Dostáváme několik pěkných ohlasů ohledně našeho produktu ClusterControl, zejména toho, jak snadná je instalace a spuštění. Instalace nového softwaru je jedna věc, ale jeho správné používání je věc druhá.
Není neobvyklé být při testování nového softwaru netrpělivý a než začít číst dokumentaci, raději si pohráváte s novou vzrušující aplikací. To je trochu nešťastné, protože vám mohou uniknout důležité funkce nebo nepochopíte, jak je používat.
Tato série blogů pokrývá všechny základní operace ClusterControl pro MySQL, MongoDB a PostgreSQL s příklady, jak ze svého nastavení vytěžit maximum. Poskytuje vám hluboký ponor do různých témat a šetří vám čas.
Toto jsou témata obsažená v této sérii:
- Nasazení prvních clusterů
- Přidání stávající infrastruktury
- Monitorování výkonu a zdraví
- Vytváření HA komponentů
- Správa pracovního postupu
- Ochrana vašich dat
- Ochrana vašich dat
- Podrobný případ použití
V dnešním příspěvku se budeme zabývat instalací ClusterControl a nasazením vašich prvních clusterů.
Přípravy
V této sérii použijeme sadu Vagrant boxů, ale pokud chcete, můžete použít svou vlastní infrastrukturu. V případě, že to chcete otestovat pomocí Vagrant, zpřístupnili jsme příklad nastavení z následujícího úložiště Github:https://github.com/severalnines/vagrant
Naklonujte úložiště do vlastního počítače:
$ git clone example@sqldat.com:severalnines/vagrant.gitTopologie tulákových uzlů je následující:
- vm1:clustercontrol
- vm2:databázový uzel1
- vm3:databázový uzel2
- vm4:databázový uzel3
Pokud chcete, můžete snadno přidat další uzly změnou následujícího řádku:
4.times do |n|Soubor Vagrant je nakonfigurován tak, aby automaticky nainstaloval ClusterControl na první uzel a předal uživatelské rozhraní ClusterControl na port 8080 na vašem hostiteli, na kterém běží Vagrant. Pokud je tedy IP adresa vašeho hostitele 192.168.1.10, naleznete uživatelské rozhraní ClusterControl zde:https://192.168.1.10:8080/clustercontrol/
Instalace ClusterControl
Toto můžete přeskočit, pokud jste se rozhodli použít soubor Vagrant a získat automatickou instalaci. Instalace ClusterControl je však jednoduchá a zabere méně než pět minut.
Při instalaci balíčku vše, co musíte udělat, je zadat následující tři příkazy na uzlu ClusterControl, abyste jej nainstalovali:
$ wget https://www.severalnines.com/downloads/cmon/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userTo je ono:jednodušší už to být nemůže. Pokud instalační skript nenarazí na žádné problémy, měl by být ClusterControl nainstalován a spuštěn. Nyní se můžete přihlásit do ClusterControl na následující adrese URL:https://192.168.1.210/clustercontrol
Po vytvoření účtu správce a přihlášení budete vyzváni k přidání prvního clusteru.
