Kontaktovali jste někdy společnost Microsoft nebo jejího partnera a diskutovali jste s nimi o nákladech na přechod do cloudu? Pokud ano, možná jste už slyšeli o kalkulačce DTU Azure SQL Database a možná jste také četli o tom, jak ji Andy Mallon vytvořil zpětně. Kalkulačka DTU je bezplatný nástroj, který můžete použít k nahrání metrik výkonu ze serveru a použít data k určení vhodné úrovně služeb, pokud byste měli tento server migrovat do Azure SQL Database (nebo do elastického fondu SQL Database).
Chcete-li to provést, musíte buď naplánovat, nebo ručně spustit skript (příkazový řádek nebo Powershell, dostupný ke stažení na webu kalkulačky DTU) během období typického produkčního zatížení.
Pokud se pokoušíte analyzovat rozsáhlé prostředí nebo chcete analyzovat data z konkrétních bodů v čase, může to být oříšek. V mnoha případech má mnoho správců databází nějakou příchuť monitorovacího nástroje, který pro ně již zachycuje údaje o výkonu. V mnoha případech pravděpodobně buď již zachycuje potřebné metriky, nebo jej lze snadno nakonfigurovat tak, aby zachycoval data, která potřebujete. Dnes se podíváme na to, jak využít SentryOne, abychom mohli poskytnout příslušná data kalkulačce DTU.
Pro začátek se podívejme na informace získané nástrojem příkazového řádku a skriptem PowerShell dostupným na webu kalkulačky DTU; existují 4 čítače sledování výkonu, které zachycuje:
- Procesor – % času procesoru
- Logický disk – čtení disku/s
- Logický disk – zápis na disk/s
- Databáze – vyprázdnění logbajtů/s
Prvním krokem je určení, zda jsou tyto metriky již zachyceny jako součást sběru dat v SQL Sentry. Pro zjištění doporučuji přečíst si tento blogový příspěvek Jasona Halla, kde mluví o tom, jak jsou data uspořádána a jak je můžete dotazovat. Nebudu zde procházet jednotlivé kroky, ale doporučuji vám, abyste si celou tuto sérii blogu přečetli a přidali do záložek.
Když jsem se podíval do databáze SentryOne, zjistil jsem, že 3 ze 4 čítačů jsou již ve výchozím nastavení zachyceny. Jediný, který chyběl, byl [Database – Log Bytes Flushed/sec] , takže jsem to musel umět zapnout. Byl tu další blogový příspěvek od Justina Randalla, který vysvětluje, jak to udělat.
Stručně řečeno, můžete zadat dotaz na [PerformanceAnalysisCounter] tabulka.
SELECT ID, PerformanceAnalysisCounterCategoryID, PerformanceAnalysisSampleIntervalID, CounterResourceName, CounterName FROM dbo.PerformanceAnalysisCounter WHERE CounterResourceName =N'LOG_BYTES_FLUSHED_PER_SEC';
Všimnete si, že ve výchozím nastavení je [PerformanceAnalysisSampleIntervalID] je nastaveno na 0 – to znamená, že je zakázáno. Chcete-li to povolit, budete muset spustit následující příkaz. Jednoduše vytáhněte ID z dotazu SELECT, který jste právě spustili, a použijte jej v této AKTUALIZACI:
UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID =1 WHERE ID =166;
Po spuštění aktualizace budete muset restartovat monitorovací službu SentryOne relevantní pro tento cíl, aby bylo možné shromáždit nová data počítadla.
Všimněte si, že jsem nastavil [PerformanceAnalysisSampleIntervalID] na 1, takže data jsou zachycována každých 10 sekund, můžete však tato data zachycovat méně často, abyste minimalizovali velikost shromážděných dat za cenu nižší přesnosti. Viz [PerformanceAnalysisSampleInterval] tabulka pro seznam hodnot, které můžete použít.
Neočekávejte, že data začnou proudit do tabulek okamžitě; to bude nějakou dobu trvat, než si prorazí cestu systémem. Počet obyvatel můžete zkontrolovat pomocí následujícího dotazu:
SELECT TOP (100) * FROM dbo.PerformanceAnalysisDataDatabaseCounter WHERE PerformanceAnalysisCounterID =166;
Jakmile potvrdíte, že se data zobrazují, měli byste mít data pro každou z metrik požadovaných kalkulačkou DTU, i když možná budete chtít počkat na extrakci, dokud nebudete mít reprezentativní vzorek z plného pracovního vytížení nebo obchodního cyklu.
Pokud si přečtete Jasonův příspěvek na blogu, uvidíte, že data jsou uložena v různých kumulativních tabulkách a že každá z těchto kumulativních tabulek má různou míru uchovávání. Mnohé z nich jsou nižší, než bych chtěl, pokud analyzuji pracovní zátěž za určité časové období. I když je možné je změnit, nemusí to být nejmoudřejší. Protože to, co vám ukazuji, není podporováno, možná se budete chtít vyhnout přílišnému vrtání se v nastavení SentryOne, protože by to mohlo mít negativní dopad na výkon, růst nebo obojí.
