Poznámka:Tento příspěvek byl původně publikován pouze v naší elektronické knize, High Performance Techniques for SQL Server, Volume 4. O našich elektronických knihách se můžete dozvědět zde.
Pravidelně dostávám otázku:"Kde mám začít, když dojde na pokus o vyladění instance SQL Server?" Moje první odpověď je zeptat se jich na konfiguraci jejich instance. Pokud některé věci nejsou správně nakonfigurovány, může být zbytečným úsilím začít se ihned zabývat dlouhotrvajícími nebo nákladnými dotazy.
Blogoval jsem o běžných věcech, které správcům chybí, kde sdílím mnoho nastavení, která by správci měli změnit oproti výchozí instalaci SQL Serveru. U položek souvisejících s výkonem jim říkám, že by měli zkontrolovat následující:
- Nastavení paměti
- Aktualizace statistik
- Údržba indexu
- MAXDOP a prahová hodnota nákladů pro paralelismus
- doporučené postupy tempdb
- Optimalizace pro ad hoc zátěž
Jakmile se dostanu přes konfigurační položky, zeptám se, zda se podívali na statistiky souborů a čekání a také na vysoce nákladné dotazy. Většinou je odpověď „ne“ – s vysvětlením, že si nejsou jisti, jak tyto informace najít.
Když někdo uvádí, že potřebuje vyladit SQL Server, obvykle je běžné, že běží pomalu. Co znamená pomalý? Je to určitá zpráva, konkrétní aplikace nebo všechno? Začalo se to teprve dít, nebo se to časem zhoršuje? Začnu tím, že položím obvyklé otázky třídění, jaké je využití paměti, CPU a disku ve srovnání s tím, když jsou věci normální, zda se problém právě začal dít a co se nedávno změnilo. Pokud klient nezachycuje základní linii, nemá metriky, se kterými by mohl porovnávat, aby zjistil, zda jsou aktuální statistiky abnormální.
Téměř každý SQL Server, na kterém pracuji, hostí více než jednu uživatelskou databázi. Když klient hlásí, že SQL Server běží pomalu, většinou se obává konkrétní aplikace, která způsobuje problémy jejich zákazníkům. Prudkou reakcí je okamžité zaměření na tuto konkrétní databázi, avšak často může jiný proces spotřebovávat cenné zdroje a databáze aplikace je ovlivněna. Například, pokud máte velkou databázi sestav a někdo spustil masivní sestavu, která zahlcuje disk, nakopává CPU a vyprázdní mezipaměť plánu, můžete se vsadit, že ostatní uživatelské databáze se při generování této sestavy zpomalí.
Vždy rád začnu tím, že se podívám na statistiky souborů. Pro SQL Server 2005 a vyšší se můžete dotazem na DMV sys.dm_io_virtual_file_stats získat statistiky I/O pro jednotlivá data a soubor protokolu. Tento DMV nahradil funkci fn_virtualfilestats. K zachycení statistik souborů rád používám skript, který dal dohromady Paul Randal:zachycování IO latence po určitou dobu. Tento skript zachytí základní linii a o 30 minut později (pokud nezměníte dobu trvání v sekci WAITFOR DELAY) zachytí statistiky a vypočítá rozdíly mezi nimi. Paulův skript také trochu počítá s určením latence čtení a zápisu, což nám usnadňuje čtení a porozumění.
Na svém notebooku jsem obnovil kopii databáze AdventureWorks2014 na USB disk, abych měl nižší rychlost disku; Poté jsem spustil proces, který proti němu vytvoří zátěž. Níže můžete vidět výsledky, kde moje latence zápisu pro můj datový soubor je 240 ms a latence zápisu pro můj soubor protokolu je 46 ms. Takto vysoké latence jsou problematické.
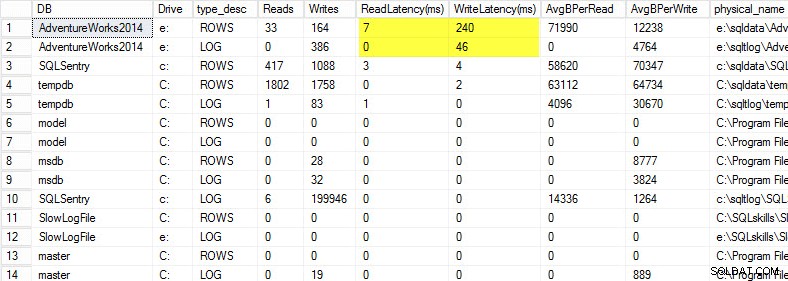
Cokoli nad 20 ms by mělo být považováno za špatné, jak jsem sdílel v předchozím příspěvku:sledování latence čtení/zápisu. Moje latence čtení je slušná, ale databáze AdventureWorks2014 trpí pomalým zápisem. V tomto případě bych prozkoumal, co generuje zápisy, a také prozkoumal výkon mého I/O subsystému. Pokud by to byly příliš vysoké latence čtení, začal bych zkoumat výkon dotazů (proč to dělá tolik čtení, například z chybějících indexů), a také celkový výkon I/O subsystému.
