Někdo omylem smazal část databáze. Někdo zapomněl zahrnout klauzuli WHERE do dotazu DELETE nebo vypustil špatnou tabulku. Takové věci se mohou a budou dít, je to nevyhnutelné a lidské. Ale dopad může být katastrofální. Co můžete udělat, abyste se před podobnými situacemi ochránili, a jak můžete svá data obnovit? V tomto příspěvku na blogu pokryjeme některé z nejtypičtějších případů ztráty dat a jak se můžete připravit, abyste se z nich mohli zotavit.
Přípravy
Existují věci, které byste měli udělat, abyste zajistili hladké zotavení. Pojďme si je projít. Mějte prosím na paměti, že nejde o situaci „vyberte si jednu“ – v ideálním případě zavedete všechna opatření, o kterých budeme diskutovat níže.
Záloha
Musíte mít zálohu, z té se nedá uniknout. Záložní soubory byste měli nechat otestovat – pokud své zálohy neotestujete, nemůžete si být jisti, zda jsou dobré a zda je někdy budete moci obnovit. Pro obnovu po havárii byste si měli ponechat kopii zálohy někde mimo vaše datové centrum – pro případ, že by se celé datové centrum stalo nedostupným. Pro urychlení obnovy je velmi užitečné ponechat kopii zálohy také na uzlech databáze. Pokud je vaše datová sada velká, její kopírování přes síť ze záložního serveru do databázového uzlu, který chcete obnovit, může trvat dlouho. Uchovávání nejnovější zálohy lokálně může výrazně zkrátit dobu obnovy.
