Úvod
Výkonnostní cívky jsou líné cívky přidané optimalizátorem za účelem snížení odhadovaných nákladů na vnitřní stranu z spojení vnořených smyček . Dodávají se ve třech variantách:Lazy Table Spool , Lazy Index Spool a Lazy Row Count Spool . Příklad tvaru plánu znázorňujícího zařazování výkonu líné tabulky je níže:
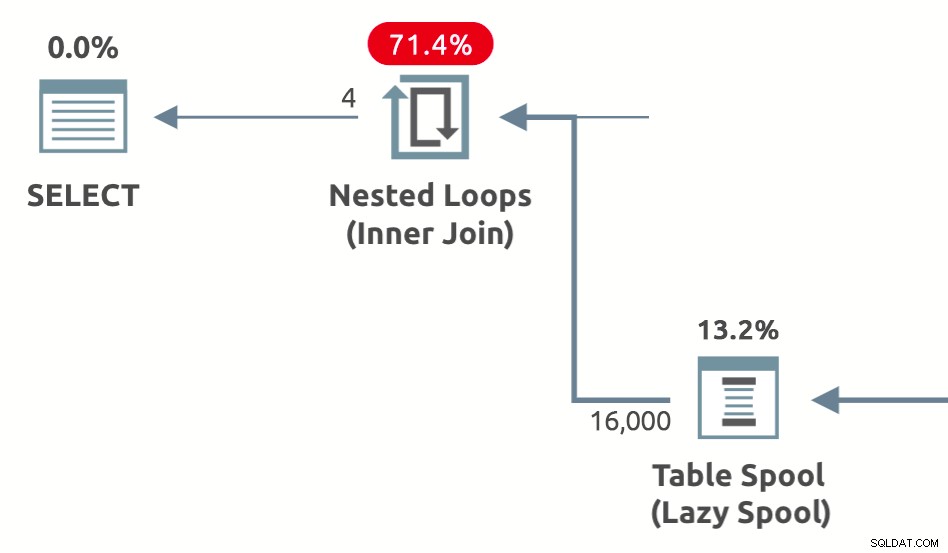
Otázky, na které jsem se v tomto článku rozhodl odpovědět, jsou proč, jak a kdy optimalizátor dotazů zavádí jednotlivé typy zařazování výkonu.
Těsně předtím, než začneme, chci zdůraznit důležitý bod:V plánech provádění existují dva odlišné typy spojení vnořených smyček. Na odrůdu budu odkazovat pomocí vnějších odkazů jako přihlášku a typ s predikátem spojení na samotném operátoru spojení jako spojení vnořených smyček . Aby bylo jasno, tento rozdíl se týká operátorů plánu provádění , nikoli syntaxe dotazu T-SQL. Další podrobnosti naleznete v mém odkazovaném článku.
Výkonnostní cívky
Na obrázku níže je výkonová cívka operátory prováděcího plánu zobrazené v Průzkumníku plánů (horní řádek) a SSMS 18.3 (dolní řádek):
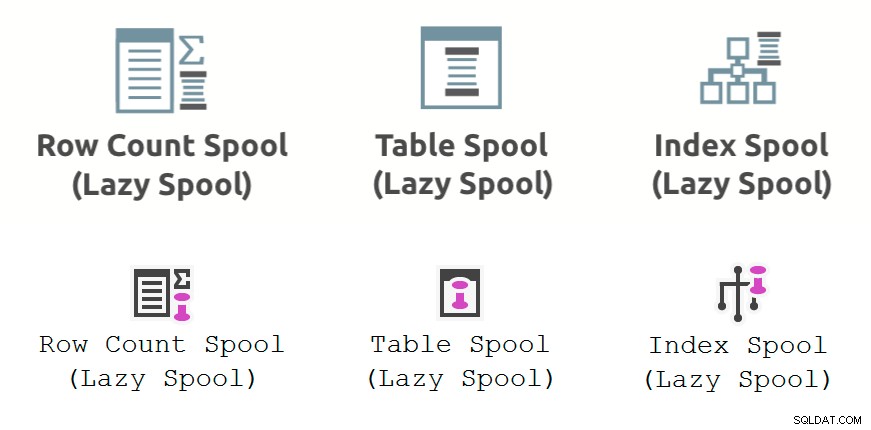
Obecné poznámky
Všechny řady výkonu jsou líní . Pracovní stůl cívky se postupně zaplňuje, řádek po druhém, jak řádky proudí přes cívku. (Naproti tomu Eager spooly spotřebují veškerý vstup od svého podřízeného operátora, než vrátí jakékoli řádky svému nadřazenému).
