Úvod
V SQL Server 2012 byla seskupená (vektorová) agregace schopna používat paralelní spouštění v dávkovém režimu, ale pouze pro částečnou agregaci (na vlákno). Přidružený globální agregát vždy běžel v režimu řádků po přerozdělovacích tocích výměna.
SQL Server 2014 přidal možnost provádět seskupenou agregaci v paralelním dávkovém režimu v rámci jediné Hash Match Aggregate operátor. To odstranilo zbytečné zpracování v režimu řádků a odstranilo potřebu výměny.
SQL Server 2016 zavedl sériové zpracování v dávkovém režimu a agregované posunutí dolů . Po úspěšném rozbalení se provede agregace v rámci Prohledávání úložiště sloupců samotného operátora, který může pracovat přímo s komprimovanými daty a využívat výhody instrukcí CPU SIMD.
Zlepšení výkonu možná s agregovaným snížením mohou být velmi podstatné. Dokumentace uvádí některé podmínky potřebné k dosažení rozšíření, ale existují případy, kdy nedostatek „místně agregovaných řádků“ nelze plně vysvětlit pouze na základě těchto podrobností.
Tento článek popisuje další faktory, které ovlivňují agregované rozšíření dolů pro GROUP BY pouze dotazy . Skalární agregační rozšíření (agregace bez GROUP BY klauzule), rozšíření filtru a posunutí výrazu dolů mohou být popsány v budoucím příspěvku.
Úložiště Columnstore
První věc, kterou je třeba říci, je, že agregované rozšíření se vztahuje pouze na komprimovaná data, takže řádky v úložišti delta nejsou způsobilé. Kromě toho může pushdown záviset na typu použité komprese. Abychom tomu porozuměli, je nutné si nejprve prohlédnout, jak úložiště columnstore funguje na vysoké úrovni:
komprimovaná skupina řádků obsahuje segment sloupce pro každý sloupec. Nezpracované hodnoty sloupců jsou zakódované ve 4bajtovém nebo 8bajtovém celém čísle pomocí hodnoty nebo slovník kódování.
Kódování hodnoty může snížit počet bitů potřebných pro ukládání převodem nezpracovaných hodnot pomocí základního offsetu a modifikátoru velikosti. Například hodnoty {1100, 1200, 1300} lze uložit jako (0, 1, 2) tak, že nejprve změníte měřítko faktorem 0,01, abyste získali {11, 12, 13}, a poté přepočítali na 11, abyste získali {0, 1, 2}.
Kódování slovníku se používá, pokud existují duplicitní hodnoty. Lze jej použít s nečíselnými údaji. Každá jedinečná hodnota je uložena ve slovníku a je jí přiřazeno celé číslo. Data segmentu pak odkazují na čísla ID ve slovníku namísto původních hodnot.
Po zakódování mohou být data segmentu dále komprimována pomocí kódování délky běhu (RLE) a bitového sbalení:
RLE nahradí opakující se prvky daty a počtem opakování, například {1, 1, 1, 1, 1, 2, 2, 2} lze nahradit {5×1, 3×2}. Úspora místa RLE se zvyšuje s délkou opakujících se běhů. Krátké běhy mohou být kontraproduktivní.
Bit-packing ukládá binární podobu dat v co nejužším společném okně. Například čísla {7, 9, 15} jsou uložena v binárních (jednobajtových pro mezeru) celých číslech jako {00000111, 00001001, 00001111}. Zabalením těchto bitů do pevného čtyřbitového okna získáme stream {011110011111}. Vědět, že existuje pevná velikost okna, znamená, že není potřeba oddělovač.
Kódování a komprese jsou samostatné kroky, takže RLE a bit-packing se aplikují na výsledek kódování hodnot nebo slovníkového kódování nezpracovaných dat. Data ve stejném segmentu sloupce mohou mít navíc směs RLE a bit-packing komprese. Data komprimovaná RLE se nazývají čistá a bitová komprimovaná data se nazývají nečistá . Segment sloupce může obsahovat čistá i nečistá data.
