V roce 2014 jsem zde zahájil sérii blogových příspěvků, abych hovořil o konkrétních typech čekání a o tom, co dělají a co neznamenají. To mi vnuklo nápad vytvořit knihovny čekání a zámků, které spravuji (více o nich později).
Pokud to čtete a přemýšlíte „o čem to mluví?“ pak je tento příspěvek pro vás. Představím vám statistiky čekání a vysvětlím, jak kritické jsou pro řešení problémů s výkonem zátěže na serveru SQL Server.
Plánování
Spuštění interního kódu SQL Serveru se provádí pomocí mechanismu zvaného vlákna . Každé vlákno může spouštět kód SQL Server a více vláken může být koordinováno společně, když dotaz běží paralelně. Tato vlákna se vytvářejí při spuštění SQL Serveru v závislosti na počtu procesorových jader dostupných pro SQL Server k použití.
Vlákna jsou umístěna v plánovači při spuštění dotazu s jedním plánovačem na jádro procesoru a neopouštějte tento plánovač, dokud dotaz neskončí. Plánovač má tři základní ‚části‘:
- procesor , který má právě jedno vlákno aktuálně spouštějící kód.
- seznam číšníků , který má všechna vlákna, která jsou v podstatě zaseknutá a čekají, až bude k dispozici konkrétní zdroj.
- Spustitelná fronta , který má všechna vlákna, která jsou schopna spustit, ale čekají, až se dostanou do procesoru.
Vlákna přecházejí ze stavu 1 do 2 na 3 do 1, stále dokola, dokud dotaz neskončí.
Čeká
Z našeho pohledu je nejzajímavější část plánování, když vlákno musí čekat na zdroj, než může pokračovat. Některé příklady jsou:
- Vlákno potřebuje číst stránku a stránka není v paměti, takže vlákno zahájí asynchronní fyzický vstup/výstup a poté musí čekat mimo procesor, dokud se vstup/výstup nedokončí.
- Vlákno potřebuje získat zámek sdílení na řádku, aby jej mohlo číst, ale jiné vlákno již má konfliktní výhradní zámek, zatímco aktualizuje řádek.
Když vlákno narazí na potřebu zdroje, který nemůže získat, nemá jinou možnost, než se zastavit a počkat, až bude zdroj dostupný (mechanismus, jakým je vlákno informováno o dostupnosti zdroje, je nad rámec tohoto článku). Když k tomu dojde, SQL Server si zaznamená, proč vlákno muselo čekat, a tomu se říká typ čekání . Některé příklady jsou:
- Když vlákno čeká na načtení stránky do paměti, aby ji bylo možné přečíst, typ čekání je PAGEIOLATCH_SH (pokud vlákno čeká na stránku, kterou změní, typ čekání je PAGEIOLATCH_EX ).
- Když vlákno čeká na zámek sdílení na řádku, typ čekání je LCK_M_S (lock-mode-share)
SQL Server také sleduje, jak dlouho musí vlákno čekat. Toto se nazývá doba čekání na zdroj a obvykle se nazývá doba čekání .
Statistika čekání
Celková sada metrik, kolik vláken čekalo na které zdroje a jak dlouho v průměru, se nazývá statistika čekání . Tyto informace jsou mimořádně užitečné pro odstraňování problémů s výkonem pracovní zátěže, protože snadno zjistíte, kde mohou být úzká hrdla výkonu.
Základní myšlenkou je, že SQL Server má informace o tom, proč se vlákna musí zastavit a čekat a na co čekají. Takže místo abyste museli hádat, kde začít s odstraňováním problémů, může vás pečlivá analýza statistik čekání obvykle nasměrovat směrem, kterým se vydat.
Pokud je například většina čekání na serveru PAGEIOLATCH_SH , může to naznačovat, že je na serveru tlak paměti nebo že existují dotazy provádějící prohledávání velkých tabulek namísto použití indexů bez klastrů, nebo že existuje problém se základním I/O subsystémem nebo z mnoha jiných důvodů.
Existuje velké množství typů čekání, ale většina z nich se neobjevuje příliš často, takže existuje základní sada, kterou na svých serverech uvidíte znovu a znovu. Pochopení toho, co to znamená a jak je prozkoumat, je zásadní, abyste nepodlehli tomu, co nazývám „laděním výkonu po kolena“, a neztráceli čas a úsilí snahou vyřešit problém, který ve skutečnosti problémem není. Napsal jsem sem sérii blogových příspěvků, které se tam zabývají podrobnostmi, a Aaron Bertrand také napsal souhrnný příspěvek 10 nejlepších statistik čekání v loňském roce.
Sledování čekání
Existuje několik způsobů, jak můžete sledovat čekání. Nejjednodušší je podívat se na to, co čeká na serveru právě teď, pomocí skriptu, který zkoumá sys.dm_os_waiting_tasks DMV. Zde najdete skript, který to provede, a který má automaticky generované adresy URL do knihovny čekání.
