Již dříve jsem psal o výhodách používání NOEXPAND rady, a to i v Enterprise Edition. Podrobnosti jsou všechny v odkazovaném článku, ale pro stručné shrnutí:
- SQL Server se pouze automaticky vytvoří statistiky indexovaného zobrazení při
NOEXPANDpoužívá se nápověda tabulky. Vynechání této nápovědy může vést k varování plánu provádění o chybějících statistikách, které nelze vyřešit ručním vytvořením statistik. - SQL Server bude pouze používat automaticky nebo ručně vytvořené statistiky zobrazení ve výpočtech odhadu mohutnosti, když dotaz odkazuje přímo na zobrazení a
NOEXPANDpoužívá se nápověda. U všech definic pohledu kromě těch nejtriviálnějších to znamená, že kvalita odhadů mohutnosti bude pravděpodobně nižší, když se tato nápověda nepoužívá, což často vede k méně optimálním plánům provádění. - Neexistence nebo nemožnost použití statistik zobrazení může způsobit, že optimalizátor odhadne odhady mohutnosti, i když jsou k dispozici statistiky základní tabulky. K tomu může dojít, když je část plánu dotazů nahrazena referencí indexovaného zobrazení funkcí automatického přiřazování zobrazení, ale statistiky zobrazení nejsou k dispozici, jak je popsáno výše.
Nepoužití NOEXPAND má další důsledek nápověda, kterou jsem mimochodem zmínil před několika lety ve svém článku Omezení optimalizátoru s filtrovanými indexy:
NOEXPANDrady jsou potřeba i ve verzi Enterprise Edition, aby bylo zajištěno, že optimalizátor využívá záruku jedinečnosti poskytovanou indexy zobrazení.
Tento článek zkoumá toto prohlášení a jeho důsledky podrobněji.
Nastavení ukázky
Následující skript vytvoří jednoduchou tabulku a indexované zobrazení:
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); To vytvoří tabulku haldy s jedním sloupcem a neomezený pohled na stejnou tabulku s jedinečným seskupeným indexem. Toto není zamýšleno jako realistický případ použití pro indexované zobrazení; ale pomůže to ilustrovat klíčové body s minimem rušivých vlivů. Důležité je, že základní tabulka zde nemá vůbec žádné indexy (ani klastrovaný index), ale pohled ano a tento index je jedinečný.
Ukázkový dotaz
Zvažte následující jednoduchý dotaz na základní tabulku:
SELECT DISTINCT
T.col1
FROM dbo.T AS T; Plán provádění, který uvidíte pro tento dotaz, závisí na používané edici serveru SQL. Pokud ne Enterprise Edition (nebo ekvivalentní), uvidíte plán jako tento:

Optimalizátor dotazů SQL Server se rozhodl prohledat základní tabulku a použít zadanou odlišnost pomocí operátoru Distinct Sort. Tento tvar plánu je plně očekávaný, protože automatické přiřazování indexovaných pohledů není k dispozici mimo Enterprise Edition. Od tohoto okamžiku přestanu říkat „Enterprise Edition nebo ekvivalent“, ale prosím nadále vyvozujte, že mám na mysli jakoukoli edici, která podporuje automatické přiřazování zobrazení, když řeknu „Enterprise Edition“ od nynějška.
Nápověda ROZŠÍŘIT ZOBRAZENÍ
To je trochu stranou, ale abychom získali stejný plán na Enterprise Edition, musíme použít EXPAND VIEWS nápověda k dotazu:
SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS);
Může se zdát trochu zvláštní používat tuto nápovědu, když neexistují žádné odkazy na zobrazení v dotazu, ale tak to funguje. EXPAND VIEWS nápověda účinně určuje, že při kompilaci a optimalizaci dotazu by měla být shoda indexovaného zobrazení zakázána. Aby bylo jasno:Bez tohoto náznaku může Enterprise Edition jinak odpovídat dotazu (jeho části) jednomu nebo více indexovaným pohledům.