Nasazení clusteru Galera
Budete vyzváni k vytvoření nového databázového serveru/klastru nebo importu existujícího (tj. již nasazeného) serveru nebo klastru:
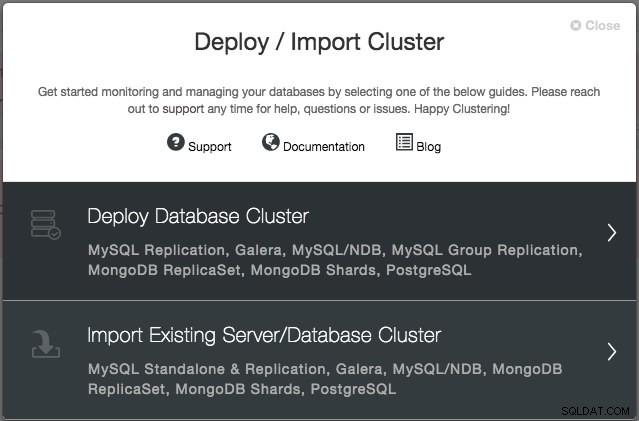
Chystáme se nasadit cluster Galera. Jsou zde dvě sekce, které je třeba vyplnit. První záložka se týká SSH a obecných nastavení:
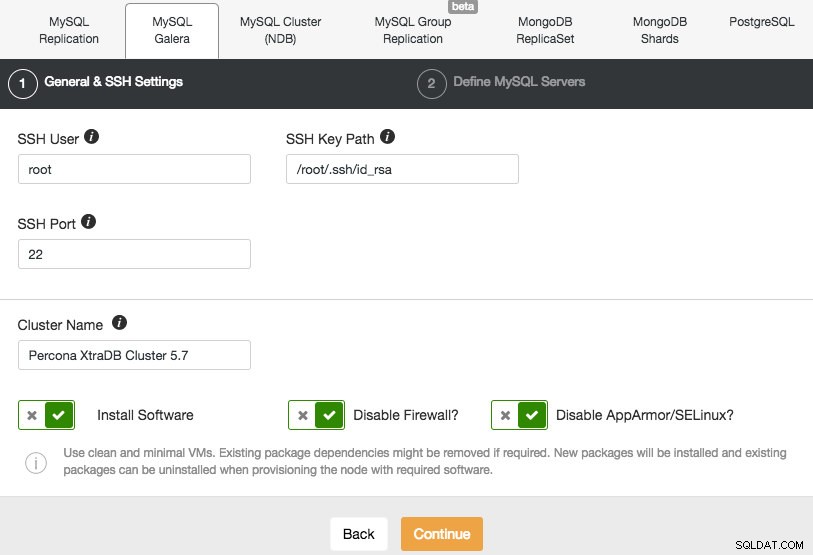
Abychom ClusterControl umožnili instalaci uzlů Galera, používáme uživatele root, kterému byl udělen SSH přístup pomocí bootstrap skriptů Vagrant. V případě, že se rozhodnete používat vlastní infrastrukturu, musíte zde zadat uživatele, který má povoleno provádět SSH bez hesla do uzlů, které bude ClusterControl ovládat. Jen mějte na paměti, že musíte předem sami nastavit SSH bez hesla z ClusterControl do všech uzlů databáze.
