Úvod
Dosažení minimálního protokolování pomocí INSERT...SELECT může být složité podnikání. Úvahy uvedené v Průvodci výkonem načítání dat jsou stále docela obsáhlé, i když je třeba si přečíst také SQL Server 2016, Minimální protokolování a Dopad velikosti dávky v operacích hromadného načítání od Parikshita Savjaniho z týmu SQL Server Tiger Team, abyste získali aktualizovaný obrázek pro SQL Server 2016 a novější, při hromadném načítání do clusterovaných tabulek úložiště řádků. To znamená, že tento článek se zabývá čistě poskytováním nových podrobností o minimálním protokolování při hromadném načítání tradičních (ne „optimalizovaných pro paměť“) tabulek haldy pomocí INSERT...SELECT . Tabulkám s indexem seskupeným b-stromem se věnujeme samostatně ve druhé části této série.
Hromadné tabulky
Při vkládání řádků pomocí INSERT...SELECT do hromady bez neshlukovaných indexů, dokumentace všeobecně uvádí, že takové vložky budou minimálně protokolovány tak dlouho jako TABLOCK nápověda je přítomna. To se odráží v souhrnných tabulkách obsažených v Průvodci výkonem načítání dat a post Tiger Team. Souhrnné řádky pro tabulky haldy bez indexů jsou v obou dokumentech stejné (žádné změny pro SQL Server 2016):

Explicitní TABLOCK nápověda není jediným způsobem, jak splnit požadavek na uzamykání na úrovni tabulky . Můžeme také nastavit ‘zámek stolu při hromadném zatížení‘ možnost pro cílovou tabulku pomocí sp_tableoption nebo povolením dokumentovaného příznaku trasování 715. (Poznámka:Tyto možnosti nestačí k povolení minimálního protokolování při použití INSERT...SELECT protože INSERT...SELECT nepodporuje zámky hromadné aktualizace).
„možné souběžné použití“ sloupec v souhrnu se vztahuje pouze na metody hromadného načítání jiné než INSERT...SELECT . Současné načítání tabulky haldy není možné pomocí INSERT...SELECT . Jak je uvedeno v Průvodci výkonem načítání dat , hromadné načítání pomocí INSERT...SELECT bere exkluzivitu X zámek na stole, nikoli hromadná aktualizace BU zámek vyžadován pro souběžné hromadné načítání.
To vše stranou – a za předpokladu, že neexistuje žádný jiný důvod neočekávat minimální protokolování při hromadném načítání neindexované haldy pomocí TABLOCK (nebo ekvivalentní) — vložka stále nemusí být minimálně přihlášeni…
Výjimka z pravidla
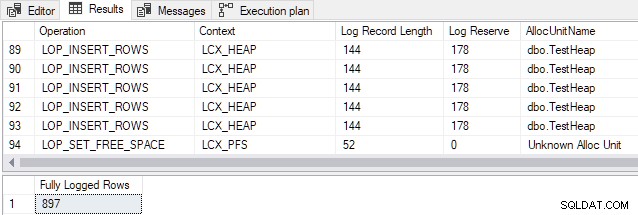
Následující ukázkový skript by měl být spuštěn na vývojové instanci v nové testovací databázi nastavte na použití SIMPLE model obnovy. Načte určitý počet řádků do tabulky haldy pomocí INSERT...SELECT pomocí TABLOCK a sestavy o vygenerovaných záznamech protokolu transakcí:
CREATE TABLE dbo.TestHeap( id integer NOT NULL IDENTITY, c1 integer NOT NULL, padding char(45) NOT NULL DEFAULT '');GO-- Vymazat logCHECKPOINT;GO-- Vložit řádkyINSERT dbo.TestHeap WITH (TABLOCK ) (c1)SELECT TOP (897) CHECKSUM(NEWID())FROM master.dbo.spt_values AS SV;GO-- Zobrazit položky protokoluSELECT FD.Operation, FD.Context, FD.[Log Record Length], FD.[Log Reserve], FD.AllocUnitName, FD.[Název transakce], FD.[Informace o zámku], FD.[Popis]FROM sys.fn_dblog(NULL, NULL) AS FD;GO-- Spočítejte počet plně přihlášených řádkůSELECT [ Plně protokolované řádky] =COUNT_BIG(*) OD sys.fn_dblog(NULL, NULL) JAKO FDWHERE FD.Operation =N'LOP_INSERT_ROWS' AND FD.Context =N'LCX_HEAP' AND FD.AllocUnitName =N'dbo.TestHeap'<; /před>Výstup ukazuje, že všech 897 řádků bylo plně protokolováno navzdory zjevnému splnění všech podmínek pro minimální protokolování (z prostorových důvodů je uveden pouze vzorek záznamů protokolu):
Stejný výsledek je vidět, pokud se vložení opakuje (tj. nezáleží na tom, zda je tabulka haldy prázdná nebo ne). Tento výsledek je v rozporu s dokumentací.
