Vstup do výroby je velmi důležitý úkol, který je třeba předem pečlivě promyslet a naplánovat. Některá nepříliš dobrá rozhodnutí lze později snadno napravit, některá ne. Vždy je tedy lepší strávit čas navíc čtením oficiálních dokumentů, knih a výzkumů jiných lidí brzy, než později litovat. To platí pro většinu nasazení počítačových systémů a PostgreSQL není výjimkou.
Počáteční plánování systému
Některá rozhodnutí musí být přijata brzy, než se systém spustí. PostgreSQL DBA musí odpovědět na řadu otázek:Poběží DB na holém kovu, virtuálních počítačích nebo dokonce v kontejnerech? Poběží v prostorách organizace nebo v cloudu? Jaký OS bude použit? Bude úložiště typu rotujících disků nebo SSD? Pro každý scénář nebo rozhodnutí existují pro a proti a závěrečná výzva bude provedena ve spolupráci se zúčastněnými stranami podle požadavků organizace. Tradičně lidé používali PostgreSQL na holém kovu, ale to se v posledních letech dramaticky změnilo, protože stále více poskytovatelů cloudu nabízí PostgreSQL jako standardní možnost, což je známkou širokého přijetí a výsledkem rostoucí popularity PostgreSQL. Nezávisle na konkrétním řešení musí DBA zajistit, že data budou bezpečná, což znamená, že databáze bude schopna přežít pády, a to je kritérium č. 1 při rozhodování o hardwaru a úložišti. Takže toto nás přivádí k prvnímu tipu!
Tip 1
Bez ohledu na to, co inzeruje řadič disku nebo výrobce disku nebo poskytovatel cloudového úložiště, měli byste se vždy ujistit, že úložiště nelže o fsync. Jakmile se fsync vrátí v pořádku, data by měla být na médiu v bezpečí bez ohledu na to, co se stane poté (selhání, výpadek napájení atd.). Jeden pěkný nástroj, který vám pomůže otestovat spolehlivost mezipaměti pro zpětný zápis vašich disků, je diskchecker.pl.
Stačí si přečíst poznámky:https://brad.livejournal.com/2116715.html a udělat test.
Použijte jeden stroj k poslechu událostí a skutečný stroj k testování. Měli byste vidět:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0na konci zprávy o testovaném stroji.
Druhým problémem po spolehlivosti by měl být výkon. Rozhodnutí o systému (CPU, paměť) bývala mnohem důležitější, protože bylo docela těžké je později změnit. Ale v dnešní době cloudu můžeme být flexibilnější ohledně systémů, na kterých DB běží. Totéž platí pro skladování, zejména v rané fázi života systému a při stále malých velikostech. Když DB překročí velikost TB, pak je stále těžší a těžší změnit základní parametry úložiště bez nutnosti úplného kopírování databáze – nebo ještě hůře, provádět pg_dump, pg_restore. Druhý tip se týká výkonu systému.
Tip 2
Stejně jako vždy testujete sliby výrobců ohledně spolehlivosti, totéž byste měli dělat s výkonem hardwaru. Bonnie++ je nejoblíbenějším měřítkem výkonu úložiště pro systémy podobné Unixu. Pro celkové testování systému (CPU, paměť a také úložiště) není nic reprezentativnějšího než výkon DB. Základním testem výkonu na vašem novém systému by tedy bylo spuštění pgbench, oficiální sady benchmarků PostgreSQL založené na TCP-B.
Začít s pgbench je poměrně snadné, vše, co musíte udělat, je:
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$Po každé důležité změně, kterou chcete posoudit a porovnat výsledky, byste se měli vždy poradit s pgbench.
Nasazení systému, automatizace a monitorování
Jakmile spustíte provoz, je velmi důležité mít zdokumentované a reprodukovatelné hlavní součásti systému, mít automatizované postupy pro vytváření služeb a opakujících se úloh a také mít nástroje k provádění nepřetržitého monitorování.
