Začátkem tohoto týdne jsem zveřejnil reakci na svůj nedávný příspěvek o STRING_SPLIT() v SQL Server 2016, řešení několika komentářů zanechaných u příspěvku a/nebo zaslaných přímo mně:
STRING_SPLIT()v SQL Server 2016:Následná akce č. 1
Poté, co byl tento příspěvek většinou napsán, přišla nejnovější otázka od Douga Ellnera:
Jak se tyto funkce porovnávají s parametry s hodnotou tabulky?
Nyní bylo testování TVP již na mém seznamu budoucích projektů, po nedávné výměně Twitteru s @Nick_Craver na Stack Overflow. Řekl, že jsou nadšeni, že STRING_SPLIT() fungovaly dobře, protože nebyli spokojeni s výkonem odesílání ~7 000 hodnot prostřednictvím parametru s hodnotou tabulky.
Moje testy
Pro tyto testy jsem použil SQL Server 2016 RC3 (13.0.1400.361) na 8jádrovém virtuálním počítači s Windows 10, s úložištěm PCIe a 32 GB RAM.
Vytvořil jsem jednoduchou tabulku, která napodobovala to, co dělali (vybral jsem asi 10 000 hodnot z tabulky více než 3 milionů řádkových příspěvků), ale pro mé testy má mnohem méně sloupců a méně indexů:
CREATE TABLE dbo.Posts_Regular( PostID int PRIMARY KEY, HitCount int NOT NULL DEFAULT 0); INSERT dbo.Posts_Regular(PostID) SELECT TOP (3000000) ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2;
Vytvořil jsem také In-Memory verzi, protože jsem byl zvědavý, jestli tam bude nějaký přístup fungovat jinak:
CREATE TABLE dbo.Posts_InMemory( PostID int PRIMARY KEY NENCLUSTERED HASH WITH (BUCKET_COUNT =4000000), HitCount int NOT NULL DEFAULT 0) WITH (MEMORY_OPTIMIZED =ON);
Nyní jsem chtěl vytvořit aplikaci C#, která by předávala 10 000 jedinečných hodnot, buď jako řetězec oddělený čárkami (vytvořený pomocí StringBuilderu) nebo jako TVP (předaný z DataTable). Cílem by bylo načíst nebo aktualizovat výběr řádků na základě shody, buď s prvkem vytvořeným rozdělením seznamu, nebo s explicitní hodnotou v TVP. Kód byl napsán tak, aby připojil každou 300. hodnotu k řetězci nebo DataTable (kód C# je v příloze níže). Vzal jsem funkce, které jsem vytvořil v původním příspěvku, upravil je tak, aby zpracovávaly varchar(max) a poté přidal dvě funkce, které akceptovaly TVP – jedna z nich je optimalizovaná pro paměť. Zde jsou typy tabulek (funkce jsou v příloze níže):
CREATE TYPE dbo.PostIDs_Regular AS TABLE(PostID int PRIMARY KEY);GO CREATE TYPE dbo.PostIDs_InMemory AS TABLE( PostID int NOT NULL PRIMARY KEY NENCLUSTERED HASH WITH (BUCKET_COUNT =10000000)MI /před>Také jsem musel zvětšit tabulku Numbers, aby zvládl řetězce> 8K a s> 8K prvky (udělal jsem to na 1MM řádky). Potom jsem vytvořil sedm uložených procedur:pět z nich má
varchar(max)a spojení s výstupem funkce za účelem aktualizace základní tabulky a poté dva pro přijetí TVP a spojení přímo proti němu. Kód C# volá každou z těchto sedmi procedur se seznamem 10 000 příspěvků k výběru nebo aktualizaci 1 000krát. Tyto postupy jsou také v příloze níže. Takže jen pro shrnutí, testované metody jsou:
- Nativní (
STRING_SPLIT()) - XML
- CLR
- Tabulka čísel
- JSON (s explicitním
intvýstup) - Parametr s hodnotou tabulky
- Parametr s hodnotou tabulky optimalizovaný pro paměť
Vyzkoušíme načtení 10 000 hodnot 1 000krát pomocí DataReaderu – ale ne iteraci přes DataReader, protože by to jen prodloužilo test a bylo by to stejné množství práce pro aplikaci C# bez ohledu na to, jak databáze sestavu vyrobil. Vyzkoušíme také aktualizaci 10 000 řádků, každý 1 000krát, pomocí ExecuteNonQuery() . A budeme testovat s běžnou i paměťově optimalizovanou verzí tabulky Příspěvky, kterou můžeme velmi snadno přepínat, aniž bychom museli měnit některou z funkcí nebo procedur, za použití synonyma:
VYTVOŘIT SYNONYM dbo.Posts FOR dbo.Posts_Regular; -- pro otestování verze optimalizované pro paměť:DROP SYNONYM dbo.Posts;VYTVOŘTE SYNONYM dbo.Posts FOR dbo.Posts_InMemory; -- pro opětovné otestování diskové verze:DROP SYNONYM dbo.Posts;CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;
Spustil jsem aplikaci, spustil jsem ji několikrát pro každou kombinaci, abych zajistil, že kompilace, ukládání do mezipaměti a další faktory nejsou nespravedlivé vůči nejprve provedené dávce, a poté jsem analyzoval výsledky z tabulky protokolování (také jsem namátkově zkontroloval sys. dm_exec_procedure_stats, abyste se ujistili, že žádný z přístupů nemá významnou režii založenou na aplikacích, a to ani neměly).
