Ukládání ~3,5 TB dat a vkládání asi 1 kB/s 24x7 a také dotazování rychlostí, která není specifikována, je možné s SQL Serverem, ale existuje více otázek:
- jaký požadavek na dostupnost pro to máte? 99,999 % provozuschopnosti, nebo stačí 95 %?
- jaký máte požadavek na spolehlivost? Stojí vás chybějící vložka 1 milion $?
- jaký máte požadavek na obnovitelnost? Pokud přijdete o jeden den dat, záleží na tom?
- jaký máte požadavek na konzistenci? Musí být zaručeno, že zápis bude viditelný při dalším čtení?
Pokud potřebujete všechny tyto požadavky, které jsem zdůraznil, zatížení, které navrhujete, bude stát miliony hardwaru a licencí na relační systém, jakýkoli systém, bez ohledu na to, jaké triky zkoušíte (sharding, dělení atd.). Systém nosql by podle jejich definice nesplňoval vše tyto požadavky.
Je tedy zřejmé, že některé z těchto požadavků jste již zmírnili. Ve Visual Guide to NoSQL Systems je pěkný vizuální průvodce srovnávající nabídky nosql na základě paradigmatu „vybrat 2 ze 3“:
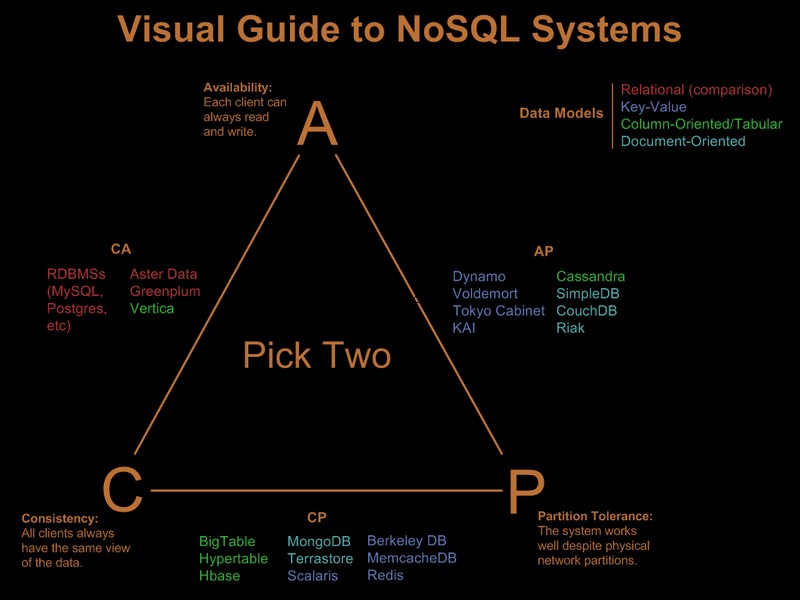
Po aktualizaci komentáře OP
S SQL Server by to byla přímá implementace:
- jeden klíč seskupený jednou tabulkou (GUID, čas). Ano, dojde k fragmentaci, ale má fragmentace vliv na předčítání a předčítání je potřeba pouze pro skenování s velkým rozsahem. Vzhledem k tomu, že dotazujete pouze na konkrétní GUID a časové období, nebude fragmentace příliš záležet. Ano, je to široký klíč, takže nelistové stránky budou mít špatnou hustotu klíčů. Ano, povede to ke špatnému faktoru plnění. A ano, může dojít k rozdělení stránek. Navzdory těmto problémům, vzhledem k požadavkům, je stále nejlepší volbou clusterovaný klíč.
- rozdělte tabulku podle času, abyste mohli efektivně mazat záznamy, jejichž platnost vypršela, prostřednictvím automatického posuvného okna. Rozšiřte to o online přestavbu indexového oddílu z minulého měsíce, abyste odstranili špatný faktor plnění a fragmentaci, kterou zavedlo shlukování GUID.
- povolit kompresi stránky. Vzhledem k tomu, že skupiny klíčů seskupují nejprve podle GUID, budou všechny záznamy GUID vedle sebe, což dává kompresi stránky dobrou šanci na nasazení komprese slovníku.
- budete potřebovat rychlou IO cestu pro soubor protokolu. Máte zájem o vysokou propustnost, ne o nízkou latenci, aby protokol držel krok s 1 000 insertů/s, takže stripování je nutností.
Rozdělení a komprese stránek vyžadují SQL Server Enterprise Edition, nebudou fungovat na Standard Edition a obojí je pro splnění požadavků docela důležité.
Jako vedlejší poznámku, pokud záznamy pocházejí z front-endové farmy webových serverů, dal bych Express na každý webový server a místo INSERT na zadním konci bych SEND informace na back-end, pomocí místního připojení/transakce na Express umístěném společně s webovým serverem. To dává řešení mnohem lepší příběh o dostupnosti.
Takže takhle bych to udělal v SQL Serveru. Dobrou zprávou je, že problémům, kterým budete čelit, dobře rozumíte a jsou známá řešení. to nutně neznamená, že je to lepší, než čeho byste mohli dosáhnout s Cassandrou, BigTable nebo Dynamo. Nechám někoho znalejšího ve věcech, které nejsou sql-ish, aby argumentoval jejich případ.
Všimněte si, že jsem nikdy nezmínil programovací model, podporu .Net a podobně. Upřímně si myslím, že jsou ve velkých nasazeních irelevantní. Dělají obrovský rozdíl ve vývojovém procesu, ale po nasazení nezáleží na tom, jak rychlý byl vývoj, pokud režie ORM zabíjí výkon :)