Úspora místa, které lze dosáhnout pomocí kódování a komprese, může záviset na objednávce. Všechny segmenty sloupců ve skupině řádků musí být implicitně seřazeny stejným způsobem, aby SQL Server mohl efektivně rekonstruovat úplné řádky ze segmentů sloupců. Vědět, že řádek 123 je uložen na stejné pozici (123) v každém segmentu sloupce znamená, že číslo řádku nemusí být uloženo.
Nevýhodou tohoto uspořádání je společné pořadí řazení musí být vybrán pro všechny segmenty sloupců ve skupině řádků. Konkrétní uspořádání může velmi dobře vyhovovat jednomu sloupci, ale promarnit významné příležitosti v jiných sloupcích. To je nejzřetelněji případ komprese RLE. SQL Server používá technologii Vertipaq k určení vhodného způsobu řazení sloupců v každé skupině řádků, aby bylo dosaženo dobrého celkového výsledku komprese.
SQL Server aktuálně používá pouze RLE v segmentu sloupce, pokud je minimum 64 souvislé opakující se hodnoty. Zbývající hodnoty v segmentu jsou bitově sbaleny. Jak bylo uvedeno, to, zda se opakující se hodnoty zobrazí v segmentu sloupců jako souvislé, závisí na pořadí zvoleném pro skupinu řádků.
SQL Server podporuje specializované SIMD rozbalení bitů pro šířky bitů od 1 do 10 včetně, 12 a 21 bitů. SQL Server může také používat standardní celočíselné velikosti, např. 16, 32 a 64 bitů s bitovým balením. Tato čísla jsou vybrána, protože krásně sedí v 64bitové jednotce. Například jedna jednotka může obsahovat tři 21bitové podjednotky nebo 5 12bitových podjednotek. SQL Server není při sbalování bitů překročí 64bitovou hranici.
SIMD používá 256bitové registry, když procesor podporuje instrukce AVX2, a 128bitové registry, když jsou dostupné instrukce SSE4.2. V opačném případě lze použít rozbalení bez SIMD.
Skupinové agregované podmínky rozšíření
Většina plánů s Hash Match Aggregate operátor přímo nad Columnstore Scan operátor bude potenciálně způsobilý pro seskupený souhrnný pokles v souladu se všeobecnými podmínkami uvedenými v dokumentaci.
Někdy lze také přidat další filtry a výrazy, aniž by bylo zabráněno seskupení agregace dolů. Obecným pravidlem je, že filtr nebo výraz musí také umožňovat posunutí dolů (ačkoli kompatibilní výrazy se mohou stále zobrazovat v samostatném Výpočetním skaláru ). Jak bylo uvedeno v úvodu, tyto aspekty mohou být podrobně popsány v samostatných článcích.
Aktuálně v prováděcích plánech není nic, co by naznačovalo, zda byl konkrétní agregát považován za obecně kompatibilní se seskupeným agregovaným snížením nebo ne. Přesto, když plán obecně splňuje podmínky pro seskupené agregované posunutí dolů jsou k dispozici cesty kódu s posunutím dolů (rychlé) i bez posunutí dolů (pomalé).
Každá výstupní dávka skenování (až 900 řádků) provede rozhodnutí za běhu mezi rychlými a pomalými cestami kódu. Tato flexibilita umožňuje co největšímu počtu dávek těžit z pushdown. V nejhorším případě žádné dávky nepoužijí rychlou cestu za běhu, a to navzdory „obecně kompatibilnímu“ plánu.
Plán provádění zobrazuje výsledek rychlého zpracování rozšíření dolů jako ‚místně agregované řádky‘ bez odpovídajícího výstupu řádků ze skenování. Dávky s pomalou cestou se jako obvykle zobrazují jako výstupní řádky ze skenování columnstore, přičemž agregaci provádí samostatný operátor namísto skenování.
Jediná seskupená kombinace agregace a skenování může poslat některé dávky rychlou cestou a některé pomalou cestou, takže je dokonale možné vidět některé, ale ne všechny řádky lokálně agregované. Když je seskupený souhrnný zásobník úspěšný, každá výstupní dávka ze skenování obsahuje seskupovací klíče a částečný agregát představující řádky, které přispívají.