Tip 3
Jedním z praktických způsobů, jak začít používat PostgreSQL se všemi jeho pokročilými podnikovými funkcemi, je ClusterControl od společnosti Somenines. Jeden může mít podnikový cluster PostgreSQL pouhým stisknutím několika kliknutí. ClusterControl poskytuje všechny výše uvedené služby a mnoho dalších. Nastavení ClusterControl je poměrně snadné, stačí postupovat podle pokynů v oficiální dokumentaci. Jakmile připravíte své systémy (typicky jeden pro spuštění CC a jeden pro PostgreSQL pro základní nastavení) a provedete nastavení SSH, musíte zadat základní parametry (IP adresy, čísla portů atd.), a pokud vše půjde dobře, měli byste viz výstup, jako je tento:
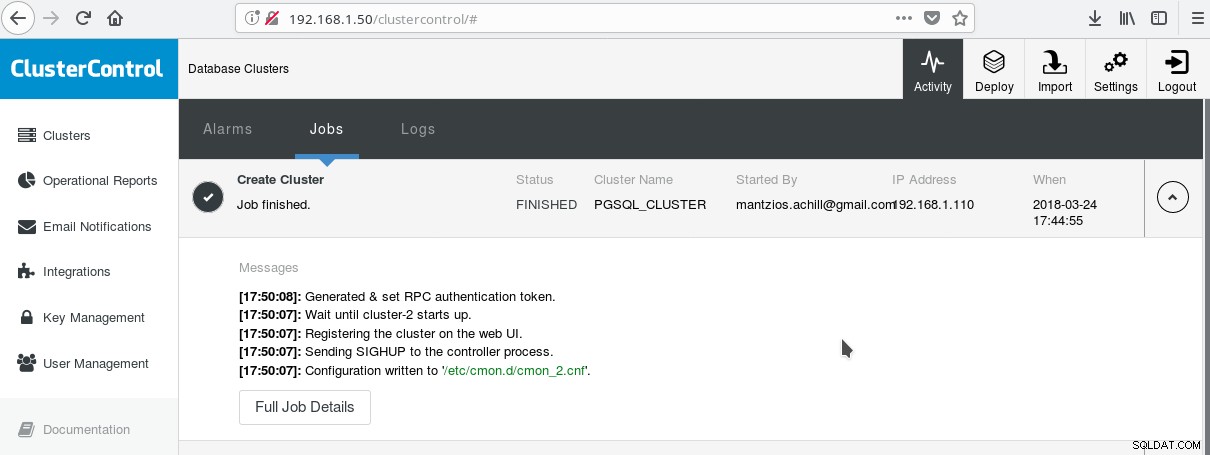
A na hlavní obrazovce clusterů:
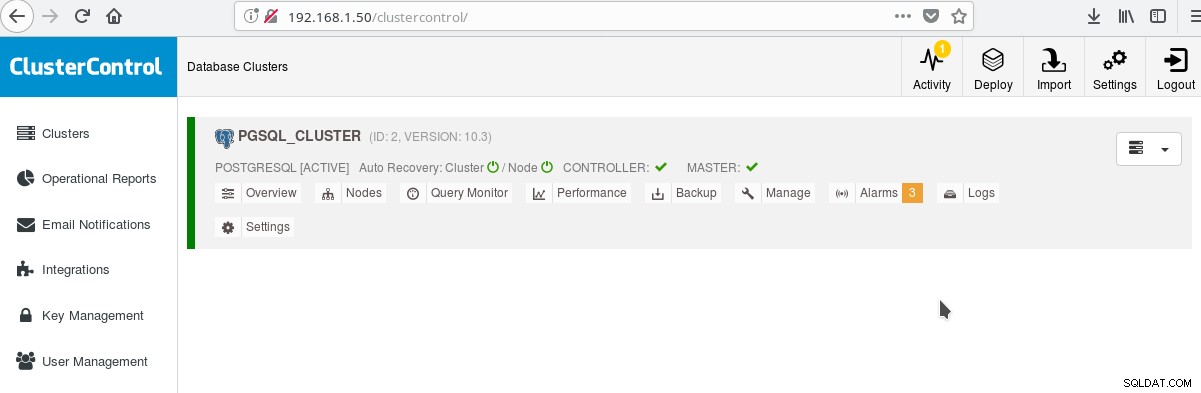
Můžete se přihlásit ke svému hlavnímu serveru a začít vytvářet schéma! Samozřejmě můžete použít jako základ právě vytvořený cluster pro další budování infrastruktury (topologie). Obecně dobrým nápadem je mít stabilní rozložení souborového systému serveru a konečnou konfiguraci na serveru PostgreSQL a databázích uživatelů/aplikací, než začnete vytvářet klony a pohotovostní režimy (slave) založené na právě vytvořeném zbrusu novém serveru.
Rozvržení, parametry a nastavení PostgreSQL
Ve fázi inicializace clusteru je nejdůležitější rozhodnutí, zda použít kontrolní součty dat na datových stránkách či nikoli. Pokud chcete maximální bezpečnost dat pro svá cenná (budoucí) data, pak je čas to udělat. Pokud existuje možnost, že byste tuto funkci mohli v budoucnu chtít a v této fázi ji zanedbáte, nebudete ji moci později změnit (bez pg_dump/pg_restore). Toto je další tip:
Tip 4
Chcete-li povolit kontrolní součty dat, spusťte initdb následovně:
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>Všimněte si, že by to mělo být provedeno v době tipu 3, který jsme popsali výše. Pokud jste již vytvořili cluster pomocí ClusterControl, budete muset znovu spustit pg_createcluster ručně, protože v době psaní tohoto článku neexistuje způsob, jak říci systému nebo CC, aby tuto možnost zahrnuli.
