Začněme svou cestu SQL, abychom porozuměli agregaci dat v SQL a typům agregací včetně jednoduchých a posuvných agregací.
Než přejdeme k agregacím, stojí za to zvážit zajímavá fakta, která některým vývojářům často unikají, pokud jde o SQL obecně a agregaci zvláště.
V tomto článku SQL odkazuje na T-SQL, což je verze SQL od společnosti Microsoft a má více funkcí než standardní SQL.
Matematika za SQL
Je velmi důležité pochopit, že T-SQL je založeno na některých solidních matematických konceptech, i když to není rigidní jazyk založený na matematice.
Podle knihy „Microsoft_SQL_Server_2008_T_SQL_Fundamentals“ od Itzika Ben-Gana je SQL navrženo k dotazování a správě dat v systému správy relačních databází (RDBMS).
Samotný systém správy relačních databází je založen na dvou pevných matematických větvích:
- Teorie množin
- Predikátová logika
Teorie množin
Teorie množin, jak název napovídá, je odvětvím matematiky o množinách, které lze také nazvat kolekcemi určitých odlišných objektů.
Stručně řečeno, v teorii množin uvažujeme o věcech nebo předmětech jako o celku stejným způsobem, jakým uvažujeme o jednotlivém předmětu.
Například kniha je soubor všech jednoznačně odlišných knih, takže knihu bereme jako celek, který stačí k tomu, abychom získali podrobnosti o všech knihách v ní.
Predikátová logika
Predikátová logika je booleovská logika, která vrací true nebo false v závislosti na podmínce nebo hodnotách proměnných.
Predikátovou logiku lze použít k vynucení pravidel integrity (cena musí být větší než 0,00) nebo k filtrování dat (kde je cena vyšší než 10,00), nicméně v kontextu T-SQL máme tři logické hodnoty takto:
- Pravda
- Nepravda
- Neznámé (null)
To lze ilustrovat následovně:
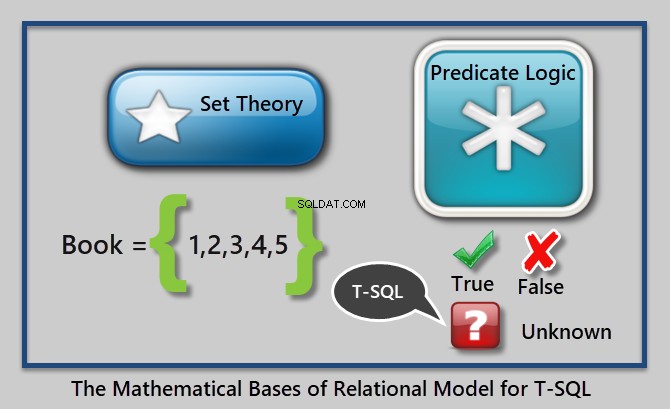
Příklad predikátu je „Pokud je cena knihy vyšší než 10,00“.
To je o matematice dost, ale mějte prosím na paměti, že na ni budu odkazovat později v článku.
Proč je agregace dat v SQL snadná
Agregace dat v SQL v jeho nejjednodušší podobě je o tom, abyste se o součtech dozvěděli najednou.
Pokud například máme tabulku zákazníků, která obsahuje seznam všech zákazníků spolu s jejich podrobnostmi, pak nám agregovaná data tabulky zákazníků mohou poskytnout celkový počet zákazníků, které máme.
Jak již bylo zmíněno dříve, uvažujeme o množině jako o jedné položce, takže pro získání součtů jednoduše aplikujeme agregační funkci na tabulku.
Vzhledem k tomu, že SQL je původně jazyk založený na množinách (jak bylo uvedeno výše), je relativně snazší na něj aplikovat agregační funkce ve srovnání s jinými jazyky.
Například, pokud máme tabulku produktů, která má záznamy o všech produktech v databázi, můžeme rovnou použít funkci počítání na tabulku produktů, abychom získali celkový počet produktů, spíše než je počítat jeden po druhém ve smyčce.