Výsledky – tabulky založené na disku
Někdy se potýkám s vizualizací dat – opravdu jsem se snažil přijít na způsob, jak tyto metriky znázornit na jediném grafu, ale myslím, že tam bylo příliš mnoho datových bodů, než aby ty nejvýraznější vynikly.
Kliknutím na kteroukoli z nich můžete zvětšit na nové kartě/okně, ale i když máte malé okno, snažil jsem se, aby byl vítěz jasný pomocí barvy (a vítěz byl ve všech případech stejný). A aby bylo jasno, "průměrnou dobou trvání" mám na mysli průměrnou dobu, kterou aplikaci trvalo dokončení smyčky 1 000 operací.
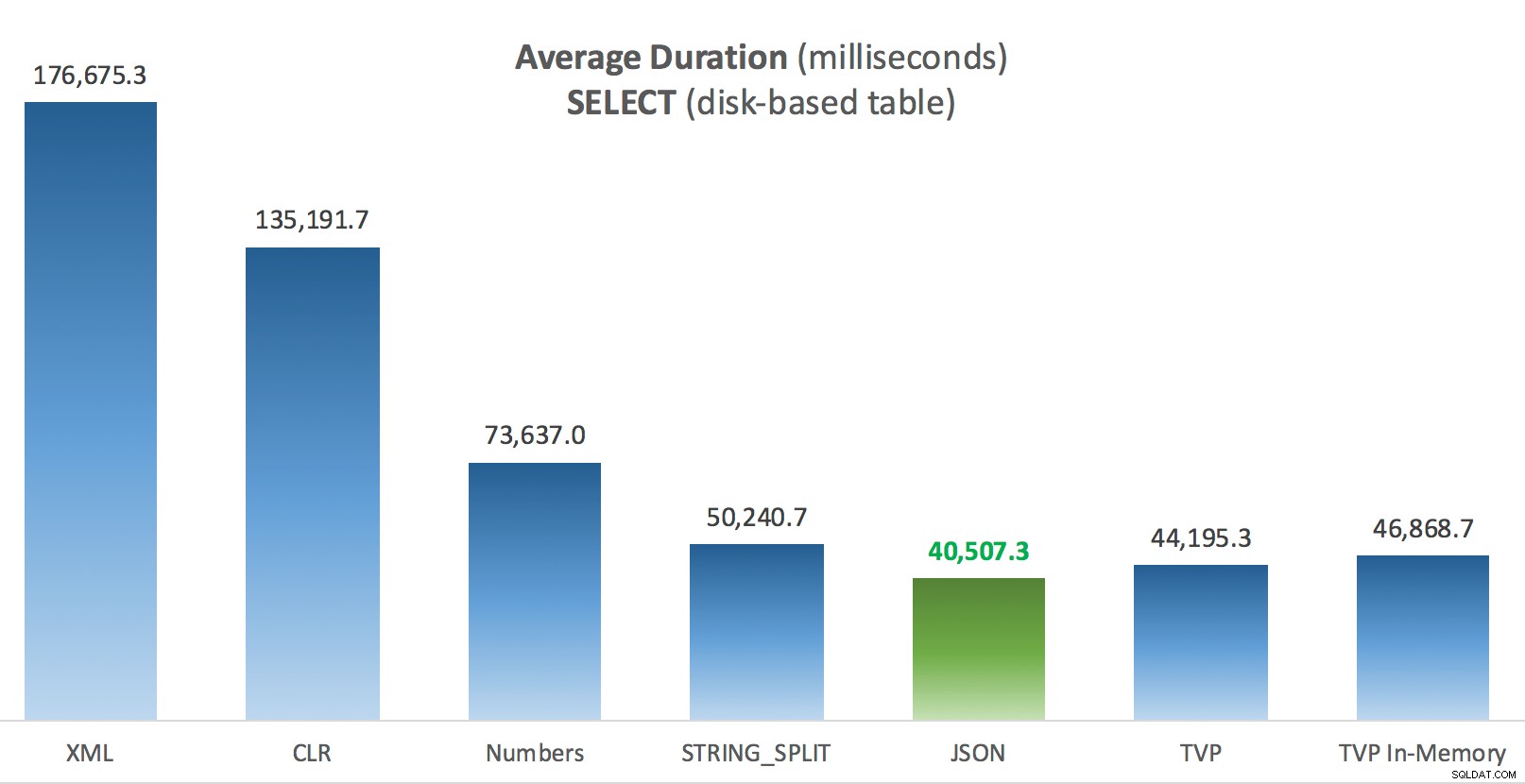 Průměrná doba trvání (milisekundy) pro SELECTy oproti tabulce příspěvků na disku
Průměrná doba trvání (milisekundy) pro SELECTy oproti tabulce příspěvků na disku
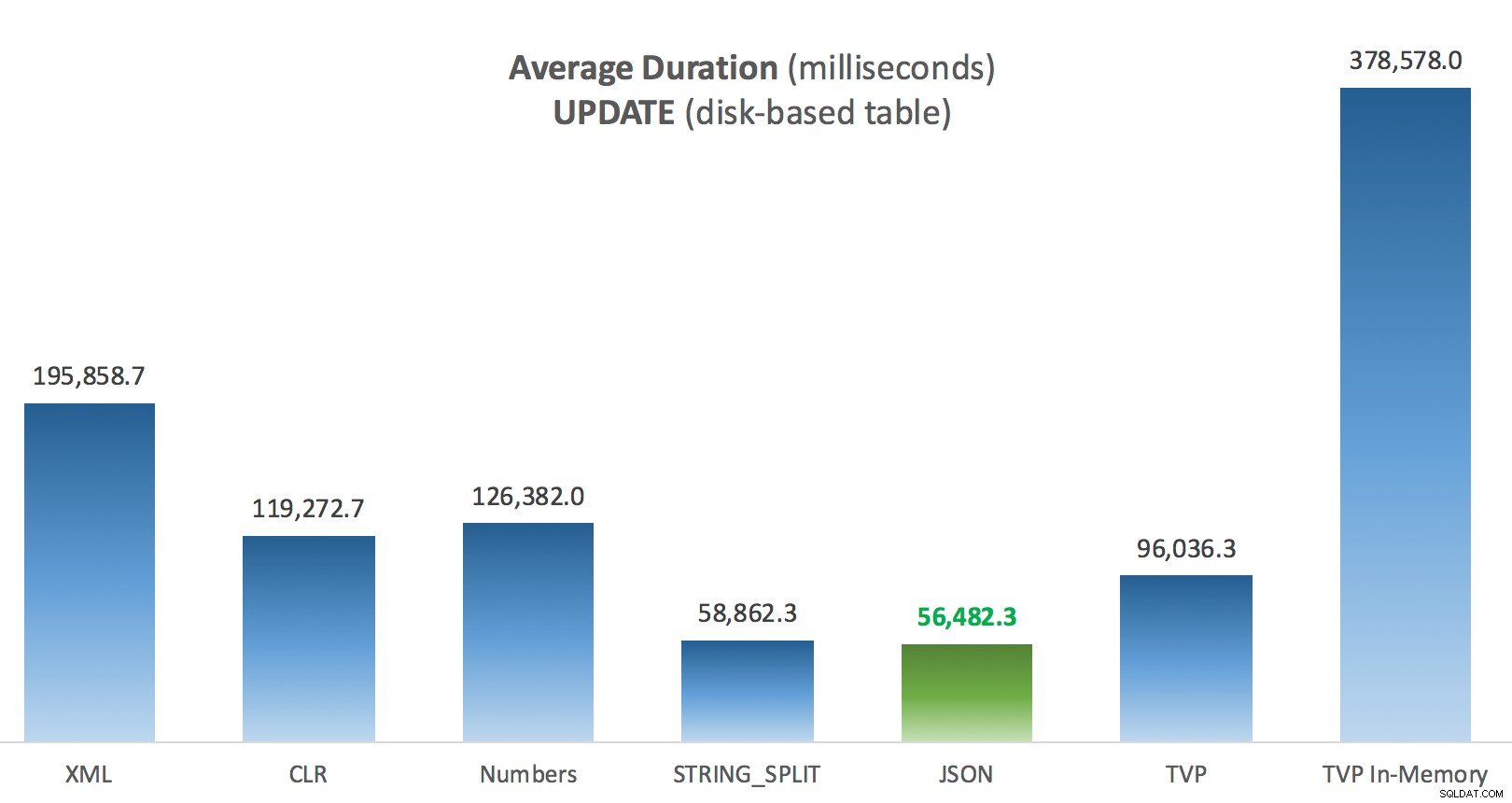 Průměrná doba trvání (milisekundy) pro AKTUALIZACE oproti tabulce příspěvků na disku
Průměrná doba trvání (milisekundy) pro AKTUALIZACE oproti tabulce příspěvků na disku
Nejzajímavější věcí zde pro mě je, jak špatně si TVP s optimalizovanou pamětí vedl při pomoci s UPDATE . Ukazuje se, že paralelní skenování je v současnosti blokováno příliš agresivně, když je zapojeno DML; Microsoft to rozpoznal jako nedostatek funkcí a doufá, že to brzy vyřeší. Všimněte si, že paralelní skenování je aktuálně možné pomocí SELECT ale právě teď je blokován pro DML. (Nebude to vyřešeno v SQL Server 2014, protože tyto specifické operace paralelního skenování tam nejsou k dispozici pro žádnou operaci.) Když je to opraveno nebo když jsou vaše TVP menší a/nebo paralelismus stejně není prospěšný, měli byste vidět že paměťově optimalizované TVP budou fungovat lépe (vzor prostě nefunguje dobře pro tento konkrétní případ použití relativně velkých TVP).