Minimální práh protokolování pro hromady
Počet řádků, které je třeba přidat do jednoho
INSERT...SELECTk dosažení minimálního protokolování do neindexované haldy s povoleným uzamčením tabulky závisí na výpočtu, který SQL Server provádí při odhadu celkové velikosti údajů, které mají být vloženy. Vstupy pro tento výpočet jsou:
- Verze serveru SQL.
- Odhadovaný počet řádků vedoucích do Vložit operátor.
- Velikost cílového řádku tabulky.
Pro SQL Server 2012 a starší , přechodový bod pro tuto konkrétní tabulku je 898 řádků . Změna čísla v demo skriptu TOP klauzule od 897 do 898 vytváří následující výstup:
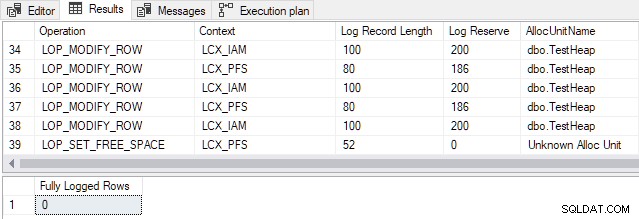
Vygenerované položky protokolu transakcí se týkají alokace stránek a údržby Mapy alokace indexu (IAM) a Page Free Space (PFS) struktur. Pamatujte na minimální protokolování znamená, že SQL Server nezaznamenává každé vložení řádku samostatně. Místo toho jsou protokolovány pouze změny metadat a alokačních struktur. Změna z 897 na 898 řádků umožňuje minimální protokolování pro tuto konkrétní tabulku.
Pro SQL Server 2014 a novější , přechodový bod je 950 řádků pro tento stůl. Spuštěním INSERT...SELECT s TOP (949) bude používat úplné protokolování – změna na TOP (950) vytvoří minimální protokolování .
Prahové hodnoty nejsou závisí na Odhadu mohutnosti používaný model nebo úroveň kompatibility databáze.
Výpočet velikosti dat
Zda se SQL Server rozhodne použít hromadné načtení sady řádků — a tedy zda minimální protokolování je nebo není k dispozici — závisí na výsledku řady výpočtů provedených metodou nazvanou sqllang!CUpdUtil::FOptimizeInsert , což buď vrátí true pro minimální protokolování nebo false pro úplné přihlášení. Příklad zásobníku volání je uveden níže:
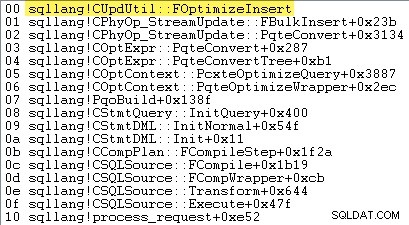
Podstatou testu je:
- Vložka musí obsahovat více než 250 řádků .
- Celková velikost vložených dat musí být vypočtena jako nejméně 8 stránek .
Kontrola více než 250 řádků závisí pouze na odhadovaném počtu řádků přicházejících do Vložení tabulky operátor. V plánu provádění je to zobrazeno jako ‘Odhadovaný počet řádků‘ . Buďte opatrní. Je snadné vytvořit plán s nízkým odhadovaným počtem řádků, například pomocí proměnné v TOP klauzule bez OPTION (RECOMPILE) . V takovém případě optimalizátor odhadne 100 řádků, které nedosáhnou prahové hodnoty, a zabrání tak hromadnému zatížení a minimálnímu protokolování.
Výpočet celkové velikosti dat je složitější a neodpovídá „Odhadovaná velikost řádku“ proudící do Vložení tabulky operátor. Způsob provedení výpočtu se v SQL Server 2012 a dřívějších verzích mírně liší ve srovnání s SQL Server 2014 a novějšími. Přesto oba vytvářejí výsledek velikosti řádku, který se liší od toho, co je vidět v prováděcím plánu.