Logická záloha
Vaše první záloha bude s největší pravděpodobností fyzická záloha. Pro MySQL nebo MariaDB to bude buď něco jako xtrabackup nebo nějaký snímek souborového systému. Takové zálohy jsou skvělé pro obnovu celé datové sady nebo pro zřizování nových uzlů. V případě smazání podmnožiny dat však trpí značnou režií. Za prvé, nemůžete obnovit všechna data, jinak přepíšete všechny změny, ke kterým došlo po vytvoření zálohy. To, co hledáte, je schopnost obnovit pouze podmnožinu dat, pouze řádky, které byly náhodně odstraněny. Chcete-li to provést pomocí fyzické zálohy, museli byste ji obnovit na samostatném hostiteli, najít odstraněné řádky, vypsat je a poté je obnovit v produkčním clusteru. Kopírování a obnova stovek gigabajtů dat jen pro obnovu hrstky řádků je něco, co bychom rozhodně nazvali značnou režií. Abyste tomu zabránili, můžete použít logické zálohy - namísto ukládání fyzických dat tyto zálohy ukládají data v textovém formátu. To usnadňuje nalezení přesných dat, která byla odstraněna, a která pak mohou být obnovena přímo v produkčním clusteru. Aby to bylo ještě jednodušší, můžete také rozdělit takové logické zálohování na části a zálohovat každou tabulku do samostatného souboru. Pokud je vaše datová sada velká, bude rozumné rozdělit jeden velký textový soubor co nejvíce. Díky tomu bude záloha