SQL Server zavedl objekty In-Memory OLTP v SQL Server 2014. V původní verzi bylo mnoho omezení; některé byly řešeny v SQL Server 2016 a očekává se, že další budou řešeny v příštím vydání, protože funkce se neustále vyvíjí. Zatím se přijetí In-Memory OLTP nezdá příliš rozšířené, ale jak tato funkce dozrává, očekávám, že se více klientů začne ptát na implementaci. Jako u každé větší změny schématu nebo kódu doporučuji důkladné testování, abyste zjistili, zda In-Memory OLTP poskytne očekávané výhody. S ohledem na to mě zajímalo, jak se změnil výkon velmi jednoduchých příkazů INSERT, UPDATE a DELETE pomocí In-Memory OLTP. Doufal jsem, že pokud se mi podaří prokázat latching nebo locking jako problém s diskovými tabulkami, pak tabulky v paměti poskytnou řešení, protože jsou bez zámku a latch-free.
Vyvinul jsem následující test případy:
- Disková tabulka s tradičními uloženými procedurami pro DML.
- Tabulka v paměti s tradičními uloženými procedurami pro DML.
- Tabulka v paměti s nativně zkompilovanými procedurami pro DML.
Zajímalo mě srovnání výkonu tradičních uložených procedur a nativně kompilovaných procedur, protože jedním omezením nativně kompilované procedury je, že všechny odkazované tabulky musí být In-Memory. Zatímco jednořádkové, osamocené úpravy mohou být v některých systémech běžné, často vidím, že k úpravám dochází v rámci větší uložené procedury s více příkazy (SELECT a DML), které přistupují k jedné nebo více tabulkám. Dokumentace In-Memory OLTP důrazně doporučuje používat nativně kompilované procedury, abyste dosáhli co nejvyššího výkonu z hlediska výkonu. Chtěl jsem pochopit, jak moc to zlepšilo výkon.
Nastavení
Vytvořil jsem databázi se skupinou souborů optimalizovanou pro paměť a poté v databázi vytvořil tři různé tabulky (jednu na disku, dvě v paměti):
- DiskTable
- InMemory_Temp1
- InMemory_Temp2
DDL byl téměř stejný pro všechny objekty, kde to bylo vhodné, zohledňovalo to na disku a v paměti. DiskTable DDL vs. DDL v paměti:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
Vytvořil jsem také devět uložených procedur – jednu pro každou kombinaci tabulky/úpravy.
- DiskTable_Insert
- DiskTable_Update
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Update
- InMemRegularSP _Delete
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
Každá uložená procedura přijala celočíselný vstup do smyčky pro tento počet úprav. Uložené procedury měly stejný formát, variace byly pouze tabulka, ke které se přistupovalo, a to, zda byl objekt nativně zkompilován nebo ne. Kompletní kód pro vytvoření databáze a objektů lze nalézt zde , s příklady příkazů INSERT a UPDATE níže:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Poznámka:Tabulky IDs_* byly znovu vyplněny po dokončení každé sady INSERTů a byly specifické pro tři různé scénáře.
Metodika testování
Testování bylo provedeno pomocí skriptů .cmd, které používaly sqlcmd k volání skriptu, který provedl uloženou proceduru, například:
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"ukončit
Tento přístup jsem použil k vytvoření jednoho nebo více připojení k databázi, která by běžela souběžně. Kromě porozumění základním změnám ve výkonu jsem chtěl také prozkoumat vliv různé zátěže. Tyto skripty byly spouštěny ze samostatného počítače, aby se eliminovala režie instancí připojení. Každá uložená procedura byla provedena 1000krát připojením a testoval jsem 1 připojení, 10 připojení a 100 připojení (1000, 10000 a 100000 modifikací). Zachytil jsem metriky výkonu pomocí Query Store a také jsem zachytil statistiku čekání. S Query Store jsem mohl zachytit průměrnou dobu trvání a CPU pro každou uloženou proceduru. Data statistiky čekání byla zachycena pro každé připojení pomocí dm_exec_session_wait_stats a poté agregována pro celý test.
Každý test jsem provedl čtyřikrát a poté jsem vypočítal celkové průměry pro data použitá v tomto příspěvku. Skripty používané pro testování zátěže si můžete stáhnout zde.
Výsledky
Jak by se dalo předpokládat, výkon s objekty In-Memory byl lepší než s objekty na disku. Tabulka In-Memory s běžnou uloženou procedurou však měla někdy srovnatelný nebo jen mírně lepší výkon ve srovnání s tabulkou na disku s běžnou uloženou procedurou. Pamatujte:Zajímalo mě, zda skutečně potřebuji zkompilovanou uloženou proceduru, abych získal velkou výhodu s tabulkou v paměti. Pro tento scénář jsem to udělal. Ve všech případech měla in-memory tabulka s nativně kompilovanou procedurou výrazně lepší výkon. Dva níže uvedené grafy znázorňují stejná data, ale s různými měřítky pro osu x, aby se demonstrovalo, že výkon pro běžné uložené procedury, které upravují data, se zhoršil s více souběžnými připojeními.