Recept na agregaci dat
Abychom mohli agregovat data v SQL, potřebujeme minimálně následující věci:
- Data (tabulka) se sloupci, která při agregaci dávají smysl
- Agregační funkce, která se použije na data
Příprava ukázkových dat (tabulka)
Vezměme si příklad jednoduché tabulky objednávek, která obsahuje tři věci (sloupce):
- Číslo objednávky (OrderId)
- Datum, kdy byla objednávka zadána (OrderDate)
- Částka objednávky (TotalAmount)
Pojďme vytvořit databázi AggregateSample a pokračovat dále:
-- Create aggregate sample database CREATE DATABASE AggregateSample
Nyní vytvořte tabulku objednávek ve vzorové databázi následovně:
-- Create order table in the aggregate sample database USE AggregateSample CREATE TABLE SimpleOrder (OrderId INT PRIMARY KEY IDENTITY(1,1), OrderDate DATETIME2, TotalAmount DECIMAL(10,2) )
Vyplnění ukázkových dat
Naplňte tabulku přidáním jednoho řádku:
INSERT INTO dbo.SimpleOrder ( OrderDate ,TotalAmount ) VALUES ( '20180101' -- OrderDate - datetime2 ,20.50 -- TotalAmount - decimal(10, 2) ); GO
Podívejme se nyní na tabulku:
-- View order table SELECT OrderId ,OrderDate ,TotalAmount FROM SimpleOrder
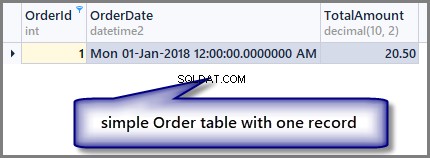
Vezměte prosím na vědomí, že v tomto článku používám dbForge Studio pro SQL Server, takže pouze vzhled výstupu se může lišit, pokud spustíte stejný kód v SSMS (SQL Server Management Studio), pokud jde o skripty a jejich výsledky, není žádný rozdíl.
Základní agregační funkce
Základní agregační funkce, které lze na tabulku použít, jsou následující:
- Součet
- Počet
- Min
- Maximálně
- Průměrný
Agregace tabulky jednoho záznamu
Nyní je zajímavá otázka, „můžeme agregovat (součet nebo počítat) data (záznamy) v tabulce, pokud má pouze jeden řádek jako v našem případě? Odpověď je „Ano“, můžeme, i když to nedává moc smysl, ale může nám to pomoci pochopit, jak se data připravují na agregaci.
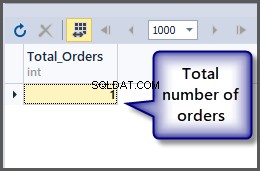
Abychom získali celkový počet objednávek, použijeme funkci count() s tabulkou, jak bylo uvedeno výše, můžeme jednoduše aplikovat agregační funkci na tabulku, protože SQL je jazyk založený na množině a operace lze aplikovat na množinu. přímo.
-- Getting total number of orders placed so far SELECT COUNT(*) AS Total_Orders FROM SimpleOrder
A co nyní objednávka s minimální, maximální a průměrnou částkou pro jeden záznam:
-- Getting order with minimum amount, maximum amount, average amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) Average_Amount FROM SimpleOrder
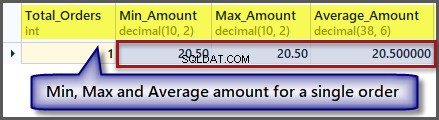
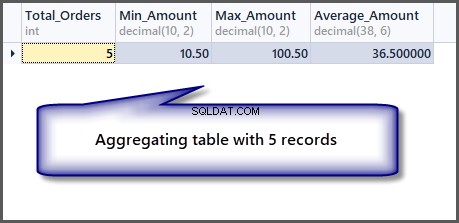
Jak vidíme z výstupu, minimální, maximální a průměrná částka je stejná, pokud máme jeden záznam, takže použití agregační funkce na jeden záznam je možné, ale dává nám to stejné výsledky.
Potřebujeme alespoň více než jeden záznam, abychom dali smysl agregovaným datům.