nekonzistentní, ale ve většině případů to není problém - pokud budete potřebovat obnovit celou datovou sadu do konzistentního stavu, použijete fyzickou zálohu, která je v tomto ohledu mnohem rychlejší. Pokud potřebujete obnovit pouze podmnožinu dat, jsou požadavky na konzistenci méně přísné.
Obnova bodu v čase
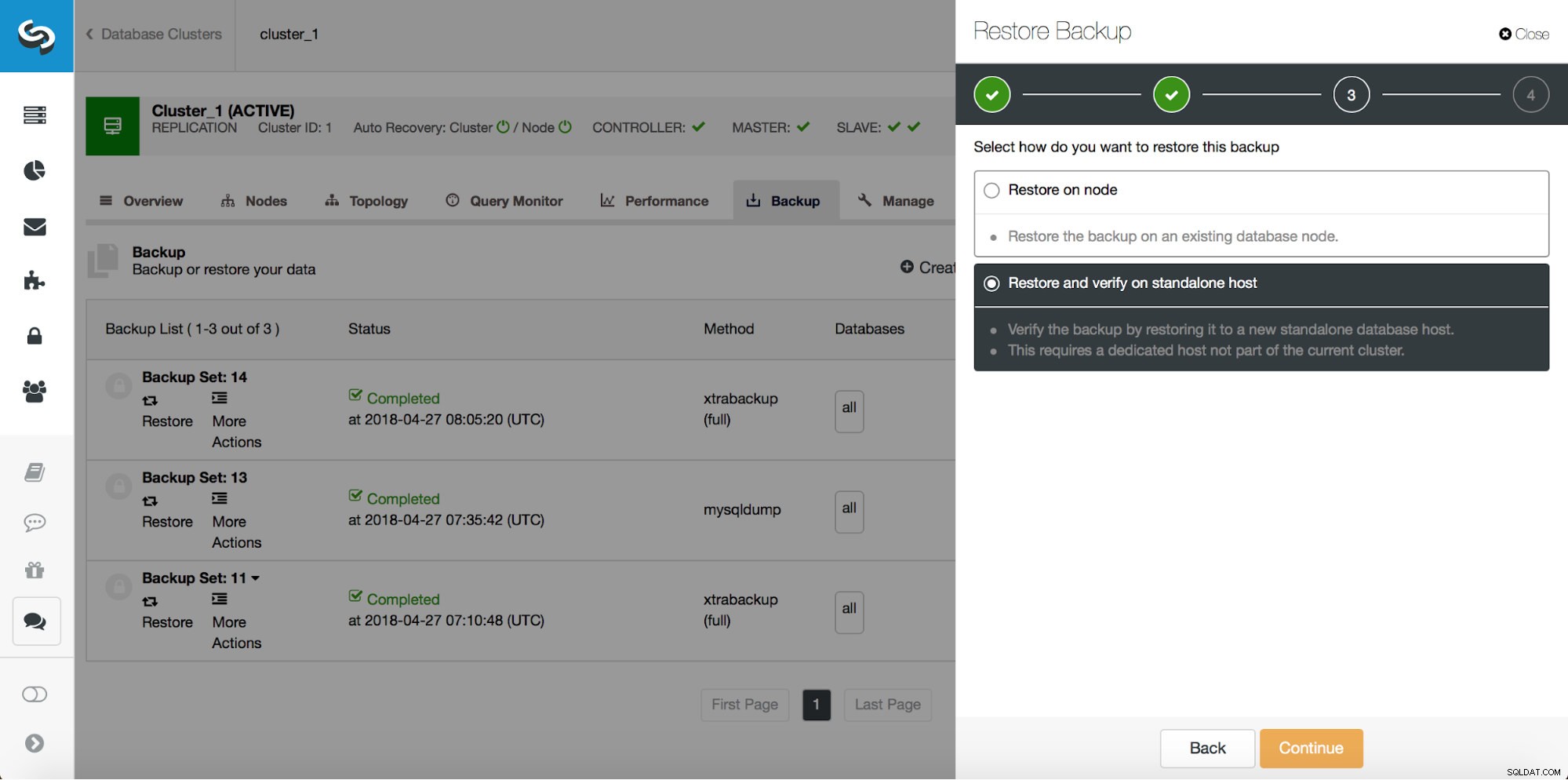
Zálohování je jen začátek – budete moci obnovit svá data do bodu, ve kterém byla záloha pořízena, ale s největší pravděpodobností byla data po této době odstraněna. Pouhým obnovením chybějících dat z poslední zálohy můžete ztratit všechna data, která byla po zálohování změněna. Abyste tomu zabránili, měli byste implementovat Point-In-Time Recovery. Pro MySQL to v zásadě znamená, že budete muset použít binární protokoly k přehrání všech změn, ke kterým došlo mezi okamžikem zálohování a událostí ztráty dat. Níže uvedený snímek obrazovky ukazuje, jak s tím může ClusterControl pomoci.
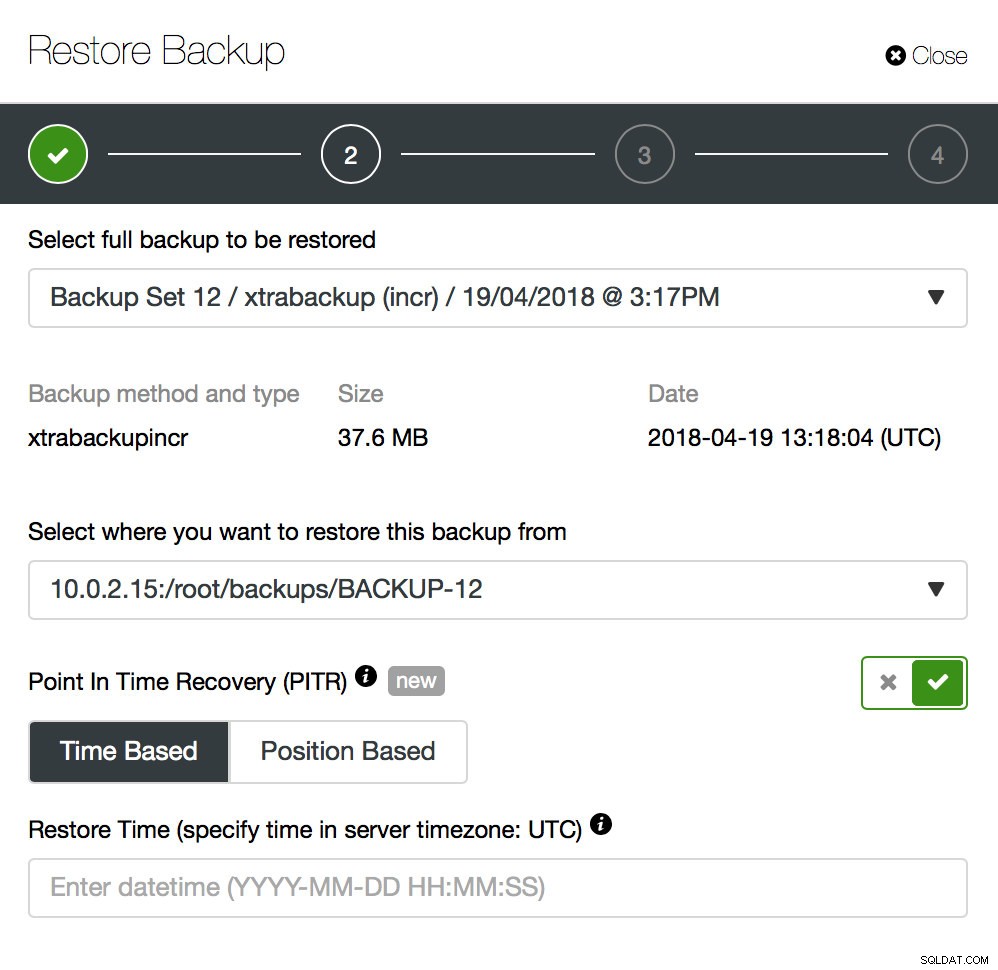
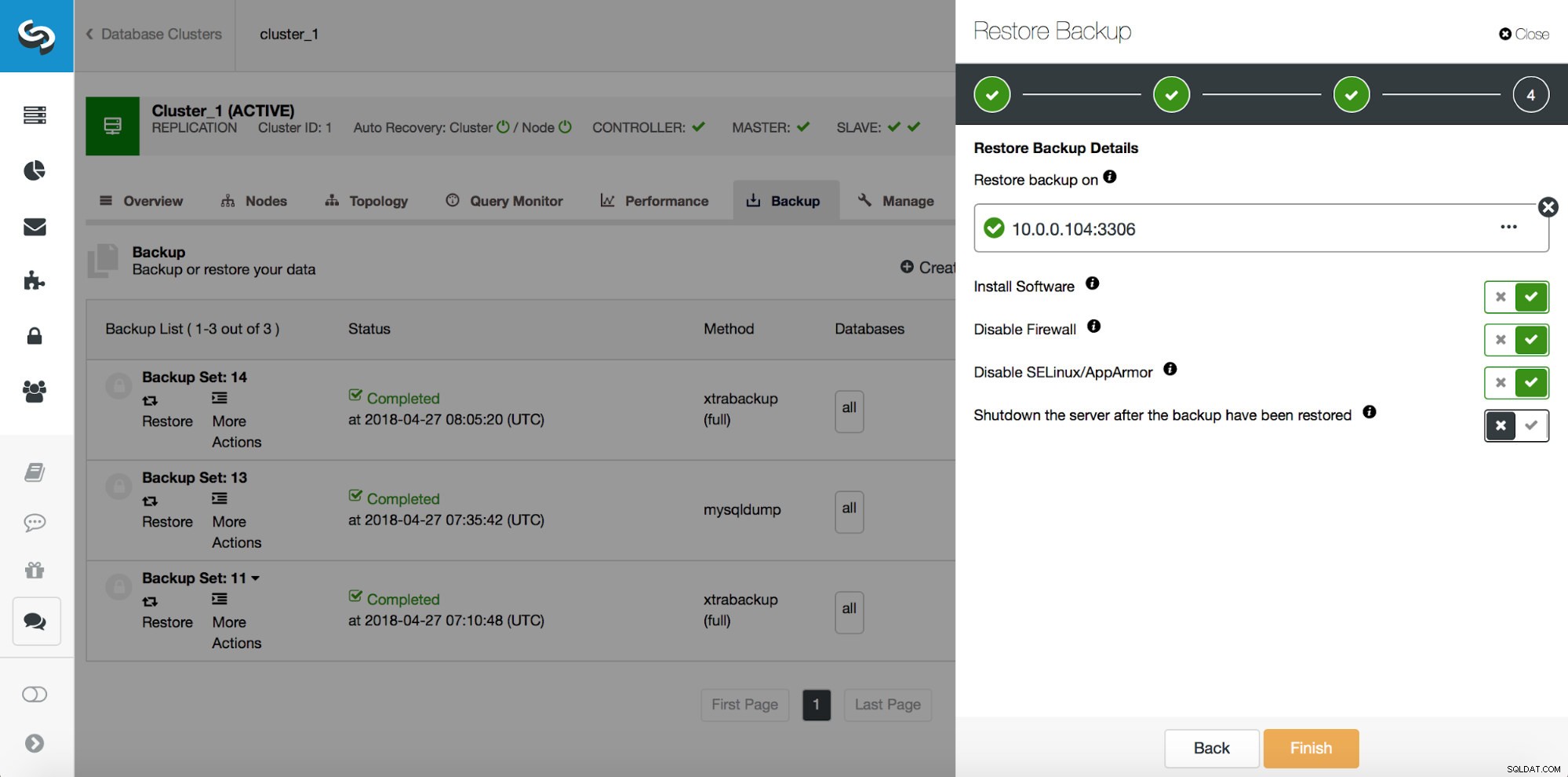
Co budete muset udělat, je obnovit tuto zálohu až do okamžiku těsně před ztrátou dat. Budete jej muset obnovit na samostatném hostiteli, abyste neprováděli změny v produkčním clusteru. Jakmile budete mít zálohu obnovenou, můžete se přihlásit k tomuto hostiteli, najít chybějící data, vypsat je a obnovit v produkčním clusteru.
