Před několika týdny jsem psal o tom, jak jsem byl překvapen výkonem nové nativní funkce v SQL Server 2016, STRING_SPLIT() :
- Překvapení a předpoklady výkonu:STRING_SPLIT()
Po zveřejnění příspěvku jsem dostal několik komentářů (veřejně i soukromě) s těmito návrhy (nebo otázkami, které jsem proměnil v návrhy):
- Určení explicitního výstupního datového typu pro přístup JSON, aby tato metoda netrpěla potenciální režií výkonu v důsledku záložní funkce
nvarchar(max). - Testování mírně odlišného přístupu, kde se s daty skutečně něco dělá – konkrétně
SELECT INTO #temp. - Zobrazuje srovnání odhadovaného počtu řádků se stávajícími metodami, zejména při vnořování rozdělených operací.
Některým lidem jsem odpověděl offline, ale řekl jsem si, že by stálo za to sem zveřejnit reakci.
Být spravedlivější vůči JSON
Původní funkce JSON vypadala takto, bez specifikace výstupního datového typu:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Přejmenoval jsem jej a vytvořil dva další s následujícími definicemi:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Myslel jsem, že to drasticky zlepší výkon, ale bohužel tomu tak nebylo. Provedl jsem znovu testy a výsledky byly následující:
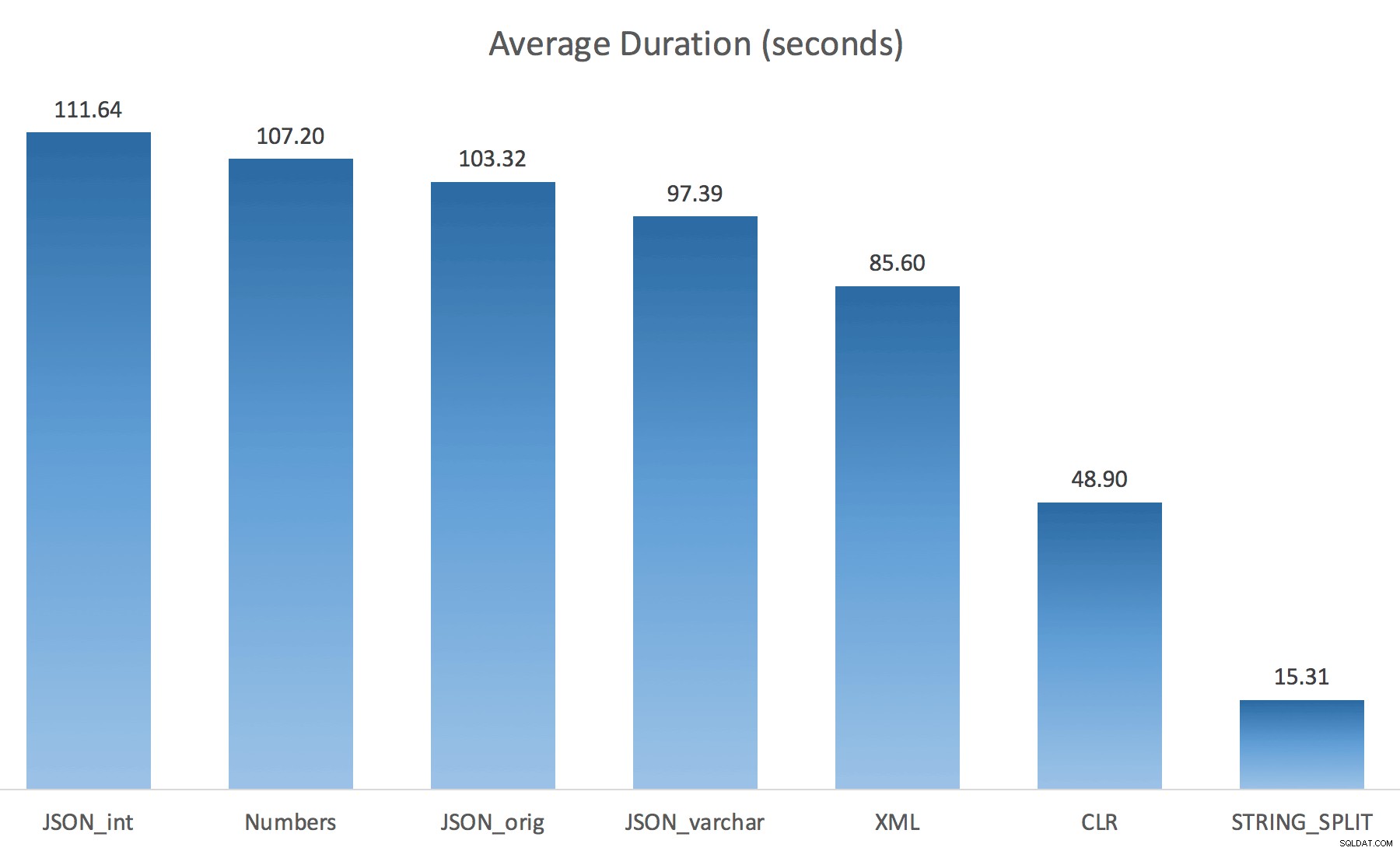
Čekání pozorovaná během náhodné instance testu (filtrováno na> 25):
| CLR | IO_COMPLETION | 1 595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6 294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4 307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6 110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Čísla | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1 917 |
| IO_COMPLETION | 1 616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
Pozorováno čekání> 25 (všimněte si, že zde není žádný záznam pro STRING_SPLIT )
Při změně z výchozího na varchar(100) trochu zlepšil výkon, zisk byl zanedbatelný a změnil se na int vlastně to ještě zhoršil. Přidejte k tomu, že pravděpodobně budete muset přidat STRING_ESCAPE() na příchozí řetězec v některých scénářích, jen pro případ, že mají znaky, které zkazí analýzu JSON. Můj závěr je stále takový, že je to elegantní způsob, jak používat novou funkcionalitu JSON, ale většinou jde o novinku nevhodnou pro rozumné měřítko.
Materializace výstupu
Jonathan Magnan učinil tento chytrý postřeh v mém předchozím příspěvku:
STRING_SPLIT je skutečně velmi rychlý, ale také pekelně pomalý při práci s dočasnou tabulkou (pokud to nebude opraveno v budoucím sestavení).SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Bude MNOHEM pomalejší než řešení SQL CLR (15x a více!).