Také se ujistěte, že jste zakázali AppArmor/SELinux. Zde se podívejte proč.
Poté pokračujte do druhé fáze a zadejte informace týkající se databáze a cílové hostitele:
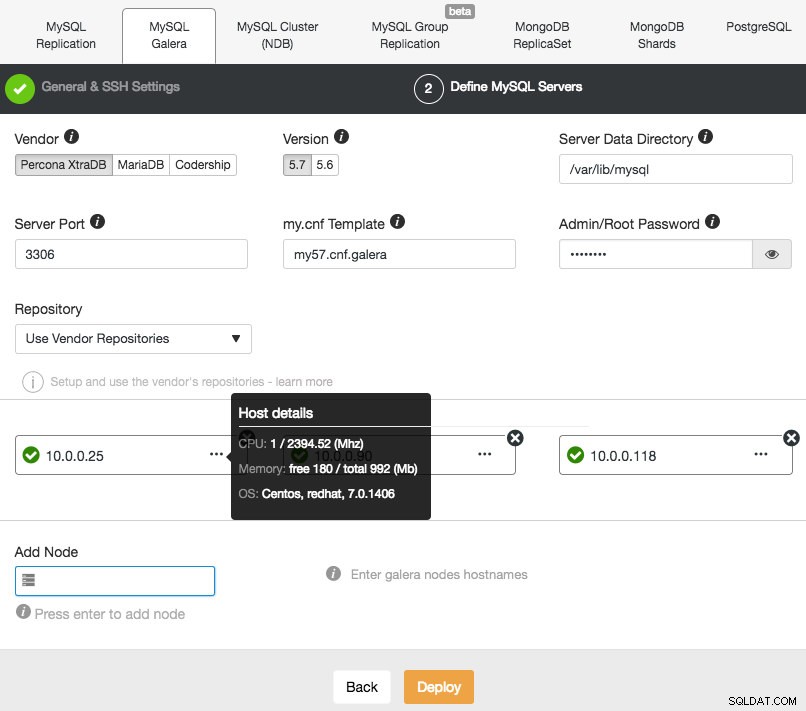
ClusterControl okamžitě provede určité kontroly zdravého rozumu pokaždé, když při přidávání uzlu stisknete Enter. Souhrn hostitele můžete zobrazit umístěním ukazatele myši nad každý definovaný uzel. Jakmile je vše zelené, znamená to, že ClusterControl má připojení ke všem uzlům, můžete kliknout na Deploy. Bude vytvořena úloha pro vytvoření nového clusteru. Příjemné je, že můžete sledovat průběh této úlohy kliknutím na Aktivita -> Úkoly -> Vytvořit seskupení -> Úplné podrobnosti o úloze :
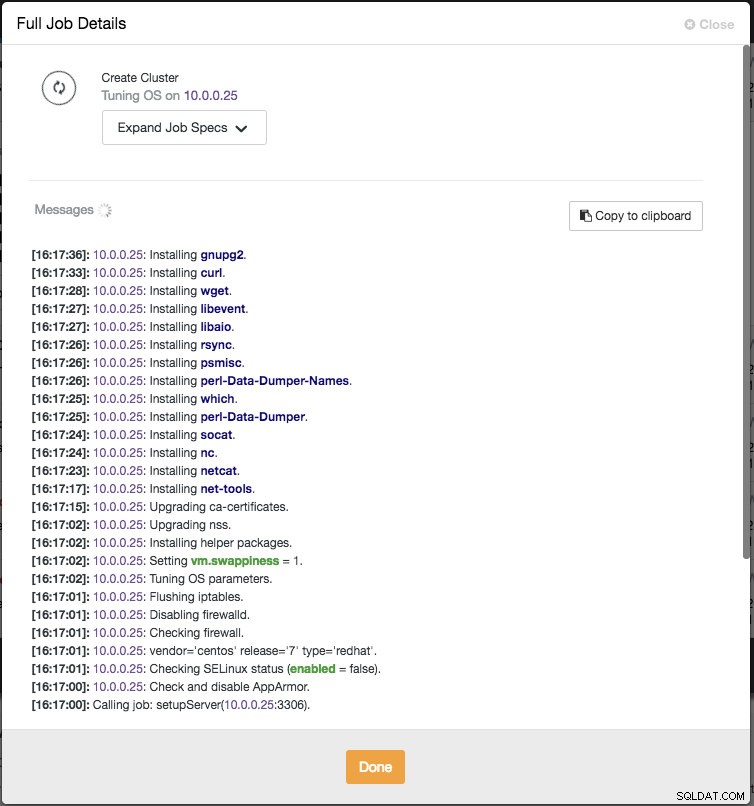