Agregace tabulky více záznamů
Nyní přidejte další čtyři záznamy následovně:
INSERT INTO dbo.SimpleOrder ( OrderDate ,TotalAmount ) VALUES ( '20180101' -- OrderDate - datetime2 ,20.50 -- TotalAmount - decimal(10, 2) ), ( '20180102' -- OrderDate - datetime2 ,30.50 -- TotalAmount - decimal(10, 2) ), ( '20180103' -- OrderDate - datetime2 ,10.50 -- TotalAmount - decimal(10, 2) ), ( '20180110' -- OrderDate - datetime2 ,100.50 -- TotalAmount - decimal(10, 2) ); GO
Tabulka nyní vypadá následovně:
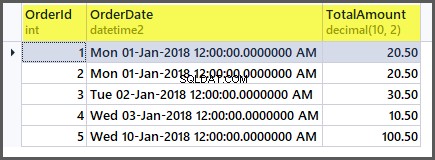
Pokud nyní aplikujeme agregační funkce na tabulku, získáme dobré výsledky:
-- Getting order with minimum amount, maximum amount, average amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) Average_Amount FROM SimpleOrder
Seskupování agregovaných dat
Agregovaná data můžeme seskupit podle libovolného sloupce nebo sady sloupců a získat agregace založené na tomto sloupci.
Například pokud chceme znát celkový počet objednávek za datum, musíme tabulku seskupit podle data pomocí klauzule Group by takto:
-- Getting total orders per date SELECT OrderDate ,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY OrderDate
Výstup je následující:
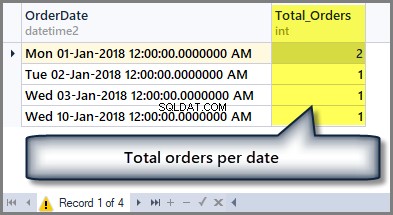
Pokud tedy chceme vidět součet všech částek objednávky, můžeme jednoduše použít funkci součtu na sloupec celkové částky bez jakéhokoli seskupování následovně:
-- Sum of all the orders amount SELECT SUM(TotalAmount) AS Sum_of_Orders_Amount FROM SimpleOrder
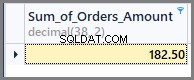
Abychom získali součet množství objednávek za datum, jednoduše přidáme skupinu podle data do výše uvedeného příkazu SQL následovně:
-- Sum of all the orders amount per date SELECT OrderDate ,SUM(TotalAmount) AS Sum_of_Orders FROM SimpleOrder GROUP BY OrderDate
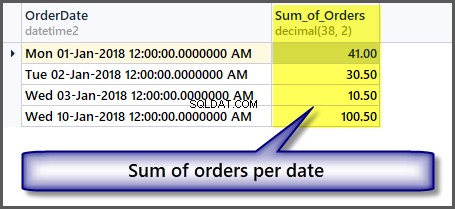
Získání součtů bez seskupování dat
Můžeme okamžitě získat součty, jako je celkový počet objednávek, maximální částka objednávky, minimální částka objednávky, součet částky objednávek, průměrná částka objednávky, aniž bychom ji museli seskupovat, pokud je agregace určena pro všechny tabulky.