Abych to vykompenzoval, vytvořil jsem skript, který mi umožňuje extrahovat data, která potřebuji pro různé souhrnné tabulky, a ukládat tato data do vlastního umístění, abych mohl ovládat své vlastní uchovávání a nezasahovat do funkčnosti SentryOne.
TABLE:dbo.AzureDatabaseDTUData
Vytvořil jsem tabulku s názvem [AzureDatabaseDTUData] a uložil jej do databáze SentryOne. Postup, který jsem vytvořil, automaticky vygeneruje tuto tabulku, pokud neexistuje, takže to není nutné dělat ručně, pokud nechcete přizpůsobit, kde je uložena. Pokud chcete, můžete to uložit do samostatné databáze, k tomu budete potřebovat pouze upravit skript. Tabulka vypadá takto:
CREATE TABLE dbo.AzureDatabaseDTUdata( ID bigint identity(1,1) není null, DeviceID smallint není null, [TimeStamp] datetime není null, CounterName nvarchar(256) není null, [Value] float není null, InstanceName nvarchar 256) není null, CONSTRAINT PK_AzureDatabaseDTUdata PRIMARY KEY (ID));
Postup:dbo.Custom_CollectDTUDataForDevice
Toto je uložená procedura, kterou můžete použít k načtení všech dat specifických pro DTU najednou (za předpokladu, že jste shromažďovali počítadlo bajtů protokolu po dostatečnou dobu), nebo naplánovat její pravidelné přidávání ke shromážděným datům, dokud jste připraveni odeslat výstup do kalkulačky DTU. Stejně jako výše uvedená tabulka je procedura vytvořena v databázi SentryOne, ale můžete ji snadno vytvořit i jinde, stačí přidat tří nebo čtyřdílné názvy k odkazům na objekty. Rozhraní postupu je následující:
PROCEDUR VYTVOŘENÍ [dbo].[Custom_CollectDTUDataForDevice] @DeviceID smallint =-1, @DaysToPurge smallint =14, -- Tyto definují CounterID pro případ, že by se někdy změnila. @ProcessorCounterID smallint =1858, -- Procesor (výchozí) @DiskReadCounterID smallint =64, -- Čtení disku/s (DiskCounter) @DiskWritesCounterID smallint =67, -- Zápisy na disk/s (počítač disků) @LogBytes16int smallint, --CounterID6int smallFlush Log Bytes Flushed/Sec (DatabaseCounter)AS...
Poznámka :Celý postup je trochu dlouhý, proto je připojen k tomuto příspěvku (dbo.Custom_CollectDTUDataForDevice.sql_.zip).
Existuje několik parametrů, které můžete použít. Každý z nich má výchozí hodnotu, takže je nemusíte zadávat, pokud vám výchozí hodnoty vyhovují.
- @DeviceID – To vám umožňuje určit, zda chcete shromažďovat data pro konkrétní SQL Server nebo vše. Výchozí hodnota je -1, což znamená zkopírovat všechny sledované servery SQL. Pokud chcete exportovat informace pouze pro konkrétní instanci, vyhledejte
DeviceIDodpovídající hostiteli v[dbo].[Device]tabulku a předat tuto hodnotu. Můžete předat pouze jeden@DeviceIDnajednou, takže pokud chcete projít sadou serverů, můžete proceduru volat vícekrát, nebo můžete proceduru upravit tak, aby podporovala sadu zařízení. - @DaysToPurge – Toto představuje věk, ve kterém chcete data odstranit. Výchozí hodnota je 14 dní, což znamená, že budete stahovat pouze data stará maximálně 14 dní a všechna data starší než 14 dní ve vaší vlastní tabulce budou smazána.
Další čtyři parametry jsou zde pro budoucí zabezpečení pro případ, že by se SentryOne výčty ID čítačů někdy změnily.
Pár poznámek ke skriptu:
- Když jsou data načtena, vezme maximální hodnotu z zkrácené minuty a exportuje ji. To znamená, že existuje jedna hodnota na metriku za minutu, ale je to maximální zachycená hodnota. To je důležité kvůli způsobu, jakým musí být data prezentována kalkulačce DTU.
- Při prvním spuštění exportu to může trvat trochu déle. Je to proto, že stahuje všechna data, která může, na základě hodnot vašich parametrů. Při každém dalším spuštění jsou extrahována pouze data, která jsou nová od posledního spuštění, takže by to mělo být mnohem rychlejší.
- Budete muset naplánovat tuto proceduru tak, aby se spouštěla podle časového plánu, který má předstih před procesem čištění SentryOne. Právě jsem vytvořil úlohu agenta SQL, která se spouští každou noc a která shromažďuje všechna nová data od předchozí noci.
- Protože se proces čištění v SentryOne může lišit v závislosti na metrikách, můžete skončit s řádky ve vaší kopii, které neobsahují všechna 4 počítadla za určité časové období. Možná budete chtít začít analyzovat svá data teprve od začátku procesu extrakce.