Výpočet velikosti řádku
Celková velikost vložených dat se vypočítá vynásobením odhadovaného počtu řádků podle očekávané maximální velikosti řádku . Výpočet velikosti řádku je bod, který se liší mezi verzemi SQL Server.
V SQL Server 2012 a starších verzích výpočet provádí sqllang!OptimizerUtil::ComputeRowLength . Pro testovací tabulku haldy (záměrně navržená s jednoduchými nenulovými sloupci s pevnou délkou pomocí původního FixedVar formát uložení řádku) osnova výpočtu je:
- Inicializujte FixedVar generátor metadat.
- Získejte informace o typu a atributech pro každý sloupec v Vložení tabulky vstupní proud.
- Přidejte do metadat zadané sloupce a atributy.
- Dokončete generátor a požádejte jej o maximální velikost řádku.
- Přidejte režii pro nulovou bitmapu a počet sloupců.
- Přidejte čtyři bajty pro řádek stavové bity a řádek offset k počtu dat sloupců.
Fyzická velikost řádku
Lze očekávat, že výsledek tohoto výpočtu bude odpovídat velikosti fyzického řádku, ale není tomu tak. Například s vypnutým verzováním řádků pro databázi:
SELECT DDIPS.index_type_desc, DDIPS.alloc_unit_type_desc, DDIPS.page_count, DDIPS.record_count, DDIPS.min_record_size_in_bytes, DDIPS.max_record_size_in_bytes, JDIPS.avg_record_size_in_bytes, DDIPS.avg_record_size_in_bytes, DDIPS.avg_record_size_in_bytes, DDIPS.avg_record_size_in_s. U'), 0, -- halda NULL, -- všechny oddíly 'DETAILNÍ') JAKO DDIPS;
…udává velikost záznamu 60 bajtů v každém řádku testovací tabulky:

Postup je popsán v části Odhad velikosti haldy:
- Celková velikost bajtů všech pevných délek sloupce =53 bajtů:
id integer NOT NULL=4 bajtyc1 integer NOT NULL=4 bajtypadding char(45) NOT NULL=45 bajtů.
- Nová bitmapa =3 bajty :
- =2 + int((Num_Cols + 7) / 8)
- =2 + int((3 + 7) / 8)
- =3 bajty.
- Záhlaví řádku =4 bajty .
- Celkem 53 + 3 + 4 =60 bajtů .
Odpovídá také odhadované velikosti řádku zobrazené v plánu provádění:

Podrobnosti interního výpočtu
Interní výpočet použitý k určení, zda se použije hromadné zatížení, přináší jiný výsledek na základě následujícího vložit stream informace o sloupcích získané pomocí debuggeru. Použitá čísla typů odpovídají sys.types :
- Celková pevná délka velikost sloupce =66 bajtů :
- ID typu 173
binary(8)=8 bajtů (interní). - Zadejte ID 56
integer=4 bajty (interní). - ID typu 104
bit=1 bajt (interní). - Zadejte ID 56
integer=4 bajty (idsloupec). - Zadejte ID 56
integer=4 bajty (c1sloupec). - ID typu 175
char(45)=45 bajtů (paddingsloupec).
- ID typu 173
- Nová bitmapa =3 bajty (jako dříve).
- Záhlaví řádku režie =4 bajty (jako dříve).
- Vypočítaná velikost řádku =66 + 3 + 4 =73 bajtů .
Rozdíl je v tom, že vstupní proud napájí Vložení tabulky obsahuje tři další interní sloupce . Ty jsou odstraněny při generování showplanu. Další sloupce tvoří lokátor vložení tabulky , který obsahuje záložku (RID nebo lokátor řádku) jako svou první komponentu. Jsou to metadata pro vložení a neskončí přidáním do tabulky.
Další sloupce vysvětlují nesrovnalosti mezi výpočtem provedeným pomocí OptimizerUtil::ComputeRowLength a fyzickou velikost řádků. To by mohlo být považováno za chybu :SQL Server by neměl započítávat sloupce metadat ve vloženém proudu do konečné fyzické velikosti řádku. Na druhou stranu může být výpočet jednoduše odhadem nejlepšího úsilí pomocí obecné aktualizace operátor.