Se zapnutým automatickým párováním zobrazení
Bez EXPAND VIEWS nápověda, kompilace stejného dotazu na Developer Edition (například) vytvoří jiný plán:
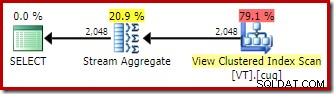
Použití porovnávání indexovaných pohledů znamená, že plán provádění obsahuje skenování indexu seskupeného pohledu namísto skenování základní tabulky.
Stejný plán se vytvoří v tomto případě, pokud dotaz odkazuje přímo na pohled (místo na základní tabulku):
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; Ve všech edicích je před zahájením optimalizace dotazu rozšířena reference zobrazení. V edicích ekvivalentních Enterprise může být rozšířená forma později přiřazena zpět k pohledu. Toto je klíčový koncept, kterému je třeba porozumět, když přemýšlíte o tom, jak kompilátor dotazů a optimalizátor používají indexovaná zobrazení na serveru SQL Server.
Souhrnný proud
Nejzajímavějším rozdílem mezi těmito dvěma plány, který jsme dosud viděli, je Stream Aggregate v plánu s odpovídajícím zobrazením. Pokud se podíváte na odhadované náklady operátorů Table Scan a View Scan, uvidíte, že jsou naprosto stejné. Optimalizátor se nerozhodl použít indexované zobrazení, protože to zlevnilo přístup k datům. Skenování indexu zobrazení spíše umožňuje DISTINCT požadavek, aby byl implementován jako souhrnný proud, nikoli jako agregátní hash nebo odlišné řazení (jako v prvním plánu).
Agregát toku vyžaduje vstup seřazený podle sloupců seskupení. V tomto případě je rozdíl ekvivalentní seskupení podle jednoho sloupce a jedinečný seskupený index zobrazení poskytuje nezbytnou záruku objednávky. Cenový model optimalizátoru identifikuje Stream Aggregate jako levnější možnost než Distinct Sort nebo Hash Aggregate pro tento dotaz. Toto je základ pro výběr optimalizátoru pro přístup k indexovanému zobrazení, když je k dispozici automatická shoda zobrazení.
Se vším, co bylo řečeno a pochopeno, je Stream Aggregate stále neočekávaný:Vzhledem k garanci jedinečnosti, kterou poskytuje index zobrazení, není nutné tuto operaci seskupování vůbec provádět. Unikátní seskupený index již zajišťuje, že sloupec neobsahuje žádné duplikáty.
To je ve zkratce problém. Při použití automatického párování pohledů optimalizátor rozpozná záruku objednání poskytovanou indexem zobrazení, ale nikoli záruku jedinečnosti.
Použití nápovědy NOEXPAND
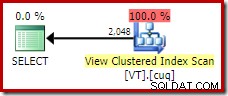
Abychom získali ideální plán provádění tohoto dotazu, musíme odkazovat přímo na pohled a použít NOEXPAND nápověda k tabulce:
SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); To nám dává plán, který by zkušený databázový člověk očekával; ten, který správně rozpozná, že odlišná operace je nadbytečná a lze ji odstranit:
Druhý příklad
Nevyužití záruky jedinečnosti poskytované indexem zobrazení může mít další vliv na konečný plán provádění. Zvažte nyní vlastní spojení indexovaného zobrazení (opět jen pro ilustraci konceptu – toto není zamýšleno jako realistický dotaz):
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1; Při použití Developer Edition zvolený plán provádění vůbec nepřistupuje k indexovanému zobrazení a obsahuje spojení hash (někdy indikující, že chybí užitečný index):
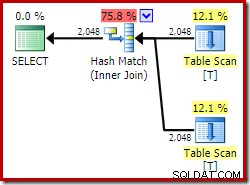
Nyní zkusme přesně stejný dotaz, ale s NOEXPAND nápověda k odkazu na každý pohled:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
ON V2.col1 = V1.col1; Plán provádění nyní obsahuje dva přístupy s indexovaným pohledem a slučovací spojení:
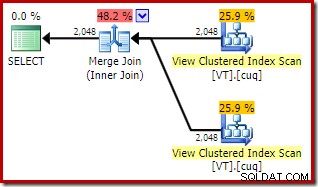
Tento nový plán má mnohem nižší odhadované náklady než plán spojení hash, tak proč optimalizátor nezvolil tuto možnost dříve? Můžeme zjistit proč přidáním nápovědy ke sloučení k původnímu dotazu:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN);
Díky tomu vypadá podobně plán, který zvolí přístup k zobrazení, i když NOEXPAND nebylo zadáno:
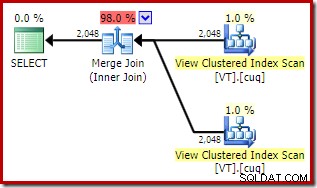
Celkové odhadované náklady tohoto plánu jsou vyšší než oba předchozí příklady. Sloučení spojení v tomto plánu také představuje vyšší podíl celkových odhadovaných nákladů než dříve (98 % oproti 48,2 %).