Pro tento konkrétní případ jsou zde plány pro SELECT (které jsem mohl přinutit jít paralelně) a UPDATE (což jsem nemohl):
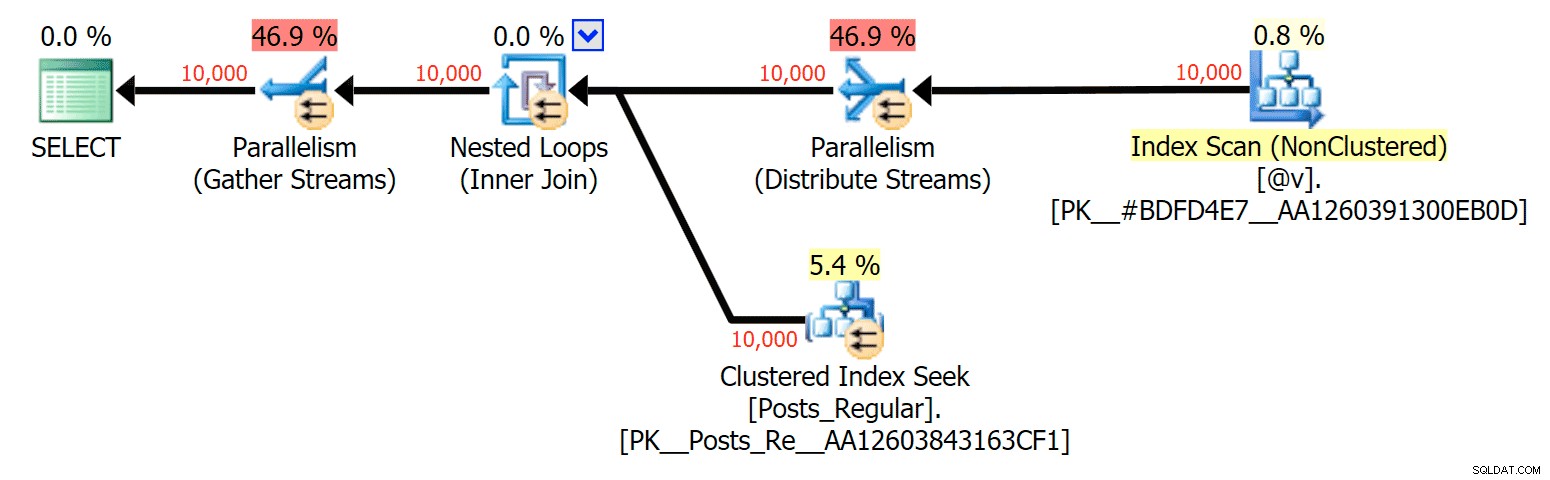 Paralelismus v plánu SELECT spojující diskovou tabulku s TVP v paměti
Paralelismus v plánu SELECT spojující diskovou tabulku s TVP v paměti
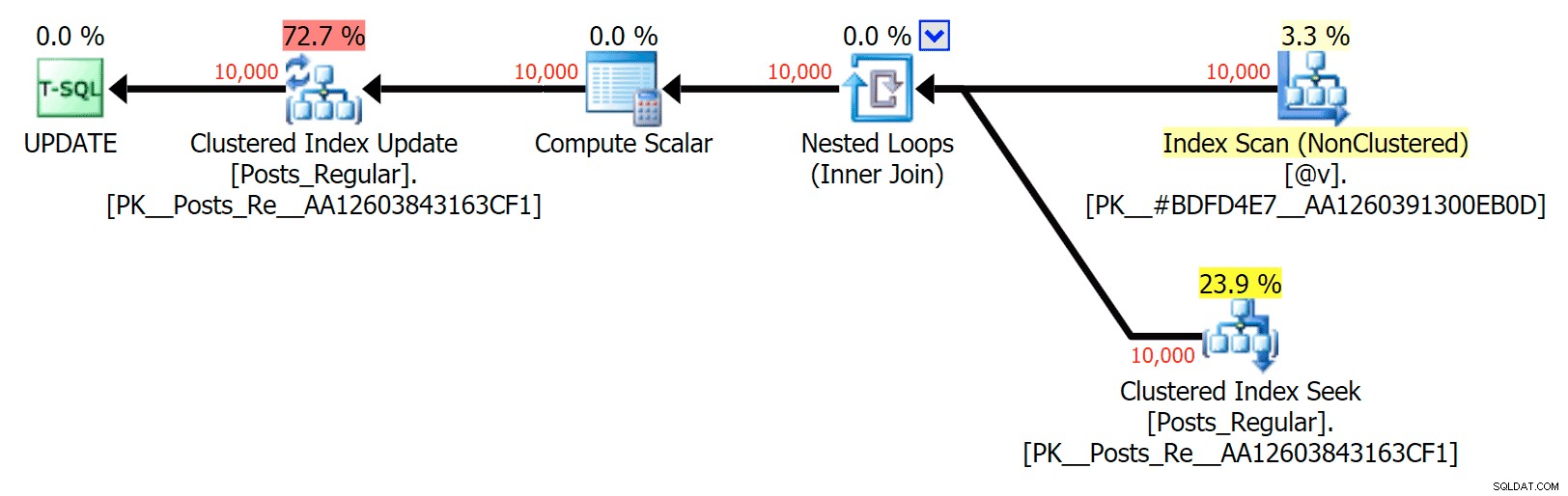 Žádný paralelismus v plánu UPDATE spojující diskovou tabulku s in-memory TVP
Žádný paralelismus v plánu UPDATE spojující diskovou tabulku s in-memory TVP
Výsledky – Tabulky optimalizované pro paměť
Trochu více konzistence – čtyři způsoby vpravo jsou relativně vyrovnané, zatímco tři vlevo se zdají naopak velmi nežádoucí. Zvláštní pozornost věnujte také absolutnímu měřítku ve srovnání s tabulkami na disku – většinou pomocí stejných metod a dokonce i bez paralelismu skončíte s mnohem rychlejšími operacemi proti tabulkám optimalizovaným pro paměť, což vede k nižšímu celkovému využití procesoru.
