Funkce okna ROW_NUMBER má mnoho praktických aplikací, které přesahují pouhé zřejmé potřeby hodnocení. Většinou, když počítáte čísla řádků, musíte je vypočítat na základě nějaké objednávky a v klauzuli pořadí okna funkce poskytujete požadovanou specifikaci objednávky. Existují však případy, kdy potřebujete vypočítat čísla řádků v žádném konkrétním pořadí; jinými slovy, založené na nedeterministickém řádu. To může být v celém výsledku dotazu nebo v rámci oddílů. Příklady zahrnují přiřazení jedinečných hodnot k řádkům výsledků, deduplikaci dat a vrácení libovolného řádku na skupinu.
Všimněte si, že potřeba přiřadit čísla řádků na základě nedeterministického pořadí je jiná než potřeba přiřadit je na základě náhodného pořadí. U prvního z nich vás prostě nezajímá, v jakém pořadí jsou přiřazeny a zda opakované provádění dotazu přiřazuje stejná čísla řádků stejným řádkům nebo ne. U posledně jmenovaného očekáváte, že opakovaná provádění se budou neustále měnit, kterým řádkům bude přiřazena která čísla řádků. Tento článek zkoumá různé techniky pro výpočet čísel řádků s nedeterministickým pořadím. Doufáme, že se najde technika, která bude spolehlivá a optimální.
Zvláštní poděkování Paulu Whiteovi za tip týkající se neustálého skládání, za běhovou konstantní techniku a za to, že jste vždy skvělým zdrojem informací!
Když na objednávce záleží
Začnu případy, kdy na pořadí podle čísla řádku záleží.
Ve svých příkladech použiji tabulku s názvem T1. Pomocí následujícího kódu vytvořte tuto tabulku a naplňte ji ukázkovými daty:
SET NOCOUNT ON; USE tempdb; DROP TABLE IF EXISTS dbo.T1; GO CREATE TABLE dbo.T1 ( id INT NOT NULL CONSTRAINT PK_T1 PRIMARY KEY, grp VARCHAR(10) NOT NULL, datacol INT NOT NULL ); INSERT INTO dbo.T1(id, grp, datacol) VALUES (11, 'A', 50), ( 3, 'B', 20), ( 5, 'A', 40), ( 7, 'B', 10), ( 2, 'A', 50);
Zvažte následující dotaz (budeme ho nazývat Dotaz 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Zde chcete, aby byla čísla řádků přiřazena v rámci každé skupiny identifikované sloupcem grp, seřazené podle sloupce datacol. Když jsem na svém systému spustil tento dotaz, dostal jsem následující výstup:
id grp datacol n --- ---- -------- --- 5 A 40 1 2 A 50 2 11 A 50 3 7 B 10 1 3 B 20 2
Čísla řádků jsou zde přiřazena v částečně deterministickém a částečně nedeterministickém pořadí. Chci tím říct, že máte jistotu, že v rámci stejného oddílu řádek s vyšší hodnotou datacol získá vyšší hodnotu čísla řádku. Protože však datacol není v rámci oddílu grp jedinečný, je pořadí přiřazení čísel řádků mezi řádky se stejnými hodnotami grp a datacol nedeterministické. To je případ řádků s hodnotami id 2 a 11. Oba mají hodnotu grp A a hodnotu datacol 50. Když jsem tento dotaz na svém systému provedl poprvé, řádek s id 2 dostal řádek číslo 2 a řádek s ID 11 dostal řádek číslo 3. Nezáleží na pravděpodobnosti, že se to stane v praxi na SQL Serveru; pokud spustím dotaz znovu, teoreticky by k řádku s id 2 mohl být přiřazen řádek číslo 3 a k řádku s id 11 by mohl být přiřazen řádek číslo 2.