Důvod toho lze vidět při pohledu na vlastnosti slučovacího spojení. V NOEXPAND plán, bylo to spojení jednoho k mnoha. V plánu přímo výše se jedná o spojení s mnoha sloučením. Cenový model optimalizátoru přiřazuje vyšší náklady spojením sloučením many-to-many, protože ke zpracování jakýchkoli duplikátů je potřeba pracovní tabulka tempdb.
Závěry
Záruky poskytované jedinečným indexem mohou být mocným optimalizačním nástrojem, takže je škoda, že automatické porovnávání indexů v současné době nedokáže využít jeho výhod. Potenciální výhody jdou nad rámec eliminace zbytečných agregací nebo umožnění sloučení typu one-to-many, jak je vidět v předchozích jednoduchých příkladech. Obecně může být obtížné zjistit, že plán provádění není optimální, protože optimalizátor nevyužil výhody záruky jedinečnosti.
Toto omezení optimalizátoru se nevztahuje pouze na jedinečný seskupený index, který musí mít pohled, aby mohl být materializován. Ve složitějších scénářích mohou být v zobrazení také přítomny další neshlukované indexy; možná odrážet vztahy mezi tabulkami, které je obtížné vynutit nebo reprezentovat jinak. Pokud jsou tyto neshlukované indexy definovány jako jedinečné, optimalizátor přehlédne i tyto záruky, pokud se použije automatické porovnávání indexů.
Když to přidáme k omezením kolem vytváření a používání statistických informací, zdá se, že spoléhání se na automatické párování pohledů může vést k horším plánům provádění. Nejbezpečnější možností je pravděpodobně explicitně odkazovat na indexovaná zobrazení a použít NOEXPAND nápověda pokaždé – alespoň dokud se tyto problémy nevyřeší v produktu.
Polehčující faktory
Měl bych zdůraznit, že problém popsaný v tomto článku se týká pouze záruky jedinečnosti, kterou poskytuje jedinečný index zobrazení. Pokud optimalizátor může získat požadované informace o jedinečnosti jiným způsobem , je velká šance, že se vyhneme problémům s optimalizací.
Například může existovat vhodný jedinečný index na základní tabulce, na kterou pohled odkazuje. Nebo v případě pohledu, který obsahuje agregaci, může optimalizátor již odvodit užitečnou záruku jedinečnosti z GROUP BY pohledu. doložka. Běžná praxe přidávání seskupeného indexu zobrazení do seskupovacích klíčů v takovém případě nepřidává žádné další informace o jedinečnosti.
Nicméně jsou chvíle, kdy tento „přehled jedinečnosti“ může znamenat, že získáte kvalitnější plány provádění pomocí explicitního odkazu na zobrazení a NOEXPAND rady, a to i v Enterprise Edition.