Po dokončení úlohy jste právě vytvořili svůj první cluster. Přehled clusteru by měl vypadat takto:
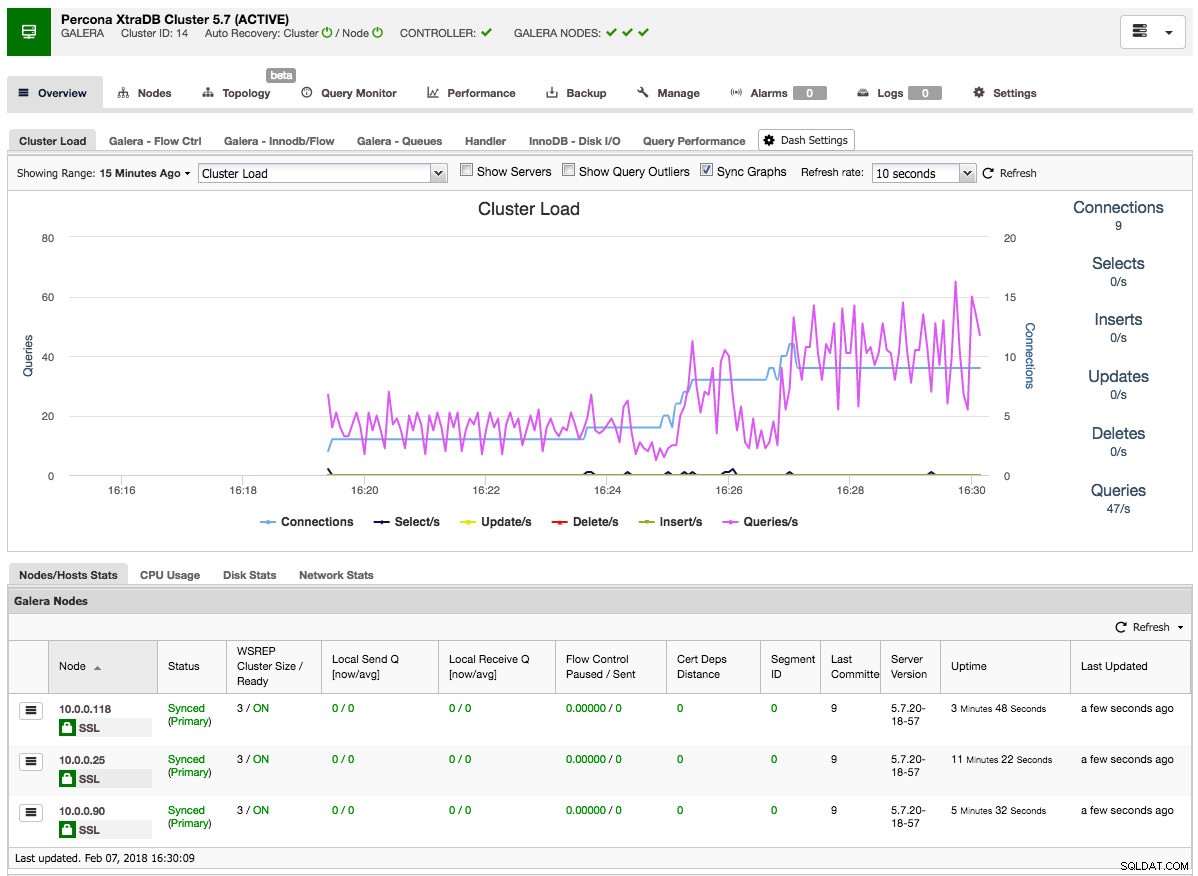
Na kartě uzly můžete provádět jakoukoli operaci, kterou byste normálně provedli na clusteru. Monitor dotazů vám poskytuje dobrý přehled o spuštěných i hlavních dotazech. Karta Výkon vám pomůže bedlivě sledovat výkon vašeho clusteru a obsahuje také poradce, kteří vám pomohou proaktivně jednat podle trendů v datech. Karta zálohování vám umožňuje snadno plánovat zálohování a ukládat je na místní nebo cloudové úložiště. Karta Správa vám umožňuje rozšířit váš cluster nebo jej zpřístupnit vašim aplikacím prostřednictvím nástroje pro vyrovnávání zatížení.
Všechny tyto funkce budou popsány v dalších příspěvcích na blogu v této sérii.