Podrobné kontroly
Existuje řada kontrol za běhu, aby se zjistilo, zda lze použít zpracování se zásobníkem. Mezi lehce zdokumentované kontroly patří:
- Nesmí existovat možnost agregovaného přetečení .
- Jakékoli nečisté (bit-packed) klíče seskupení nesmí být širší než 10 bitů . Čisté (zakódované RLE) seskupovací klíče jsou považovány za klávesy s nečistou šířkou nula, takže obvykle představují jen málo překážek.
- Zpracování odeslání dolů musí být i nadále považováno za smysluplné pomocí ‚míry přínosu‘ aktualizovaného na konci každé výstupní dávky.
Možnost přetečení agregátů se konzervativně posuzuje pro každou dávku na základě typu agregace, datového typu výsledku, aktuálních dílčích hodnot agregace a informací o vstupních datech. Například SQL Server zná minimální a maximální hodnoty z metadat segmentu, jak jsou vystaveny v DMV sys.column_store_segments . Tam, kde hrozí přetečení, použije dávka pomalé zpracování cesty. Toto je většinou riziko pro SUM agregát.
Omezení šířky nečistého seskupovacího klíče stojí za to zdůraznit. Platí pouze pro sloupce v GROUP BY klauzule, které jsou skutečně použity v prováděcím plánu jako základ pro seskupování. Tyto sady nejsou vždy úplně stejné, protože optimalizátor má svobodu odstraňovat nadbytečné seskupovací sloupce nebo jinak přepisovat agregáty, pokud je zaručeno, že konečné výsledky dotazu budou odpovídat původní specifikaci dotazu. Tam, kde existuje rozdíl, záleží na seskupení sloupců zobrazených v prováděcím plánu.
Větší problém je vědět, zda je některý ze seskupovacích sloupců uložen pomocí bit-packingu, a pokud ano, jaká šířka byla použita. Bylo by také užitečné vědět, kolik hodnot bylo zakódováno pomocí RLE. Tyto informace mohou být v column_store_segments DMV, ale to už dnes neplatí. Pokud vím, v současné době neexistuje žádný zdokumentovaný způsob, jak získat informace o sbalení bitů a RLE z metadat. To nás nechává hledat nezdokumentované alternativy.
Vyhledání informací o RLE a bitovém sbalení
Nezdokumentovaný DBCC CSINDEX nám může poskytnout informace, které potřebujeme. Aby tento příkaz vytvořil výstup na kartě Zprávy SSMS, musí být příznak trasování 3604 zapnutý. Vzhledem k informacím o segmentu sloupce, který nás zajímá, tento příkaz vrátí:
- Atributy segmentů (podobně jako
column_store_segments) - Informace RLE
- Záložky do dat RLE
- Informace o bitpacku
Vzhledem k tomu, že není zdokumentováno, existuje několik zvláštností (například nutnost přidat jeden k ID sloupců pro clustered columnstore, ale ne nonclustered columnstore) a dokonce i několik menších chyb. Neměli byste jej používat na nic jiného než na osobní testovací systém. Doufejme, že jednoho dne bude místo toho poskytnuta podporovaná metoda přístupu k těmto datům.