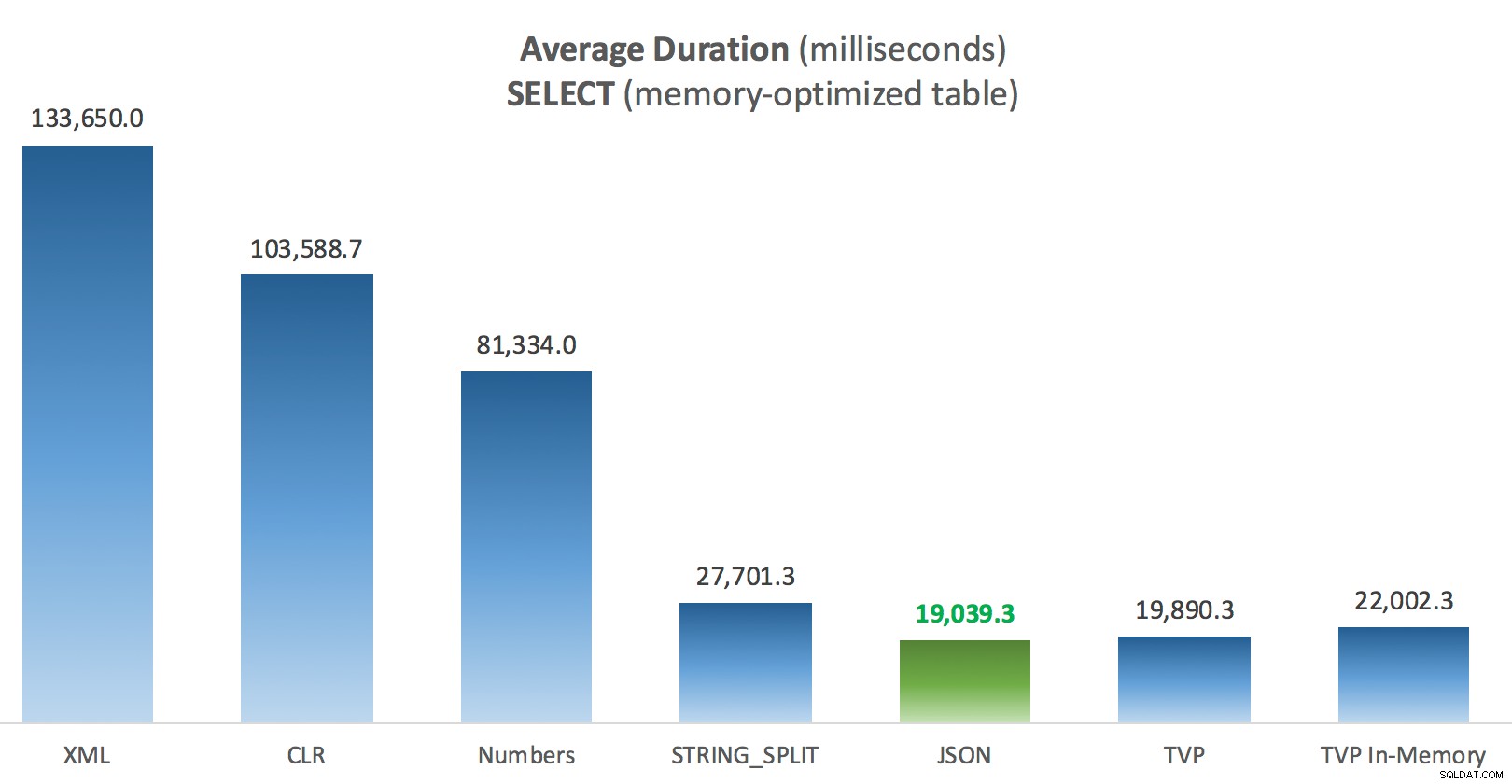 Průměrná doba trvání (milisekundy) pro SELECTy oproti tabulce příspěvků optimalizovaných pro paměť
Průměrná doba trvání (milisekundy) pro SELECTy oproti tabulce příspěvků optimalizovaných pro paměť
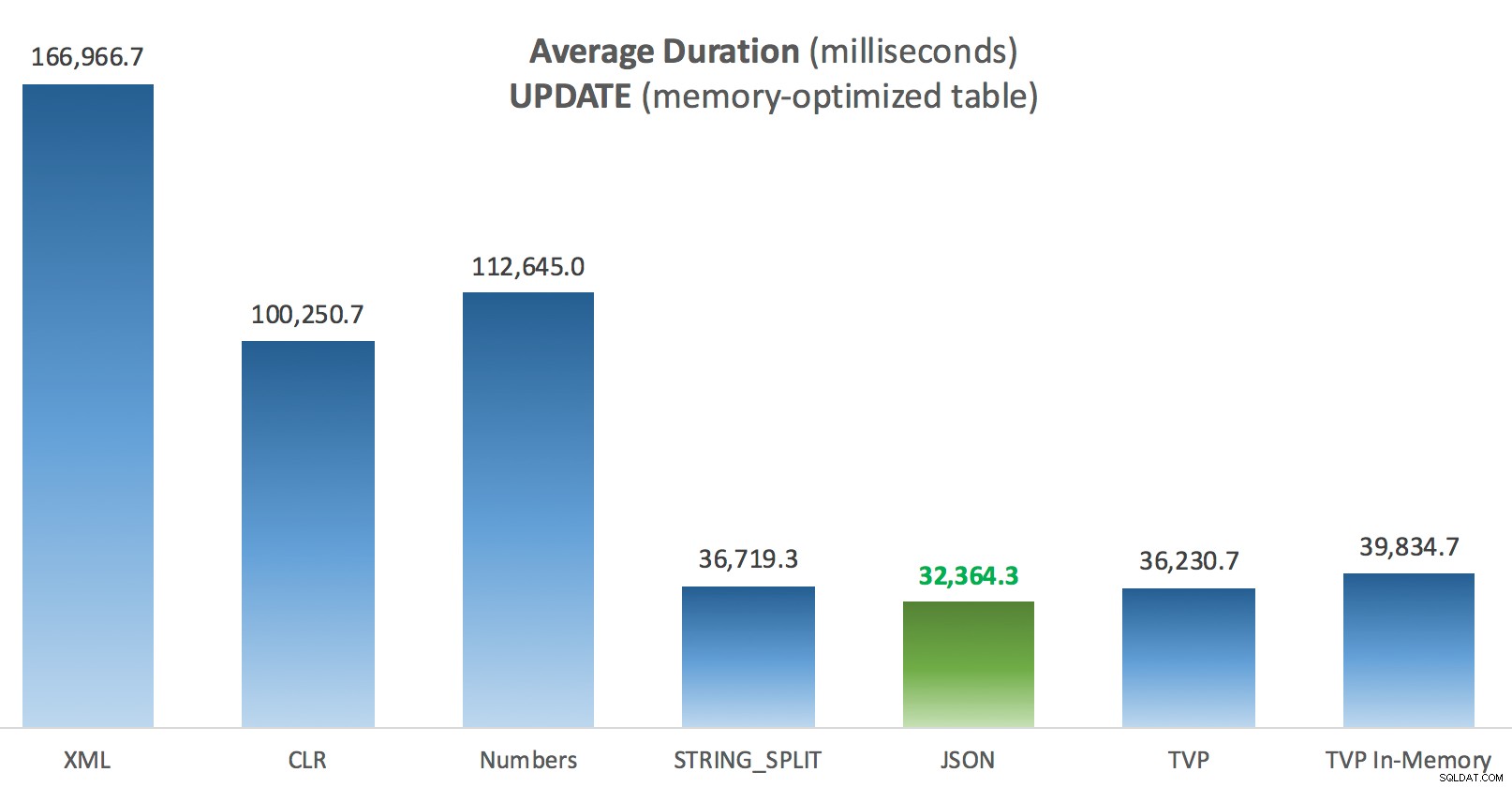 Průměrná doba trvání (milisekundy) pro AKTUALIZACE oproti tabulce příspěvků optimalizovaných pro paměť
Průměrná doba trvání (milisekundy) pro AKTUALIZACE oproti tabulce příspěvků optimalizovaných pro paměť
Závěr
V tomto konkrétním testu se specifickou velikostí dat, distribucí a počtem parametrů a na mém konkrétním hardwaru byl JSON konzistentním vítězem (i když jen okrajově). U některých dalších testů v předchozích příspěvcích však jiné přístupy dopadly lépe. Jen příklad toho, jak to, co děláte a kde to děláte, může mít dramatický dopad na relativní účinnost různých technik, zde jsou věci, které jsem testoval v této krátké sérii, s mým shrnutím toho, kterou techniku použít v takovém případě a kterou použít jako 2. nebo 3. volbu (například pokud nemůžete implementovat CLR kvůli podnikové politice nebo protože používáte Azure SQL Database, nebo nemůžete použít JSON nebo STRING_SPLIT() protože ještě nepoužíváte SQL Server 2016). Všimněte si, že jsem se nevrátil a znovu neotestoval přiřazení proměnné a SELECT INTO skripty využívající TVP – tyto testy byly nastaveny za předpokladu, že již máte existující data ve formátu CSV, která by stejně musela být nejprve rozdělena. Obecně platí, že pokud se tomu můžete vyhnout, IMHO své množiny neuhlazujte do řetězců oddělených čárkami.