Dalším způsobem je podívat se na souhrnné statistiky čekání pro celý server pomocí skriptu, který zkoumá sys.dm_os_wait_stats DMV. Zde najdete skript, který to provede, a který má automaticky generované adresy URL do knihovny čekání. S touto metodou však musíte být opatrní, protože zobrazí všechna čekání, ke kterým došlo od spuštění serveru. Lepším způsobem je sledovat čekání v malých intervalech, řekněme půl hodiny, a skript k tomu je zde.
Statistiky čekání můžete získat také pomocí doplňku Server Reports do nového nástroje Azure Data Studio a pomocí Query Store od SQL Server 2017 a novější.
Pamatujte, že po shromáždění metrik musíte stále rozumět tomu, co typy čekání znamenají.
Zdroje čekání
Abych s tím pomohl, a protože Microsoft nemá dokumentaci o tom, jak interpretovat statistiky čekání, v roce 2016 jsem vydal knihovnu typů čekání s podrobnostmi o stovkách běžných typů čekání a o tom, jak je řešit. Do knihovny se můžete dostat na https://www.SQLskills.com/help/waits. A pak v roce 2017 SentryOne vytvořil automatizovaný systém, který poskytuje infografiku pro každou stránku v knihovně, kterou můžete rychle použít, abyste zjistili, zda typ čekání, který vás zajímá, je opravdu běžný nebo ne (podrobnosti viz tento příspěvek) . Níže je uveden příklad infografiky pro PAGEIOLATCH_SH typ čekání:
Na vodorovné ose je škála (přepínatelná mezi lineární a logaritmickou) toho, jaké procento instancí (sledovaných na dálku pomocí SentryOne) zažilo toto čekání za předchozí kalendářní měsíc, a na svislé ose je procento času, po který tyto instance zažily toto čekání. wait ve skutečnosti mělo vlákno čekající na tento typ čekání.
Dalším zdrojem, který vám pomůže pochopit čekání, je online školicí kurz, který jsem nahrál pro Pluralsight – viz zde.
Přinejmenším byste si měli přečíst různé blogové příspěvky v sekcích Statistika čekání a Sledování čekání výše.
Sledování čekání pomocí SentryOne Tools
SQL Sentry za vás v průběhu času automaticky sleduje čekání na úrovni instance, takže nemusíte chytat vysoké čekání „v akci“. Někdo si včera odpoledne stěžoval na pomalý systém nebo na zprávu, která minulé úterý vypršela? Žádný problém. Můžete se ponořit do všech čekání pro jakýkoli bod v čase nebo v určitém rozsahu a porovnat je s různými jinými metrikami výkonu shromážděnými v té době – ať už jde o další trendy na řídicím panelu, jako je zálohování nebo databázová I/O aktivita, přeskakování na všechny Nejlepší SQL příkazy, které byly spuštěny ve stejném okně, zkoumaly dlouhotrvající blokování nebo používají základní linie k porovnání profilu čekání s jinými obdobími.
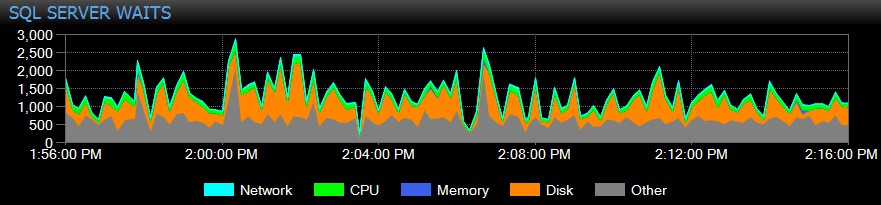
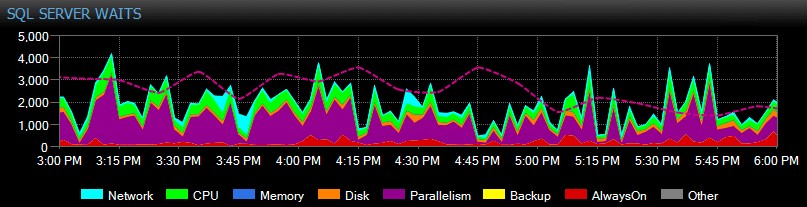
Můžete dokonce přizpůsobit čekání, která jsou nebo nejsou shromažďována, měnit kategorie, které jsou prezentovány vizuálně, a vytvářet inteligentní upozornění a/nebo reakce na konkrétní scénáře čekání. Mnoho našich zákazníků používá SQL Sentry k tomu, aby se soustředili na problémy se skutečným výkonem související s čekáním, protože jim to umožňuje ignorovat spoustu hluku, který je jen běžnou aktivitou vláken SQL Serveru.
Shrnutí
Jak můžete vidět z výše uvedených informací, čekání vždy probíhá na serveru SQL Server, protože tak funguje plánování vláken a vícevláknové systémy. Jsou jedním z nejvýkonnějších nástrojů v sadě nástrojů pro odstraňování problémů, takže pokud je ještě nepoužíváte, je čas začít. Křivka učení je krátká a strmá – jakmile několikrát spustíte různé dotazy a nástroje, rychle se v tom zorientujete a pak je to případ, kdy si prostudujete průvodce po dobu, na kterou se díváte. určení, zda jsou problémem nebo nikoli.
Hodně štěstí při odstraňování problémů!