Zpožděný Slave
Všechny metody, které jsme probrali výše, mají jeden společný problém – obnovení dat nějakou dobu trvá. Když obnovíte všechna data a poté se pokusíte vypsat pouze zajímavou část, může to trvat déle. Pokud máte logické zálohování a můžete rychle přejít k datům, která chcete obnovit, může to trvat méně času, ale v žádném případě to není rychlý úkol. Stále musíte najít několik řádků ve velkém textovém souboru. Čím je větší, tím je úkol komplikovanější - někdy samotná velikost souboru zpomaluje všechny akce. Jednou z metod, jak se těmto problémům vyhnout, je mít zpožděného otroka. Slave se obvykle snaží zůstat v aktuálním stavu s nadřízenou jednotkou, ale je také možné je nakonfigurovat tak, aby si od svého masteru udržovali odstup. Na níže uvedeném snímku obrazovky můžete vidět, jak použít ClusterControl k nasazení takového slave:
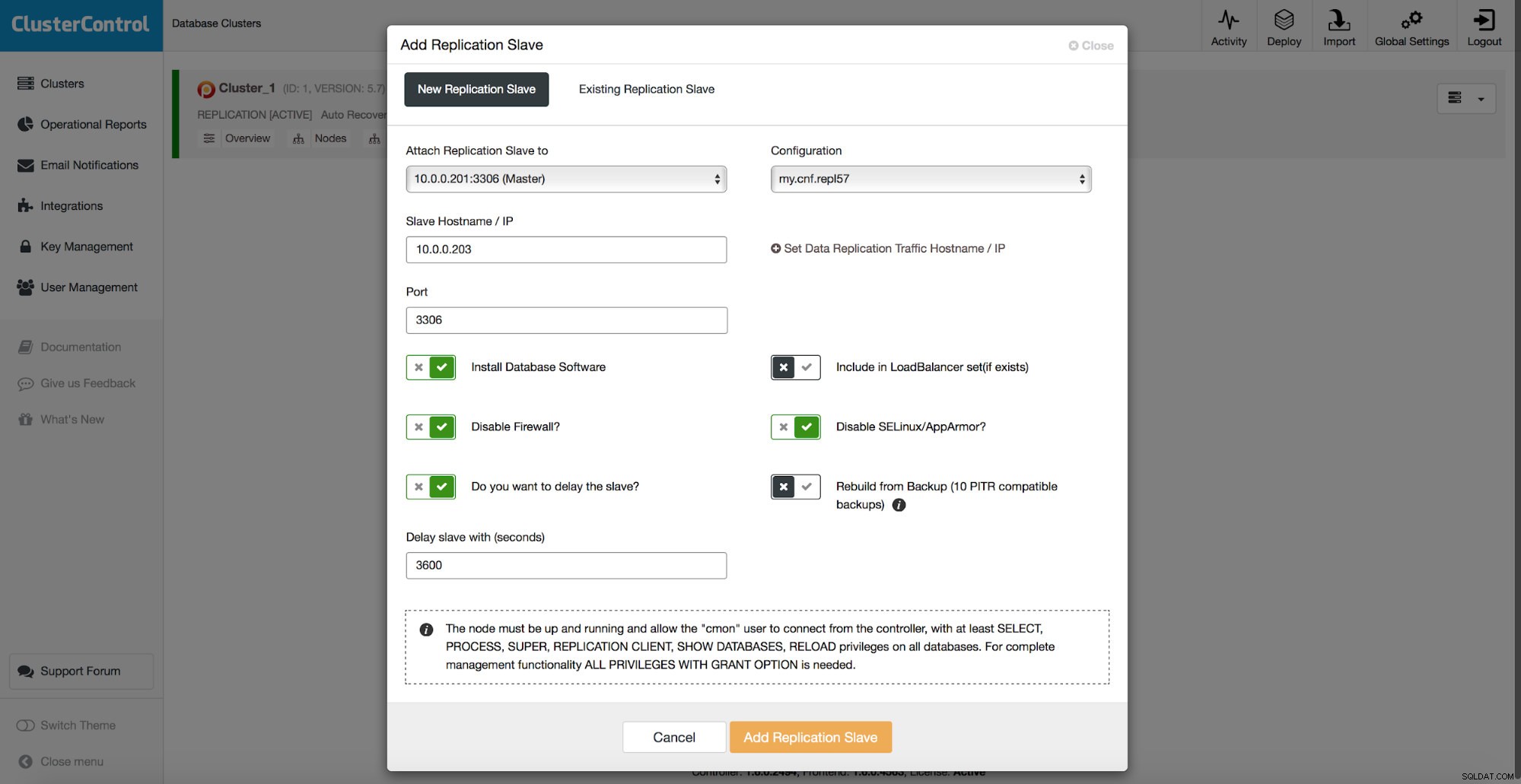
Stručně řečeno, máme zde možnost přidat replikační slave do nastavení databáze a nakonfigurovat jej tak, aby byl zpožděn. Na výše uvedeném snímku obrazovky bude slave zpožděn o 3600 sekund, což je jedna hodina. To vám umožní používat slave zařízení k obnově odstraněných dat až do jedné hodiny od smazání dat. Nebudete muset obnovovat zálohu, bude stačit spustit mysqldump nebo SELECT ... INTO OUTFILE pro chybějící data a získáte data k obnovení na vašem produkčním clusteru.