Nasazení replikačního clusteru MySQL
Nasazení nastavení replikace MySQL je podobné nasazení databáze Galera, kromě toho, že má další kartu v dialogovém okně nasazení, kde můžete definovat topologii replikace:
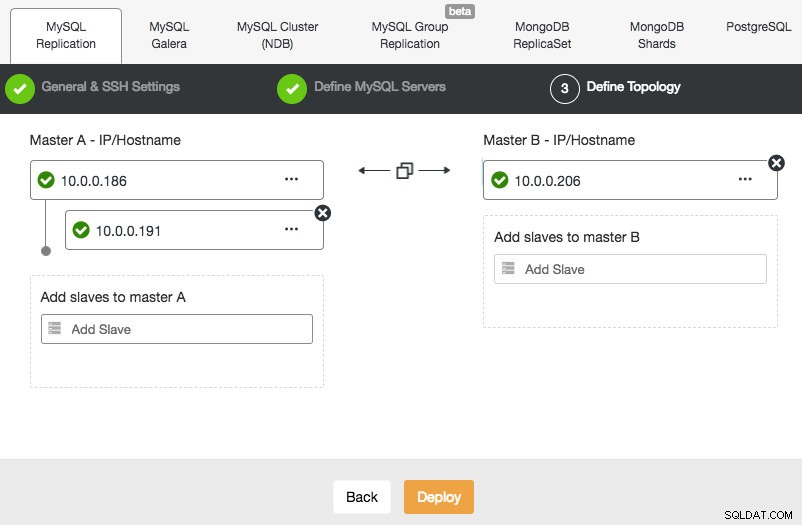
Můžete nastavit standardní replikaci master-slave i replikaci master-master. V druhém případě zůstane zapisovatelný vždy pouze jeden master. Mějte na paměti, že replikace master-master nepřichází s řešením konfliktů a zaručenou konzistencí dat, jako v případě Galery. Používejte toto nastavení opatrně nebo se podívejte do clusteru Galera. Jakmile je vše zelené a kliknete na Deploy, vytvoří se úloha pro vytvoření nového clusteru.
Opět platí, že průběh nasazení je k dispozici v části Aktivita -> Úlohy.
Chcete-li škálovat slave (čtení kopie), jednoduše použijte možnost „Přidat uzel“ v seznamu clusteru:
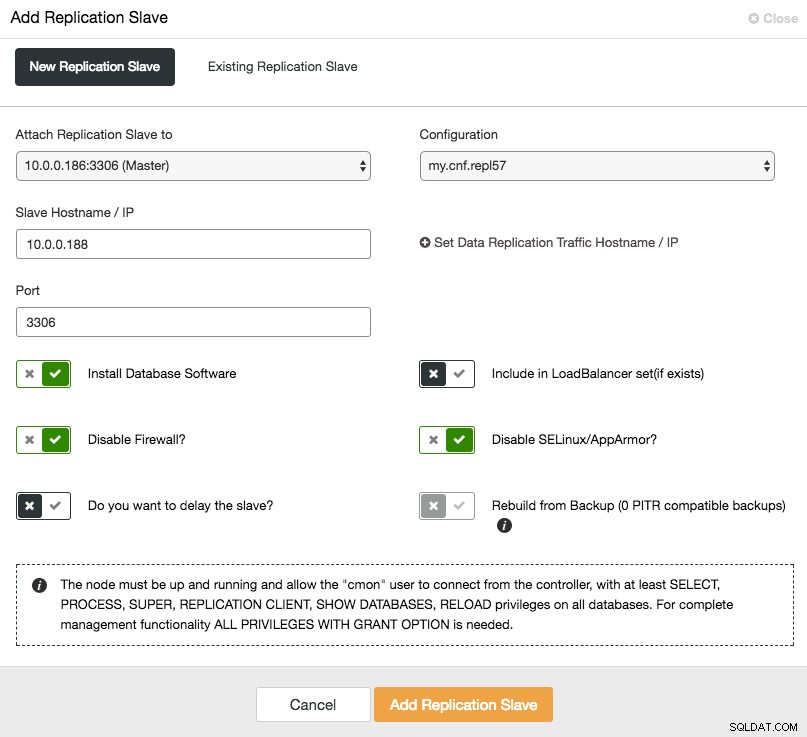
Po přidání podřízeného uzlu ClusterControl poskytne podřízenému uzlu kopii dat z jeho masteru pomocí Xtrabackup nebo z jakýchkoli existujících záloh kompatibilních s PITR pro tento cluster.
