Úvod
Eager Index Spool přečte všechny řádky ze svého podřízeného operátoru do indexované pracovní tabulky, než začne vracet řádky svému nadřazenému operátoru. V některých ohledech je dychtivá indexová cívka tím posledním chybějícím návrhem indexu , ale není to jako takové hlášeno.
Posouzení nákladů
Vkládání řádků do indexovaného pracovního stolu je relativně levné, ale není zdarma. Optimalizátor musí vzít v úvahu, že vynaložená práce ušetří více, než kolik stojí. Aby to dopadlo ve prospěch cívky, je třeba odhadnout, že plán spotřebuje řádky z cívky více než jednou. V opačném případě by mohlo také přeskočit zařazování a provést základní operaci pouze jednou.
- Chcete-li k ní přistupovat více než jednou, musí se cívka objevit na vnitřní straně operátoru spojení vnořených smyček.
- Každá iterace smyčky by měla hledat konkrétní hodnotu klíče zařazování indexu, kterou poskytuje vnější strana smyčky.
To znamená, že připojení musí být přihláška , nikoli spojení vnořených smyček . Rozdíl mezi těmito dvěma naleznete v mém článku Apply versus Nested Loops Join.
Významné funkce
Zatímco dychtivá indexová cívka se může objevit pouze na vnitřní straně vnořených smyček použít , nejedná se o „výkonovou cívku“. Dychtivé zařazování indexů nelze deaktivovat příznakem trasování 8690 nebo NO_PERFORMANCE_SPOOL nápověda k dotazu.
Řádky vložené do zařazování indexů nejsou normálně předem seřazeny podle pořadí klíčů indexu, což může vést k rozdělení stránky indexu. Nezdokumentovaný příznak trasování 9260 lze použít ke generování Řazení operátora před zařazováním indexu, aby se tomu zabránilo. Nevýhodou je, že dodatečné náklady na třídění mohou optimalizátora odradit od výběru možnosti řazení.
SQL Server nepodporuje paralelní vkládání do indexu b-stromu. To znamená, že vše pod paralelním eager indexem spool běží na jediném vláknu. Operátoři pod cívkou jsou stále (zavádějícím způsobem) označeni ikonou paralelismu. K zápisu je vybráno jedno vlákno do cívky. Ostatní vlákna čekají na EXECSYNC dokud se to dokončí. Jakmile je cívka naplněna, lze ji číst z paralelními vlákny.
Indexové fronty neříkají optimalizátoru, že podporují výstup uspořádaný podle indexových klíčů zařazování. Pokud je vyžadován setříděný výstup ze zařazování, můžete vidět zbytečné Třídění operátor. Dychtivé indexové cívky by tak jako tak měly být často nahrazeny trvalým indexem, takže to je většinou menší problém.
Existuje pět pravidel optimalizace, která mohou generovat Eager Index Spool možnost (interně známá jako index on-the-fly ). Podíváme se na tři z nich podrobně, abychom pochopili, odkud se berou dychtivé indexové cívky.
SelToIndexOnTheFly
Toto je nejběžnější. Odpovídá jednomu nebo více relačním výběrům (také známým jako filtry nebo predikáty) těsně nad operátorem přístupu k datům. SelToIndexOnTheFly pravidlo nahradí predikáty vyhledávacím predikátem na eager index spool.
Ukázka
AdventureWorks příklad ukázkové databáze je uveden níže:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%';
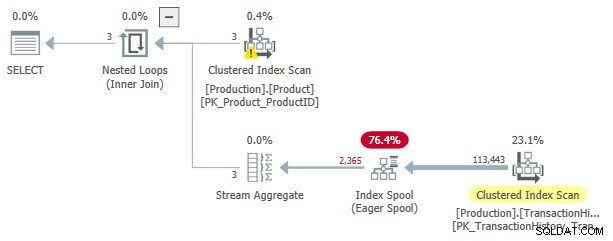
Tento plán realizace má odhadované náklady 3,0881 Jednotky. Některé zajímavosti:
- Vnitřní spojení Nested Loops operátor je použít s
ProductIDaSafetyStockLevelzProducttabulky jako vnější reference . - Při první iteraci aplikace Eager Index Spool je plně naplněna z Clustered Index Scan z
TransactionHistorystůl. - Pracovní tabulka zařazování má seskupený index s klíčem
(ProductID, Quantity). - Řádky odpovídající predikátů
TH.ProductID = P.ProductIDaTH.Quantity < P.SafetyStockLeveljsou zodpovězeny cívkou pomocí jejího indexu. To platí pro každou iteraci aplikace, včetně té první. TransactionHistorytabulka je naskenována pouze jednou.
