V březnu jsem začal sérii o všudypřítomných mýtech o výkonu v SQL Server. Jednou z myšlenek, se kterou se čas od času setkávám, je, že sloupce varchar nebo nvarchar můžete předimenzovat bez jakéhokoli postihu.
Předpokládejme, že ukládáte e-mailové adresy. V minulém životě jsem se tím docela zabýval – tehdy RFC 3696 uvádělo, že e-mailová adresa může mít 320 znaků (64chars@255chars). Novější RFC, #5321, nyní uznává, že 254 znaků je nejdelší e-mailová adresa, která může být. A pokud má někdo z vás tak dlouhou adresu, možná bychom si měli popovídat. :-)
Nyní, ať už půjdete podle starého nebo nového standardu, musíte podporovat možnost, že někdo použije všechny povolené znaky. To znamená, že musíte použít 254 nebo 320 znaků. Ale to, co jsem viděl lidi dělat, je, že se vůbec neobtěžují zkoumat standard a jen předpokládají, že potřebují podporovat 1 000 znaků, 4 000 znaků nebo dokonce více.
Pojďme se tedy podívat, co se stane, když máme tabulky se sloupcem e-mailové adresy různé velikosti, ale ukládající přesně stejná data:
CREATE TABLE dbo.Email_V320( id int PRIMÁRNÍ KLÍČ IDENTITY, email varchar(320)); CREATE TABLE dbo.Email_V1000( id int PRIMÁRNÍ KLÍČ IDENTITY, email varchar(1000)); CREATE TABLE dbo.Email_V4000( id int PRIMÁRNÍ KLÍČ IDENTITY, email varchar(4000)); CREATE TABLE dbo.Email_Vmax( id int PRIMÁRNÍ KLÍČ IDENTITY, email varchar(max));
Nyní vygenerujeme 10 000 fiktivních e-mailových adres ze systémových metadat a naplníme všechny čtyři tabulky stejnými daty:
INSERT dbo.Email_V320(e-mail) VYBRAT NAHORU (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') OD sys.all_columns JAKO c VNITŘNÍ PŘIPOJENÍ sys.all_objects AS o ON c.[id_objektu] =o.[id_objektu] VNITŘNÍ PŘIPOJENÍ sys.all_columns AS c2 ON c.[id_objektu] =c2.[id_objektu] ORDER BY NEWID(); INSERT dbo.Email_V1000(e-mail) SELECT email FROM dbo.Email_V320;INSERT dbo.Email_V4000(e-mail) SELECT email FROM dbo.Email_V320;INSERT dbo.Email_Vmax (e-mail) SELECT email FROM_32. -- pojďme znovu vytvořit ALTER INDEX VŠE NA dbo.Email_V320 REBUILD;ALTER INDEX VŠE NA dbo.Email_V1000 REBUILD;ALTER INDEX VŠE NA dbo.Email_V4000 REBUILD;ALTER INDEX ALL ON dbo.REBUILD;Chcete-li ověřit, že každá tabulka obsahuje přesně stejná data:
VYBERTE AVG(DÉLKA(e-mail)), MAX(DÉLKA(e-mail)) Z dbo.Email_; Všechny čtyři mi dávají 35 a 77; váš počet najetých kilometrů se může lišit. Také se ujistěte, že všechny čtyři tabulky zabírají stejný počet stránek na disku:
SELECT o.name, COUNT(p.[object_id]) FROM sys.objects AS o CROSS APPLY sys.dm_db_database_page_allocations (DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p WHERE o.name LIKE N'Email[_]V[^2]%' GROUP BY o.name;Všechny čtyři tyto dotazy vynesou 89 stránek (opět se váš počet najetých kilometrů může lišit).