Příklady
Nejlepší způsob, jak zobrazit DBCC CSINDEX a demonstrovat body, které byly dosud v tomto textu uvedeny, je propracovat několik příkladů. Následující skripty předpokládají, že existuje tabulka nazvaná dbo.Numbers v aktuální databázi, která obsahuje celá čísla od 1 do alespoň 16 384. Zde je skript pro vytvoření mé standardní verze této tabulky s deseti miliony celých čísel:
IF OBJECT_ID(N'dbo.Numbers', N'U') NENÍ NULLBEGIN DROP TABLE dbo.Numbers;END;GOWITH Deset(N) AS ( SELECT 1 UNION ALL VYBERTE 1 UNION ALL VYBERTE 1 UNION ALL VYBERTE 1 UNION ALL VYBERTE 1 UNION ALL VYBERTE 1 UNION ALL VYBERTE 1 UNION ALL VYBERTE 1 UNION ALL VYBERTE 1 UNION ALL VYBERTE 1) VYBERTE n =IDENTITY(int, 1, 1)INTO dbo.Čísla OD Deseti AS T10CROSS JOIN Deseti AS T100C T1000Cross se připojte deset, když se T10000Cross připojte deset, protože T100000Cross se připojí deset, když se T1000000Cross připojí deset jako T10000000Order od n -ofsetu 0 řádků načtení prvních 10 * 1000 * 1000 řádků pouze proption (MaxDop 1); brankátor Tabulka DBO.numbersdd omezení [PK DBO.Umbers N] KEY CLUSTERED (n)WITH( SORT_IN_TEMPDB =ON, MAXDOP =1, FILLFACTOR =100);
Všechny příklady používají stejnou základní testovací tabulku:První sloupec c1 obsahuje jedinečné číslo pro každý řádek. Druhý sloupec c2 je vyplněno určitým počtem duplikátů pro každou z malého počtu odlišných hodnot.
Clusterovaný index columnstore se vytvoří po naplnění dat, takže všechna testovací data skončí v jedné komprimované skupině řádků (žádné úložiště delta). Je sestaven tak, že nahrazuje seskupený index b-stromu ve sloupci c2 povzbudit algoritmus VertiPaq, aby zvážil užitečnost řazení v tomto sloupci hned na začátku. Toto je základní nastavení testu:
POUŽÍVEJTE pískoviště;POKUD EXISTUJE TABULKA GODROP dbo.Test;GOCREATE TABLE dbo.Test( c1 celé číslo NOT NULL, c2 celé číslo NOT NULL);GODECLARE @values integer =512, @dupes integer =63; INSERT dbo.Test (c1, c2)SELECT N.n, N.n % @valuesFROM dbo.Numbers AS NWHERE N.n BETWEEN 1 AND @values * @dupes;GO-- Povzbuďte VertiPaqCREATE CLUSTERED INDEX CCSI ON dbo.GOCECLUNSOL CREATE2); INDEX CCSI ON dbo.TestWITH (MAXDOP =1, DROP_EXISTING =ON);
Dvě proměnné jsou pro počet různých hodnot, které se mají vložit do sloupce c2 a počet duplikátů pro každou z těchto hodnot.
Testovací dotaz je velmi jednoduchý seskupený COUNT_BIG agregaci pomocí sloupce c2 jako klíč:
-- Testovací dotaz SELECT T.c2, numrows =COUNT_BIG(*)FROM dbo.Test AS TGROUP BY T.c2;
Informace o indexu úložiště sloupců se zobrazí pomocí DBCC CSINDEX po každém provedení testovacího dotazu:
DECLARE @dbname sysname =DB_NAME(), @objectid integer =OBJECT_ID(N'dbo.Test', N'U'); DECLARE @rowsetid bigint =( SELECT P.hobt_id FROM sys.partitions AS P WHERE P.[object_id] =@objectid AND P.index_id =1 AND P.partition_number =1 ), @rowgroupid integer =0, @columnid integer =COLUMNPROPERTY (@objectid, N'c2', 'ColumnId') + 1; DBCC CSINDEX( @dbname, @rowsetid, @columnid, @rowgroupid, 1, -- zobrazit data segmentu 2, -- možnost tisku 0, -- spustit jednotku bitpacku (včetně) 2 -- jednotku bitpacku konec (exkluzivně));Testy byly spuštěny na nejnovější vydané verzi SQL Server dostupné v době psaní článku:Microsoft SQL Server 2017 RTM-CU13-OD sestavení 14.0.3049 Developer Edition (64bitová verze) na Windows 10 Pro. Věci by měly fungovat dobře i na nejnovějším sestavení SQL Server 2016.