| Cíl | 1. volba | 2. volba (a případně 3.) |
|---|---|---|
| Jednoduché přiřazení proměnných | STRING_SPLIT() | CLR, pokud <2016 XML, pokud není CLR a <2016 |
| VYBRAT DO | CLR | XML, pokud není CLR |
| VYBRAT DO (bez cívky) | CLR | Tabulka čísel, pokud není CLR |
| VYBRAT DO (bez cívky + MAXDOP 1) | STRING_SPLIT() | CLR, pokud <2016 Tabulka čísel, pokud není CLR a <2016 |
| VYBRAT spojující velký seznam (na disku) | JSON (int) | TVP pokud <2016 |
| VYBRAT připojení k velkému seznamu (optimalizováno pro paměť) | JSON (int) | TVP pokud <2016 |
| AKTUALIZACE připojení k velkému seznamu (na disku) | JSON (int) | TVP pokud <2016 |
| AKTUALIZACE připojení k velkému seznamu (optimalizováno pro paměť) | JSON (int) | TVP pokud <2016 |
Pro Dougovu konkrétní otázku:JSON, STRING_SPLIT() a TVP si v těchto testech vedly v průměru dost podobně – dostatečně blízko na to, aby TVP byly jasnou volbou, pokud nepoužíváte SQL Server 2016. Pokud máte různé případy použití, tyto výsledky se mohou lišit. Skvěle .
Což nás přivádí k morálce tohoto příběh:Já a ostatní můžeme provádět velmi specifické výkonnostní testy, které se točí kolem jakékoli funkce nebo přístupu, a dospět k nějakému závěru o tom, který přístup je nejrychlejší. Ale existuje tolik proměnných, že nikdy nebudu mít odvahu říct „tento přístup je vždy nejrychlejší." V tomto scénáři jsem se velmi snažil kontrolovat většinu přispívajících faktorů, a přestože JSON zvítězil ve všech čtyřech případech, můžete vidět, jak tyto různé faktory ovlivnily dobu provádění (a u některých přístupů drasticky). vždy stojí za to vytvořit si vlastní testy a doufám, že jsem pomohl ilustrovat, jak na takové věci jdu.
Příloha A:Kód konzolové aplikace
Prosím, žádné hnidopichy ohledně tohoto kódu; bylo doslova složeno dohromady jako velmi jednoduchý způsob, jak spustit tyto uložené procedury 1000krát se skutečnými seznamy a DataTables sestavenými v C# a zaznamenat čas, který každá smyčka zabrala, do tabulky (pro jistotu zahrnout veškerou režii související s aplikací s manipulací buď velký řetězec nebo sbírka). Mohl bych přidat zpracování chyb, zacyklit jinak (např. vytvořit seznamy uvnitř smyčky místo opětovného použití jedné jednotky práce) a tak dále.
použitím System;použitím System.Text;použitím System.Configuration;použitím System.Data;použitím System.Data.SqlClient; jmenný prostor SplitTesting{ class Program { static void Main(string[] argumenty) { string operation ="Aktualizace"; if (args[0].ToString() =="-Vybrat") { operation ="Vybrat"; } var csv =new StringBuilder(); Prvky DataTable =new DataTable(); elementy.Columns.Add("value", typeof(int)); for (int i =1; i <=10000; i++) { csv.Append((i*300).ToString()); if (i <10000) { csv.Append(","); } elements.Rows.Add(i*300); } string[] metody ={ "Nativní", "CLR", "XML", "Čísla", "JSON", "TVP", "TVP_InMemory" }; using (SqlConnection con =new SqlConnection()) { con.ConnectionString =ConfigurationManager.ConnectionStrings["primární"].ToString(); con.Open(); SqlParameter p; foreach (metoda řetězce v metodách) { SqlCommand cmd =new SqlCommand("dbo." + operace + "Příspěvky_" + metoda, con); cmd.CommandType =CommandType.StoredProcedure; if (metoda =="TVP" || metoda =="TVP_InMemory") { cmd.Parameters.Add("@PostList", SqlDbType.Structured).Value =prvky; } else { cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Value =csv.ToString(); } var timer =System.Diagnostics.Stopwatch.StartNew(); for (int x =1; x <=1000; x++) { if (operace =="Aktualizovat") { cmd.ExecuteNonQuery(); } else { SqlDataReader rdr =cmd.ExecuteReader(); rdr.Close(); } } timer.Stop(); long this_time =timer.ElapsedMilliseconds; // log time - procedura logování přidá čas hodin a // zaznamenává paměť/disk (určeno pomocí synonyma) SqlCommand log =new SqlCommand("dbo.LogBatchTime", con); log.CommandType =CommandType.StoredProcedure; log.Parameters.Add("@Operation", SqlDbType.VarChar, 32).Value =operace; log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Value =metoda; log.Parameters.Add("@Timing", SqlDbType.Int).Value =this_time; log.ExecuteNonQuery(); Console.WriteLine(metoda + " :" + this_time.ToString()); } } } }} Ukázka použití:
SplitTesting.exe -VyberteSplitTesting.exe -Aktualizovat
Příloha B:Funkce, procedury a tabulka protokolování
Zde byly funkce upraveny tak, aby podporovaly varchar(max) (funkce CLR již přijala nvarchar(max) a stále jsem se zdráhal to zkusit změnit):
VYTVOŘENÍ FUNKCE dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))VRÁTÍ TABULKU SE SCHEMABINDINGAS RETURN (VYBRAT [hodnotu] Z STRING_SPLIT(@List, @Delimiter));PŘEJÍT VYTVOŘIT FUNKCI tStrings_dbo. ( @List varchar(max), @Delimiter char(1))VRÁTÍ TABULKU SE SCHEMABINDINGAS RETURN (SELECT [value] =y.i.value('(./text())[1]', 'varchar(max)') FROM (SELECT x =CONVERT(XML, '' + REPLACE(@Seznam, @Delimiter, '') + '').query('.')) JAKO CROSS APPLY x.nodes('i') AS y(i));GO CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))RETURNS TABLE WITH SCHEMABINDINGAS RETURN (SELECT [value] =SUBSTRING (@Seznam, Číslo, CHARINDEX(@Oddělovač, @Seznam + @Oddělovač, Číslo) - Číslo) FROM dbo.Numbers WHERE Číslo <=CONVERT(INT, LEN(@Seznam)) A PODŘETĚZEC(@Oddělovač + @Seznam, Číslo , LEN(@Delimiter)) =@Delimiter );GO VYTVOŘIT FUNKCI dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))VRACÍ TABULKU S SCH EMABINDINGAS RETURN (SELECT [hodnota] FROM OPENJSON(CHAR(91) + @List + CHAR(93)) WITH (hodnota int '$'));GO A uložené procedury vypadaly takto:
POSTUP VYTVOŘENÍ dbo.UpdatePosts_Native @PostList varchar(max)ASBEGIN AKTUALIZACE p SET HitCount +=1 OD dbo.Příspěvky JAKO p VNITŘNÍ PŘIPOJENÍ dbo.SplitStrings_Native(@PostList, ',') JAKO s NA p.PostID [hodnota]; ENDGCREATE PROCEDURE dbo.SelectPosts_Native @PostList varchar(max)ASBEGIN VYBERTE p.PostID, p.HitCount FROM dbo.Posts AS p VNITŘNÍ PŘIPOJENÍ dbo.SplitStrings_Native(@PostList, ',') AS ON =p s.[value];ENDGO-- opakujte pro 4 další metody založené na varchar(max) CREATE PROCEDURE dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular READONLY -- přepněte _Regular na _InMemoryASBEGIN SET NOCOUNT ON; AKTUALIZOVAT p SET HitCount +=1 OD dbo.Příspěvky JAKO p VNITŘNÍ PŘIPOJIT SE @PostList JAKO s ON p.PostID =s.PostID; ENDGRETE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular ONLY READONLY -- přepnout _ReSET AS s ON p.PostID =s.PostID; SELECT p.PostID, p.HitCount FROM dbo.Posts AS p VNITŘNÍ PŘIPOJENÍ @PostList AS s ON p.PostID =s.PostID;ENDGO-- opakujte pro uložení v paměti
A nakonec logovací tabulka a postup:
CREATE TABLE dbo.SplitLog( LogID int IDENTITY(1,1) PRIMÁRNÍ KLÍČ, ClockTime datetime NOT NULL DEFAULT GETDATE(), OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory or Posts_Regular Operation varchar(32) NOT NULL DEFAULT 'Update', -- nebo vyberte metodu varchar(32) NOT NULL DEFAULT 'Native', -- nebo TVP, JSON atd. Časování int NOT NULL DEFAULT 0);GO CREATE PROCEDURE dbo.LogBatchTime @Operation varchar(32), @Metoda varchar(32), @Časování intASBEGIN SET NOCOUNT ON; INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing) SELECT base_object_name, @Operation, @Method, @Timing FROM sys.synonyms WHERE name =N'Posts';ENDGO -- a dotaz pro vygenerování grafů:;WITH x AS( SELECT OperatingTable,Operation,Metoda,Timeing, Recency =ROW_NUMBER() OVER (PARTITION BY OperatingTable,Operation,Metod ORDER BY ClockTime DESC) FROM dbo.SplitLog)SELECT OperatingTable,Operation,Metoda,AverageDuration =AVG(1. FROM x WHERE Aktuálnost <=3GROUP BY OperatingTable,Operation,Metoda;