Pokud potřebujete přiřadit čísla řádků na základě zcela deterministického pořadí, které zaručuje opakovatelné výsledky při provádění dotazu, pokud se nezmění podkladová data, potřebujete, aby byla kombinace prvků v klauzuli o rozdělení oken a řazení jedinečná. Toho lze v našem případě dosáhnout přidáním id sloupce do klauzule pořadí okna jako nerozhodného výsledku. Klauzule OVER by pak byla:
OVER (PARTITION BY grp ORDER BY datacol, id)
V každém případě, při výpočtu čísel řádků na základě nějaké smysluplné specifikace řazení, jako je tomu v Dotazu 1, SQL Server potřebuje zpracovat řádky uspořádané kombinací prvků rozdělení oken a řazení. Toho lze dosáhnout buď stažením předobjednaných dat z indexu, nebo seřazením dat. V tuto chvíli není na T1 žádný index, který by podporoval výpočet ROW_NUMBER v Dotazu 1, takže SQL Server se musí rozhodnout pro třídění dat. To lze vidět na plánu pro Dotaz 1 na obrázku 1.
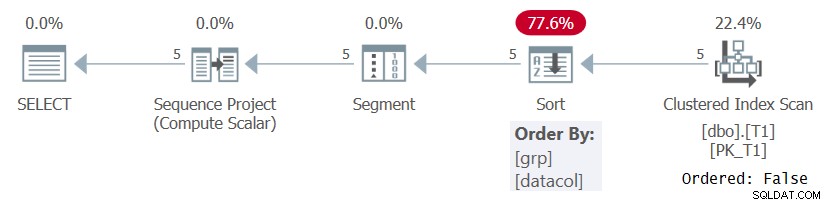 Obrázek 1:Plán pro dotaz 1 bez podpůrného indexu
Obrázek 1:Plán pro dotaz 1 bez podpůrného indexu
Všimněte si, že plán skenuje data z seskupeného indexu pomocí vlastnosti Ordered:False. To znamená, že skenování nemusí vracet řádky seřazené podle indexového klíče. Je tomu tak, protože seskupený index se zde používá jen proto, že pokrývá dotaz a ne kvůli pořadí klíčů. Plán pak použije řazení, což má za následek dodatečné náklady, škálování N Log N a zpožděnou dobu odezvy. Operátor segmentu vytvoří příznak označující, zda je řádek první v oddílu nebo ne. Nakonec operátor Sequence Project přiřadí čísla řádků začínající 1 v každém oddílu.
Chcete-li se vyhnout nutnosti třídění, můžete připravit krycí rejstřík se seznamem klíčů, který je založen na prvcích rozdělení a řazení, a seznamem zahrnutí, který je založen na krycích prvcích. Rád bych tento index považoval za index POC (pro rozdělení , objednávka a krytí ). Zde je definice POC, která podporuje náš dotaz:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Spusťte dotaz 1 znovu:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Plán tohoto provedení je znázorněn na obrázku 2.
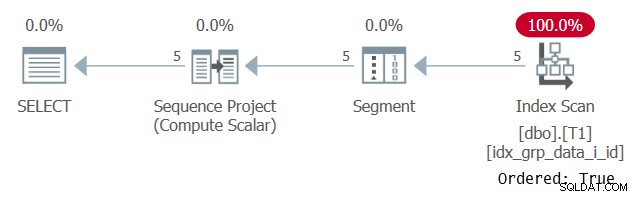 Obrázek 2:Plán pro dotaz 1 s indexem POC
Obrázek 2:Plán pro dotaz 1 s indexem POC
Všimněte si, že tentokrát plán skenuje index POC s vlastností Ordered:True. To znamená, že skenování zaručuje, že řádky budou vráceny v pořadí klíče indexu. Vzhledem k tomu, že data jsou vytahována z indexu předobjednaná, jak to potřebuje funkce okna, není potřeba explicitní řazení. Měřítko tohoto plánu je lineární a doba odezvy je dobrá.