Test 1:Pushdown, 9bitové nečisté klíče
Tento test používá skript populace testovacích dat přesně tak, jak je napsán výše, a vytváří tabulku s 32 256 řádky. Sloupec
c1obsahuje čísla od 1 do 32 256.Sloupec
c2obsahuje 512 různých hodnot od 0 do 511 včetně. Každá hodnota vc2je 63krát duplikován , ale při zobrazení vc1se nezobrazují jako souvislé bloky objednat; cyklují 63krát přes hodnoty 0 až 511.Vzhledem k předchozí diskusi očekáváme, že SQL Server uloží
c2data sloupce pomocí:
- Kódování slovníku protože existuje značný počet duplicitních hodnot.
- Žádné RLE . Počet duplikátů (63) na hodnotu nedosahuje prahové hodnoty 64 požadované pro RLE.
- Velikost balení 9 . 512 různých položek slovníku se přesně vejde do 9 bitů (2^9 =512). Každá 64bitová jednotka bude obsahovat až sedm 9bitových podjednotek.
To vše je potvrzeno jako správné pomocí DBCC CSINDEX dotaz:
Atributy segmentu část výstupu zobrazuje kódování slovníku (typ 2; hodnoty pro encodingType jsou zdokumentovány na sys.column_store_segments ).
Verze =1 kódováníType =2 hasNulls =0
BaseId =-1 Velikost =-1,000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 Max. =37944 Počet řádků =32256
Sekce RLE zobrazuje žádná data RLE , pouze ukazatel na bitově zabalenou oblast a prázdný záznam pro hodnotu nula:
Záhlaví RLE:
Typ lobu =3 Počet pole RLE (z hlediska nativních jednotek) =2
Velikost vstupu pole RLE =8
Data RLE:
Index =0 Index bitpackového pole =0 Počet =32256
Index =1 Hodnota =0 Počet =0
Záhlaví dat Bitpack sekce zobrazuje bitpack velikosti 9 a 4 608 použitých bitpackových jednotek:
Bitpack Data Header:
Vstupní velikost bitpacku =9 Počet jednotek bitpacku =4608 MinId bitpacku =3
Velikost dat bitpacku =36864
Data Bitpack sekce zobrazuje hodnoty uložené v prvních dvou jednotkách bitpacku, jak to vyžadují poslední dva parametry DBCC CSINDEX příkaz. Připomeňme, že každá 64bitová jednotka může obsahovat 7 podjednotek (číslovaných 0 až 6) po 9 bitech (7 x 9 =63 bitů). Celkem 4 608 jednotek pojme 4 608 * 7 =32 256 řádků:
Jednotka 0 Podjednotka 0 =383
Jednotka 0 Podjednotka 1 =255
Jednotka 0 Podjednotka 2 =127
Jednotka 0 Podjednotka 3 =510
Jednotka 0 Podjednotka 4 =381
Jednotka 0 Podjednotka 5 =253
Jednotka 0 Podjednotka 6 =125
Jednotka 1 Podjednotka 0 =508
Jednotka 1 Podjednotka 1 =379
Jednotka 1 Podjednotka 2 =251
Jednotka 1 Podjednotka 3 =123
Jednotka 1 Podjednotka 4 =506
Jednotka 1 Podjednotka 5 =377
Jednotka 1 Podjednotka 6 =249
Protože seskupovací klíče používají bit-packing s velikostí menší nebo rovnou 10 , očekáváme seskupený agregovaný pokles pracovat zde. Prováděcí plán skutečně ukazuje, že všechny řádky byly lokálně agregovány při Columnstore Index Scan operátor:

XML plánu obsahuje ActualLocallyAggregatedRows="32256" v informacích za běhu pro skenování indexu.
Test 2:Žádné posunutí dolů, 12bitové nečisté klíče
Tento test změní @values parametr na 1025 se zachováním @dupes na 63. To dává tabulku 64 575 řádků s 1 025 odlišnými hodnotami ve sloupci c2 běží od 0 do 1024 včetně. Každá hodnota v c2 je 63krát duplikován .
SQL Server ukládá c2 data sloupce pomocí:
- Kódování slovníku protože existuje značný počet duplicitních hodnot.
- Žádné RLE . Počet duplikátů (63) na hodnotu nedosahuje prahové hodnoty 64 požadované pro RLE.