-- Getting order with minimum amount, maximum amount, average amount, sum of amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) AS Average_Amount ,SUM(TotalAmount) AS Sum_of_Amount FROM SimpleOrder
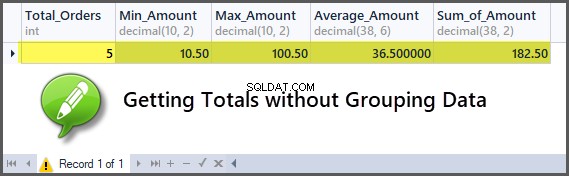
Přidávání zákazníků do objednávek
Dovolte nám přidat trochu zábavy přidáním zákazníků do naší tabulky. Můžeme to udělat tak, že vytvoříme další tabulku zákazníků a předáme ID zákazníka do tabulky objednávek, ale abych to zjednodušil a zesměšnil styl datového skladu (kde jsou tabulky denormalizované), přidávám sloupec se jménem zákazníka do tabulky objednávek následovně :
-- Adding CustomerName column and data to the order table ALTER TABLE SimpleOrder ADD CustomerName VARCHAR(40) NULL GO UPDATE SimpleOrder SET CustomerName = 'Eric' WHERE OrderId = 1 GO UPDATE SimpleOrder SET CustomerName = 'Sadaf' WHERE OrderId = 2 GO UPDATE SimpleOrder SET CustomerName = 'Peter' WHERE OrderId = 3 GO UPDATE SimpleOrder SET CustomerName = 'Asif' WHERE OrderId = 4 GO UPDATE SimpleOrder SET CustomerName = 'Peter' WHERE OrderId = 5 GO
Získání celkového počtu objednávek na zákazníka
Uhodnete nyní, jak získat celkový počet objednávek na zákazníka? Musíte seskupit podle zákazníka (CustomerName) a použít agregační funkci count() na všechny záznamy následovně:
-- Total orders per customer
SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder
GROUP BY CustomerName
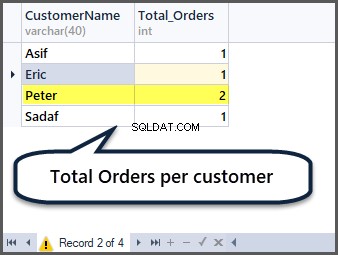
Přidání dalších pěti záznamů do tabulky objednávek
Nyní přidáme dalších pět řádků do tabulky jednoduchého pořadí takto:
-- Adding 5 more records to order table
INSERT INTO SimpleOrder (OrderDate, TotalAmount, CustomerName)
VALUES
('01-Jan-2018', 70.50, 'Sam'),
('02-Jan-2018', 170.50, 'Adil'),
('03-Jan-2018',50.00,'Sarah'),
('04-Jan-2018',50.00,'Asif'),
('11-Jan-2018',50.00,'Peter')
GO
Podívejte se nyní na data:
-- Viewing order table after adding customer name and five more rows SELECT OrderId,CustomerName,OrderDate,TotalAmount FROM SimpleOrder GO
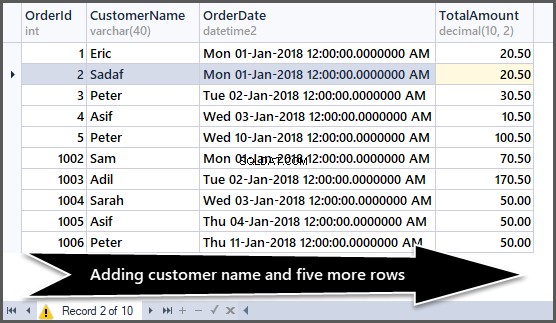
Získání celkového počtu objednávek na zákazníka seřazených podle maximálních až minimálních objednávek
Pokud vás zajímají celkové objednávky na zákazníka seřazené podle maximálních až minimálních objednávek, není vůbec špatný nápad rozdělit si to na menší kroky takto:
-- (1) Getting total orders SELECT COUNT(*) AS Total_Orders FROM SimpleOrder
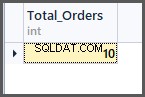
-- (2) Getting total orders per customer SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY CustomerName
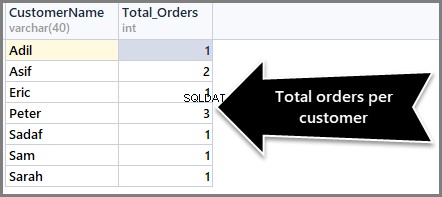
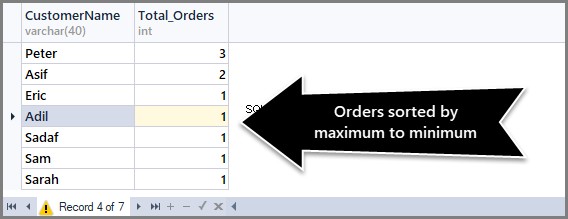
Abychom seřadili počet objednávek od maxima k minimu, musíme použít klauzuli Order By DESC (sestupné pořadí) s count() na konci takto:
-- (3) Getting total orders per customer from maximum to minimum orders SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY CustomerName ORDER BY COUNT(*) DESC
Získání celkového počtu objednávek za datum seřazené nejdříve podle nejnovější objednávky
Pomocí výše uvedené metody nyní můžeme zjistit celkový počet objednávek za datum seřazené podle poslední objednávky nejprve následovně:
-- Getting total orders per date from most recent first SELECT CAST(OrderDate AS DATE) AS OrderDate,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY OrderDate ORDER BY OrderDate DESC
Funkce CAST nám pomáhá získat pouze část data. Výstup je následující:
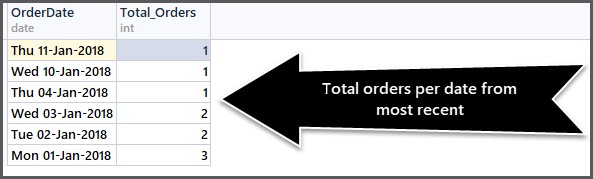
Můžete použít co nejvíce kombinací, pokud dávají smysl.