Výkonnostní cívky se vždy objevují na vnitřní straně (nižší vstup v grafických prováděcích plánech) operátoru spojení nebo aplikace vnořených smyček. Obecnou myšlenkou je ukládat do mezipaměti a přehrávat výsledky, čímž se ušetří opakované provádění vnitřních operátorů, kdykoli je to možné.
Když je cívka schopna znovu přehrát výsledky uložené v mezipaměti, nazývá se to přetočení . Když zařazování musí provést své podřízené operátory, aby získala správná data, znovu svázání dojde.
Možná vám pomůže vymyslet si cívku převázání jako vyrovnávací paměť a přetočení jako mezipaměť.
Lazy Table Spool
Tento typ zařazování výkonu lze použít s oběma možnostmi použít a vnořené smyčky se spojují .
Použít
znovu svázání (chyba v mezipaměti) nastane při každém vnějším odkazu změny hodnoty. Cívka líného stolu se znovu spojí zkrácením jeho pracovní stůl a plně jej znovu naplní od svých podřízených operátorů.
přetočení (zásah do mezipaměti) nastane, když se vnitřní strana spustí se stejným vnější referenční hodnoty jako bezprostředně předcházející opakování smyčky. Přetočením se přehrají výsledky uložené v mezipaměti z pracovního stolu cívky, čímž se ušetří náklady na opětovné provedení operátorů plánu pod cívkou.
Poznámka:Spool líné tabulky ukládá do mezipaměti výsledky pouze pro jednu sadu použít vnější odkaz hodnoty najednou.
Připojení k vnořeným smyčkám
Cívka líné tabulky se naplní jednou během první iterace smyčky. Spool převine svůj obsah pro každou následující iteraci spojení. U spojení vnořených smyček je vnitřní strana spojení statická sada řádků, protože predikát spojení je na samotném spojení. Statická sada řádků na vnitřní straně může být proto uložena do mezipaměti a opakovaně použita prostřednictvím zařazování. Vnořená smyčka spojení výkonu se nikdy znovu nespojí.
Lazy Row Count Spool
Spool počtu řádků je o něco více než Spool tabulky bez sloupců. Ukládá existenci řádku do mezipaměti, ale nepromítá žádná data sloupce. Kromě upozornění na jeho existenci a zmínky o tom, že může být známkou chyby ve zdrojovém dotazu, nebudu mít více co říci o spoolech počtu řádků.
Od této chvíle, kdykoli v textu uvidíte „table spool“, čtěte to prosím jako „table (nebo row count) spool“, protože jsou si velmi podobné.
Lazy Index Spool
Lazy Index Spool operátor je dostupný pouze při použití .
Zařazování indexů udržuje pracovní tabulku, která není zkrácena když vnější odkaz hodnoty se mění. Místo toho jsou do existující mezipaměti přidána nová data indexovaná vnějšími referenčními hodnotami. Spool líného indexu se liší od cívky líné tabulky tím, že dokáže přehrát výsledky z libovolných iteraci předchozí smyčky, nejen poslední.
Další krok k pochopení toho, kdy se v plánech provádění objevují spooly výkonu, vyžaduje trochu porozumět tomu, jak optimalizátor funguje.
Pozadí optimalizátoru
Zdrojový dotaz je převeden na reprezentaci logického stromu analýzou, algebrizací, zjednodušením a normalizací. Když výsledný strom nesplňuje podmínky pro triviální plán, optimalizátor založený na nákladech hledá logické alternativy, které zaručeně povedou ke stejným výsledkům, ale za nižší odhadované náklady.