Když na pořadí nezáleží
Věci jsou trochu složitější, když potřebujete přiřadit čísla řádků se zcela nedeterministickým pořadím. Přirozená věc, kterou chcete v takovém případě udělat, je použít funkci ROW_NUMBER bez zadání klauzule pořadí oken. Nejprve se podívejme, zda to standard SQL umožňuje. Zde je relevantní část standardu definující pravidla syntaxe pro funkce okna:
Pravidla syntaxe…
5) Nechť WNS je
6) Pokud je zadáno
a) Je-li zadáno
…
f) ROW_NUMBER() OVER WNS je ekvivalentní
…
Všimněte si, že položka 6 uvádí funkce
Takže to zkusme a zkusme vypočítat čísla řádků bez řazení oken na serveru SQL:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Výsledkem tohoto pokusu je následující chyba:
Zpráva 4112, úroveň 15, stav 1, řádek 53Funkce 'ROW_NUMBER' musí mít klauzuli OVER s ORDER BY.
Pokud se podíváte do dokumentace SQL Serveru k funkci ROW_NUMBER, najdete následující text:
„order_by_clause“.Klauzule ORDER BY určuje pořadí, ve kterém jsou řádkům přiřazeny jejich jedinečné ROW_NUMBER v rámci zadaného oddílu. Je to povinné.“
Zjevně je tedy klauzule pořadí oken povinná pro funkci ROW_NUMBER na serveru SQL Server. To je mimochodem také případ Oracle.
Musím říct, že si nejsem jistý, jestli rozumím zdůvodnění tohoto požadavku. Pamatujte, že umožňujete definovat čísla řádků na základě částečně nedeterministického pořadí, jako v Dotazu 1. Proč tedy nepovolit nedeterminismus úplně? Možná existuje nějaký důvod, o kterém nepřemýšlím. Pokud vás takový důvod napadá, podělte se o něj.
V každém případě můžete namítnout, že pokud vám nezáleží na pořadí, protože klauzule o objednávce okna je povinná, můžete zadat jakoukoli objednávku. Problém s tímto přístupem je, že pokud objednáváte podle nějakého sloupce z dotazovaných tabulek, může to znamenat zbytečnou penalizaci výkonu. Pokud neexistuje žádný podpůrný index, budete platit za explicitní třídění. Když je na místě podpůrný index, omezujete úložný stroj na strategii skenování pořadí indexů (podle seznamu propojených indexů). Neumožníte mu větší flexibilitu, jakou má obvykle, když na pořadí nezáleží při výběru mezi skenováním pořadí indexu a skenováním pořadí přidělení (na základě stránek IAM).
Jeden nápad, který stojí za to vyzkoušet, je zadat konstantu, například 1, v klauzuli pořadí oken. Pokud je podporován, doufáte, že je optimalizátor dostatečně chytrý, aby si uvědomil, že všechny řádky mají stejnou hodnotu, takže neexistuje žádná skutečná relevance pro řazení, a proto není potřeba vynucovat řazení nebo skenování pořadí indexu. Zde je dotaz pokoušející se o tento přístup:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Bohužel SQL Server toto řešení nepodporuje. Vygeneruje následující chybu:
Msg 5308, Level 16, State 1, Line 56Funkce v okně, agregace a funkce NEXT VALUE FOR nepodporují celočíselné indexy jako výrazy klauzule ORDER BY.
SQL Server zjevně předpokládá, že pokud používáte celočíselnou konstantu v klauzuli pořadí oken, představuje řadovou pozici prvku v seznamu SELECT, jako když zadáte celé číslo v klauzuli prezentace ORDER BY. Pokud je to tak, další možností, kterou stojí za to vyzkoušet, je zadat neceločíselnou konstantu, například takto:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No Order') AS n FROM dbo.T1;
Ukázalo se, že toto řešení také není podporováno. SQL Server generuje následující chybu:
Msg 5309, Level 16, State 1, Line 65Funkce v okně, agregace a funkce NEXT VALUE FOR nepodporují konstanty jako výrazy klauzule ORDER BY.