Je důležité znát celkový výkon vašeho I/O subsystému a nejlepší způsob, jak zjistit, čeho je schopen, je jeho porovnání. Glenn Berry o tom mluví ve svém článku analyzujícím výkon I/O pro SQL Server. Glenn vysvětluje latenci, IOPS a propustnost a ukazuje CrystalDiskMark, což je bezplatný nástroj, který můžete použít k základnímu nastavení úložiště.
Poté, co jsem zjistil, jak si vedou statistiky souborů, rád se podívám na statistiky čekání pomocí DMV sys.dm_os_wait_stats, který vrací informace o všech čekáních, ke kterým došlo. Za tímto účelem se obracím na další skript, který Paul Randal poskytuje ve svém zachycování statistik čekání na určitý časový úsek blogu. Paulův scénář za nás opět trochu počítá, ale co je důležitější, vylučuje spoustu vlídných čekání, o které se obvykle nestaráme. Tento skript má také WAITFOR DELAY a je nastaven na 30 minut. Čtení statistik čekání může být trochu složitější:Můžete mít čekání, která se na základě procenta zdají být vysoká, ale průměrné čekání je tak nízké, že se není čeho bát.
Spustil jsem stejný proces načítání a zachytil jsem statistiky čekání, které jsem ukázal níže. Pro vysvětlení mnoha z těchto typů čekání si můžete přečíst další z Paulových blogových příspěvků, statistiky čekání nebo mi prosím řekněte, kde to bolí, plus některé jeho příspěvky na tomto blogu.
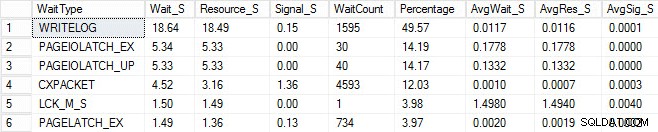
V tomto uměle vytvořeném výstupu může čekání PAGEIOLATCH indikovat úzké hrdlo mého I/O subsystému, ale může to být také problém s pamětí, hledáním prohledávání tabulek nebo řadou dalších problémů. V mém případě víme, že jde o problém s diskem, protože databázi ukládám na USB klíčenku. Čekací doba LCK_M_S je velmi vysoká, existuje však pouze jeden případ čekání. Můj WRITELOG je také vyšší, než bych si přál, ale je pochopitelné, když vím o problémech s latencí u USB flash disku. To také ukazuje, že CXPACKET čeká a bylo by snadné mít prudkou reakci a domnívat se, že máte problém s paralelismem/MAXDOP, nicméně počítadlo AvgWait_S je velmi nízké. Buďte opatrní při používání čeká na řešení problémů. Nechte to být průvodcem, který vám řekne věci, které nepředstavují problém, a zároveň vám poskytne směr, kam jít hledat problémy. Správné řešení problémů spočívá v korelaci chování z více oblastí, aby se problém zúžil.
Poté, co se podívám do souboru a statistiky čekání, začnu se zabývat otázkami s vysokými náklady na základě problémů, které jsem našel. Za tímto účelem se obracím na Diagnostické informační dotazy Glenna Berryho. Tyto sady dotazů jsou vstupními skripty, které používá mnoho konzultantů. Glenn a komunita neustále poskytují aktualizace, aby byly co nejinformativní a robustní. Jedním z mých oblíbených dotazů jsou dotazy uložené v mezipaměti podle počtu provedení. Miluji hledání dotazů nebo uložených procedur, které mají vysoký exekuční_počet spojený s vysokým total_logical_reads. Pokud mají tyto dotazy možnosti ladění, můžete server rychle změnit. Ve skriptech jsou také zahrnuty nejlepší SP v mezipaměti podle celkového počtu logických čtení a nejlepší odložené SP podle celkového fyzického přečtení. Oba jsou dobré pro hledání vysokého čtení s vysokým počtem provedení, takže můžete snížit počet I/O.
Kromě Glennových skriptů rád používám sp_whoisactive Adama Machanice, abych viděl, co aktuálně běží.
Ladění výkonu zahrnuje mnohem více, než jen prohlížení statistik souborů a čekání a nákladné dotazy, nicméně tím bych rád začal. Je to způsob, jak rychle třídit prostředí a začít určovat, co je příčinou problému. Neexistuje žádný úplně blbý způsob, jak vyladit:to, co potřebuje každý produkční DBA, je kontrolní seznam věcí, které je třeba projít, aby je bylo možné odstranit, a skutečně dobrou sbírku skriptů, kterými je třeba analyzovat stav systému. Mít základní linii je klíčem k rychlému vyloučení normálního vs. abnormálního chování. Moje dobrá přítelkyně Erin Stellato má celý kurz Pluralsight s názvem SQL Server:Benchmarking and Baselining, pokud potřebujete pomoc s nastavením a zachycením vaší základní linie.