Tak jsem se do toho pustil. Vytvořil jsem kód, který by volal každou z mých funkcí a vypisoval výsledky do #temp tabulky a načasoval je:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
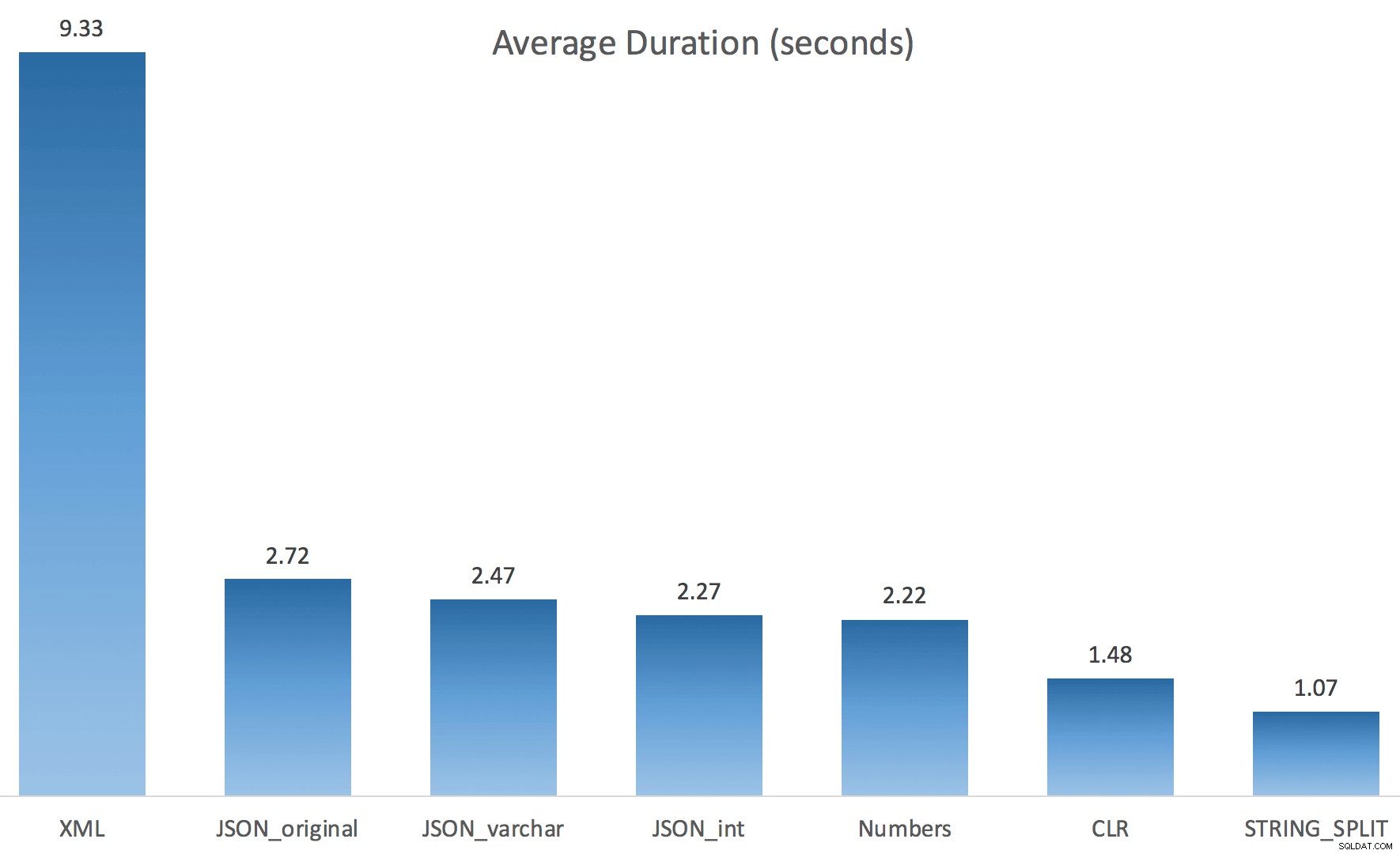
Každý test jsem spustil pouze jednou (spíše než 100krát smyčku), protože jsem nechtěl úplně zničit I/O v mém systému. Přesto po zprůměrování tří testovacích jízd měl Jonathan naprostou, 100% pravdu. Zde byly doby trvání naplnění #temp tabulky ~500 000 řádky pomocí každé metody:
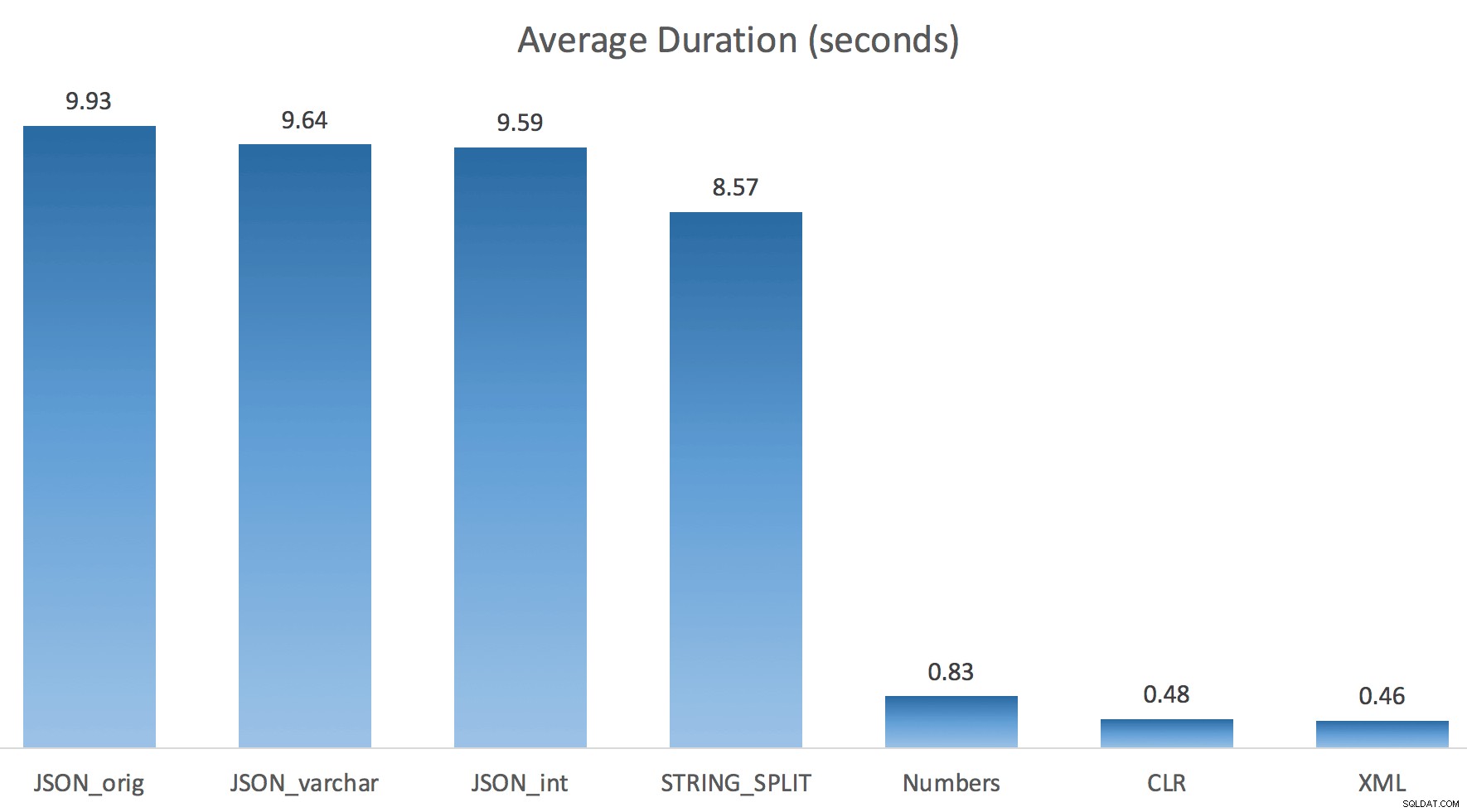
Zde jsou tedy JSON a STRING_SPLIT každá metoda trvala asi 10 sekund, zatímco přístupy s tabulkou Numbers, CLR a XML trvaly méně než sekundu. Zmateně jsem prozkoumal čekání a jistě, čtyři metody vlevo způsobily významný LATCH_EX čekání (asi 25 sekund) nebylo vidět u ostatních tří a nebylo možné hovořit o dalších významných čekáních.