Nasaďte replikaci PostgreSQL
ClusterControl podporuje nasazení PostgreSQL verze 9.xa vyšší. Kroky jsou podobné s nasazením MySQL Replication, kde na konci kroku nasazení můžete definovat topologii databáze při přidávání uzlů:
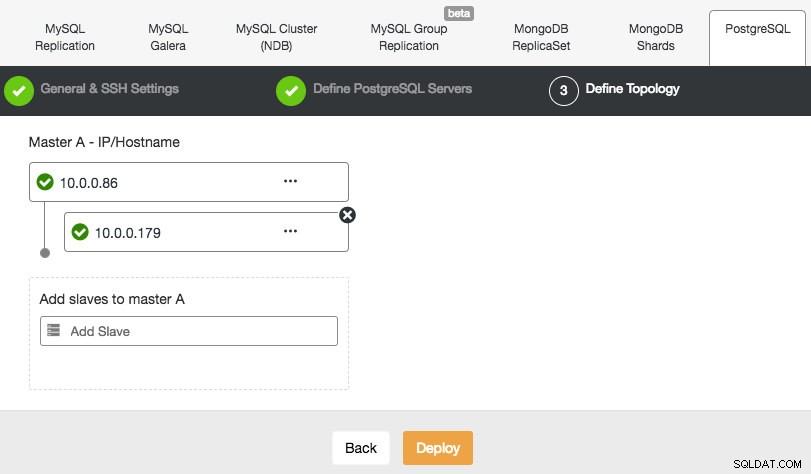
Podobně jako u replikace MySQL můžete po dokončení nasazení škálovat přidáním podřízených replikací do clusteru. Krok je stejně jednoduchý jako výběr hlavního zařízení a vyplnění FQDN pro nového podřízeného:
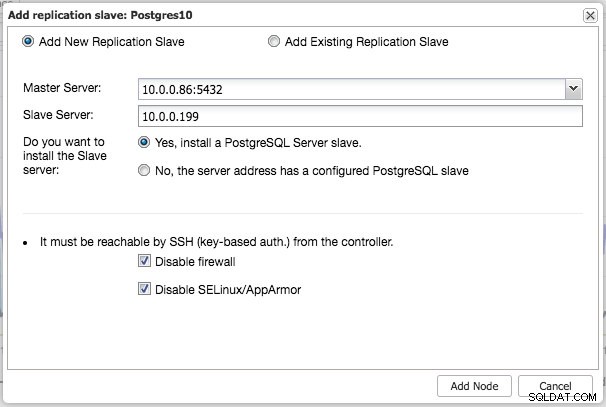
ClusterControl poté provede potřebnou přípravu dat z vybraného masteru pomocí pg_basebackup, nakonfiguruje uživatele replikace a povolí streamingovou replikaci. Přehled clusteru PostgreSQL vám poskytne určitý přehled o vašem nastavení:
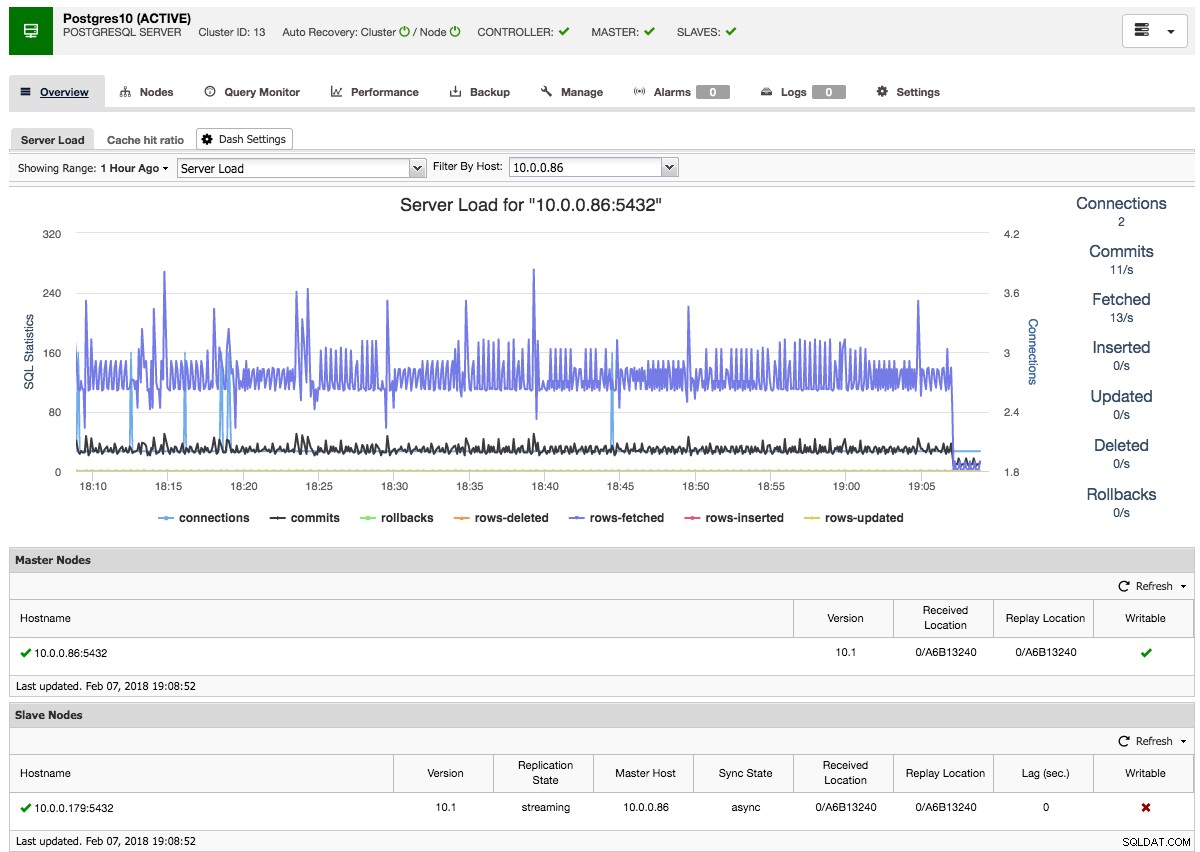
Stejně jako u přehledů clusterů Galera a MySQL zde naleznete všechny potřebné karty a funkce:karty sledování dotazů, výkon a zálohování, to vše vám umožňuje provádět potřebné operace.