Ještě lépe, získejte nejmodernější nástroj, jako je SQL Sentry Performance Advisor, který bude nejen shromažďovat a ukládat historické informace pro profilování a sledování trendů a poskytuje snadný přístup ke všem výše zmíněným a dalším podrobnostem, ale také poskytuje schopnost porovnávat aktivitu s vestavěnými nebo uživatelem definovanými základními liniemi, efektivně udržovat indexy bez hnutí prstu a upozorňovat nebo automatizovat reakce na základě velmi robustní architektury vlastních podmínek. Následující snímek obrazovky zobrazuje historické zobrazení řídicího panelu Performance Advisor s oranžovými čekáními na disku, databázovými I/O vpravo dole a základními liniemi porovnávajícími aktuální a předchozí období na každém grafu (kliknutím zvětšíte):
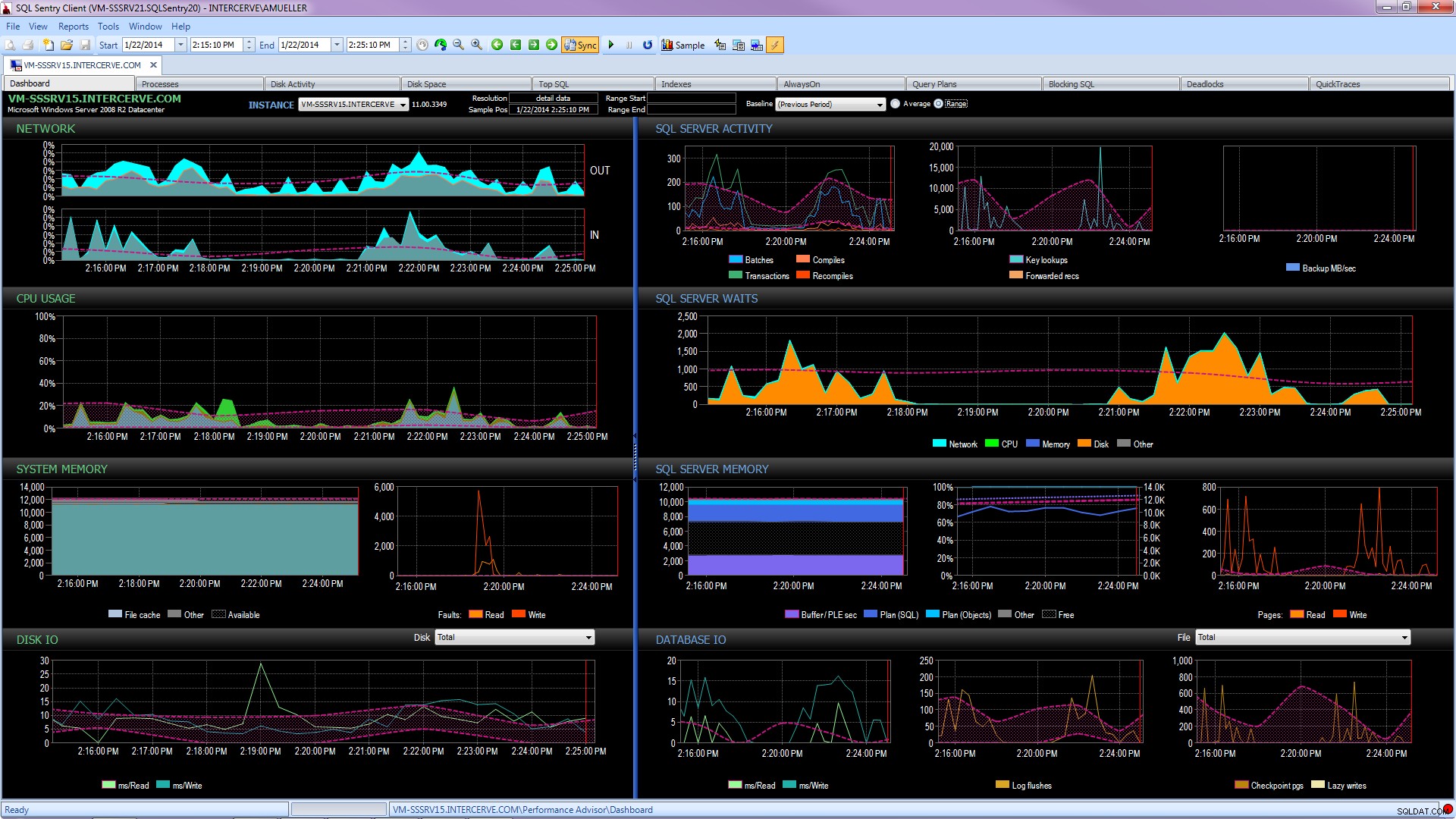
Nástroje pro sledování kvality nejsou zdarma, ale poskytují spoustu funkcí a podpory, které vám umožní zaměřit se na problémy s výkonem na vašich serverech, místo abyste se zaměřovali na dotazy, úlohy a upozornění, která mohou vám umožní soustředit se na problémy s výkonem – ale pouze tehdy, když je uděláte správně. Často má velkou hodnotu nevynalézat kolo znovu.