A protože čekání na blokování bylo delší než celkové trvání, dalo mi to vodítko, že to má co do činění s paralelismem (tento konkrétní stroj má 4 jádra). Takže jsem znovu vygeneroval testovací kód a změnil jsem jen jeden řádek, abych viděl, co by se stalo bez paralelismu:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
Nyní STRING_SPLIT dopadl mnohem lépe (stejně jako metody JSON), ale stále je to alespoň dvojnásobek času, který zabral CLR:
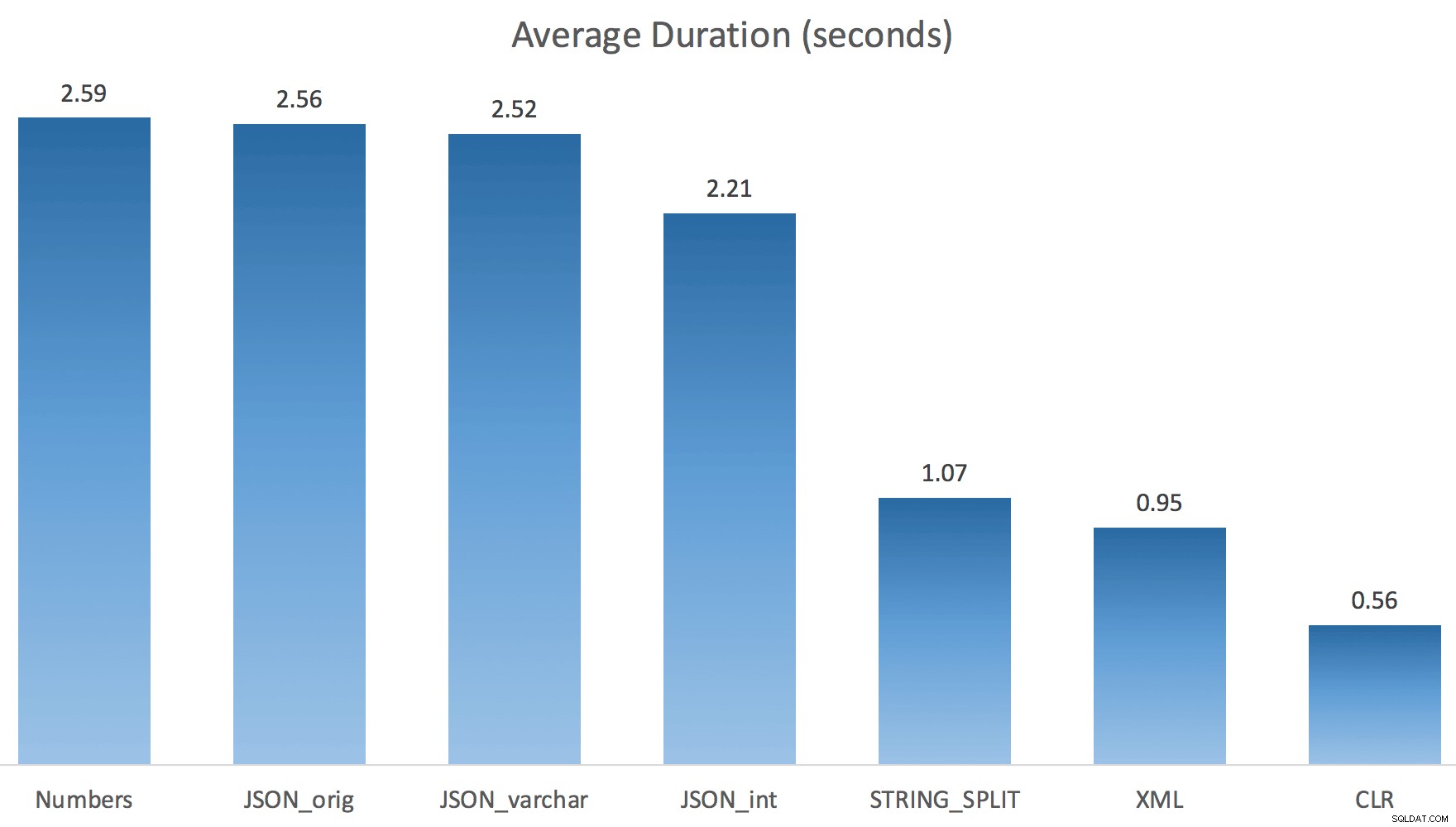
Takže pokud je zapojen paralelismus, může v těchto nových metodách existovat přetrvávající problém. Nešlo o problém s distribucí vláken (to jsem si ověřil) a CLR měl ve skutečnosti horší odhady (100x skutečný vs. jen 5x pro STRING_SPLIT ); Předpokládám, že jen nějaký základní problém s koordinací západek mezi vlákny. Prozatím by mohlo být užitečné použít MAXDOP 1 pokud víte, že zapisujete výstup na nové stránky.
