Na PASS Summit před několika týdny společnost Microsoft vydala CTP2.1 SQL Server 2019 a jedním z velkých vylepšení funkcí, které je součástí CTP, je Scalar UDF Inlining. Před tímto vydáním jsem si chtěl pohrát s rozdílem ve výkonu mezi vkládáním skalárních UDF a prováděním RBAR (řádek po agonizujícím řádku) skalárních UDF v dřívějších verzích SQL Serveru a narazil jsem na volbu syntaxe pro VYTVOŘIT FUNKCI prohlášení v SQL Server Books Online, které jsem nikdy předtím neviděl.
DDL pro VYTVOŘIT FUNKCI podporuje klauzuli WITH pro možnosti funkcí a při čtení Books Online jsem si všiml, že syntaxe obsahuje následující:
-- Klauzule funkcí Transact-SQL::= { [ ŠIFROVÁNÍ ] | [ SCHEMABINDING ] | [ VRÁTÍ NULL NA NULL VSTUP | VOLÁN NA NULL VSTUP ] | [ EXECUTE_AS_Clause ] }
Byl jsem opravdu zvědavý na RETURNS NULL ON NULL INPUT funkce, tak jsem se rozhodl udělat nějaké testování. Byl jsem velmi překvapen, když jsem zjistil, že je to vlastně forma skalární optimalizace UDF, která je v produktu minimálně od SQL Server 2008 R2.
Ukazuje se, že pokud víte, že skalární UDF vždy vrátí výsledek NULL, když je poskytnut vstup NULL, pak by UDF měl být VŽDY vytvořen pomocí RETURNS NULL ON NULL INPUT možnost, protože pak SQL Server dokonce vůbec nespustí definici funkce pro žádné řádky, kde je vstup NULL – ve skutečnosti to zkratuje a zabrání zbytečnému provádění těla funkce.
Abych vám toto chování ukázal, použiji instanci SQL Server 2017 s nejnovější kumulativní aktualizací aplikovanou na ni a AdventureWorks2017 databáze z GitHubu (můžete si ji stáhnout odtud), která je dodávána s dbo.ufnLeadingZeros funkce, která jednoduše přidá úvodní nuly ke vstupní hodnotě a vrátí osmiznakový řetězec, který obsahuje tyto úvodní nuly. Chystám se vytvořit novou verzi této funkce, která bude obsahovat VRÁTÍ NULL NA NULL INPUT možnost, abych ji mohl porovnat s původní funkcí pro výkon provádění.
POUŽÍVEJTE [AdventureWorks2017]; VYTVOŘTE FUNKCI [dbo].[ufnLeadingZeros_new]( @Value int ) VRACÍ varchar(8) WITH SCHEMABINDING, VRÁTÍ NULL NA NULL INPUT AS ZAČÁTEK DECLARE(8) DECLARE; SET @ReturnValue =CONVERT(varchar(8), @Value); SET @ReturnValue =REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue; NÁVRAT (@ReturnValue); KONEC; GO Pro účely testování rozdílů ve výkonu při provádění v rámci databázového stroje dvou funkcí jsem se rozhodl vytvořit na serveru relaci Extended Events pro sledování sqlserver.module_end událost, která se spustí na konci každého provedení skalárního UDF pro každý řádek. To mi umožňuje demonstrovat sémantiku zpracování řádek po řádku a také mi umožňuje sledovat, kolikrát byla funkce během testu skutečně vyvolána. Rozhodl jsem se také shromáždit sql_batch_completed a sql_statement_completed události a filtrovat vše podle session_id abych se ujistil, že zachycuji pouze informace související s relací, na které jsem testy skutečně prováděl (pokud chcete tyto výsledky replikovat, budete muset změnit 74 na všech místech v kódu níže na jakékoli ID relace vašeho testu kód bude spuštěn). Relace události používá TRACK_CAUSALITY aby bylo možné snadno spočítat, ke kolika provedením funkce došlo prostřednictvím activity_id.seq_no hodnotu pro události (která se zvýší o jednu za každou událost, která splňuje session_id filtr).