Spuštění agregací
Nyní, když jsme obeznámeni s aplikací agregačních funkcí na naše data, přejděme k pokročilé formě agregace a jednou takovou agregací je běžící agregace.
Spuštěné agregace jsou agregace aplikované na podmnožinu dat spíše než na celou datovou sadu, což nám pomáhá vytvářet malá okna na datech.
Dosud jsme viděli, že všechny agregační funkce jsou aplikovány na všechny řádky tabulky, které lze seskupit podle nějakého sloupce, jako je datum objednávky nebo jméno zákazníka, ale se spuštěnými agregacemi máme volnost použít agregační funkce bez seskupování celku. datová sada.
To samozřejmě znamená, že můžeme použít agregační funkci bez použití klauzule Seskupit podle, což je poněkud zvláštní pro ty začátečníky v SQL (nebo to někteří vývojáři přehlížejí), kteří nejsou obeznámeni s funkcemi oken a spouštěním agregací.
Windows na datech
Jak již bylo řečeno dříve, běžící agregace se aplikuje na podmnožinu datové sady nebo (jinými slovy) na malá okna dat.
Představte si okna jako sadu(y) v sadě nebo tabulku(y) v tabulce. Dobrým příkladem zobrazení dat v našem případě je, že máme tabulku objednávek, která obsahuje objednávky zadané v různých datech, takže co když je každé datum samostatné okno, pak můžeme použít agregační funkce na každé okno stejným způsobem, jakým jsme to použili na stůl.
Pokud seřadíme tabulku objednávek (SimpleOrder) podle data objednávky (OrderDate) takto:
-- View order table sorted by order date
SELECT so.OrderId
,so.OrderDate
,so.TotalAmount
,so.CustomerName FROM SimpleOrder so
ORDER BY so.OrderDate
Windows na datech připravených ke spouštění agregací naleznete níže:

Tato okna nebo podmnožiny můžeme také považovat za šest mini tabulek na základě data objednávky a na každou z těchto mini tabulek lze použít agregace.
Použití oddílu By uvnitř klauzule OVER()
Spuštěné agregace lze použít rozdělením tabulky pomocí „Rozdělit podle“ uvnitř klauzule OVER().