Setříděný vstup do cívky
Je možné vynutit tříděný vstup do eager index spool, ale to ovlivní odhadované náklady, jak je uvedeno v úvodu. Ve výše uvedeném příkladu povolením nedokumentovaného příznaku trasování vznikne plán bez zařazování:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'
OPTION (QUERYTRACEON 9260);
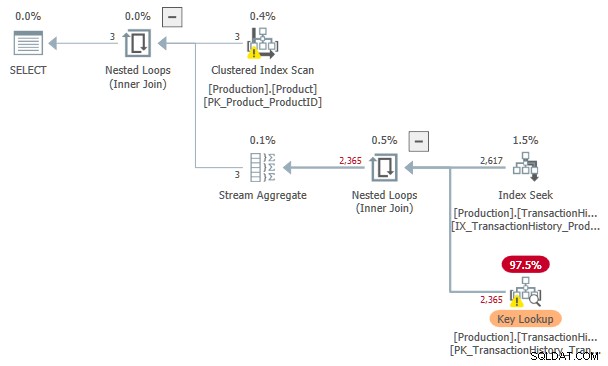
Odhadovaná cena tohoto Vyhledávání indexu a Vyhledání klíče plán je 3,11631 Jednotky. To je více než náklady na plán se samotnou indexovou cívkou, ale méně než plán s indexovou cívkou a tříděným vstupem.
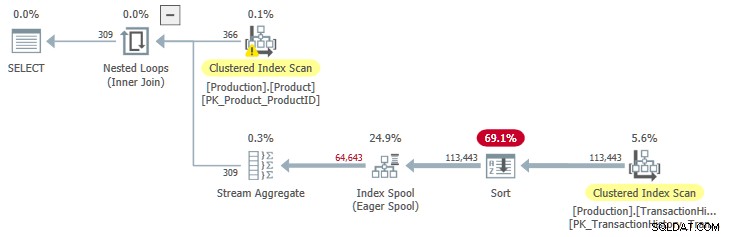
Abychom viděli plán se seřazeným vstupem do cívky, musíme zvýšit očekávaný počet iterací smyčky. To dává spool šanci splatit dodatečné náklady na Řazení . Jeden způsob, jak rozšířit počet řádků očekávaných od Product tabulka je vytvořit Name predikát méně omezující:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'[A-P]%'
OPTION (QUERYTRACEON 9260); To nám dává plán provádění s seřazeným vstupem do zařazování:
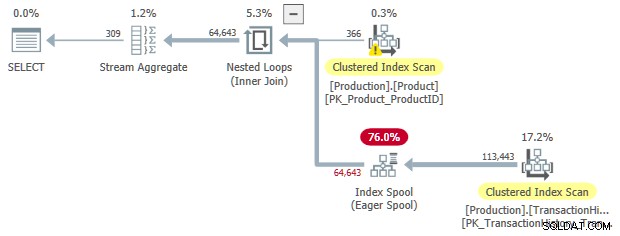
JoinToIndexOnTheFly
Toto pravidlo transformuje vnitřní spojení k přihlášce , s dychtivou indexovou cívkou na vnitřní straně. Aby toto pravidlo odpovídalo, musí být alespoň jeden z predikátů spojení nerovností.
Toto je mnohem specializovanější pravidlo než SelToIndexOnTheFly , ale myšlenka je v podstatě stejná. V tomto případě je výběr (predikát), který se transformuje na hledání zařazování indexu, spojen se spojením. Transformace ze spojení na použít umožňuje přesunutí predikátu spojení ze samotného spojení na vnitřní stranu aplikace.
