Existuje několik metod, jak se podívat na špatně fungující dotazy na SQL Server, zejména Query Store, Extended Events a dynamická řízení zobrazení (DMV). Každá možnost má klady a zápory. Extended Events poskytuje data o jednotlivých provedeních dotazů, zatímco Query Store a DMV agregují data o výkonu. Abyste mohli používat Query Store a Extended Events, musíte je předem nakonfigurovat – buď povolit Query Store pro vaši databázi (databáze), nebo nastavit relaci XE a spustit ji. Data DMV jsou vždy k dispozici, takže velmi často je to nejjednodušší způsob, jak rychle získat první pohled na výkon dotazů. Zde se Glennovy dotazy DMV hodí – ve svém skriptu má několik dotazů, které můžete použít k nalezení nejlepších dotazů pro instanci na základě CPU, logického I/O a trvání. Zacílení na dotazy s nejvyšší spotřebou zdrojů je často dobrým začátkem při odstraňování problémů, ale nemůžeme zapomenout na scénář „smrt tisíci řezy“ – dotaz nebo sadu dotazů, které se spouštějí VELMI často – možná stokrát nebo tisíckrát za minuta. Glenn má ve své sadě dotaz, který uvádí hlavní dotazy pro databázi na základě počtu provedení, ale podle mých zkušeností vám neposkytne úplný obrázek o vaší pracovní zátěži.
Hlavní DMV, který se používá k prohlížení metrik výkonu dotazů, je sys.dm_exec_query_stats. K dispozici jsou také další data specifická pro uložené procedury (sys.dm_exec_procedure_stats), funkce (sys.dm_exec_function_stats) a spouštěče (sys.dm_exec_trigger_stats), ale zvažte zátěž, kterou nejsou čistě uložené procedury, funkce a spouštěče. Zvažte smíšenou zátěž, která má nějaké dotazy ad hoc, nebo je možná zcela ad hoc.
Příklad scénáře
Vypůjčením a úpravou kódu z předchozího příspěvku Zkoumání dopadu na výkon adhoc zátěže nejprve vytvoříme dvě uložené procedury. První, dbo.RandomSelects, generuje a provádí příkaz ad hoc, a druhý, dbo.SPRandomSelects, generuje a provádí parametrizovaný dotaz.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Nyní provedeme obě uložené procedury 1000krát pomocí stejné metody popsané v mém předchozím příspěvku se soubory .cmd volajícími soubory .sql s následujícími příkazy:
Obsah souboru Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Obsah souboru Parameterized.sql:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Příklad syntaxe v souboru .cmd, který volá soubor .sql:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Pokud použijeme variaci dotazu Glenn's Top Worker Time, abychom se podívali na nejčastější dotazy na základě času pracovníka (CPU):
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
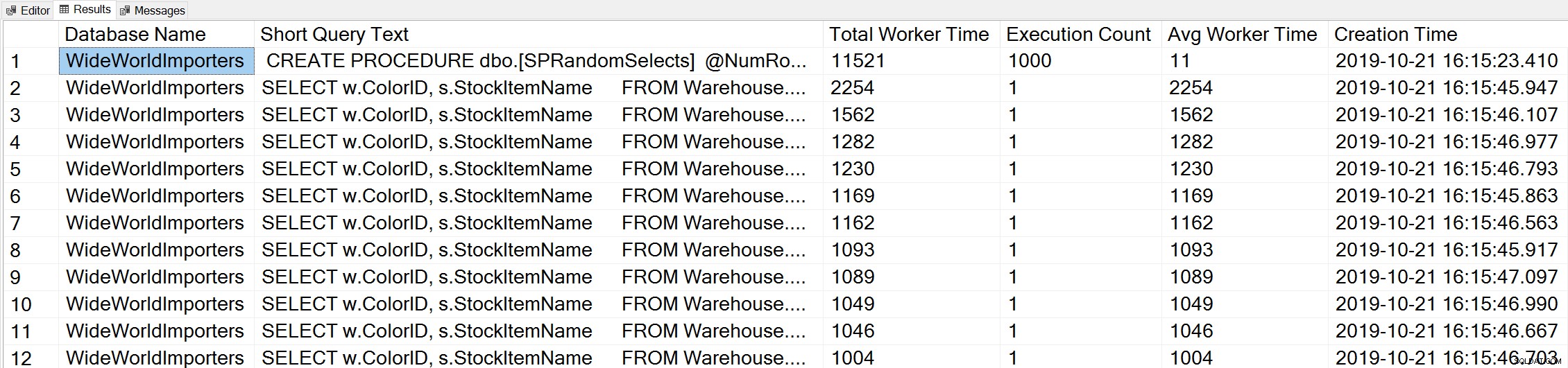
Vidíme příkaz z naší uložené procedury jako dotaz, který se provádí s nejvyšším množstvím kumulativního CPU.