Jakmile optimalizátor vygeneruje potenciální alternativy, implementuje každou z nich pomocí vhodných fyzických operátorů a vypočítá odhadované náklady. Konečný plán realizace je sestaven z možnosti s nejnižšími náklady nalezené pro každou skupinu operátorů. Další podrobnosti o tomto procesu si můžete přečíst v mé sérii Deep Dive s optimalizátorem dotazů.
Obecné podmínky nutné k tomu, aby se zařazování výkonu objevilo v konečném plánu optimalizátoru, jsou:
- Optimalizátor musí prozkoumat logická alternativa, která obsahuje logický spool ve vygenerované náhradě. Je to složitější, než to zní, takže podrobnosti rozbalím v další hlavní sekci.
- Logický spool musí být implementovatelný jako fyzická cívka operátor v prováděcím motoru. Pro moderní verze SQL Server to v podstatě znamená, že všechny klíčové sloupce v indexovém zařazování musí mít srovnatelné typu, ne více než 900 bajtů* celkem, s 64 klíčovými sloupci nebo méně.
- To nejlepší kompletní plán po optimalizaci na základě nákladů musí zahrnovat jednu z alternativ zařazování. Jinými slovy, jakákoliv volba mezi možností spool a non-spool na základě nákladů musí vyjít ve prospěch cívky.
* Tato hodnota je pevně zakódována do SQL Serveru a po zvýšení na 1700 bajtů pro nonclustered nebyla změněna indexové klíče od SQL Server 2016 výše. Důvodem je, že index zařazování je shlukovaný index, nikoli index bez klastrů.
Pravidla Optimalizátoru
Nemůžeme specifikovat spool pomocí T-SQL, takže jeho zařazení do prováděcího plánu znamená, že optimalizátor se musí rozhodnout ji přidat. Jako první krok to znamená, že optimalizátor musí zahrnout logickou cívku do jedné z alternativ, kterou se rozhodne prozkoumat.
Optimalizátor neaplikuje vyčerpávajícím způsobem všechna pravidla logické ekvivalence, která zná, na každý strom dotazů. To by bylo plýtvání, vzhledem k cíli optimalizátoru rychle vytvořit rozumný plán. To má více aspektů. Za prvé, optimalizátor postupuje po etapách, přičemž nejprve se vyzkouší levnější a častěji použitelná pravidla. Pokud je rozumný plán nalezen v rané fázi nebo dotaz nesplňuje podmínky pro pozdější fáze, může optimalizační úsilí předčasně skončit s dosud nalezeným plánem s nejnižšími náklady. Tato strategie pomáhá předcházet tomu, že byste na optimalizaci trávili více času, než kolik ušetří postupné zvyšování nákladů.
Shoda pravidel
Každý logický operátor ve stromu dotazů je rychle zkontrolován na shodu vzoru s pravidly dostupnými v aktuální fázi optimalizace. Každé pravidlo se například bude shodovat pouze s podmnožinou logických operátorů a může také vyžadovat použití specifických vlastností, jako je zaručený tříděný vstup. Pravidlo se může shodovat s jednotlivou logickou operací (jednou skupinou) nebo několika souvislými skupinami (podsekce plánu).
Po spárování je kandidátské pravidlo požádáno, aby vygenerovalo slibovanou hodnotu . Toto je číslo představující, jak pravděpodobně bude aktuální pravidlo poskytovat užitečný výsledek s ohledem na místní kontext. Pravidlo může například generovat vyšší příslibovou hodnotu, když má cíl na vstupu mnoho duplikátů, velký odhadovaný počet řádků, zaručený seřazený vstup nebo nějakou jinou žádoucí vlastnost.
Jakmile jsou identifikována slibná pravidla prozkoumání, optimalizátor je seřadí do pořadí hodnot slibů a začne je žádat, aby vygenerovaly nové logické náhražky. Každé pravidlo může generovat jednu nebo více náhrad, které budou později implementovány pomocí fyzických operátorů. V rámci tohoto procesu jsou vypočítány odhadované náklady.