Klauzule pořadí oken zjevně nepodporuje žádný druh konstanty.
Doposud jsme se o důležitosti řazení oken funkce ROW_NUMBER na serveru SQL dozvěděli následující:
- Je vyžadováno ORDER BY.
- Nelze seřadit podle celočíselné konstanty, protože SQL Server si myslí, že se pokoušíte zadat řadovou pozici v SELECT.
- Nelze seřadit podle žádného druhu konstanty.
Závěr je, že byste měli seřadit podle výrazů, které nejsou konstanty. Samozřejmě můžete seřadit podle seznamu sloupců z dotazovaných tabulek. Ale snažíme se najít efektivní řešení, kde si optimalizátor dokáže uvědomit, že zde není žádná relevance pro objednávání.
Neustálé skládání
Dosavadní závěr je takový, že nemůžete použít konstanty v klauzuli pořadí okna ROW_NUMBER, ale co výrazy založené na konstantách, jako například v následujícím dotazu:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Tento pokus se však stane obětí procesu známého jako konstantní skládání, které má obvykle pozitivní dopad na výkon dotazů. Myšlenkou této techniky je zlepšit výkon dotazu skládáním některých výrazů založených na konstantách do jejich výsledných konstant v rané fázi zpracování dotazu. Podrobnosti o tom, jaké druhy výrazů lze neustále skládat, naleznete zde. Náš výraz 1+0 je složen na 1, což má za následek stejnou chybu, jakou jste dostali při přímém zadání konstanty 1:
Msg 5308, Level 16, State 1, Line 79Funkce v okně, agregace a funkce NEXT VALUE FOR nepodporují celočíselné indexy jako výrazy klauzule ORDER BY.
Při pokusu o zřetězení dvou znakových řetězcových literálů byste čelili podobné situaci, například takto:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No' + ' Order') AS n FROM dbo.T1;
Dostanete stejnou chybu, jakou jste dostali při přímém zadání doslovného 'No Order':
Msg 5309, Level 16, State 1, Line 55Funkce v okně, agregace a funkce NEXT VALUE FOR nepodporují konstanty jako výrazy klauzule ORDER BY.
Bizarní svět – chyby, které předcházejí chybám
Život je plný překvapení…
Jedna věc, která brání neustálému skládání, je situace, kdy by výraz normálně vedl k chybě. Například výraz 2147483646+1 může být neustále skládaný, protože výsledkem je platná hodnota typu INT. V důsledku toho selže pokus o spuštění následujícího dotazu:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 109
Funkce v okně, agregace a funkce NEXT VALUE FOR nepodporují celočíselné indexy jako výrazy klauzule ORDER BY.
Výraz 2147483647+1 však nemůže být konstantní složený, protože takový pokus by vedl k chybě INT-overflow. Implikace na objednávání je docela zajímavá. Zkuste následující dotaz (budeme mu říkat Dotaz 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Kupodivu tento dotaz běží úspěšně! Stane se, že na jedné straně SQL Server nedokáže aplikovat konstantní skládání, a proto je řazení založeno na výrazu, který není jedinou konstantou. Na druhou stranu optimalizátor zjistí, že hodnota řazení je pro všechny řádky stejná, takže výraz řazení zcela ignoruje. To je potvrzeno při zkoumání plánu pro tento dotaz, jak je znázorněno na obrázku 3.
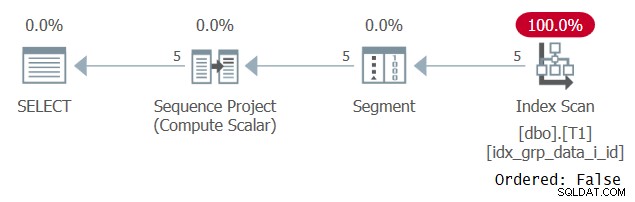 Obrázek 3:Plán pro dotaz 2
Obrázek 3:Plán pro dotaz 2
Všimněte si, že plán skenuje nějaký krycí index s vlastností Ordered:False. Přesně to byl náš výkonnostní cíl.