Pokud například chceme rozdělit tabulku objednávek podle dat, jako je každé datum podtabulkou nebo oknem na datové sadě, musíme rozdělit data podle data objednávky a toho lze dosáhnout pomocí agregační funkce, jako je COUNT( ) pomocí OVER() a rozdělení pomocí uvnitř OVER() takto:
-- Running Aggregation on Order table by partitioning by dates SELECT OrderDate, Total_Orders=COUNT(*) OVER(PARTITION BY OrderDate) FROM SimpleOrder

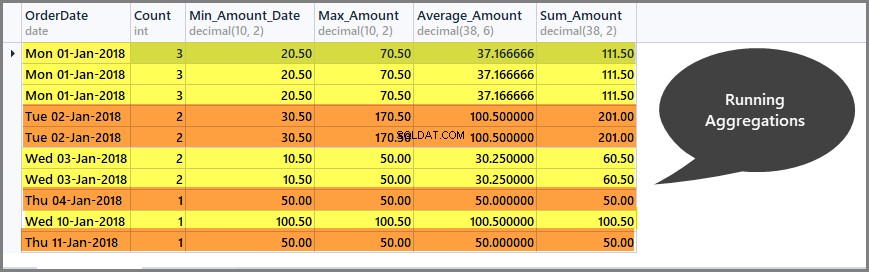
Získání průběžných součtů za časové okno (oddíl)
Spuštěné agregace nám pomáhají omezit rozsah agregace pouze na definované okno a můžeme získat průběžné součty za okno následovně:
-- Getting total orders, minimum amount, maximum amount, average amount and sum of all amounts per date window (partition by date) SELECT CAST (OrderDate AS DATE) AS OrderDate, Count=COUNT(*) OVER (PARTITION BY OrderDate), Min_Amount=MIN(TotalAmount) OVER (PARTITION BY OrderDate) , Max_Amount=MAX(TotalAmount) OVER (PARTITION BY OrderDate) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY OrderDate), Sum_Amount=SUM(TotalAmount) OVER (PARTITION BY OrderDate) FROM SimpleOrder
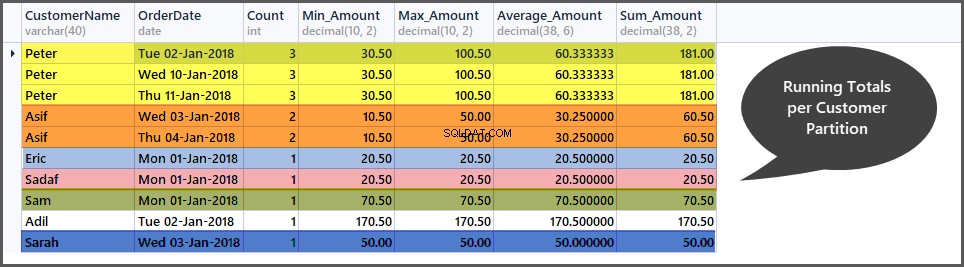
Získání průběžných součtů na zákaznické okno (oddíl)
Stejně jako průběžné součty za datumové okno můžeme také vypočítat průběžné součty za zákaznické okno rozdělením sady objednávek (tabulky) na podmnožiny malých zákazníků (oddíly) takto:
-- Getting total orders, minimum amount, maximum amount, average amount and sum of all amounts per customer window (partition by customer) SELECT CustomerName, CAST (OrderDate AS DATE) AS OrderDate, Count=COUNT(*) OVER (PARTITION BY CustomerName), Min_Amount=MIN(TotalAmount) OVER (PARTITION BY CustomerName) , Max_Amount=MAX(TotalAmount) OVER (PARTITION BY CustomerName) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY CustomerName), Sum_Amount=SUM(TotalAmount) OVER (PARTITION BY CustomerName) FROM SimpleOrder ORDER BY Count DESC,OrderDate
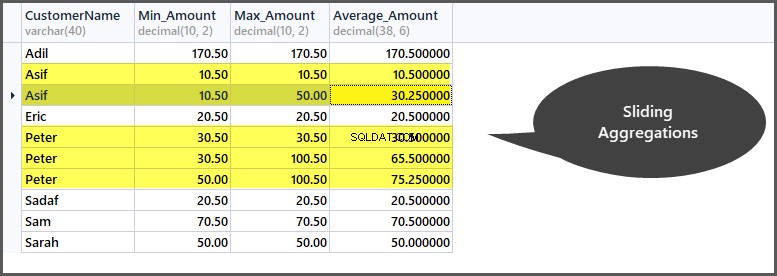
Posuvné agregace
Posuvné agregace jsou agregace, které lze použít na snímky v okně, což znamená další zúžení rozsahu v okně (oddílu).
Jinými slovy, průběžné součty nám dávají součty (součet, průměr, min, max, počet) za celé okno (podmnožinu), které vytvoříme v rámci tabulky, zatímco klouzavé součty nám dávají součty (součet, průměr, min, max, počet). pro rámec (podmnožinu podmnožiny) v okně (podmnožinu) tabulky.