Zahrnul jsem grafické plány porovnávající přístup CLR s nativním, pro paralelní i sériové provádění (také jsem nahrál soubor analýzy dotazů, který si můžete otevřít v SQL Sentry Plan Explorer, abyste se mohli sami prokousat):
STRING_SPLIT
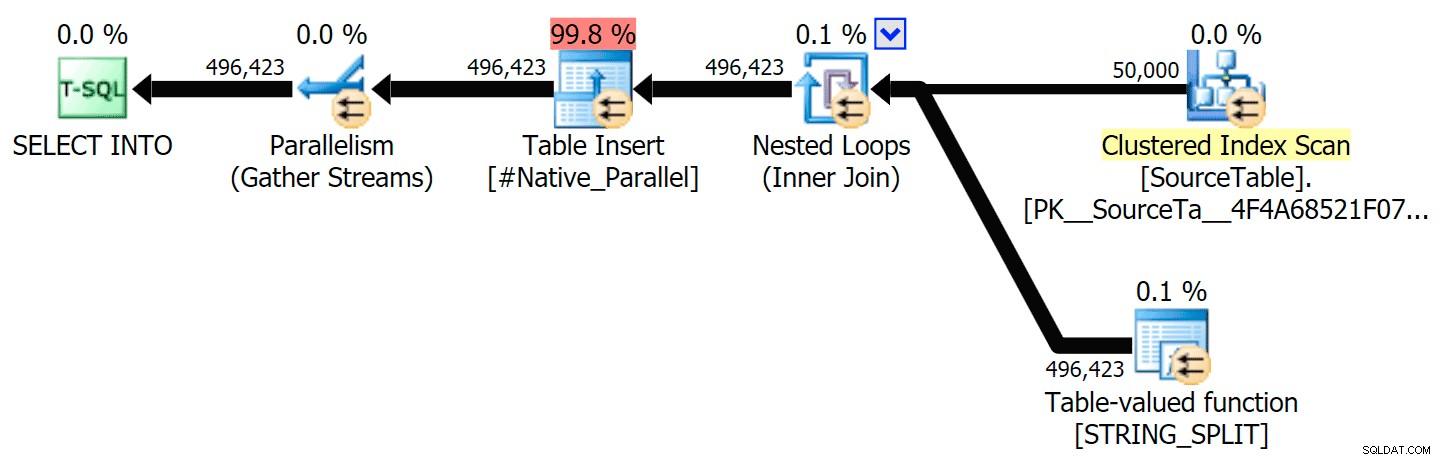
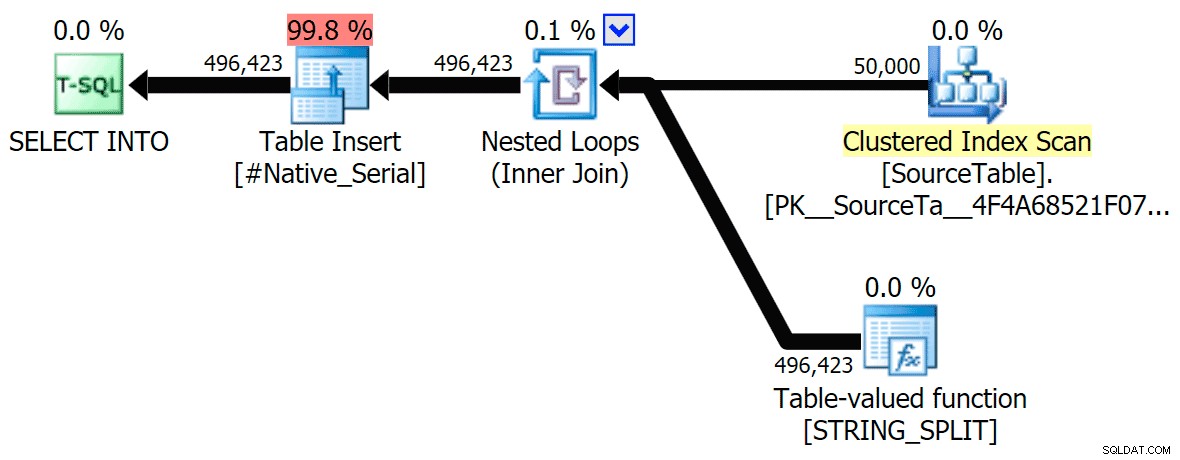
CLR
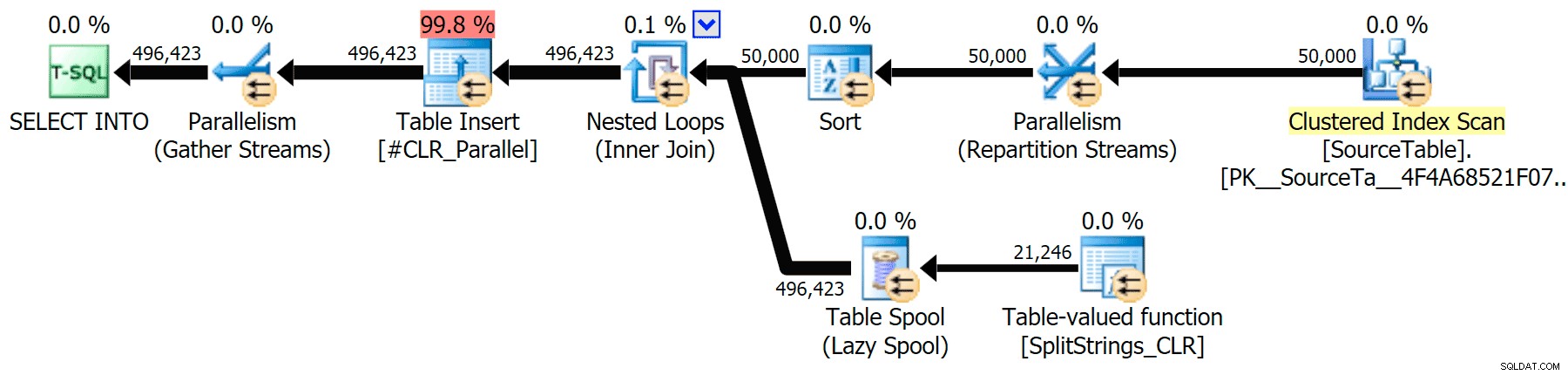
Upozornění na řazení, FYI, nebylo nic příliš šokujícího a zjevně nemělo příliš hmatatelný vliv na dobu trvání dotazu:

- StringSplit.queryanalysis.zip (25 kb)