- K určení souhrnné tabulky pro každý čítač jsem použil blok kódu ze stávajících procedur SentryOne. Mohl jsem napevno zakódovat aktuální názvy tabulek, ale pomocí metody SentryOne by měla být dopředně kompatibilní s jakýmikoli změnami vestavěných kumulativních procesů.
Jakmile jsou vaše data přesunuta do samostatné tabulky, můžete je pomocí PIVOT dotazu převést do podoby, kterou očekává kalkulačka DTU.
Postup:dbo.Custom_ExportDataForDTUCalculator
Vytvořil jsem další postup pro extrakci dat do formátu CSV. Kód pro tento postup je také přiložen (dbo.Custom_ExportDataForDTUCalculator.sql_.zip).
Existují tři parametry:
- @DeviceID – Smallint odpovídající jednomu ze zařízení, které sbíráte a které chcete odeslat do kalkulačky.
- @BeginTime – Datetime představující počáteční čas v místním čase; například
'2018-12-04 05:47:00.000'. Postup se převede do UTC. Pokud je vynechán, bude se shromažďovat od nejstarší hodnoty v tabulce. - @Čas ukončení – Datum a čas představující čas ukončení, opět v místním čase; například
'2018-12-06 12:54:00.000'. Pokud je vynechán, bude shromažďovat až poslední hodnotu v tabulce.
Příklad provedení pro získání všech dat shromážděných pro SQLInstanceA mezi 4. prosincem v 5:47 a 6. prosincem ve 12:54.
EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID =12, @BeginTime ='2018-12-04 05:47:00.000', @EndTime ='2018-12-06 12:54:00.000Data bude nutné exportovat do souboru CSV. Nedělejte si starosti o data samotná; Ujistil jsem se, že výstup výsledků je tak, že v souboru csv nejsou žádné identifikační informace o vašem serveru, pouze data a metriky.
Pokud spustíte dotaz v SSMS, můžete kliknout pravým tlačítkem a exportovat výsledky; zde však máte omezené možnosti a budete muset manipulovat s výstupem, abyste získali formát očekávaný DTU kalkulačkou. (Neváhejte to zkusit a dejte mi vědět, pokud najdete způsob, jak to udělat.)
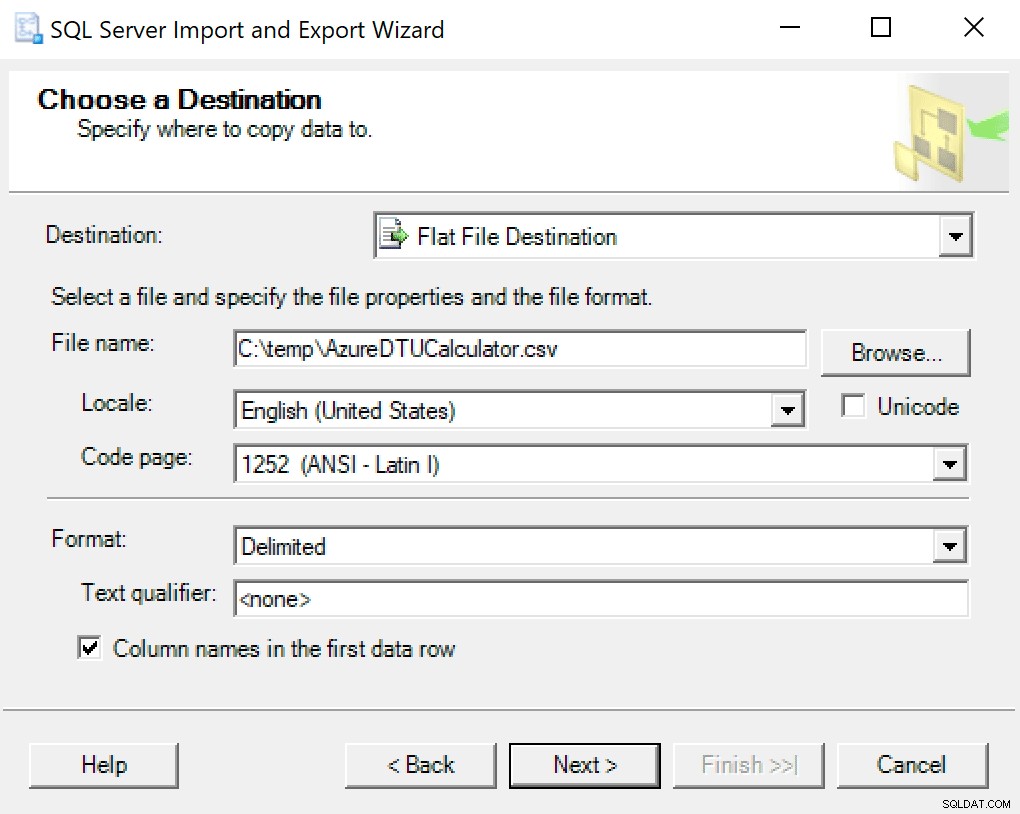
Doporučuji použít pouze průvodce exportem zapečeným do SSMS. Klikněte pravým tlačítkem na databázi a přejděte na Úkoly -> Exportovat data. Jako zdroj dat použijte „SQL Server Native Client“ a nasměrujte jej na vaši databázi SentryOne (nebo kdekoli, kde máte uloženou kopii dat). Jako cíl budete chtít vybrat „Cíl s plochým souborem“. Vyhledejte umístění, pojmenujte soubor a uložte soubor jako CSV.