Dalším velmi důležitým krokem před zahájením výroby je plánování rozvržení souborového systému serveru. Většina moderních linuxových distribucí (alespoň těch založených na debianu) připojuje vše na /, ale s PostgreSQL to normálně nechcete. Je výhodné mít své tabulkové prostory na samostatných svazcích, mít jeden svazek vyhrazený pro soubory WAL a druhý pro pg log. Nejdůležitější je ale přesunout WAL na vlastní disk. Tím se dostáváme k dalšímu tipu.
Tip 5
S PostgreSQL 10 na Debian Stretch můžete přesunout svou WAL na nový disk pomocí následujících příkazů (za předpokladu, že nový disk se jmenuje /dev/sdb):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlJe nesmírně důležité správně nastavit národní prostředí a kódování databází. Přehlédněte to ve fázi createb a budete toho velmi litovat, protože se vaše aplikace/DB přesouvá do oblastí i18n, l10n. Následující tip ukazuje, jak to udělat.
Tip 6
Měli byste si přečíst oficiální dokumenty a rozhodnout se o nastavení COLLATE a CTYPE (createdb --locale=) (odpovědné za řazení a klasifikaci znaků) a také o nastavení znakové sady (createdb --encoding=). Zadáním UTF8 jako kódování umožníte databázi ukládat vícejazyčný text.
Stáhněte si Whitepaper Today Správa a automatizace PostgreSQL s ClusterControlZjistěte, co potřebujete vědět k nasazení, monitorování, správě a škálování PostgreSQLStáhněte si WhitepaperVysoká dostupnost PostgreSQL
Od PostgreSQL 9.0, kdy se streamingová replikace stala standardní funkcí, bylo možné mít jeden nebo více aktivních pohotovostních režimů pouze pro čtení, což umožnilo směrovat provoz pouze pro čtení na kterékoli z dostupných slave. Existují nové plány pro multimaster replikaci, ale v okamžiku tohoto psaní (10.3) je možné mít pouze jeden master pro čtení a zápis, alespoň v oficiálním open source produktu. Pro další tip, který se zabývá přesně tímto.
Tip 7
Použijeme náš ClusterControl PGSQL_CLUSTER vytvořený v Tipu 3. Nejprve vytvoříme druhý stroj, který bude fungovat jako náš slave pouze pro čtení (horký pohotovostní režim v terminologii PostgreSQL). Poté klikneme na Add Replication slave a vybereme našeho hlavního a nového slave. Po dokončení úlohy byste měli vidět tento výstup:
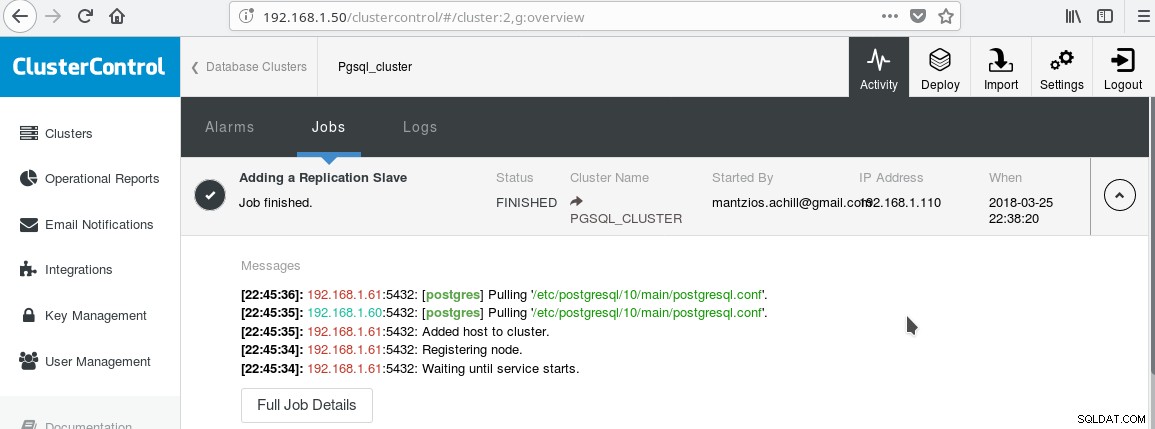
A cluster by nyní měl vypadat takto:
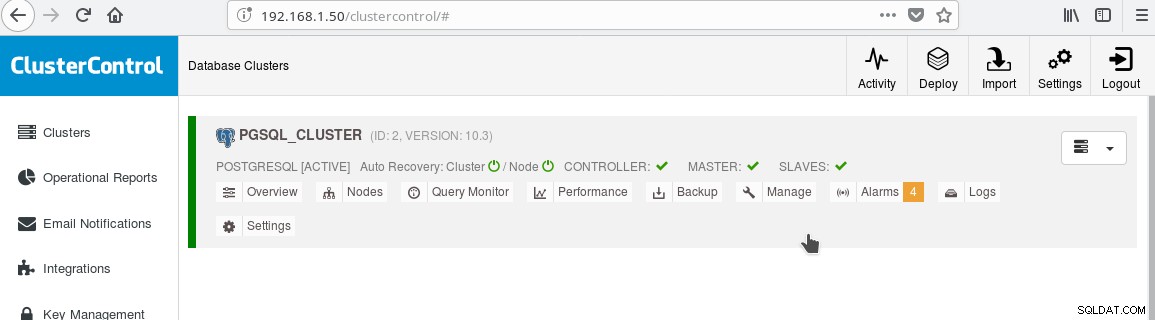
Všimněte si zelené „zaškrtnuté“ ikony na štítku „SLAVES“ vedle „MASTER“. Fungování streamingové replikace můžete ověřit vytvořením databázového objektu (databáze, tabulky atd.) nebo vložením několika řádků do tabulky na hlavním serveru a změnu uvidíte v pohotovostním režimu.