Vyrazit na léto
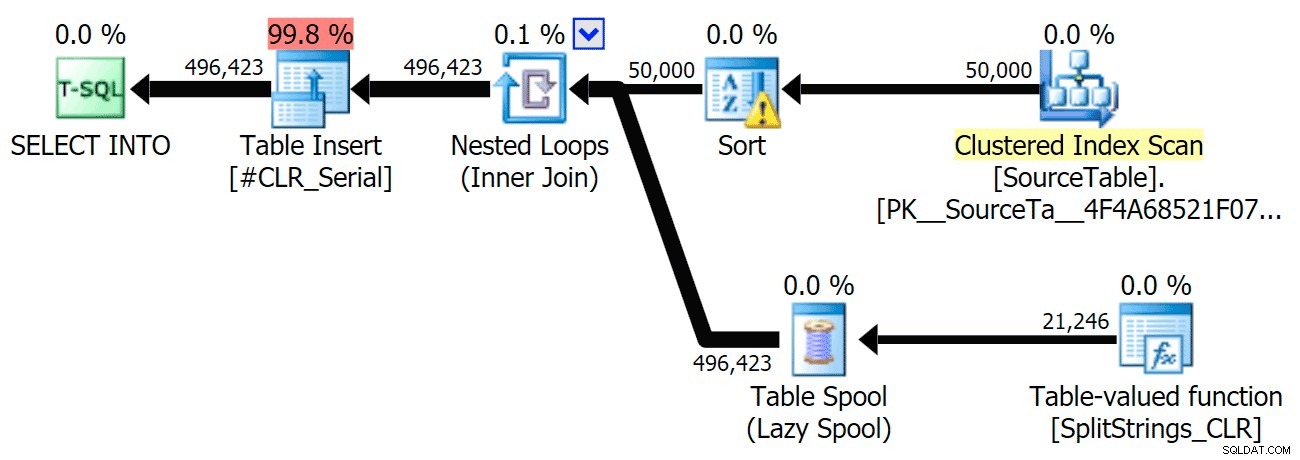
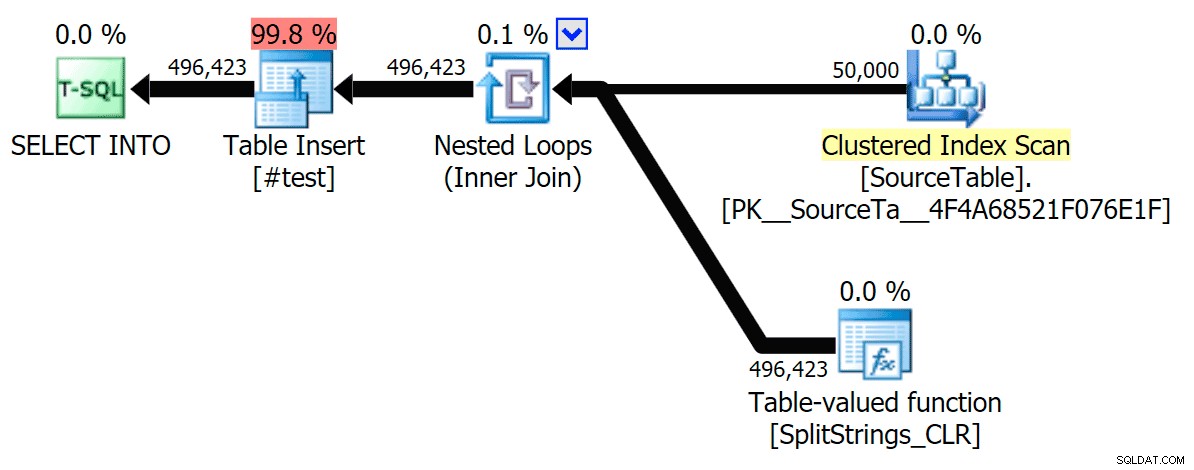
Když jsem se na ty plány podíval trochu blíže, všiml jsem si, že v plánu CLR je líná cívka. Toto je zavedeno proto, aby bylo zajištěno, že duplikáty budou zpracovávány společně (pro úsporu práce tím, že méně skutečného dělení), ale tato cívka není vždy možná ve všech půdorysných tvarech a může poskytnout trochu výhodu těm, kteří ji mohou používat ( např. plán CLR), v závislosti na odhadech. Pro