Nasazení sady replik MongoDB
Nasazení nové sady replik MongoDB je podobné jako u ostatních clusterů. V dialogu Deploy Database Cluster vyberte MongoDB ReplicatSet, definujte preferované možnosti databáze a přidejte databázové uzly:
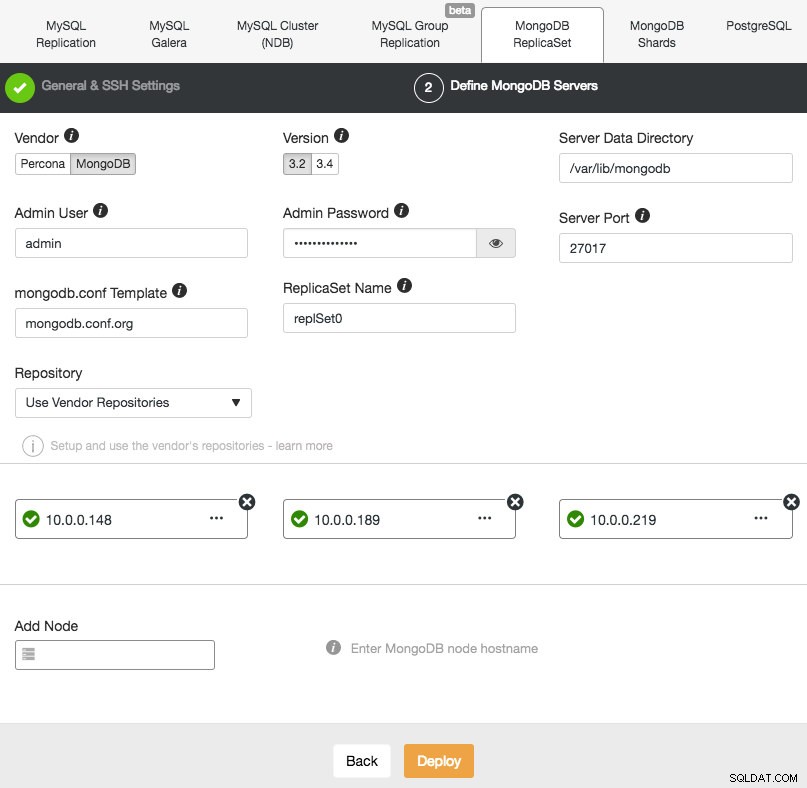
Můžete si vybrat instalaci Percona Server pro MongoDB od Percona nebo MongoDB Server od MongoDB, Inc (dříve 10gen). Musíte také zadat uživatele a heslo správce MongoDB, protože ClusterControl ve výchozím nastavení nasadí cluster MongoDB s povoleným ověřováním.
Po instalaci clusteru můžete přidat další podřízený nebo rozhodovací uzel do sady replik pomocí nabídky „Přidat uzel“ ve stejné rozevírací nabídce z přehledu clusteru:
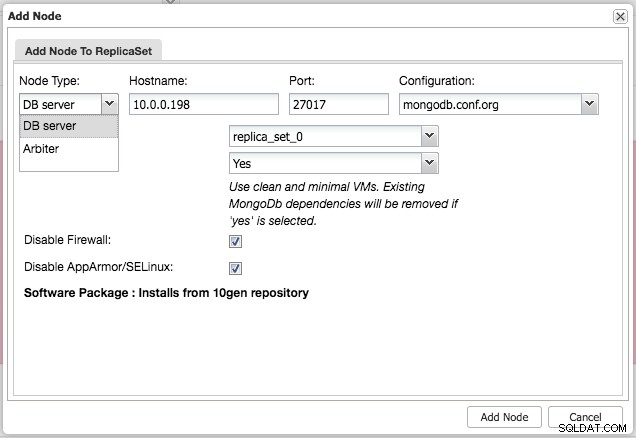
Po přidání slave nebo arbitra do sady replik se vytvoří úloha. Po dokončení této úlohy bude chvíli trvat, než ji MongoDB přidá do clusteru a bude viditelná v přehledu clusteru:
Poslední myšlenky
Na těchto třech příkladech jsme vám ukázali, jak snadné je nastavit různé clustery od začátku za pouhých pár minut. Krása použití tohoto nastavení Vagrant je v tom, že stejně snadné jako spawnování tohoto prostředí ho můžete také sundat a poté znovu spustit. Udělejte dojem na své kolegy tím, že ukážete, jak rychle můžete nastavit pracovní prostředí.
Samozřejmě by bylo stejně zajímavé přidat stávající hostitele a již nasazené clustery do ClusterControl a tím se budeme zabývat příště.