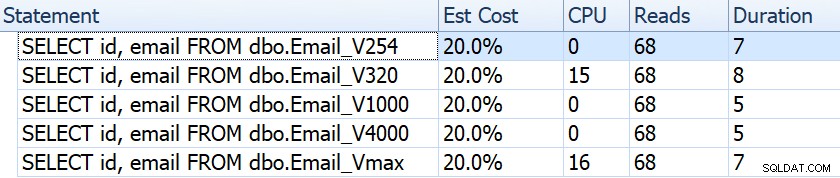
Nyní si vezměme typický dotaz, jehož výsledkem je skenování clusteru indexu:
SELECT id, email FROM dbo.Email_; Pokud se podíváme na věci, jako je trvání, přečtení a odhadované náklady, zdají se všechny stejné:
To může lidi ukolébat k falešnému předpokladu, že to nemá vůbec žádný dopad na výkon. Ale když se podíváme trochu blíže, na nápovědě pro skenování seskupeného indexu v každém plánu vidíme rozdíl, který může vstoupit do hry v jiných, propracovanějších dotazech:
Odtud vidíme, že čím větší je definice sloupce, tím vyšší je odhadovaná velikost řádku a dat. V tomto jednoduchém dotazu jsou I/O náklady (0,0512731) stejné pro všechny dotazy bez ohledu na definici, protože skenování klastrovaného indexu stejně musí číst všechna data.
Existují však i jiné scénáře, kde bude mít tento odhadovaný řádek a celková velikost dat dopad:operace, které vyžadují další zdroje, například řazení. Vezměme si tento směšný dotaz, který neslouží žádnému skutečnému účelu, kromě toho, že vyžaduje několik operací řazení:
SELECT /* V*/ ROW_NUMBER() OVER (ODDĚLENÍ e-mailem OBJEDNAT e-mailem DESC), e-mail, REVERSE(e-mail), SUBSTRING(e-mail, 1, CHARINDEX('@', e-mail)) OD dbo .Email_V GROUP BY REVERSE(e-mail), email, SUBSTRING(e-mail, 1, CHARINDEX('@', email)) ORDER BY REVERSE (e-mail), email; Spustíme tyto čtyři dotazy a vidíme, že všechny plány vypadají takto:
Tato varovná ikona na operátoru SELECT se však objeví pouze u tabulek 4000/max. jaké je varování? Je to upozornění na nadměrné přidělení paměti, které bylo zavedeno v SQL Server 2016. Zde je upozornění pro varchar(4000):
A pro varchar(max):
Podívejme se trochu blíž a uvidíme, co se děje, alespoň podle sys.dm_exec_query_stats:
SELECT [tabulka] =SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kbFROM sys.dm_exec_query_stats AS s POUŽÍT KRÍŽEM sys.dm_exec_sql_text(s.sql_handle) JAKO tWHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' OBJEDNAT PODLE s.last_grant_kb;Výsledky:
V mém scénáři nebylo trvání ovlivněno rozdíly v přidělení paměti (kromě případu max), ale můžete jasně vidět lineární průběh, který se shoduje s deklarovanou velikostí sloupce. Což můžete použít k extrapolaci toho, co by se stalo na systému s nedostatečnou pamětí. Nebo propracovanější dotaz na mnohem větší soubor dat. Nebo výrazná souběh. Kterýkoli z těchto scénářů by mohl vyžadovat úniky, aby bylo možné zpracovat operace řazení, a výsledkem by bylo téměř jistě ovlivnění trvání.
Ale odkud pocházejí tyto větší paměťové granty? Pamatujte, že se jedná o stejný dotaz na přesně stejná data. Problém je v tom, že pro určité operace musí SQL Server vzít v úvahu, kolik dat *může* být ve sloupci. Nedělá to na základě skutečného profilování dat a nemůže dělat žádné předpoklady na základě <=201 hodnot kroku histogramu. Místo toho musí odhadnout, že každý řádek obsahuje poloviční hodnotu deklarované velikosti sloupce . Takže pro varchar(4000) předpokládá, že každá e-mailová adresa je dlouhá 2 000 znaků.
Když není možné mít e-mailovou adresu delší než 254 nebo 320 znaků, není možné naddimenzováním nic získat a potenciálně je mnoho co ztratit. Zvětšit velikost sloupce s proměnnou šířkou později je mnohem snazší, než se nyní zabývat všemi nevýhodami.
Samozřejmě nadměrná velikost
charneboncharsloupce mohou mít mnohem zjevnější postihy.