Obnovení dat
V této části si projdeme několik příkladů náhodného smazání dat a toho, jak je můžete obnovit. Projdeme si obnovu po úplné ztrátě dat, ukážeme si také, jak se zotavit z částečné ztráty dat při použití fyzických a logických záloh. Konečně vám ukážeme, jak obnovit omylem smazané řádky, pokud máte v nastavení zpožděný slave.
Úplná ztráta dat
Náhodné „rm -rf“ nebo „DROP SCHEMA myonlyschema;“ byl proveden a skončili jste bez vůbec žádných dat. Pokud jste náhodou odstranili i jiné soubory než z datového adresáře MySQL, možná budete muset znovu zprovoznit hostitele. Abychom to zjednodušili, budeme předpokládat, že byl ovlivněn pouze MySQL. Uvažujme dva případy, se zpožděným otrokem a bez jednoho.
Žádná zpožděná podřízená jednotka
V tomto případě jediná věc, kterou můžeme udělat, je obnovit poslední fyzickou zálohu. Vzhledem k tomu, že všechna naše data byla odstraněna, nemusíme se obávat aktivit, ke kterým došlo po ztrátě dat, protože bez dat neprobíhá žádná aktivita. Měli bychom se obávat činnosti, která se stala po provedení zálohy. To znamená, že musíme provést obnovu bodu v čase. Samozřejmě to bude trvat déle, než jen obnovit data ze zálohy. Pokud je rychlé spuštění databáze důležitější než obnovení všech dat, můžete také jednoduše obnovit zálohu a být s ní v pořádku.
Za prvé, pokud máte stále přístup k binárním protokolům na serveru, který chcete obnovit, můžete je použít pro PITR. Nejprve chceme převést příslušnou část binárních protokolů do textového souboru pro další zkoumání. Víme, že ke ztrátě dat došlo po 13:00:00. Nejprve se podívejme, který soubor binlog bychom měli prozkoumat:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016Jak je vidět, zajímá nás poslední binlogový soubor.