- Bit-packed s velikostí 12 . 1025 různých položek slovníku se nevejde do 10 bitů (2^10 =1024). Vešly by se do 11 bitů, ale SQL Server nepodporuje tuto velikost sbalení bitů, jak bylo zmíněno dříve. Další nejmenší velikost je 12 bitů. Při použití 64bitových jednotek s pevnými okraji pro sbalení bitů se do 64 bitů nevešlo více 11bitových podjednotek než 12bitových podjednotek. V každém případě se do 64bitové jednotky vejde 5 podjednotek.
DBCC CSINDEX výstup potvrzuje výše uvedenou analýzu:
Verze =1 kódováníType =2 hasNulls =0
BaseId =-1 Velikost =-1,000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024SkllS
=104400 Počet řádků =64575
Záhlaví RLE:
Typ lobu =3 Počet pole RLE (z hlediska nativních jednotek) =2
Velikost vstupu pole RLE =8
Údaje RLE:
Index =0 Index bitpackového pole =0 Počet =64575
Index =1 Hodnota =0 Počet =0
Bitpack Data Header:
Vstupní velikost bitpacku =12 Počet jednotek bitového balíčku =12915 MinId bitpacku =3
Velikost dat bitpacku =103320
Data bitového balíčku:
Jednotka 0 Podjednotka 0 =767
Jednotka 0 Podjednotka 1 =510
Jednotka 0 Podjednotka 2 =254
Jednotka 0 Podjednotka 3 =1021
Jednotka 0 Podjednotka 4 =765
Jednotka 1 Podjednotka 0 =507
Jednotka 1 Podjednotka 1 =250
Jednotka 1 Podjednotka 2 =1019
Jednotka 1 Podjednotka 3 =761
Jednotka 1 Podjednotka 4 =505
Od nečistého seskupovací klíče mají velikost větší než 10 , očekáváme seskupený agregovaný pokles nepracovat tady. To je potvrzeno realizačním plánem, který zobrazuje nulové místně agregované řádky na Columnstore Index Scan operátor:
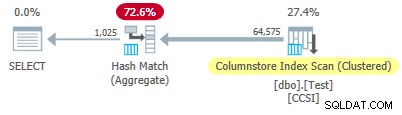
Všech 64 575 řádků je vygenerováno (v dávkách) pomocí Columnstore Index Scan a agregované v dávkovém režimu pomocí Hash Match Aggregate operátor. ActualLocallyAggregatedRows atribut chybí v informacích o běhu plánu xml pro skenování indexu.
Test 3:Pushdown, čisté klávesy
Tento test změní @dupes parametr od 63 do 64 pro povolení RLE. @values parametr se změní na 16 384 (maximum pro celkový počet řádků, které se ještě vejdou do jedné skupiny řádků). Přesné číslo zvolené pro @values není důležité – jde o to vygenerovat 64 duplikátů každé jedinečné hodnoty, aby bylo možné použít RLE.
SQL Server ukládá c2 data sloupce pomocí:
- Kódování slovníku kvůli duplicitním hodnotám.
- RLE. Používá se pro každou odlišnou hodnotu, protože každá splňuje práh 64.
- Žádná bitově zabalená data . Pokud by nějaké byly, použil by velikost 16. Velikost 12 není dostatečně velká (2^12 =4 096 různých hodnot) a velikost 21 by byla plýtvání. 16 384 různých hodnot by se vešlo do 14 bitů, ale stejně jako dříve se do 64bitové jednotky nevejde více než 16bitové podjednotky.
