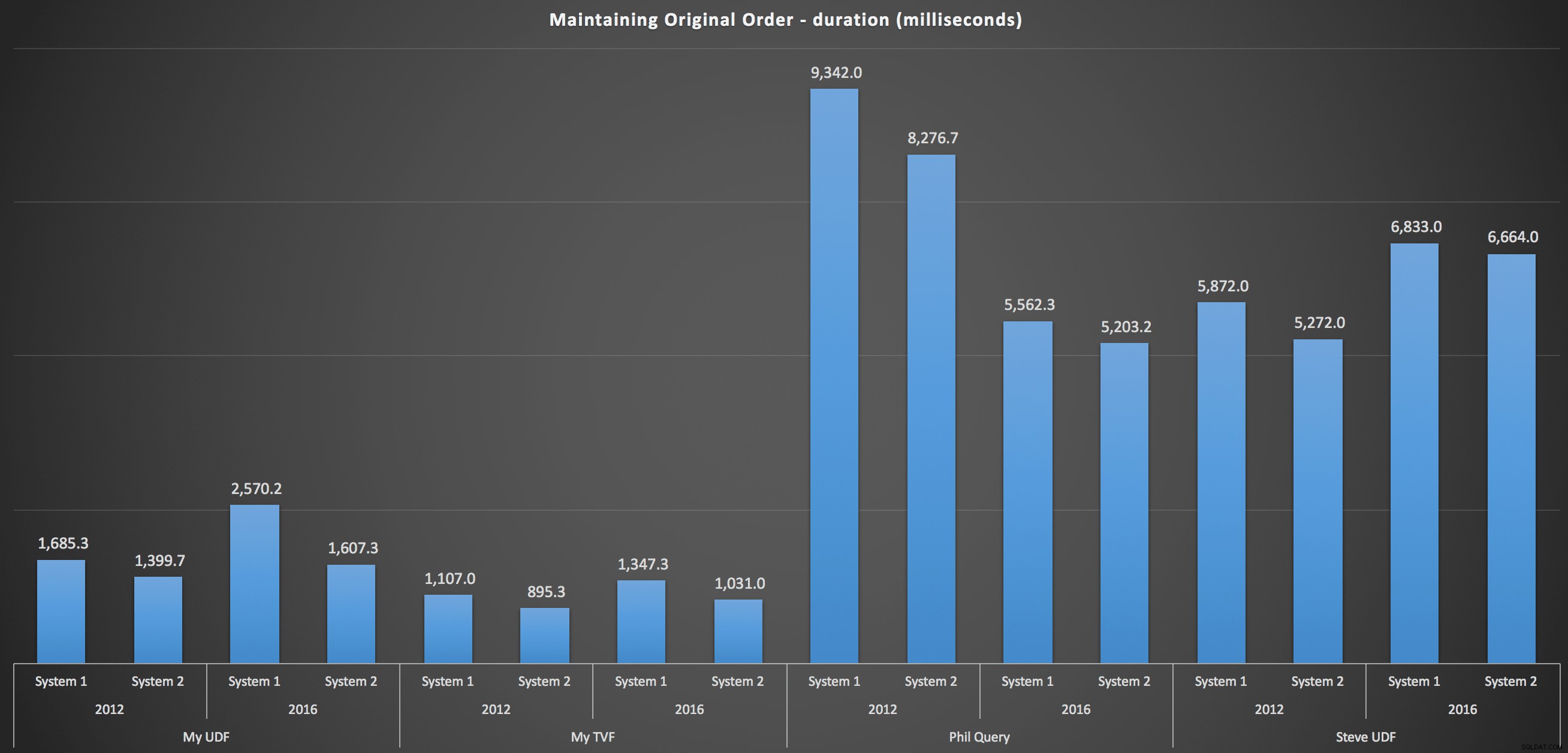
Chcete-li se dostat do podrobností, zde jsou rozdělení pro každý počítač, verzi a typ dotazu pro zachování původního pořadí:
…a pro opětovné sestavení seznamu v abecedním pořadí:
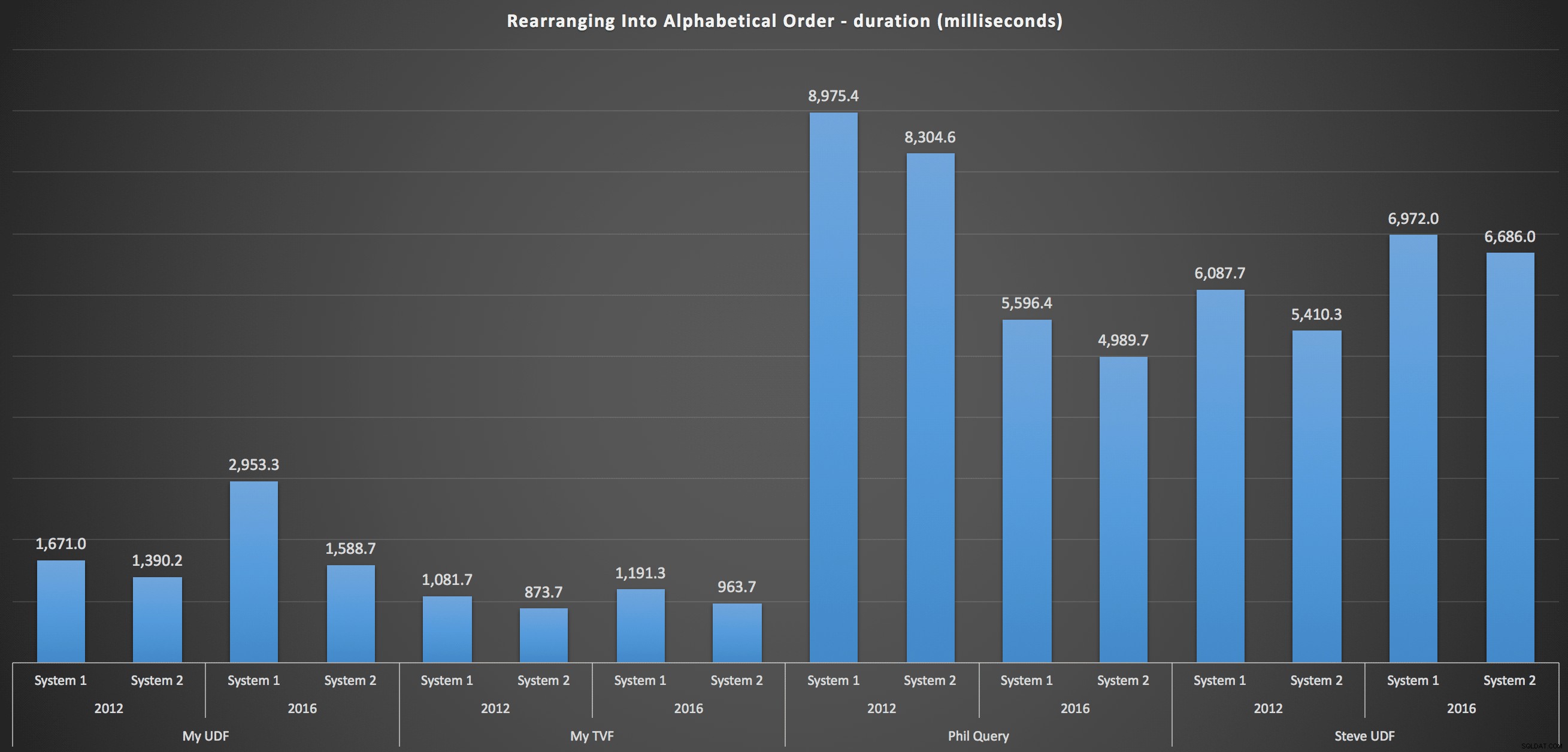
Ty ukazují, že volba řazení měla malý dopad na výsledek – oba grafy jsou prakticky totožné. A to dává smysl, protože vzhledem k formě vstupních dat neexistuje žádný index, který bych si dokázal představit, že by třídění zefektivnil – je to iterativní přístup bez ohledu na to, jak je rozdělujete nebo jak vracíte data. Ale je jasné, že některé iterativní přístupy mohou být obecně horší než jiné, a není to nutně použití UDF (nebo tabulky čísel), které je činí takovými.
Závěr
Dokud nebudeme mít na serveru SQL Server nativní funkce rozdělení a zřetězení, budeme k dokončení práce používat všechny druhy neintuitivních metod, včetně funkcí definovaných uživatelem. Pokud pracujete s jedním řetězcem najednou, neuvidíte velký rozdíl. Ale jak se budou vaše data škálovat, bude stát za to otestovat různé přístupy (a v žádném případě netvrdím, že výše uvedené metody jsou ty nejlepší, které najdete – ani jsem se nedíval například na CLR, resp. další přístupy T-SQL z této řady).