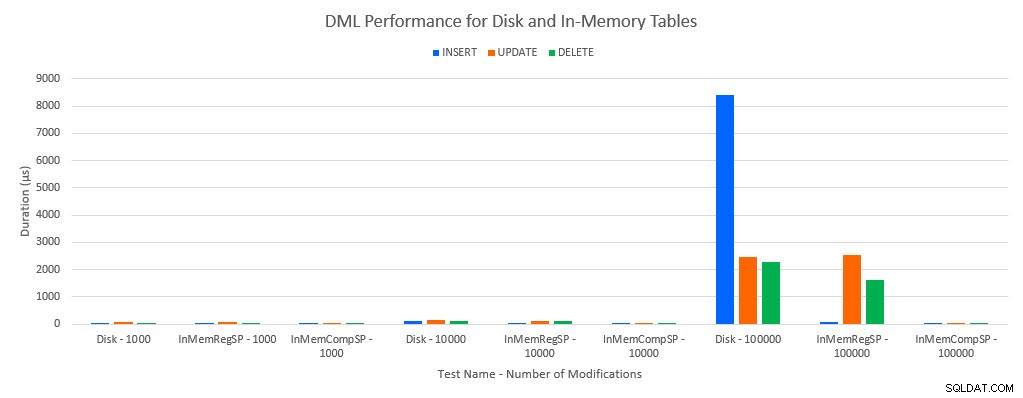
Výkon DML podle testu a zátěže
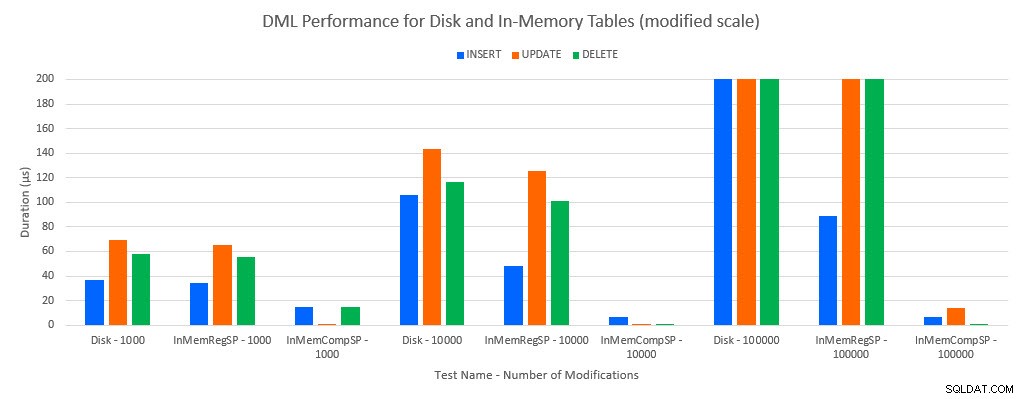
Výkon DML podle testu a pracovní zátěže [upravené měřítko]
Výjimkou jsou INSERTy do tabulky In-Memory s běžnou uloženou procedurou. Se 100 připojeními je průměrná doba trvání přes 8 ms pro tabulku na disku, ale méně než 100 mikrosekund pro tabulku In-Memory. Pravděpodobným důvodem je absence zamykání a blokování s tabulkou In-Memory, což je podporováno daty statistiky čekání:
| Test | INSERT | AKTUALIZACE | SMAZAT |
|---|---|---|---|
| Tabulka disků – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 1000 | WRITELOG | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| Tabulka disků – 10 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 10 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 10 000 | WRITELOG | WRITELOG | MEMORY_ALLOCATION_EXT |
| Tabulka disků – 100 000 | PAGELATCH_EX | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 100 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 100 000 | WRITELOG | WRITELOG | WRITELOG |
Statistika čekání na test
Údaje statistiky čekání jsou zde uvedeny na základě celkové doby čekání na zdroje (což se obecně také převádí na nejvyšší průměrnou dobu trvání zdroje, ale existovaly výjimky). Typ čekání WRITELOG je v tomto systému většinou limitujícím faktorem. PAGELATCH_EX však čeká na 100 souběžných připojení se spuštěnými příkazy INSERT, což naznačuje, že s dalším zatížením může být omezujícím faktorem chování zamykání a blokování, které existuje u tabulek na disku. Ve scénářích UPDATE a DELETE s 10 a 100 připojeními pro testy diskové tabulky byla průměrná doba čekání na prostředky nejvyšší pro zámky (LCK_M_X).
Závěr
In-Memory OLTP může absolutně poskytnout zvýšení výkonu pro správnou pracovní zátěž. Zde testované příklady jsou však extrémně jednoduché a neměly by být posuzovány pouze jako důvod k migraci na řešení In-Memory. Stále existuje několik omezení, která je třeba vzít v úvahu, a před provedením migrace je nutné provést důkladné testování (zejména proto, že migrace do tabulky In-Memory je offline proces). Ale pro správný scénář může tato nová funkce poskytnout zvýšení výkonu. Pokud chápete, že některá základní omezení budou stále existovat, jako je rychlost protokolu transakcí u odolných tabulek, i když s největší pravděpodobností omezeným způsobem – bez ohledu na to, zda tabulka existuje na disku nebo v paměti.