DBCC CSINDEX výstup potvrzuje výše uvedené (z důvodu místa je zobrazeno pouze několik záznamů a záložek RLE):
Verze =1 kódováníType =2 hasNulls =0
BaseId =-1 Velikost =-1,000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383 SkullS
=131648 Počet řádků =1048576
Záhlaví RLE:
Typ lobu =3 Počet pole RLE (z hlediska nativních jednotek) =16385
Velikost vstupu pole RLE =8
Údaje RLE:
Index =0 Hodnota =3 Počet =64
Index =1 Hodnota =1538 Počet =64
Index =2 Hodnota =3072 Počet =64
Index =3 Hodnota =4608 Počet =64
Index =4 Hodnota =6142 Počet =64
…
Index =16381 Hodnota =8954 Počet =64
Index =16382 Hodnota =10489 Počet =64
Index =16383 Hodnota =12025 Počet =64
Index =16384 Hodnota =0 Počet =0
Záhlaví záložky:
Počet záložek =65 Vzdálenost záložky =16384 Velikost záložky =520
Data záložky:
Pozice =0 Index =64
Pozice =512 Index =16448
Pozice =1024 Index =32832
…
Pozice =31744 Index =1015872
Pozice =32256 Index =1032256
Pozice =32768 Index =1048577
Bitpack Data Header:
Velikost položky bitpacku =16 Počet jednotek bitpacku =0 MinId bitpacku =3
Velikost dat bitpacku =0
Protože seskupovací klíče jsou čisté (používá se RLE), seskupený agregovaný pokles se zde očekává. Prováděcí plán to potvrzuje zobrazením místně agregovaných všech řádků na Columnstore Index Scan operátor:
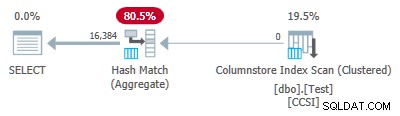
XML plánu obsahuje ActualLocallyAggregatedRows="1048576" v informacích za běhu pro skenování indexu.
Test 4:10bitové nečisté klíče
Tento test nastavuje @values na 1024 a @dupes na 63, což dává tabulku 64 512 řádků s 1 024 odlišnými hodnotami ve sloupci c2 s hodnotami od 0 do 1 023 včetně. Každá hodnota v c2 je 63krát duplikován .
To je nejdůležitější , seskupený index b-stromu je nyní vytvořen ve sloupci c1 místo sloupce c2 . Clusterovaný columnstore stále nahrazuje klastrovaný index b-tree. Toto je změněná část skriptu:
-- Poznamenejte si nyní sloupec c1!CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1);GOCREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.TestWITH (MAXDOP =1, DROP_EXISTING =ON);
SQL Server ukládá c2 data sloupce pomocí:
- Kódování slovníku kvůli duplikátům.
- Žádné RLE . Počet duplikátů (63) na hodnotu nedosahuje prahové hodnoty 64 požadované pro RLE.
- Bit-packing s velikostí 10 . 1 024 různých položek slovníku se přesně vejde do 10 bitů (2^10 =1 024). V každé 64bitové jednotce lze uložit šest podjednotek po 10 bitech.
DBCC CSINDEX výstup je:
Verze =1 kódováníType =2 hasNulls =0
BaseId =-1 Velikost =-1,000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023 Skóre
=87096 Počet řádků =64512
Záhlaví RLE:
Typ lobu =3 Počet pole RLE (z hlediska nativních jednotek) =2
Velikost vstupu pole RLE =8
Údaje RLE:
Index =0 Index bitpackového pole =0 Počet =64512
Index =1 Hodnota =0 Počet =0
Bitpack Data Header:
Vstupní velikost bitpacku =10 Počet jednotek bitového balíčku =10752 MinId bitpacku =3
Velikost dat bitpacku =86016
Data bitového balíčku:
Jednotka 0 Podjednotka 0 =766
Jednotka 0 Podjednotka 1 =509
Jednotka 0 Podjednotka 2 =254
Jednotka 0 Podjednotka 3 =1020
Jednotka 0 Podjednotka 4 =764
Jednotka 0 Podjednotka 5 =506
Jednotka 1 Podjednotka 0 =250
Jednotka 1 Podjednotka 1 =1018
Jednotka 1 Podjednotka 2 =760
Jednotka 1 Podjednotka 3 =504
Jednotka 1 Podjednotka 4 =247
Jednotka 1 Podjednotka 5 =1014
Od nečistého seskupovací klíče používají velikost menší nebo rovnou 10, očekávali bychom seskupené agregované rozšíření pracovat zde. Ale to se neděje . Plán provádění ukazuje, že 54 612 z 64 512 řádků bylo agregováno v Hash Match Aggregate operátor:
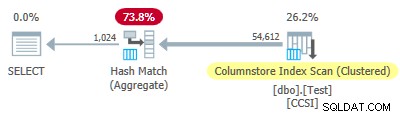
XML plánu obsahuje ActualLocallyAggregatedRows="9900" v informacích za běhu pro skenování indexu. To znamená seskupené souhrnné rozšíření byl použit pro 9 900 řádků, ale nebyl použit pro dalších 54 612!