Pokud spustíme variaci dotazu Glenn's Query Execution Counts proti databázi WideWorldImporters:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
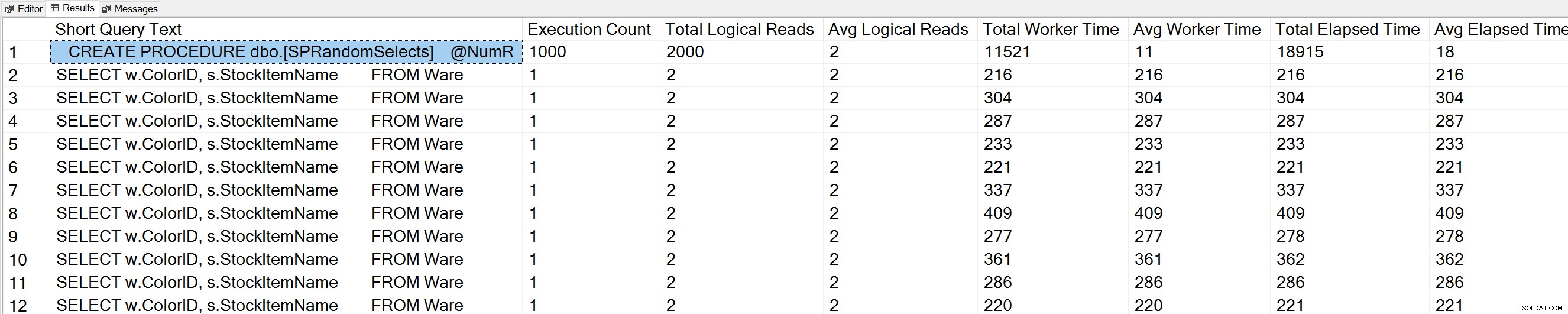
Náš příkaz uložené procedury také vidíme na začátku seznamu.
Ale ad hoc dotaz, který jsme provedli, i když má různé doslovné hodnoty, byl v podstatě stejný jak můžeme vidět při pohledu na query_hash:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
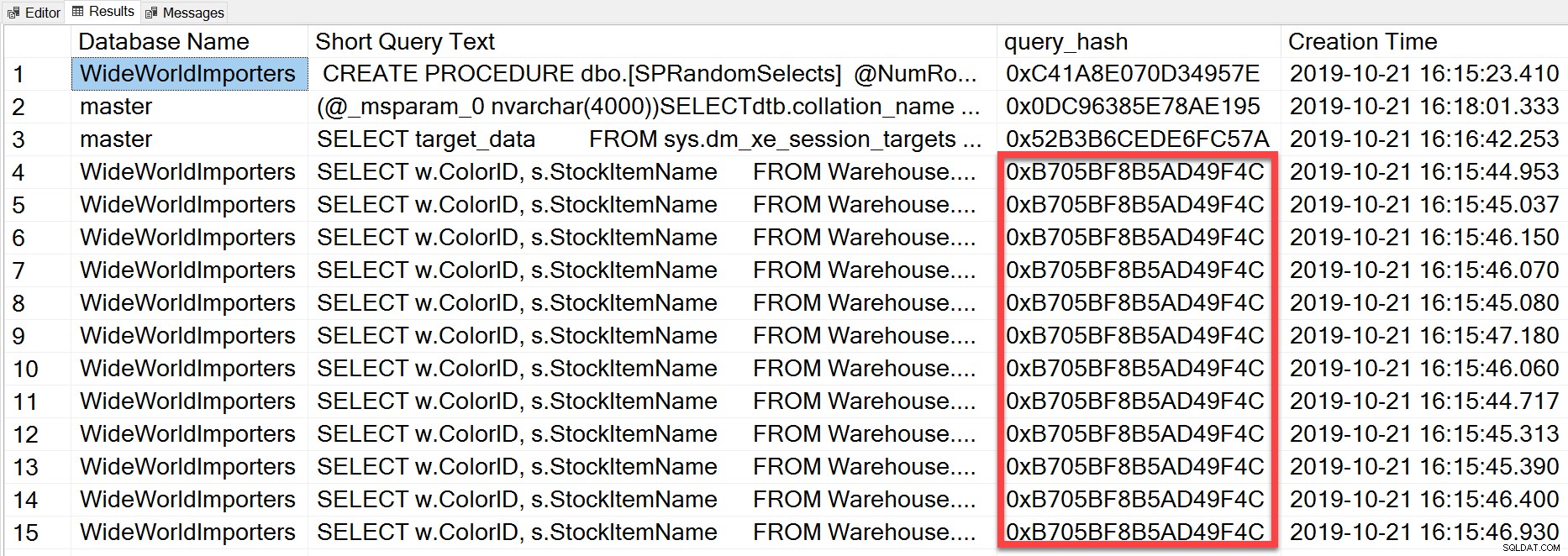
Query_hash byl přidán do SQL Server 2008 a je založen na stromu logických operátorů generovaných nástrojem Query Optimizer pro text příkazu. Dotazy, které mají podobný text příkazu, který generuje stejný strom logických operátorů, budou mít stejný dotaz_hash, i když se doslovné hodnoty v predikátu dotazu liší. Zatímco doslovné hodnoty se mohou lišit, objekty a jejich aliasy musí být stejné, stejně jako tipy pro dotazy a případně možnosti SET. Uložená procedura RandomSelects generuje dotazy s různými doslovnými hodnotami:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Ale každé provedení má přesně stejnou hodnotu pro query_hash, 0xB705BF8B5AD49F4C. Abychom pochopili, jak často se dotaz ad hoc – a ty, které jsou stejné z hlediska query_hash – spouští, musíme seskupit podle pořadí query_hash podle tohoto počtu, spíše než se dívat na execute_count v sys.dm_exec_query_stats (který často zobrazuje hodnota 1).
Pokud změníme kontext na databázi WideWorldImporters a hledáme nejlepší dotazy na základě počtu provedení, kde seskupujeme podle query_hash, můžeme nyní vidět jak uloženou proceduru , tak náš dotaz ad hoc:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

Poznámka:sys.dm_exec_function_stats DMV byl přidán do SQL Server 2016. Spuštění tohoto dotazu na SQL Server 2014 a dřívějších vyžaduje odstranění odkazu na tento DMV.