Podobným způsobem zahrnuje následující dotaz úspěšný pokus o konstantní skládání, a proto se nezdaří:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;Zpráva 5308, úroveň 16, stav 1, řádek 123
Funkce, agregace a funkce NEXT VALUE FOR v okně nepodporují celočíselné indexy jako výrazy klauzule ORDER BY.
Následující dotaz zahrnuje neúspěšný pokus o neustálé skládání, a proto je úspěšný a generuje plán zobrazený dříve na obrázku 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
Následující dotaz zahrnuje úspěšný pokus o konstantní skládání (doslovný VARCHAR '1' se implicitně převede na INT 1 a poté se 1 + 1 složí na 2), a proto se nezdaří:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'1') AS n FROM dbo.T1;Zpráva 5308, úroveň 16, stav 1, řádek 134
Funkce, agregace a funkce NEXT VALUE FOR v okně nepodporují celočíselné indexy jako výrazy klauzule ORDER BY.
Následující dotaz zahrnuje neúspěšný pokus o neustálé skládání (nelze převést 'A' na INT), a proto je úspěšný a generuje plán zobrazený dříve na obrázku 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'A') AS n FROM dbo.T1;
Abych byl upřímný, i když tato bizarní technika dosahuje našeho původního výkonnostního cíle, nemohu říci, že ji považuji za bezpečnou, a proto mi není tak příjemné se na ni spoléhat.
Běhové konstanty založené na funkcích
Pokračujeme v hledání dobrého řešení pro výpočet čísel řádků s nedeterministickým pořadím, existuje několik technik, které se zdají bezpečnější než poslední nepředvídatelné řešení:použití běhových konstant založených na funkcích, použití poddotazu založeného na konstantě, použití aliasovaného sloupce založeného na konstanta a pomocí proměnné.
Jak vysvětluji v T-SQL chyby, úskalí a osvědčené postupy – determinismus, většina funkcí v T-SQL je vyhodnocena pouze jednou na odkaz v dotazu – nikoli jednou na řádek. To je případ i většiny nedeterministických funkcí, jako je GETDATE a RAND. Existuje jen velmi málo výjimek z tohoto pravidla, jako jsou funkce NEWID a CRYPT_GEN_RANDOM, které se vyhodnocují jednou na řádek. Většina funkcí, jako GETDATE, @@SPID a mnoho dalších, je vyhodnocena jednou na začátku dotazu a jejich hodnoty jsou pak považovány za běhové konstanty. Odkaz na takové funkce není konstantní. Tyto vlastnosti dělají z runtime konstanty, která je založena na funkci, dobrou volbu jako prvek řazení oken a skutečně se zdá, že ji T-SQL podporuje. Optimalizátor si zároveň uvědomuje, že v praxi neexistuje žádná relevance objednávek, čímž se vyhne zbytečným sankcím za výkon.
Zde je příklad použití funkce GETDATE:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Tento dotaz získá stejný plán, který je znázorněn dříve na obrázku 3.
Zde je další příklad použití funkce @@SPID (vracející aktuální ID relace):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
A co funkce PI? Zkuste následující dotaz:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Tento selže s následující chybou:
Msg 5309, Level 16, State 1, Line 153Funkce v okně, agregace a funkce NEXT VALUE FOR nepodporují konstanty jako výrazy klauzule ORDER BY.
Funkce jako GETDATE a @@SPID se přehodnocují jednou za provedení plánu, takže je nelze neustále skládat. PI představuje vždy stejnou konstantu, a proto je konstanta složena.
Jak již bylo zmíněno, existuje jen velmi málo funkcí, které jsou vyhodnoceny jednou na řádek, například NEWID a CRYPT_GEN_RANDOM. To z nich dělá špatnou volbu jako prvek řazení oken, pokud potřebujete nedeterministické pořadí – nezaměňovat s náhodným pořadím. Proč platit zbytečné pokuty za třídění?