Dejte pozor, abyste kódovou stránku nechali na pokoji; některé mohou vrátit chyby. Vím, že 1252 funguje dobře. Zbytek hodnot ponechá jako výchozí.
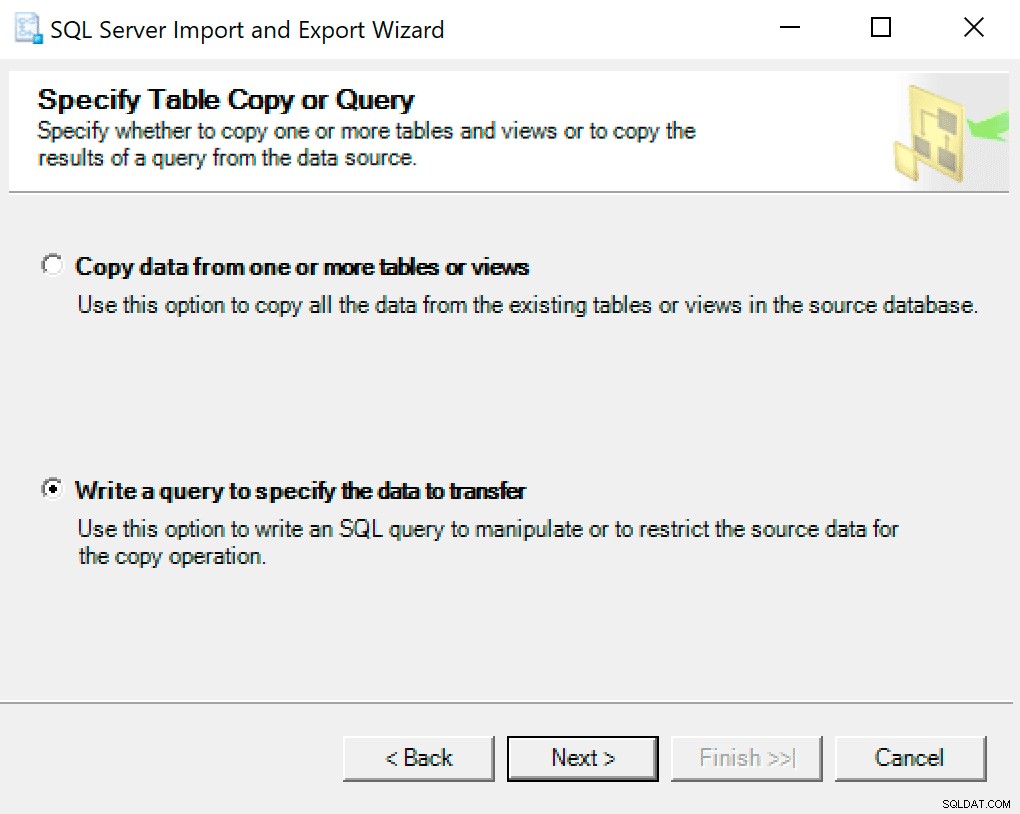
Na další obrazovce vyberte možnost Napsat dotaz pro zadání dat k přenosu .
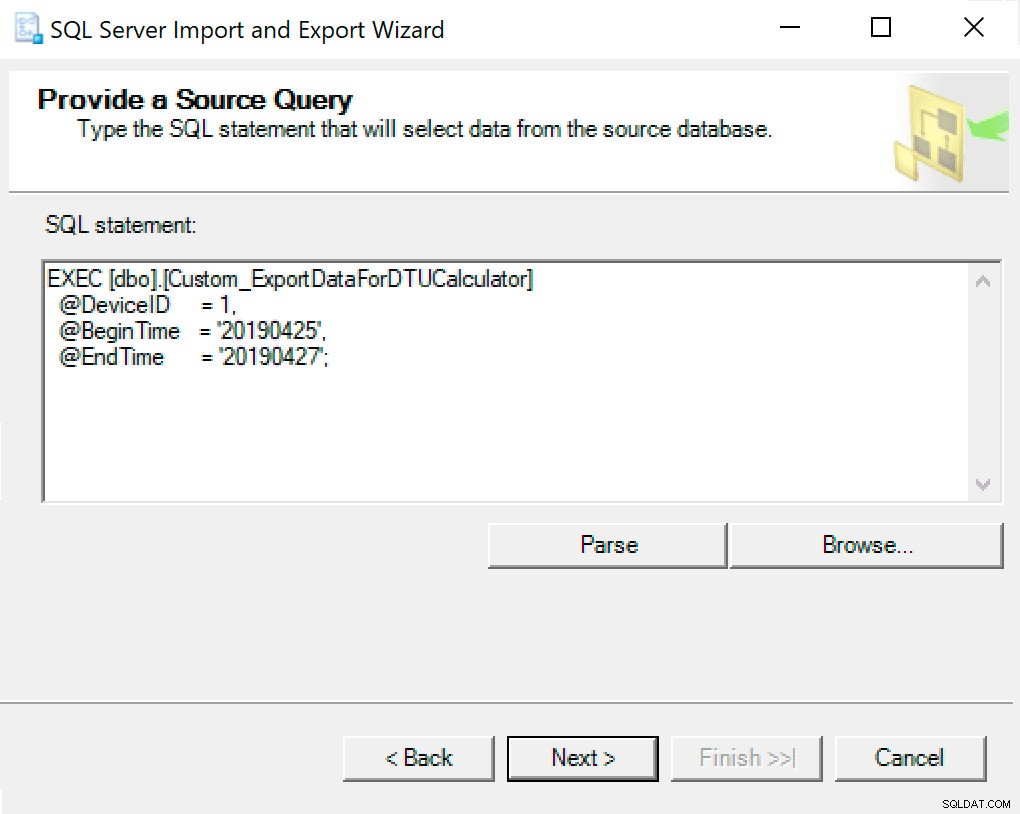
V dalším okně zkopírujte volání procedury s vašimi nastavenými parametry. Další hit.