Přítomnost pohotovostního režimu pouze pro čtení nám umožňuje provádět vyvažování zátěže pro klienty, kteří provádějí pouze výběrové dotazy mezi dvěma dostupnými servery, hlavním a podřízeným. Tím se dostáváme k tipu 8.
Tip 8
Pomocí HAProxy můžete povolit vyvažování zátěže mezi dvěma servery. S ClusterControl je to docela snadné. Klikněte na Spravovat->Load Balancer. Po výběru vašeho HAProxy serveru vám ClusterControl nainstaluje vše:xinetd na všechny vámi zadané instance a HAProxy na váš určený server HAProxy. Po úspěšném dokončení úlohy byste měli vidět:
Všimněte si zeleného zaškrtnutí HAPROXY vedle SLAVES. Nyní můžete otestovat, že HAProxy funguje:
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#Tip 9
Kromě konfigurace pro HA a vyvažování zátěže je vždy výhodné mít před serverem PostgreSQL nějaký druh fondu připojení. Pgpool a Pgbouncer jsou dva projekty pocházející z komunity PostgreSQL. Mnoho podnikových aplikačních serverů také poskytuje své vlastní fondy. Pgbouncer je velmi oblíbený díky své jednoduchosti, rychlosti a funkci „transaction pooling“, díky které se po ukončení transakce uvolní připojení k serveru, takže je znovu použitelný pro následné transakce, které mohou pocházet ze stejné relace nebo jiné relace. . Nastavení sdružování transakcí narušuje některé funkce sdružování relací, ale obecně je převod na nastavení připravené pro „sdružování transakcí“ snadný a nevýhody nejsou v obecném případě tak důležité. Běžným nastavením je konfigurace fondu aplikačního serveru se semiperzistentními připojeními:Poněkud větší fond připojení na uživatele nebo na aplikaci (které se připojují k pgbouncer) s dlouhými časovými limity nečinnosti. Tímto způsobem je doba připojení z aplikace minimální, zatímco pgbouncer pomůže udržet připojení k serveru co nejméně.
Jedna věc, která bude s největší pravděpodobností znepokojovat, jakmile začnete pracovat s PostgreSQL, je porozumění a oprava pomalých dotazů. Monitorovací nástroje, které jsme zmínili v předchozím blogu, jako je pg_stat_statements, a také obrazovky nástrojů jako ClusterControl vám pomohou identifikovat a případně navrhnout nápady na opravu pomalých dotazů. Jakmile však identifikujete pomalý dotaz, budete muset spustit EXPLAIN nebo EXPLAIN ANALYZE, abyste přesně viděli náklady a časy zahrnuté v plánu dotazů. Další tip je o velmi užitečném nástroji, jak toho dosáhnout.
Tip 10
Musíte spustit EXPLAIN ANALYZE ve své databázi a poté zkopírovat výstup a vložit jej do online nástroje pro analýzu vysvětlení depesz a kliknout na Odeslat. Poté uvidíte tři karty:HTML, TEXT a STATS. HTML obsahuje cenu, čas a počet smyček pro každý uzel v plánu. Karta STATS zobrazuje statistiky podle typu uzlu. Měli byste sledovat sloupec „% dotazu“, abyste věděli, kde přesně váš dotaz trpí.
Jak se blíže seznámíte s PostgreSQL, najdete mnoho dalších tipů sami!