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.outPo dokončení se podívejme na obsah tohoto souboru. Ve vimu budeme hledat ‚drop schema‘. Zde je relevantní část souboru:
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
/*!*/;Jak vidíme, chceme obnovit až na pozici 320358785. Tato data můžeme předat do uživatelského rozhraní ClusterControl:
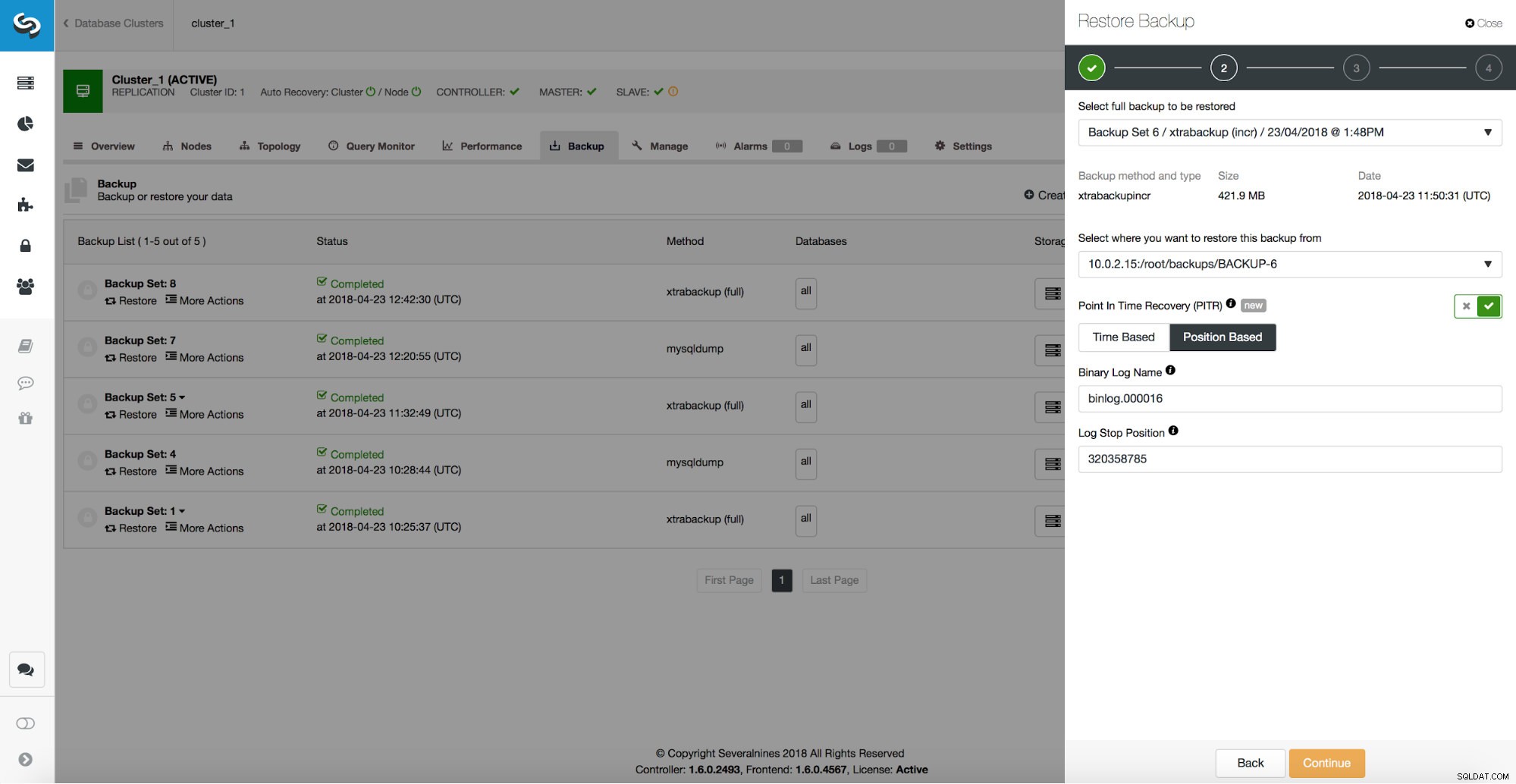
Zpožděný Slave
Pokud máme zpožděný slave a tento hostitel stačí na to, aby zvládl veškerý provoz, můžeme ho použít a povýšit na master. Nejprve se však musíme ujistit, že dohonil starého mistra až do bodu ztráty dat. K tomu zde použijeme nějaké CLI. Nejprve musíme zjistit, na jaké pozici došlo ke ztrátě dat. Poté slave zastavíme a necháme jej běžet až do události ztráty dat. Jak získat správnou pozici, jsme si ukázali v předchozí části – zkoumáním binárních logů. Můžeme použít buď tuto pozici (binlog.000016, pozice 320358785), nebo, pokud používáme vícevláknové slave, měli bychom použít GTID události ztráty dat (52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415) a replayqueries až 443415 že GTID.
Nejprve zastavíme slave a deaktivujeme zpoždění:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)Poté jej můžeme spustit až do dané pozice binárního logu.
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)Pokud bychom chtěli použít GTID, příkaz bude vypadat jinak:
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)Jakmile se replikace zastaví (to znamená, že byly provedeny všechny události, o které jsme požádali), měli bychom ověřit, že hostitel obsahuje chybějící data. Pokud ano, můžete jej povýšit na master a poté znovu vytvořit další hostitele pomocí nového masteru jako zdroje dat.
To není vždy nejlepší možnost. Vše závisí na tom, jak se váš slave zpožďuje – pokud je zpožděn o několik hodin, nemusí mít smysl čekat, až to dožene, zvláště pokud je ve vašem prostředí velký provoz zápisu. V takovém případě je s největší pravděpodobností rychlejší znovu sestavit hostitele pomocí fyzické zálohy. Na druhou stranu, pokud máte poměrně malý objem provozu, mohl by to být pěkný způsob, jak problém skutečně rychle vyřešit, propagovat nového hlavního a pokračovat v poskytování provozu, zatímco zbytek uzlů se přestavuje na pozadí. .