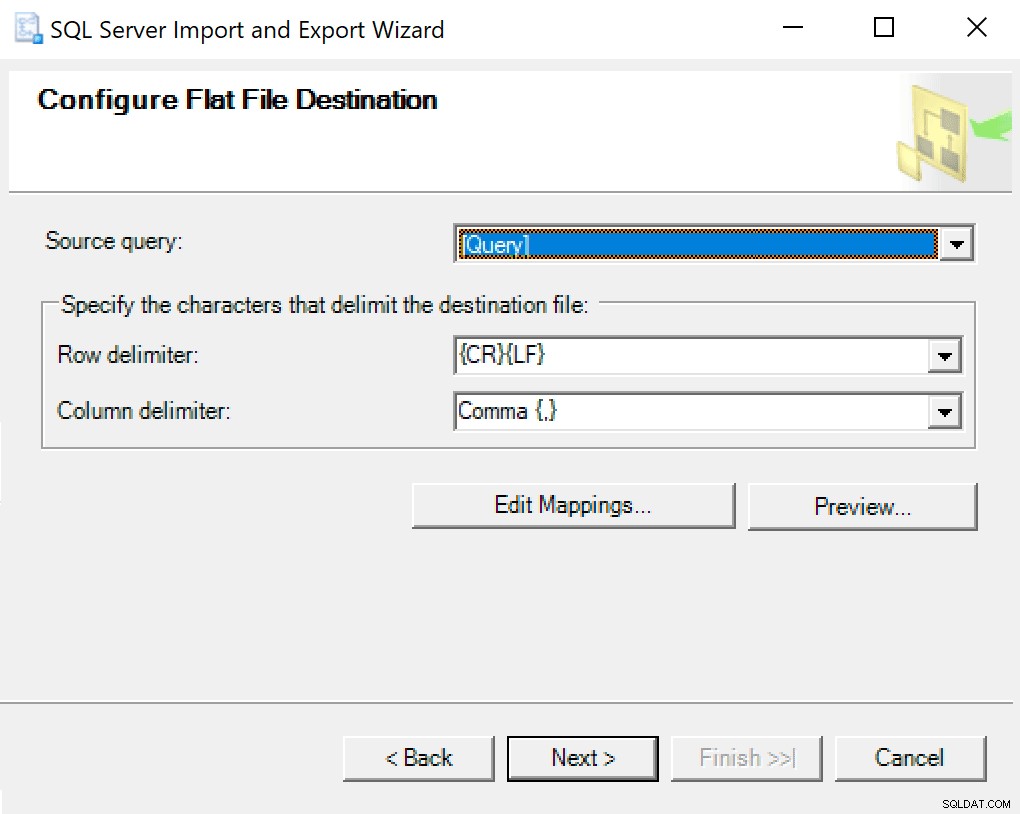
Když se dostanete do cíle Configure Flat File Destination, ponechám možnosti jako výchozí. Zde je snímek obrazovky pro případ, že se vaše liší:
Další hit a běžet okamžitě. Vytvoří se soubor, který použijete v posledním kroku.
POZNÁMKA :Mohli byste vytvořit balíček SSIS, který chcete použít, a poté předat hodnoty parametrů do balíčku SSIS, pokud to budete dělat často. Tím byste zabránili tomu, abyste museli pokaždé procházet průvodcem.