Zde je příklad použití funkce NEWID:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
Plán pro tento dotaz je znázorněn na obrázku 4, což potvrzuje, že SQL Server přidal explicitní řazení na základě výsledku funkce.
 Obrázek 4:Plán pro dotaz 3
Obrázek 4:Plán pro dotaz 3
Pokud opravdu chcete, aby byla čísla řádků přidělována v náhodném pořadí, je to technika, kterou chcete použít. Jen si musíte být vědomi toho, že to přináší náklady na řazení.
Použití dílčího dotazu
Jako výraz řazení okna můžete také použít poddotaz založený na konstantě (např. ORDER BY (SELECT 'No Order')). Také s tímto řešením optimalizátor SQL Server rozpozná, že neexistuje žádná relevance pro objednávání, a proto nevynucuje zbytečné třídění ani neomezuje možnosti úložiště na ty, které musí zaručovat pořadí. Zkuste jako příklad spustit následující dotaz:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'No Order')) AS n FROM dbo.T1;
Získáte stejný plán, který je znázorněn dříve na obrázku 3.
Jednou z velkých výhod této techniky je, že můžete přidat svůj vlastní osobní dotek. Možná se vám opravdu líbí NULL:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Možná se vám určité číslo opravdu líbí:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Možná chcete někomu poslat zprávu:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'Lilach, will you marry me?')) AS n FROM dbo.T1;
Chápete pointu.
Možné, ale nepříjemné
Existuje několik technik, které fungují, ale jsou trochu nešikovné. Jedním z nich je definovat alias sloupce pro výraz založený na konstantě a pak použít tento alias sloupce jako prvek řazení okna. Můžete to provést buď pomocí tabulkového výrazu, nebo pomocí operátoru CROSS APPLY a konstruktoru hodnot tabulky. Zde je příklad toho druhého:
SELECT id, grp, datacol,
ROW_NUMBER() OVER(ORDER BY [I'm a bit ugly]) AS n
FROM dbo.T1 CROSS APPLY ( VALUES('No Order') ) AS A([I'm a bit ugly]); Získáte stejný plán, který je znázorněn dříve na obrázku 3.
Další možností je použití proměnné jako prvku řazení oken:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Tento dotaz také získá plán zobrazený dříve na obrázku 3.
Co když použiji vlastní UDF?
Možná si myslíte, že použití vlastního UDF, které vrací konstantu, by mohlo být dobrou volbou jako prvek řazení oken, když chcete nedeterministické pořadí, ale není. Zvažte následující definici UDF jako příklad:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis; GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INT AS BEGIN RETURN NULL END; GO
Zkuste použít UDF jako klauzuli pro uspořádání oken, jako je to (budeme tomu říkat Dotaz 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Před SQL Serverem 2019 (nebo paralelní úrovní kompatibility <150) se uživatelem definované funkce vyhodnocují na řádek. I když vrátí konstantu, nebudou vloženy. V důsledku toho na jednu stranu můžete použít takový UDF jako prvek řazení oken, ale na druhou stranu to má za následek pokutu za řazení. To je potvrzeno prozkoumáním plánu pro tento dotaz, jak je znázorněno na obrázku 5.