porovnání bez cívek jsem povolil příznak trasování 8690 a spustil testy znovu. Za prvé, zde je paralelní plán CLR bez cívky:
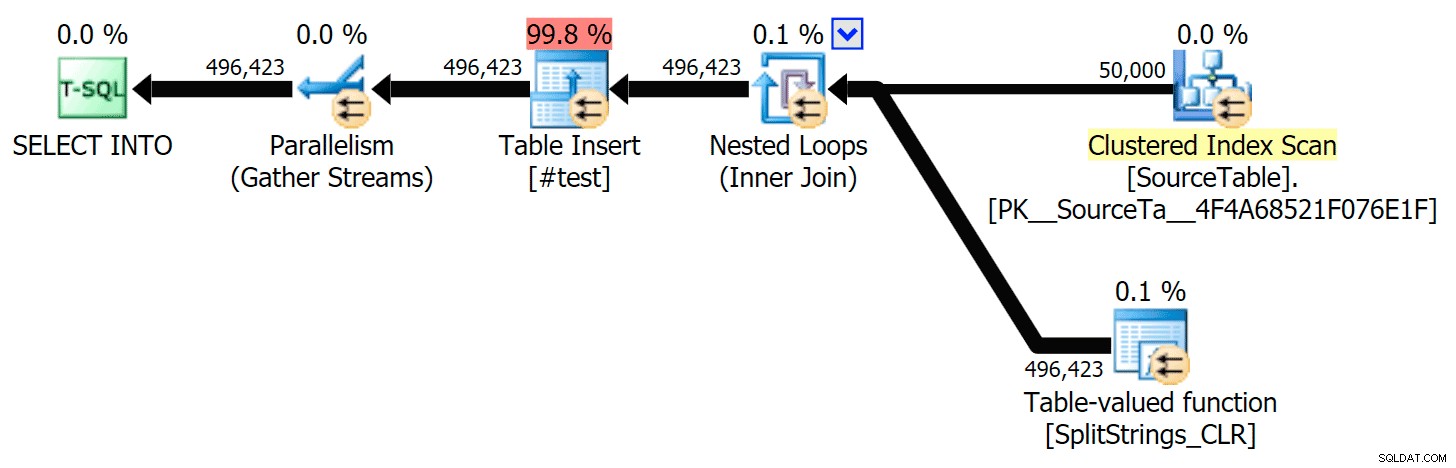
A zde byly nové doby trvání pro všechny dotazy probíhající paralelně s povoleným TF 8690:
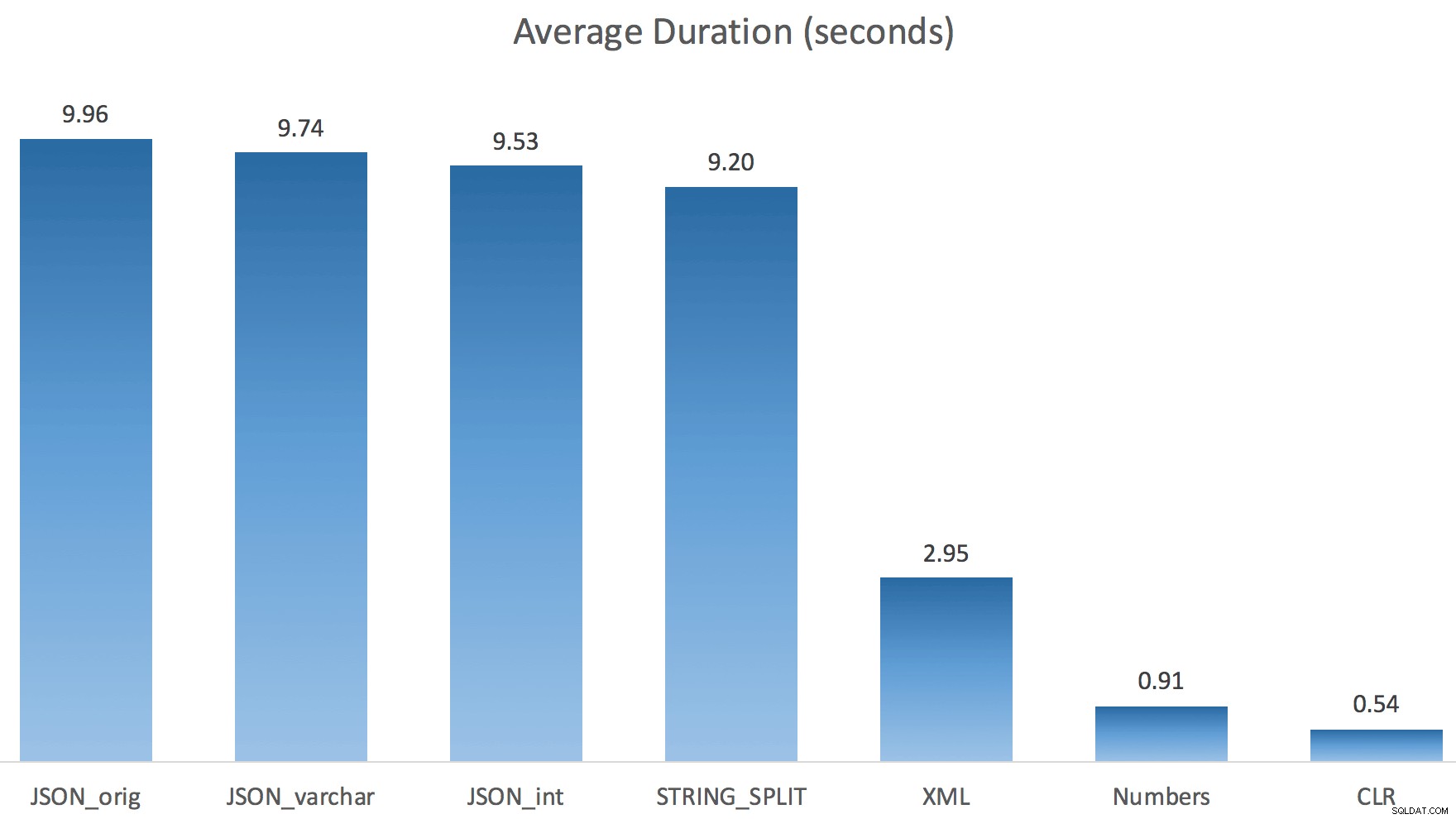
Nyní je zde sériový plán CLR bez cívky:
A zde byly výsledky časování pro dotazy pomocí TF 8690 i MAXDOP 1 :
(Všimněte si, že kromě plánu XML se většina ostatních nezměnila vůbec, s příznakem trasování nebo bez něj.)