Výpočet také nebere v úvahu další faktory, jako je 14bajtová režie verzování řádků. To lze otestovat opětovným spuštěním ukázkového skriptu s některou z izolací snímku nebo přečtěte si izolaci potvrzeného snímku možnosti databáze povoleny. Fyzická velikost řádku se zvýší o 14 bajtů (ze 60 bajtů na 74), ale prahová hodnota pro minimální protokolování zůstává nezměněn na 898 řádcích.
Výpočet prahu
Nyní máme všechny podrobnosti, které potřebujeme, abychom viděli, proč je prahová hodnota 898 řádků pro tuto tabulku na SQL Server 2012 a dřívějších verzích:
- 898 řádků splňuje první požadavek na více než 250 řádků .
- Velikost vypočítaného řádku =73 bajtů.
- Odhadovaný počet řádků =897.
- Celková velikost dat =73 bajtů * 897 řádků =65481 bajtů.
- Celkový počet stránek =65481 / 8192 =7,9932861328125.
- To je těsně pod druhým požadavkem na>=8 stránek.
- Pro 898 řádků je počet stránek 8,002197265625.
- Toto je >=8 stránek takže minimální protokolování je aktivován.
V SQL Server 2014 a novějších , změny jsou:
- Velikost řádku vypočítává generátor metadat.
- Interní celočíselný sloupec v lokátoru tabulky již není přítomen ve vloženém proudu. To představuje jednoznačný prvek , který se vztahuje pouze na indexy. Zdá se pravděpodobné, že to bylo odstraněno jako oprava chyby.
- Očekávaná velikost řádku se změní ze 73 na 69 bajtů kvůli vynechanému sloupci typu celé číslo (4 bajty).
- Fyzická velikost je stále 60 bajtů. Zbývající rozdíl 9 bajtů připadá na extra 8bajtový RID a 1bajtový bitový interní sloupec ve vkládacím proudu.
Chcete-li dosáhnout prahu 8 stránek s 69 bajty na řádek:
- 8 stránek * 8192 bajtů na stránku =65536 bajtů.
- 65535 bajtů / 69 bajtů na řádek =949,7971014492754 řádků.
- Očekáváme proto minimálně 950 řádků povolit hromadné načítání sady řádků pro tuto tabulku na SQL Server 2014 a novější.
Souhrn a závěrečné myšlenky
Na rozdíl od metod hromadného načítání, které podporují velikost dávky , jak je uvedeno v příspěvku Parikshita Savjaniho, INSERT...SELECT do neindexované haldy (prázdné nebo ne) ne vždy výsledkem je minimální protokolování, když je specifikováno zamykání tabulky.
Chcete-li povolit minimální protokolování pomocí INSERT...SELECT , SQL Server musí očekávat více než 250 řádků s celkovou velikostí alespoň jeden rozsah (8 stránek).
Při výpočtu odhadované celkové velikosti vložení (pro srovnání s prahem 8 stránek) SQL Server vynásobí odhadovaný počet řádků vypočítanou maximální velikostí řádku. SQL Server počítá interní sloupce přítomné ve vloženém proudu při výpočtu velikosti řádku. Pro SQL Server 2012 a starší to přidá 13 bajtů na řádek. Pro SQL Server 2014 a novější přidává 9 bajtů na řádek. To ovlivní pouze výpočet; nemá to vliv na konečnou fyzickou velikost řádků.
Když je aktivní minimálně protokolované hromadné načítání haldy, SQL Server není vkládat řádky jeden po druhém. Rozsahy jsou přiděleny předem a řádky, které mají být vloženy, jsou shromažďovány do celých nových stránek pomocí sqlmin!RowsetBulk před přidáním do stávající struktury. Příklad zásobníku volání je uveden níže:
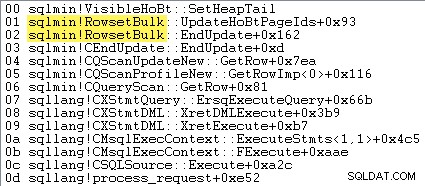
Logická čtení nejsou hlášena pro cílovou tabulku, když je použito minimálně protokolované hromadné zatížení haldy – Vložení tabulky operátor nemusí číst existující stránku, aby našel textový kurzor pro každý nový řádek.
Plány provádění se aktuálně nezobrazují kolik řádků nebo stránek bylo vloženo pomocí hromadného načtení sady řádků a minimální protokolování . Možná budou tyto užitečné informace přidány k produktu v budoucí verzi.