Smysl toho všeho, jak to platí pro zařazování výkonu, spočívá v tom, že tvar a vlastnosti logického plánu musí být vhodné pro shodu pravidel schopných zařazování a místní kontext musí vytvářet dostatečně vysokou příslibovou hodnotu, kterou optimalizátor zvolí ke generování náhrad pomocí pravidla. .
Pravidla řazení
Existuje řada pravidel, která zkoumají logické spojení vnořených smyček nebo použít alternativy. Některá z těchto pravidel mohou produkovat jednu nebo více náhražek s určitým typem výkonové cívky. Jiná pravidla, která se shodují s vnořenými smyčkami, se nepřipojují nebo platí, nikdy nevygenerují alternativu pro zařazování.
Například pravidlo ApplyToNL implementuje logické použít jako fyzické smyčky se spojují s vnějšími referencemi. Toto pravidlo může generovat několik alternativ pokaždé, když běží. Kromě fyzického operátoru spojení může každá náhrada obsahovat cívku líné tabulky, cívku líného indexu nebo žádnou cívku. Logické náhrady zařazování jsou později jednotlivě implementovány a kalkulovány jako příslušně napsané fyzické cívky podle jiného pravidla zvaného BuildSpool .
Jako druhý příklad lze uvést pravidlo JNtoIdxLookup implementuje logické spojení jako fyzické použít , s indexovým vyhledáváním bezprostředně na vnitřní straně. Toto pravidlo nikdy generuje alternativu s komponentou cívky. JNtoIdxLookup je vyhodnocena brzy a vrací vysokou příslibovou hodnotu, když se shoduje, takže jednoduché plány vyhledávání indexů jsou rychle nalezeny.
Když optimalizátor brzy najde levnou alternativu, jako je tato, mohou být složitější alternativy agresivně odstraněny nebo úplně vynechány. Důvodem je, že nemá smysl uplatňovat možnosti, které se pravděpodobně nezlepší oproti již nalezené nízkonákladové alternativě. Stejně tak nemá cenu dále zkoumat, pokud má současný nejlepší kompletní plán již dostatečně nízké celkové náklady.
Třetí příklad pravidla:Pravidlo JNtoNL je podobný ApplyToNL , ale implementuje pouze fyzické vnořené připojení smyčky , buď s líným stolem cívky, nebo žádnou cívkou. Toto pravidlo nikdy generuje zařazování indexů, protože tento typ zařazování vyžaduje použití.
Vytváření cívek a kalkulace
Pravidlo, které je schopné generování logického zařazování nemusí nutně dělat pokaždé, když je vyvoláno. Bylo by zbytečné vytvářet logické alternativy, které nemají téměř žádnou šanci, že budou vybrány jako nejlevnější. Existují také náklady na generování nových alternativ, které mohou zase produkovat další alternativy – z nichž každá může vyžadovat implementaci a náklady.
Aby to bylo možné zvládnout, optimalizátor implementuje společnou logiku pro všechna pravidla umožňující zařazování, aby určil, který typ(y) alternativy zařazování vygenerovat na základě podmínek místního plánu.
Připojení vnořených smyček
Pro spojení vnořených smyček , šanci získat líný stůl s cívkou se zvyšuje v souladu s:
- Odhadovaný počet řádků na vnějším vstupu spojení.
- Odhadované náklady operátorů vnitřních plánů.
Náklady na cívku jsou splaceny úsporami, které zabraňují provádění operací na vnitřní straně. Úspory se zvyšují s větším počtem vnitřních iterací a vyššími náklady na vnitřní straně. To platí zejména proto, že nákladový model přiřazuje relativně nízké I/O a náklady na CPU převíjení tabulky (zásahy do mezipaměti). Pamatujte, že spool tabulky na spojení vnořených smyček se vždy přetočí pouze zpět, protože nedostatek parametrů znamená, že datová sada na vnitřní straně je statická.