Tento výstup poskytuje mnohem komplexnější pochopení toho, jaké dotazy se skutečně provádějí nejčastěji, protože se agreguje na základě query_hash, nikoli pouhým pohledem na execute_count v sys.dm_exec_query_stats, který může mít více položek pro stejný query_hash, když jsou různé hodnoty literálu použitý. Výstup dotazu také obsahuje query_plan_hash, který se může lišit pro dotazy se stejným query_hash. Tyto dodatečné informace jsou užitečné při vyhodnocování výkonu plánu pro dotaz. Ve výše uvedeném příkladu má každý dotaz stejný query_plan_hash, 0x299275DD475C4B17, což dokazuje, že i s různými vstupními hodnotami generuje Query Optimizer stejný plán – je stabilní. Pokud existuje více hodnot query_plan_hash pro stejný query_hash, existuje variabilita plánu. Ve scénáři, kde se stejný dotaz na základě query_hash provede tisíckrát, je obecným doporučením parametrizovat dotaz. Pokud můžete ověřit, že neexistuje žádná variabilita plánu, pak parametrizace dotazu odebere čas optimalizace a kompilace pro každé provedení a může snížit celkové CPU. V některých scénářích může parametrizace pěti až 10 ad hoc dotazů zlepšit výkon systému jako celku.
Shrnutí
Pro každé prostředí je důležité pochopit, jaké dotazy jsou nejdražší z hlediska využití zdrojů a jaké dotazy se spouštějí nejčastěji. Stejná sada dotazů se může zobrazit pro oba typy analýzy při použití Glennova skriptu DMV, což může být zavádějící. Proto je důležité určit, zda je pracovní zátěž většinou procedurální, většinou ad hoc, nebo smíšená. I když je mnoho zdokumentováno o výhodách uložených procedur, zjistil jsem, že smíšené nebo vysoce ad hoc pracovní zátěže jsou velmi běžné, zejména u řešení, která používají objektově relační mapovače (ORM), jako je Entity Framework, NHibernate a LINQ to SQL. Pokud si nejste jisti typem zátěže pro server, spuštěním výše uvedeného dotazu se podívejte na nejčastěji prováděné dotazy na základě query_hash. Jakmile začnete chápat pracovní vytížení a to, co existuje jak pro těžké hitters, tak pro dotazy na smrt tisícem řezů, můžete přejít ke skutečnému pochopení využití zdrojů a dopadu těchto dotazů na výkon systému a zaměřit své úsilí na ladění.