Ukázka
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN);
Stejně jako dříve můžeme požádat o tříděný vstup do cívky:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN, QUERYTRACEON 9260);
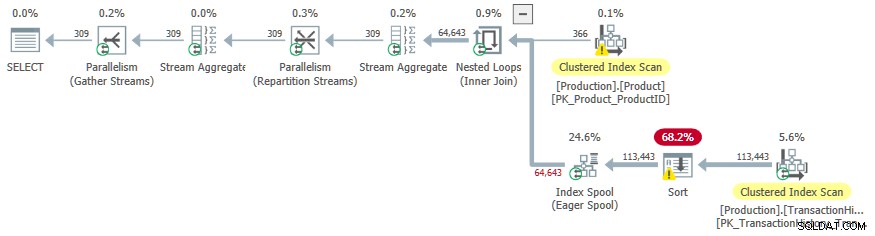
Tentokrát dodatečné náklady na třídění přiměly optimalizátora, aby zvolil paralelní plán.
Nevítaným vedlejším účinkem je Řadit operátor se přelije do tempdb . Celkové přidělení paměti dostupné pro třídění je dostatečné, ale je rovnoměrně rozděleno mezi paralelní vlákna (jako obvykle). Jak bylo uvedeno v úvodu, SQL Server nepodporuje paralelní vkládání do indexu b-stromu, takže operátoři pod nedočkavým zařazováním indexů běží na jediném vláknu. Toto jediné vlákno získá pouze zlomek přidělené paměti, takže Řadit přelije do tempdb .
Tento vedlejší efekt je možná jedním z důvodů, proč je příznak trasování nezdokumentovaný a nepodporovaný.
SelSTVFToIdxOnFly
Toto pravidlo dělá to samé jako SelToIndexOnTheFly , ale pro funkci s hodnotou tabulky streamování (sTVF) řádkový zdroj. Tyto sTVF jsou široce používány interně k implementaci DMV a DMF mimo jiné. V moderních realizačních plánech se objevují jako Funkce s hodnotou tabulky operátory (původně jako skenování vzdálených tabulek ).
V minulosti mnoho z těchto sTVF nemohlo přijímat korelované parametry z aplikace. Mohou přijímat literály, proměnné a parametry modulu, ale ne použít vnější odkazy. V dokumentaci k tomu stále existují varování, ale nyní jsou poněkud zastaralá.
Každopádně jde o to, že někdy není možné, aby SQL Server předal přihlášku vnější odkaz jako parametr k sTVF. V této situaci může mít smysl zhmotnit část výsledku sTVF v dychtivé indexové cívce. Současné pravidlo tuto schopnost poskytuje.
Ukázka
Další příklad kódu ukazuje dotaz DMV, který je úspěšně převeden ze spojení na použít . Vnější reference jsou předány jako parametry druhému DMV:
-- Transformed to an apply
-- Outer reference passed as a parameter
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id = DES.session_id
OPTION (FORCE ORDER);
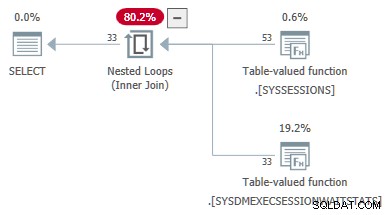
Vlastnosti plánu čekacích statistik TVF ukazují vstupní parametry. Hodnota druhého parametru je poskytnuta jako vnější odkaz z relací DMV:
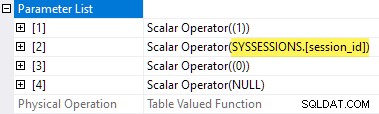
Je škoda, že sys.dm_exec_session_wait_stats je pohled, nikoli funkce, protože to nám brání napsat aplikaci přímo.