Pokud například vytvoříme okno s daty na základě (rozdělení podle zákazníka) zákazníka, můžeme vidět, že zákazník „Petr“ má ve svém okně tři záznamy a všechny agregace jsou aplikovány na tyto tři záznamy. Pokud nyní chceme vytvořit rámec pouze pro dva řádky najednou, znamená to, že se agregace dále zúží a pak se aplikuje na první a druhý řádek a poté na druhý a třetí řádek a tak dále.
Použití ŘÁDKŮ PŘEDCHÁZEJÍCÍCH s Řazení podle uvnitř klauzule OVER()
Posuvné agregace lze použít přidáním ŘÁDKŮ
Například, pokud chceme agregovat data pouze pro dva řádky najednou pro každého zákazníka, pak potřebujeme klouzavé agregace, které mají být aplikovány na tabulku objednávek takto:
-- Getting minimum amount, maximum amount, average amount per frame per customer window SELECT CustomerName, Min_Amount=Min(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING), Max_Amount=Max(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING) FROM SimpleOrder so ORDER BY CustomerName
Abychom pochopili, jak to funguje, podívejme se na původní tabulku v kontextu rámců a oken:
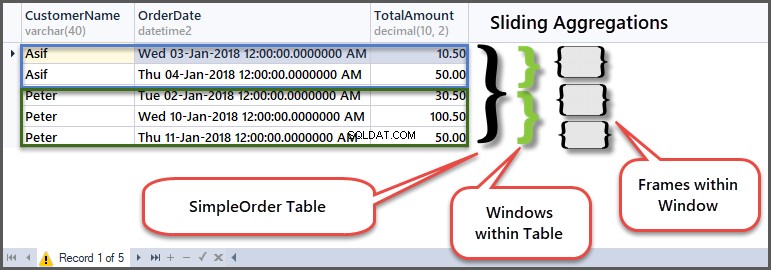
V první řadě okna zákazníka Petr zadal objednávku s částkou 30,50, protože toto je začátek rámce v okně zákazníka, takže min a max jsou stejné, protože neexistuje žádný předchozí řádek, se kterým by bylo možné porovnávat.
Dále minimální částka zůstane stejná, ale maximální bude 100,50, protože částka v předchozím řádku (prvním řádku) je 30,50 a tato částka v řádku je 100,50, takže maximum z těchto dvou je 100,50.
Dále, přesunete se do třetího řádku, porovnání proběhne s druhým řádkem, takže minimální částka dvou řádků je 50,00 a maximální částka dvou řádků je 100,50.
Funkce MDX od roku k datu (YTD) a běžící agregace
MDX je vícerozměrný výrazový jazyk používaný k dotazování na vícerozměrná data (jako je krychle) a používá se v řešeních business intelligence (BI).
Podle https://docs.microsoft.com/en-us/sql/mdx/ytd-mdx funguje funkce Year to Date (YTD) v MDX stejně jako běžící nebo posuvné agregace. Například YTD často používaný v kombinaci s nedodaným parametrem zobrazuje průběžný součet k dnešnímu dni.
To znamená, že pokud tuto funkci použijeme na rok, poskytne všechny údaje za rok, ale pokud se podrobíme až do března, dostaneme všechny součty od začátku roku do března a tak dále.
To je velmi užitečné ve zprávách SSRS.
Co dělat
A je to! Po prostudování tohoto článku jste připraveni provést základní analýzu dat a své dovednosti můžete dále zlepšit pomocí následujících věcí:
- Zkuste prosím napsat běžící skript agregace vytvořením oken v jiných sloupcích, jako je Celková částka.
- Zkuste také napsat skript posuvných agregací vytvořením rámců v jiných sloupcích, jako je Celková částka.
- Do tabulky (nebo i více tabulek) můžete přidat další sloupce a záznamy a vyzkoušet jiné kombinace agregace.
- Ukázkové skripty uvedené v tomto článku lze přeměnit na uložené procedury, které lze použít v sestavách SSRS za datovými sadami.
Odkazy:
- Ytd (MDX)
- dbForge Studio pro SQL Server