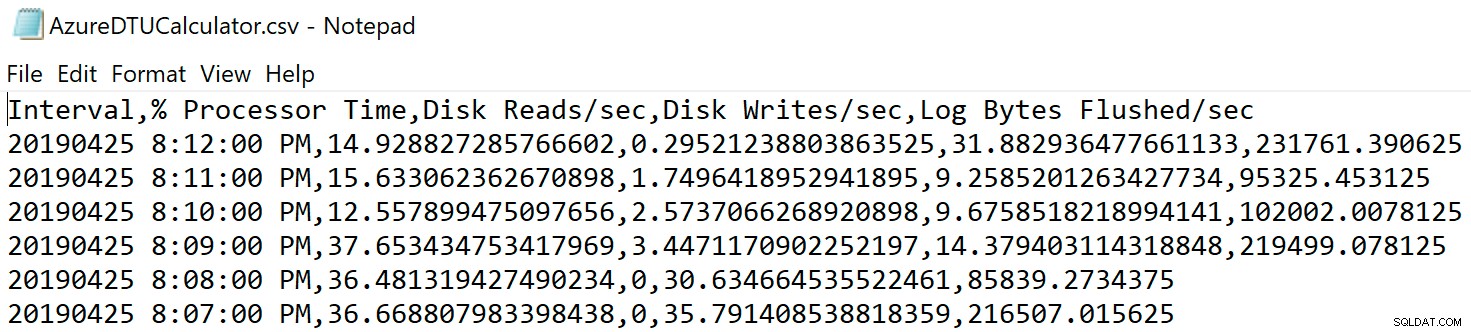
Přejděte do umístění, kam jste soubor uložili, a ověřte, že tam je. Když ji otevřete, měla by vypadat nějak takto:
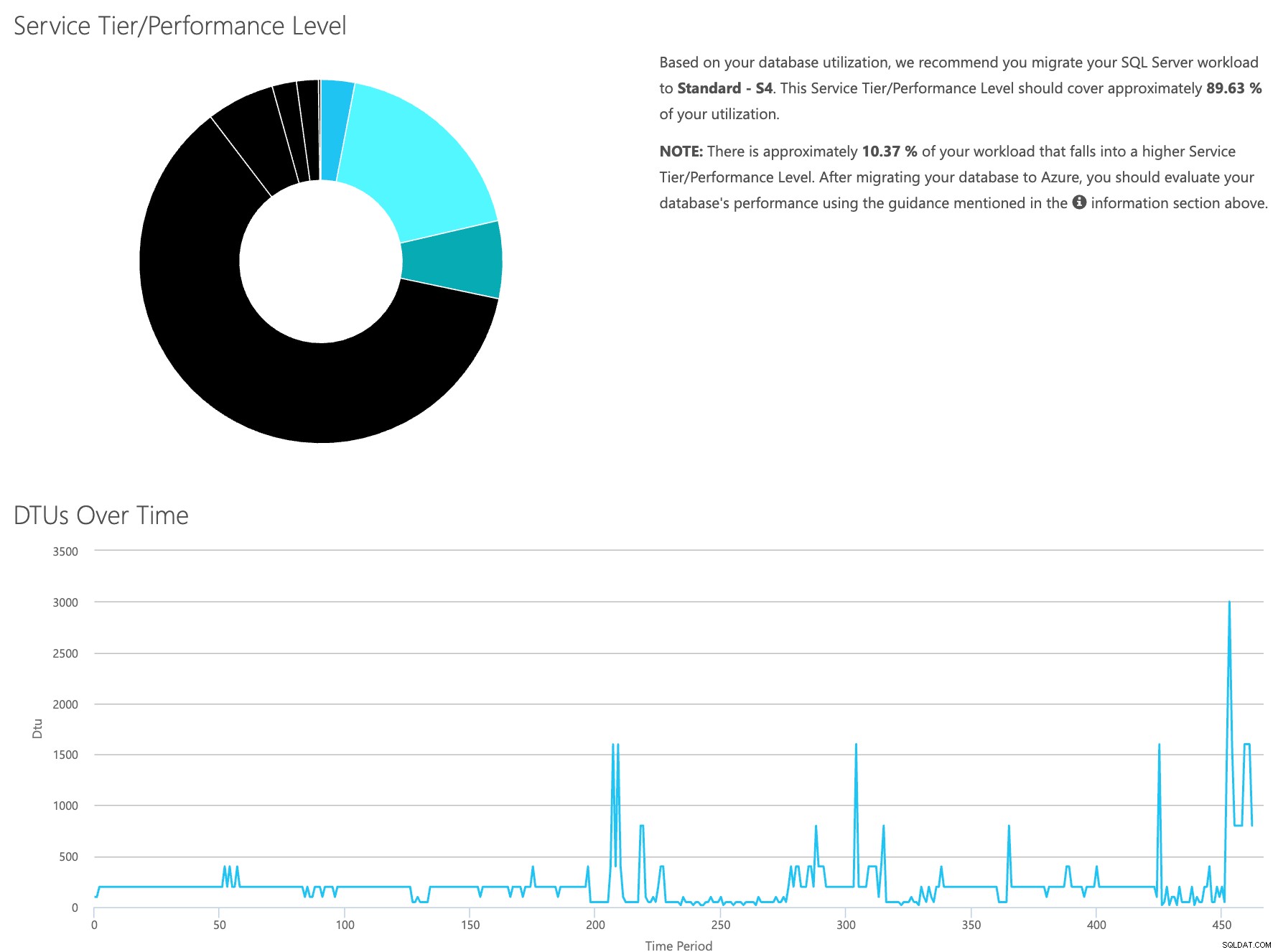
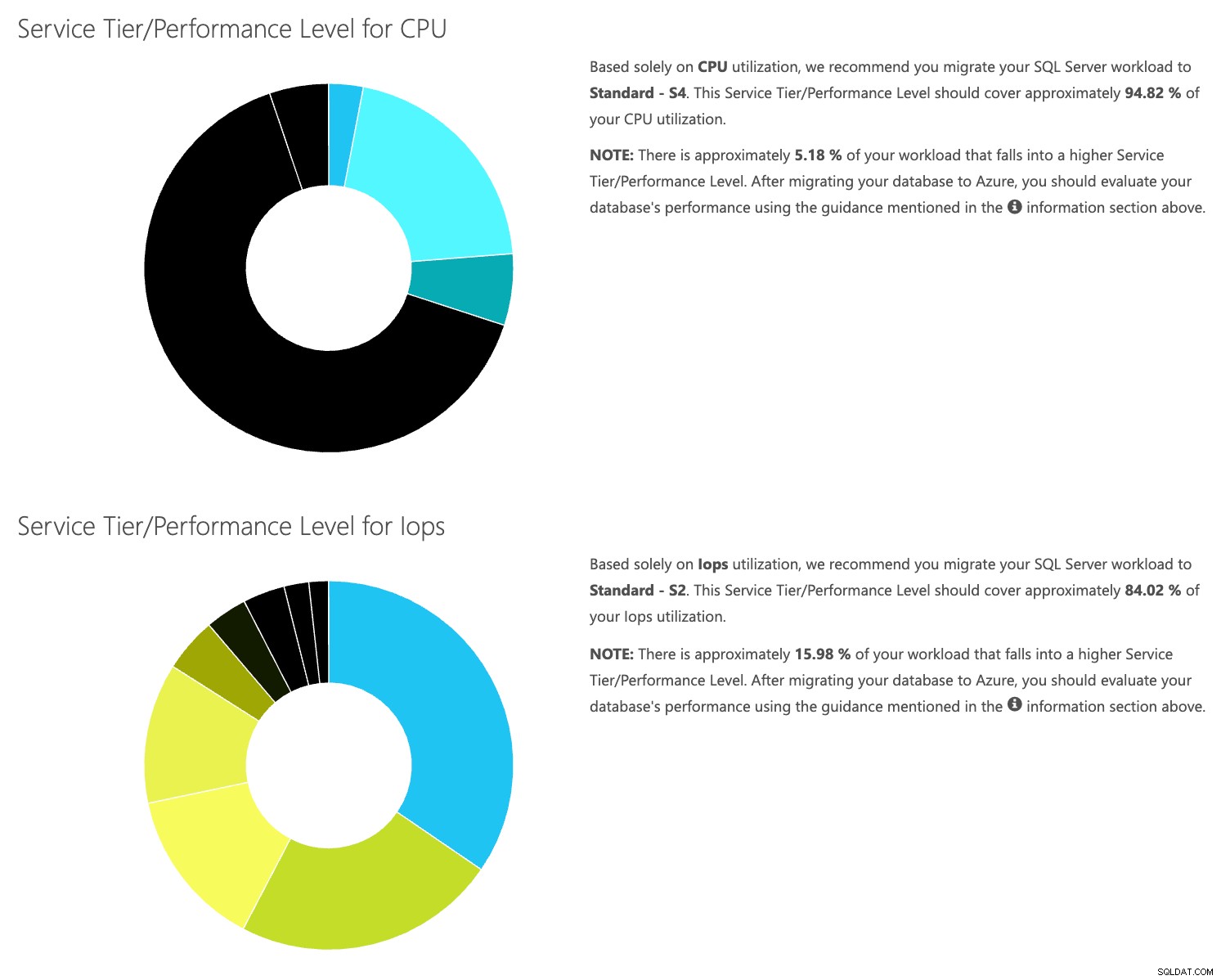
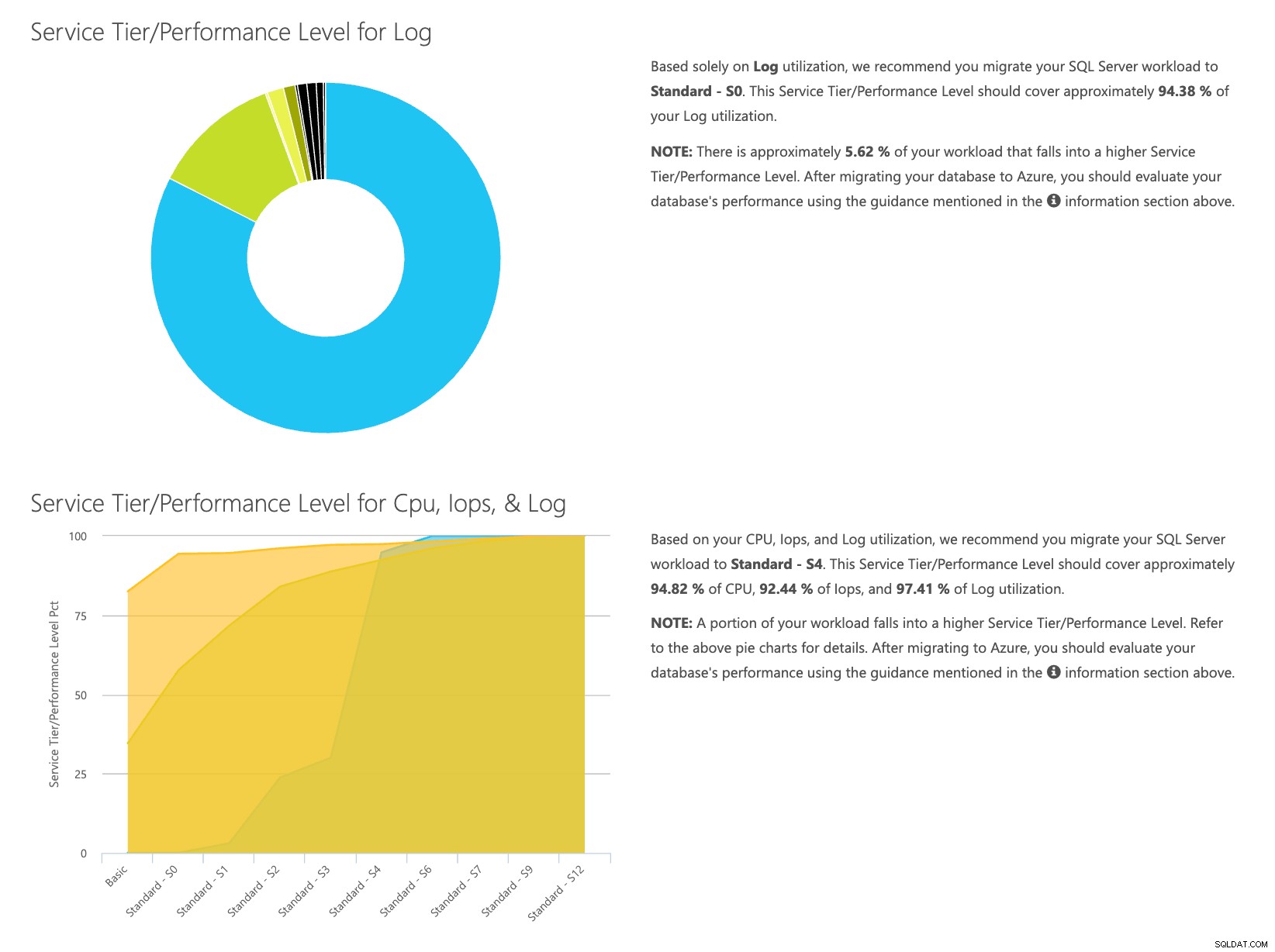
Otevřete webovou stránku kalkulačky DTU a přejděte dolů k části, která říká:„Nahrajte soubor CSV a spočítejte“. Zadejte počet jader, která má server, nahrajte soubor CSV a klikněte na Vypočítat. Získáte sadu výsledků, jako je tento (kliknutím na libovolný obrázek přiblížíte):
Vzhledem k tomu, že máte data uložena odděleně, můžete analyzovat pracovní zatížení v různých časech a můžete to udělat, aniž