Porovnání odhadovaného počtu řádků
Dan Holmes položil následující otázku:
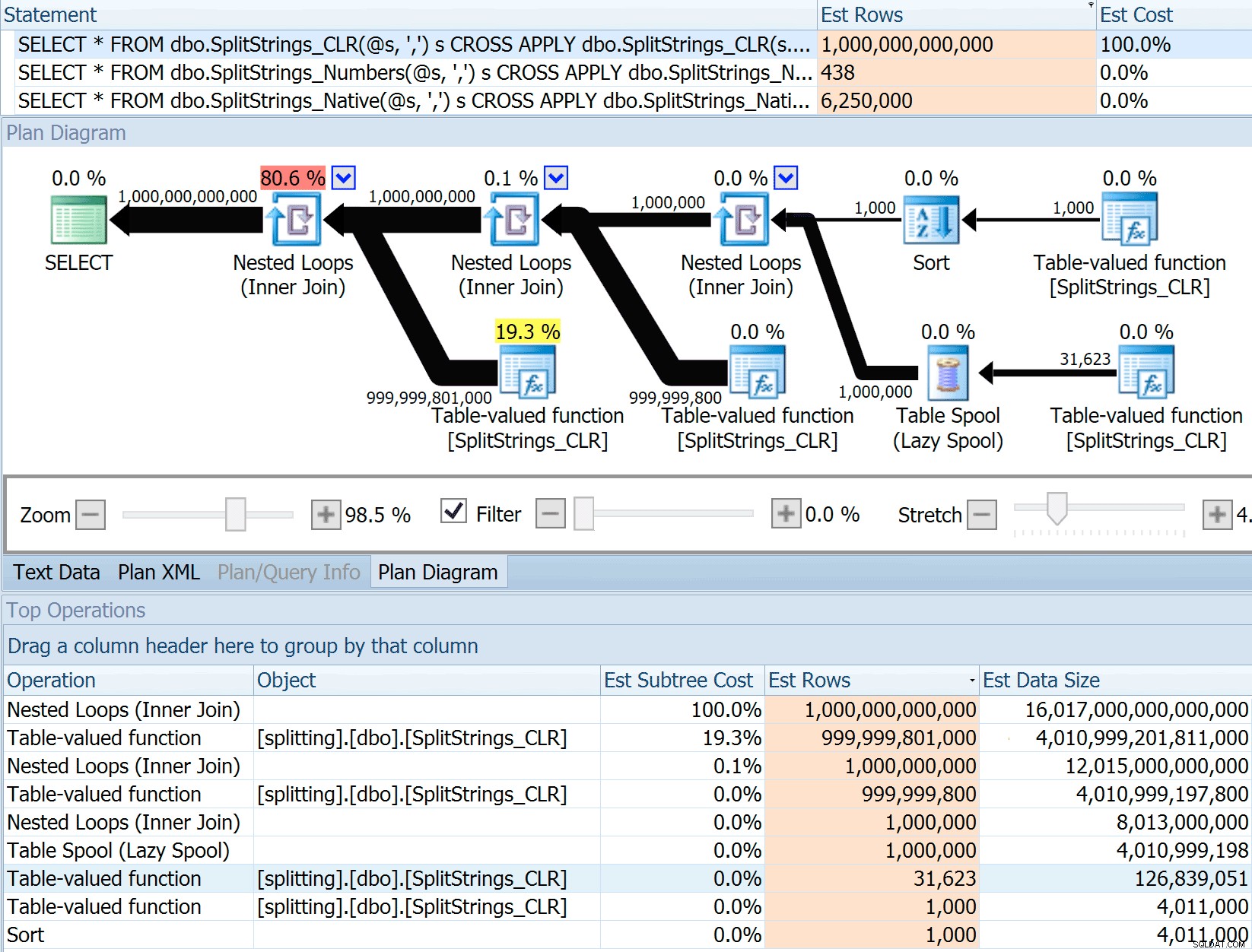
Jak odhaduje velikost dat při připojení k jiné (nebo vícenásobné) funkci rozdělení? Níže uvedený odkaz je zápisem implementace rozdělení založené na CLR. Dělá rok 2016 „lepší“ práci s odhady dat? (Bohužel ještě nemám možnost HTE nainstalovat RC).https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
Vytáhl jsem tedy kód z Danova příspěvku, změnil jsem jej tak, aby používal mé funkce, a prošel jsem jej přes Plan Explorer:
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
SPLIT_STRING přístup určitě přichází s *lepšími* odhady než CLR, ale stále hrubě překračuje (v tomto případě, když je řetězec prázdný; nemusí to tak být vždy). Funkce má vestavěnou výchozí hodnotu, která odhaduje, že příchozí řetězec bude mít 50 prvků, takže když je vnoříte, získáte 50 x 50 (2 500); pokud je znovu vnoříte, 50 x 2 500 (125 000); a nakonec 50 x 125 000 (6 250 000):
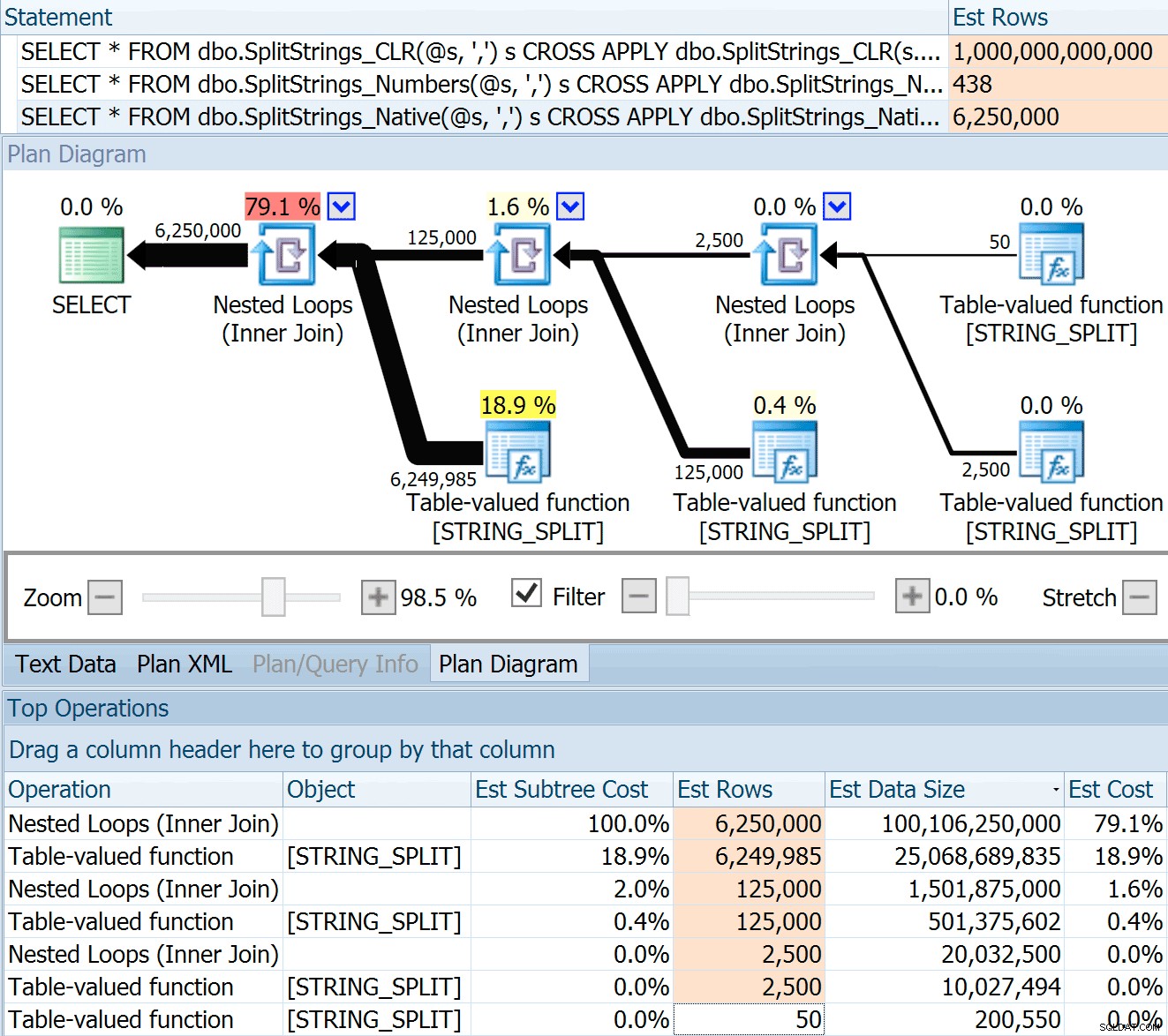
Poznámka:OPENJSON() chová se úplně stejně jako STRING_SPLIT – také předpokládá, že z každé dané operace rozdělení vyjde 50 řádků. Myslím si, že by mohlo být užitečné mít způsob, jak naznačit mohutnost funkcí, jako je tato, kromě příznaků trasování jako 4137 (před rokem 2014), 9471 a 9472 (2014+) a samozřejmě 9481…
Tento odhad 6,25 milionu řádků není skvělý, ale je mnohem lepší než přístup CLR, o kterém mluvil Dan, který odhaduje TRILIÓN ŘÁDKŮ a ztratil jsem počet čárek pro určení velikosti dat – 16 petabajtů? exabajtů?
Některé z dalších přístupů jsou na tom z hlediska odhadů samozřejmě lépe. Tabulka Numbers například odhadovala mnohem rozumnějších 438 řádků (v SQL Server 2016 RC2). Odkud toto číslo pochází? V tabulce je 8 000 řádků, a pokud si pamatujete, funkce má predikát rovnosti i nerovnosti:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter SQL Server tedy vynásobí počet řádků v tabulce 10 % (odhadem) pro filtr rovnosti a poté druhou odmocninou 30 % (opět odhad) pro filtr nerovnosti. Druhá odmocnina je způsobena exponenciálním ustupováním, které zde vysvětluje Paul White. To nám dává:
8000 * 0,1 * SQRT(0,3) =438,178Variace XML odhadovala něco málo přes miliardu řádků (kvůli tabulkovému spoolu, který se odhaduje na 5,8 milionkrát), ale její plán byl příliš složitý na to, aby se zde pokusil ilustrovat. V každém případě mějte na paměti, že odhady jasně nevypovídají celý příběh – to, že dotaz obsahuje přesnější odhady, neznamená, že bude fungovat lépe.
Bylo několik dalších způsobů, jak bych mohl odhady trochu vylepšit:jmenovitě vynucení starého modelu odhadu mohutnosti (který ovlivnil variace tabulek XML i Numbers) a použití TF 9471 a 9472 (které ovlivnily pouze variaci tabulky Numbers, protože oba kontrolují mohutnost kolem více predikátů). Zde byly způsoby, jak mohu jen trochu změnit odhady (nebo HODNĚ , v případě návratu ke starému modelu CE):

Starý CE model snížil odhady XML o řád, ale pro tabulku Numbers to úplně vyhodil do vzduchu. Predikátové příznaky změnily odhady pro tabulku Numbers, ale tyto změny jsou mnohem méně zajímavé.
Žádný z těchto příznaků trasování neměl žádný vliv na odhady pro CLR, JSON nebo STRING_SPLIT variace.
Závěr
Co jsem se tu tedy naučil? Vlastně celá parta:
- Paralelismus může v některých případech pomoci, ale když nepomůže, opravdu nepomáhá. Metody JSON byly ~5x rychlejší bez paralelismu a
STRING_SPLITbyl téměř 10x rychlejší. - Cívka ve skutečnosti pomohla přístupu CLR k lepšímu výkonu v tomto případě, ale TF 8690 může být užitečné pro experimentování v jiných případech, kdy vidíte cívky a snažíte se zlepšit výkon. Jsem si jistý, že existují situace, kdy odstranění cívky bude celkově lepší.
- Odstranění zařazování skutečně poškodilo přístup XML (ale pouze drasticky, když byl nucen být jednovláknový).
- S odhady v závislosti na přístupu spolu s obvyklými statistikami, distribucí a příznaky trasování se může stát spousta zábavných věcí. No, předpokládám, že jsem to už věděl, ale určitě je zde pár dobrých, hmatatelných příkladů.
Děkuji lidem, kteří se ptali nebo mě pobízeli, abych uvedl další informace. A jak jste mohli uhodnout z názvu, v druhém pokračování se zabývám ještě další otázkou, touto o TVP:
- STRING_SPLIT() v SQL Server 2016:Následná akce č. 2