Částečná ztráta dat – fyzické zálohování
V případě částečné ztráty dat mohou být fyzické zálohy neefektivní, ale jelikož se jedná o nejběžnější typ zálohy, je velmi důležité vědět, jak je použít pro částečné obnovení. Prvním krokem bude vždy obnovení zálohy až do okamžiku před ztrátou dat. Je také velmi důležité jej obnovit na samostatném hostiteli. ClusterControl používá pro fyzické zálohování xtrabackup, takže si ukážeme, jak jej používat. Předpokládejme, že jsme provedli následující nesprávný dotaz:
DELETE FROM sbtest1 WHERE id < 23146;
Chtěli jsme odstranit pouze jeden řádek (‘=‘ v klauzuli WHERE), místo toho jsme jich smazali spoustu (
Nyní se podíváme na výstupní soubor a uvidíme, co tam najdeme. Používáme replikaci založenou na řádcích, takže neuvidíme přesné SQL, které bylo provedeno. Místo toho (pokud budeme pro mysqlbinlog používat příznak --verbose) uvidíme události jako níže:
Jak je vidět, MySQL identifikuje řádky k odstranění pomocí velmi přesné podmínky WHERE. Záhadné znaky v komentáři čitelném pro člověka, „@1“, „@2“, znamenají „první sloupec“, „druhý sloupec“. Víme, že první sloupec je ‚id‘, což je něco, co nás zajímá. Potřebujeme najít velkou událost DELETE v tabulce ‚sbtest1‘. Komentáře, které budou následovat, by měly uvádět id 1, pak id 2, 3 a tak dále – vše až do id 23145. Vše by mělo být provedeno v jediné transakci (jedna událost v binárním protokolu). Po analýze výstupu pomocí „méně“ jsme zjistili:
Událost, ke které jsou tyto komentáře připojeny, začala v:
Chceme tedy obnovit zálohu až do předchozího potvrzení na pozici 29600687. Udělejme to nyní. K tomu použijeme externí server. Obnovíme zálohu až do této pozice a obnovíme server v provozu, abychom mohli později extrahovat chybějící data.
Po dokončení obnovy se ujistěte, že byla obnovena naše data:
Vypadá dobře. Nyní můžeme tato data extrahovat do souboru, který načteme zpět na master.
Něco není v pořádku – je to proto, že server je nakonfigurován tak, aby mohl zapisovat soubory pouze do konkrétního umístění – vše je o bezpečnosti, nechceme uživatelům umožnit ukládat obsah kamkoli se jim zlíbí. Pojďme se podívat, kam můžeme uložit náš soubor:
Dobře, zkusíme to ještě jednou:
Teď to vypadá mnohem lépe. Zkopírujeme data do hlavního serveru:
Nyní je čas načíst chybějící řádky do hlavního serveru a otestovat, zda uspěl:
To je vše, obnovili jsme naše chybějící data.
V předchozí části jsme obnovili ztracená data pomocí fyzické zálohy a externího serveru. Co kdybychom měli vytvořenou logickou zálohu? Podívejme se. Nejprve si ověřte, že máme logickou zálohu:
Ano, je to tam. Nyní je čas jej dekomprimovat.
Když se do něj podíváte, uvidíte, že data jsou uložena ve formátu INSERT s více hodnotami. Například:
Vše, co nyní musíme udělat, je přesně určit, kde se nachází naše tabulka a poté, kde jsou uloženy řádky, které nás zajímají. Nejprve, když známe vzory mysqldump (vypustit tabulku, vytvořit novou, zakázat indexy, vložit data), pojďme zjistit, který řádek obsahuje příkaz CREATE TABLE pro tabulku „sbtest1“:
Nyní pomocí metody pokusu a omylu musíme zjistit, kde hledat naše řádky. Ukážeme vám poslední příkaz, se kterým jsme přišli. Celý trik je zkusit vytisknout jiný rozsah řádků pomocí sed a pak zkontrolovat, zda nejnovější řádek obsahuje řádky blízké, ale pozdější než to, co hledáme. V příkazu níže hledáme řádky mezi 971 (CREATE TABLE) a 993. Také požádáme sed, aby skončil, jakmile dosáhne řádku 994, protože zbytek souboru nás nezajímá:
Výstup vypadá následovně:
To znamená, že náš rozsah řádků (až po řádek s ID 23145) je blízko. Dále je to vše o ručním čištění souboru. Chceme, aby to začínalo prvním řádkem, který potřebujeme obnovit:
A skončit s posledním řádkem k obnovení:
Museli jsme oříznout některá nepotřebná data (jedná se o víceřádkové vkládání), ale po tom všem máme soubor, který můžeme načíst zpět na master.
Konečně poslední kontrola:
Vše je v pořádku, data byla obnovena.