byste museli ručně spouštět\naplánovat příkazový nástroj\powershell skript pro jakýkoli server, ke kterému již používáte SentryOne.
Pro stručné shrnutí kroků je třeba udělat toto:
- Povolte počítadlo [Database – Log Bytes Flushed/s] a ověřte, že se data shromažďují
- Zkopírujte data z tabulek SentryOne do své vlastní tabulky (a naplánujte to tam, kde je to vhodné).
- Exportujte data z nové tabulky ve správném formátu pro kalkulačku DTU
- Nahrajte soubor CSV do kalkulačky DTU
Pro jakýkoli server/instanci, o které uvažujete o migraci do cloudu a kterou aktuálně monitorujete pomocí SQL Sentry, je to relativně bezproblémový způsob, jak odhadnout, jaký typ úrovně služeb budete potřebovat, a kolik to bude stát. I když to budete muset sledovat, jakmile to tam bude; za tímto účelem se podívejte na SentryOne DB Sentry.
O autorovi
Dustin Dorsey je v současnosti vedoucím databázového inženýra pro LifePoint Health, ve kterém vede tým zodpovědný za správu a inženýrská řešení v databázových technologiích pro 90 nemocnic. Od roku 2008 pracuje a podporuje SQL Server převážně ve zdravotnictví v oblasti administrace, architektury, vývoje a BI. Je vášnivý při hledání způsobů, jak řešit problémy, které sužují každodenní DBA, a rád se o to podělí s ostatními. Můžete ho najít vystupovat na akcích komunity SQL a také blogovat na DustinDorsey.com.