Mechanismus zpětné vazby
SQL Server se spustil pomocí seskupeného souhrnného rozšíření pro toto provedení, protože nečisté seskupovací klíče splňovaly kritéria 10bitů nebo méně. To trvalo celkem 11 dávek (každá z 900 řádků =celkem 9 900 řádků). V tomto okamžiku funguje mechanismus zpětné vazby, který měří efektivitu seskupeného souhrnného rozšíření rozhodl, že to nefunguje, a vypnul to . Všechny zbývající dávky byly zpracovány s deaktivovaným zásobníkem dolů.
Zpětná vazba v podstatě porovnává počet agregovaných řádků s počtem vytvořených skupin. Začíná hodnotou 100 a upravuje se na konci každé výstupní dávky zásobníku. Pokud hodnota klesne na 10 nebo níže, posun dolů je pro aktuální operaci seskupování deaktivován.
„Měření přínosů stlačování dolů“ se více či méně snižuje v závislosti na tom, jak špatně se vyvíjí úsilí o snížení agregace. Pokud je ve výstupní dávce v průměru méně než 8 řádků na seskupovací klíč, sníží se aktuální hodnota přínosu o 22 %. Pokud je jich více než 8, ale méně než 16, metrika se sníží o 11 %.
Na druhou stranu, pokud se situace zlepší a následně se u výstupní dávky objeví 16 nebo více řádků na seskupovací klíč, metrika se resetuje na 100 a bude nadále upravována, protože skenování vytváří dílčí agregované dávky.
Data v tomto testu byla prezentována v obzvláště neužitečném pořadí pro posunutí dolů kvůli původnímu seskupenému indexu b-stromu ve sloupci c1 . Když jsou prezentovány tímto způsobem, hodnoty ve sloupci c2 začínají na 0 a zvyšují se o 1, dokud nedosáhnou 1 023, pak začnou cyklus znovu. 1 023 různých hodnot je více než dostačujících k tomu, aby každá výstupní dávka s 900 řádky obsahovala pouze jeden částečně agregovaný řádek pro každý klíč. Toto není šťastný stav.
Pokud by na hodnotu bylo 64 duplikátů místo 63, SQL Server by zvážil řazení podle c2 při vytváření indexu columnstore, a tak vytvořil kompresi RLE. Jak to tak je, 22% penalta se hází po každé dávce. Počínaje 100 a za použití stejné zaokrouhlené celočíselné aritmetiky je sled metrických hodnot:
-- @metric :=FLOOR(@metric * 0,78 + 0,5);-- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
Jedenáctá dávka sníží metriku na 10 nebo méně a posun dolů je deaktivován. 11 dávek po 900 řádcích představuje 9 900 místně agregovaných řádků uvedených v prováděcím plánu.
Varianta s 900 různými hodnotami
Stejné chování lze pozorovat v testu 4 s pouhými 901 odlišnými hodnotami, za předpokladu, že jsou řádky prezentovány ve stejném neužitečném pořadí.
Změna @values parametr na 900 při zachování všeho ostatního má dramatický vliv na plán provádění:
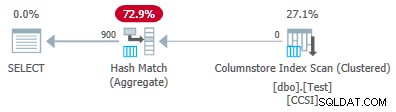
Nyní je při skenování agregováno všech 900 skupin! Vlastnosti plánu xml zobrazují ActualLocallyAggregatedRows="56700" . Je to proto, že seskupený agregovaný zásobník udržuje 900 seskupovacích klíčů a dílčích agregací v jedné dávce. It never encounters a new key value not in the batch, so there is no reason to start a fresh output batch.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Poznámka: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.