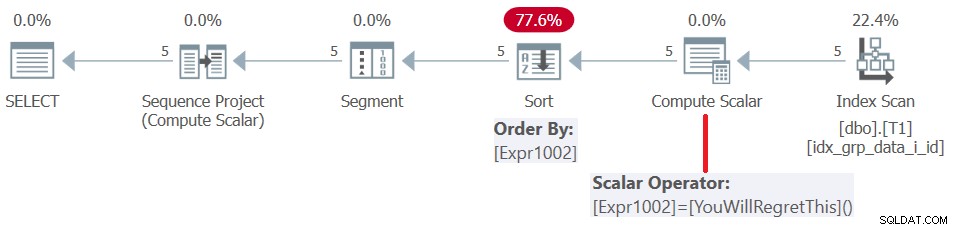 Obrázek 5:Plán pro dotaz 4
Obrázek 5:Plán pro dotaz 4
Počínaje SQL Serverem 2019, pod úrovní kompatibility>=150, jsou takové uživatelem definované funkce vloženy, což je většinou skvělá věc, ale v našem případě to vede k chybě:
Msg 5309, Level 16, State 1, Line 217Funkce v okně, agregace a funkce NEXT VALUE FOR nepodporují konstanty jako výrazy klauzule ORDER BY.
Takže použití UDF založeného na konstantě jako prvku řazení oken buď vynutí řazení nebo chybu v závislosti na verzi SQL Server, kterou používáte, a na úrovni kompatibility databáze. Stručně řečeno, nedělejte to.
Čísla řádků rozdělená s nedeterministickým pořadím
Běžným případem použití dělených čísel řádků na základě nedeterministického pořadí je vrácení libovolného řádku na skupinu. Vzhledem k tomu, že podle definice v tomto scénáři existuje rozdělovací prvek, mysleli byste si, že bezpečnou technikou by v takovém případě bylo použít prvek rozdělování oken také jako prvek řazení oken. Jako první krok vypočítáte čísla řádků takto:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
Plán pro tento dotaz je znázorněn na obrázku 6.
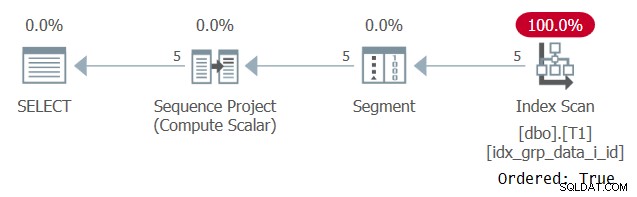 Obrázek 6:Plán pro dotaz 5
Obrázek 6:Plán pro dotaz 5
Důvod, proč je náš podpůrný index skenován pomocí vlastnosti Ordered:True, je ten, že SQL Server potřebuje zpracovávat řádky každého oddílu jako jednu jednotku. To je případ před filtrováním. Pokud filtrujete pouze jeden řádek na oddíl, máte na výběr jak algoritmy založené na pořadí, tak algoritmy založené na hash.
Druhým krokem je umístit dotaz s výpočtem čísla řádku do tabulkového výrazu a ve vnějším dotazu filtrovat řádek s číslem řádku 1 v každém oddílu, například takto:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Teoreticky by tato technika měla být bezpečná, ale Paul White našel chybu, která ukazuje, že pomocí této metody můžete získat atributy z různých zdrojových řádků ve vráceném řádku výsledku na oddíl. Použití běhové konstanty založené na funkci nebo poddotazu založeného na konstantě jako prvku řazení se zdá být bezpečné i v tomto scénáři, takže se ujistěte, že místo toho používáte řešení, jako je následující:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY (SELECT 'No Order')) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Nikdo tudy neprojde bez mého svolení
Běžnou potřebou je pokusit se vypočítat čísla řádků na základě nedeterministického pořadí. Bylo by hezké, kdyby T-SQL jednoduše učinilo klauzuli pořadí oken volitelnou pro funkci ROW_NUMBER, ale není tomu tak. Pokud ne, bylo by hezké, kdyby to alespoň umožňovalo použití konstanty jako prvku řazení, ale ani to není podporovaná možnost. Ale když se hezky zeptáte, ve formě poddotazu založeného na konstantě nebo běhové konstantě založené na funkci, SQL Server to umožní. To jsou dvě možnosti, které mi nejvíce vyhovují. Opravdu se necítím dobře s nepředvídatelnými chybnými výrazy, které, jak se zdá, fungují, takže tuto možnost nemohu doporučit.