V tomto případě neprojdeme celým procesem. Již jsme popsali, jak identifikovat pozici události ztráty dat v binárních protokolech. Také jsme popsali, jak zastavit zpožděnou podřízenou jednotku a spustit replikaci znovu, až do okamžiku před událostí ztráty dat. Také jsme vysvětlili, jak používat SELECT INTO OUTFILE a LOAD DATA INFILE k exportu dat z externího serveru a jejich načtení na master. To je vše, co potřebujete. Dokud jsou data stále na zpožděné podřízené jednotce, musíte ji zastavit. Poté musíte najít pozici před událostí ztráty dat, spustit slave až do tohoto bodu a jakmile to uděláte, použijte zpožděnou slave k extrahování dat, která byla smazána, zkopírujte soubor do masteru a načtěte jej pro obnovení dat. .
Obnova ztracených dat není legrace, ale pokud budete postupovat podle kroků, kterými jsme prošli v tomto blogu, budete mít dobrou šanci obnovit to, co jste ztratili.mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.out### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826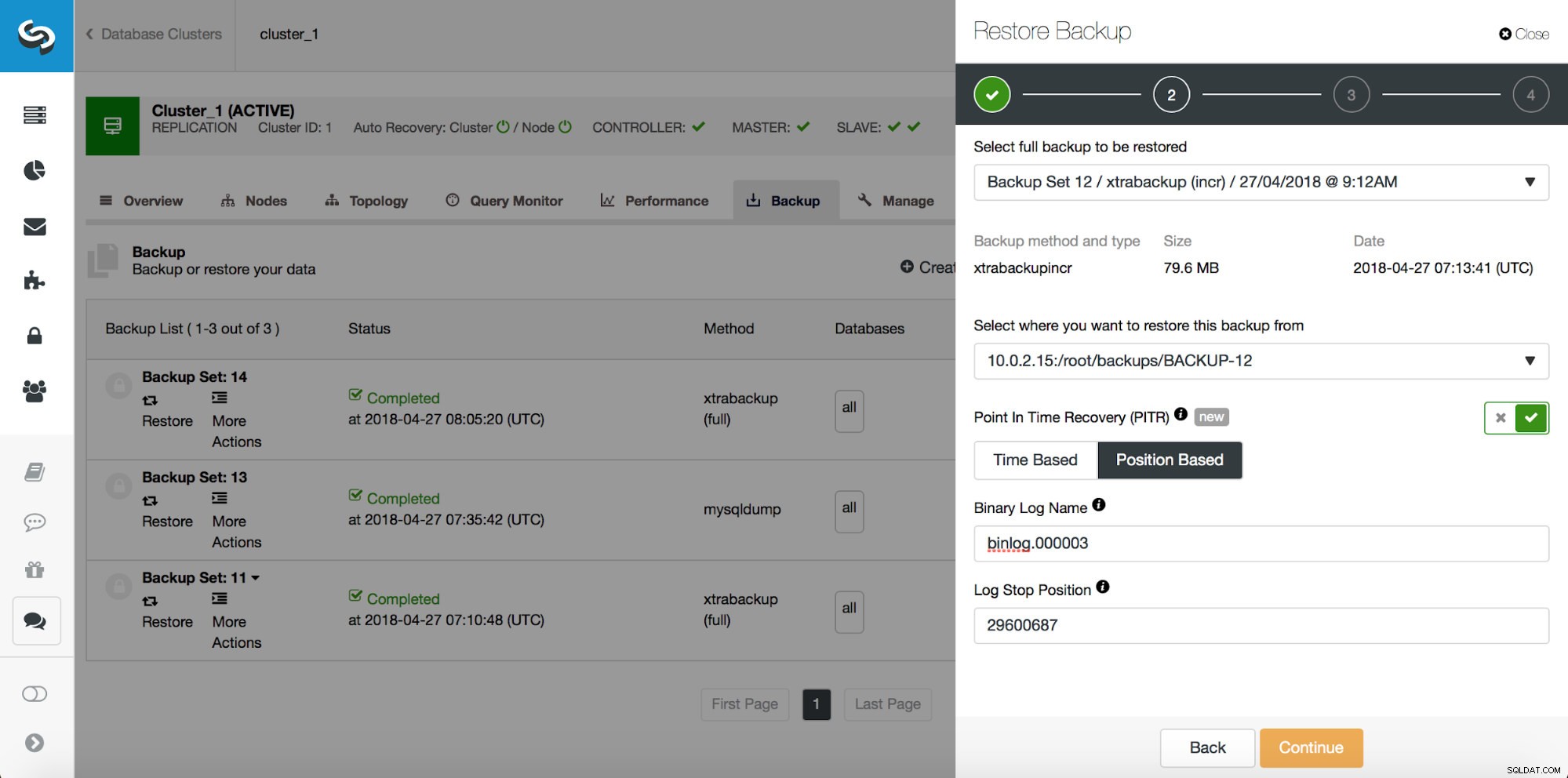
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementmysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Částečná ztráta dat – logické zálohování
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzexample@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sqlINSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | lessINSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Částečná ztráta dat, zpožděná podřízená jednotka
Závěr