VYTVOŘTE RELACI UDÁLOSTI [Session72] NA SERVERU PŘIDAT UDÁLOST sqlserver.module_end( WHERE ([balíček0].[equal_uint64]([sqlserver].[id_relace],(74)))), PŘIDAT UDÁLOST sql_batchRE_completed l sql [balíček0].[equal_uint64]([sqlserver].[id_relace],(74)))), PŘIDAT UDÁLOST sqlserver.sql_batch_starting( WHERE ([balíček0].[equal_uint64]([server sql][id_relace],(7) ))), PŘIDAT UDÁLOST sqlserver.sql_statement_completed( WHERE ([balíček0].[equal_uint64]([sqlserver].[id_relace],(74)))), PŘIDAT UDÁLOST sqlserver.sql_statement_starting([4] balíček 0HEuREINT].[4] Walu_REINT ([sqlserver].[session_id],(74)))) S (TRACK_CAUSALITY=ON) GO
Jakmile jsem zahájil relaci události a otevřel prohlížeč Live Data Viewer v Management Studio, spustil jsem dva dotazy; jeden používá původní verzi funkce k doplnění nul do CurrencyRateID ve sloupci Sales.SalesOrderHeader tabulku a novou funkci pro vytvoření identického výstupu, ale pomocí RETURNS NULL ON NULL INPUT a zachytil jsem informace o skutečném plánu provádění pro srovnání.
SELECT SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) FROM Sales.SalesOrderHeader; GO SELECT SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) FROM Sales.SalesOrderHeader; GO
Kontrola dat Extended Events ukázala několik zajímavých věcí. Nejprve se původní funkce spustila 31 465krát (od počtu module_end události) a celkový čas CPU pro sql_statement_completed událost byla 204 ms s 482 ms trvání.
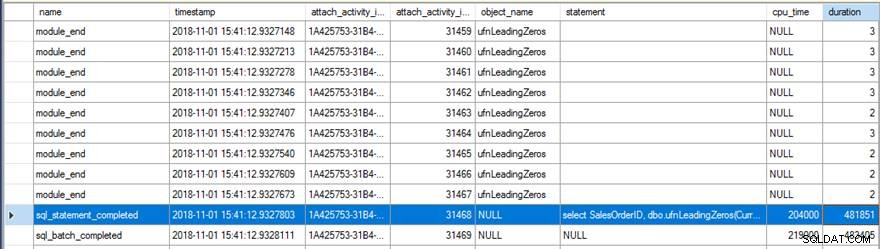
Nová verze s VRACÍ NULL NA NULL INPUT zadaná možnost se spustila pouze 13 976krát (opět od počtu module_end události) a čas CPU pro sql_statement_completed událost byla 78 ms s 359 ms trvání.

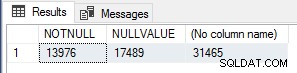
Přišlo mi to zajímavé, takže pro ověření počtu provedení jsem spustil následující dotaz na počet NOT NULL řádky hodnot, řádky s hodnotou NULL a řádky celkem v Sales.SalesOrderHeader tabulka.
VYBERTE SUM(CASE WHEN CurrencyRateID NENÍ NULL THEN 1 ELSE 0 END) AS NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULL END) AS NULL HEROM.
Tato čísla přesně odpovídají číslu module_end události pro každý z testů, takže toto je rozhodně velmi jednoduchá optimalizace výkonu pro skalární UDF, která by se měla použít, pokud víte, že výsledek funkce bude NULL, pokud jsou vstupní hodnoty NULL, ke zkratování/obejití provádění funkce výhradně pro tyto řádky.
Informace QueryTimeStats ve skutečných plánech provádění také odrážely nárůst výkonu:
Jedná se o poměrně významné snížení samotného CPU času, což může být pro některé systémy významným problémem.
Použití skalárních UDF je dobře známý návrhový anti-vzor pro výkon a existuje celá řada metod pro přepsání kódu, aby se zabránilo jejich použití a snížení výkonu. Ale pokud jsou již na svém místě a nelze je snadno změnit nebo odstranit, jednoduše znovu vytvořte UDF pomocí RETURNS NULL ON NULL INPUT Tato možnost by mohla být velmi jednoduchým způsobem, jak zvýšit výkon, pokud je v sadě dat, kde se používá UDF, mnoho vstupů NULL.