Přepsání níže stačí k překonání interní konverze:
-- Rewrite to avoid TVF parameter trickery
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id >= DES.session_id
AND DESWS.session_id <= DES.session_id
OPTION (FORCE ORDER);
Pomocí session_id predikáty se nyní nespotřebovávají jako parametry, SelSTVFToIdxOnFly pravidlo je může volně převést na eager index spool:
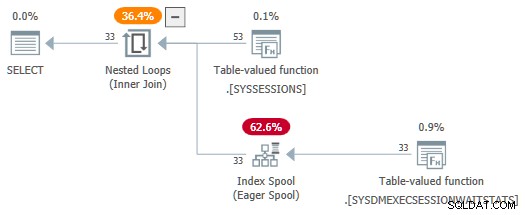
Nechci ve vás zanechat dojem, že je potřeba složitých přepisů, abyste získali horlivou indexovou cívku nad zdrojem DMV – jen to usnadňuje demo. Pokud se náhodou setkáte s dotazem s DMV spojením, který vytváří plán s dychtivým spoolem, alespoň víte, jak se tam dostal.
Na DMV nemůžete vytvářet indexy, takže pokud plán provádění nefunguje dostatečně dobře, možná budete muset použít hash nebo sloučení spojení.
Rekurzivní CTE
Zbývající dvě pravidla jsou SelIterToIdxOnFly a JoinIterToIdxOnFly . Jsou přímými protějšky SelToIndexOnTheFly a JoinToIndexOnTheFly pro rekurzivní zdroje dat CTE. Tyto jsou podle mých zkušeností extrémně vzácné, takže pro ně nebudu poskytovat ukázky. (Stejně tak Iter část názvu pravidla dává smysl:Vychází ze skutečnosti, že SQL Server implementuje koncovou rekurzi jako vnořenou iteraci.)
Když se na rekurzivní CTE odkazuje vícekrát uvnitř aplikace, použije se jiné pravidlo (SpoolOnIterator ) může uložit výsledek CTE:
WITH R AS
(
SELECT 1 AS n
UNION ALL
SELECT R.n + 1
FROM R
WHERE R.n < 10
)
SELECT
R1.n
FROM R AS R1
CROSS JOIN R AS R2; Prováděcí plán obsahuje vzácnou Eager Row Count Spool :
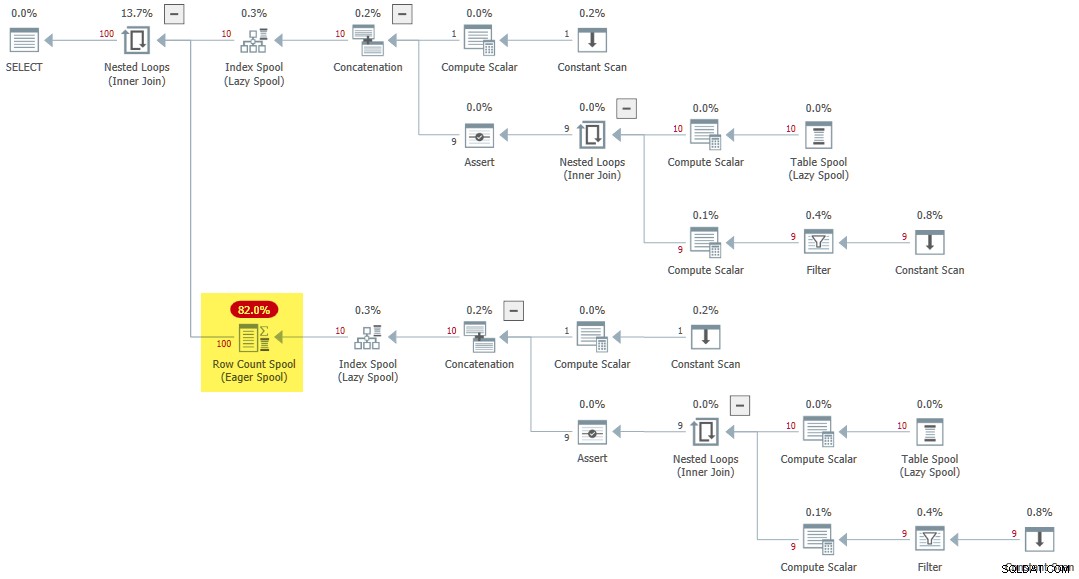
Závěrečné myšlenky
Dychtivé zařazování indexů je často známkou toho, že ve schématu databáze chybí užitečný trvalý index. To není vždy případ, jak ukazují příklady funkcí streamingové tabulky s hodnotou.