Spool může ukládat data hustěji než provozovatelé, kteří ji krmí. Například seskupený index základní tabulky může v průměru uložit 100 řádků na stránku. Řekněme, že dotaz potřebuje pouze jednu celočíselnou hodnotu sloupce z každého širokého řádku seskupeného indexu. Uložení pouze celočíselné hodnoty v pracovní tabulce řazení znamená, že na stránku lze uložit více než 800 takových řádků. To je důležité, protože optimalizátor částečně posuzuje náklady na zařazování tabulky pomocí odhadu počtu stránek pracovní tabulky potřeboval. Mezi další nákladové faktory patří náklady na CPU na řádek, které jsou součástí zápisu a čtení cívky, nad odhadovaný počet iterací smyčky.
Optimalizátor je pravděpodobně příliš zapálený na to, aby na vnitřní stranu spojení vnořených smyček přidal líné tabulky spoolů. Rozhodnutí optimalizátora však vždy dává smysl z hlediska odhadovaných nákladů. Osobně považuji spojení vnořených smyček za vysoké riziko , protože se mohou rychle zpomalit, pokud je odhad mohutnosti vstupu jednoho spojení příliš nízký.
Stolní cívka může pomáhá snížit náklady, ale nemůže plně skrýt nejhorší možný výkon naivního spojení vnořených smyček. Za normálních okolností je výhodnější indexované spojení aplikace a je odolnější vůči chybám v odhadu. Je také dobré psát dotazy, které může optimalizátor implementovat pomocí hash nebo merge join, když je to vhodné.
Použít líný stůl Spool
Pro přihlášku , šance na získání líného stolu spool roste s odhadovaným počtem duplikátů spojte klíčové hodnoty na vnějším vstupu aplikace. Při větším počtu duplikátů existuje statisticky vyšší šance, že cívka přetočí své aktuálně uložené výsledky při každé iteraci. Lepší šance na zařazení do konečného plánu realizace má použití líné tabulky s nižšími odhadovanými náklady.
Když řádky přicházející na vnější vstup použití nemají žádné konkrétní pořadí, optimalizátor provede statistické posouzení jak pravděpodobné, že každá iterace povede k levnému přetočení nebo drahému převázání. Toto hodnocení využívá data z kroků histogramu, pokud jsou k dispozici, ale i tento nejlepší případ je spíše kvalifikovaným odhadem. Bez záruky je pořadí řádků přicházejících na vnější vstup aplikace nepředvídatelné.
Stejná pravidla optimalizace, která generují alternativy logického zařazování, mohou také zadejte, že operátor aplikace vyžaduje seřazené řádky na jeho vnějším vstupu. To maximalizuje líné spool přetáčení protože je zaručeno, že se v bloku objeví všechny duplikáty. Když je zaručeno vnější pořadí řazení, buď zachovaným řazením, nebo explicitním Řazením , náklady na cívku jsou mnohem nižší. Optimalizátor zohledňuje vliv pořadí řazení na počet převinutí a opětovného navázání cívky.
Plány s Řazením na vnějším vstupu aplikace a Lazy Table Spool na vnitřním vstupu jsou zcela běžné. Optimalizace třídění na vnější straně může být stále kontraproduktivní. K tomu může například dojít, když je odhad mohutnosti vnější strany tak nízký, že řazení skončí na tempdb .
Použít řazení líných indexů
Pro přihlášku , čímž získáte líný indexový spool alternativa závisí na tvaru plánu i na kalkulaci.
Optimalizátor vyžaduje:
- Nějaké duplikáty spojit hodnoty na vnějším vstupu.
- rovnost predikát spojení (nebo jeho logický ekvivalent, kterému optimalizátor rozumí, například
x <= y AND x >= y). - Záruka že vnější odkazy jsou jedinečné pod navrhovanou cívkou líného indexu.
V prováděcích plánech je požadovaná jedinečnost často zajištěna agregovaným seskupením podle vnějších referencí nebo skalárním agregátem (bez skupiny podle). Jedinečnost může být zajištěna i jinými způsoby, například existencí jedinečného indexu nebo omezení.
Příklad hračky, který ukazuje tvar plánu, je níže:
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c);
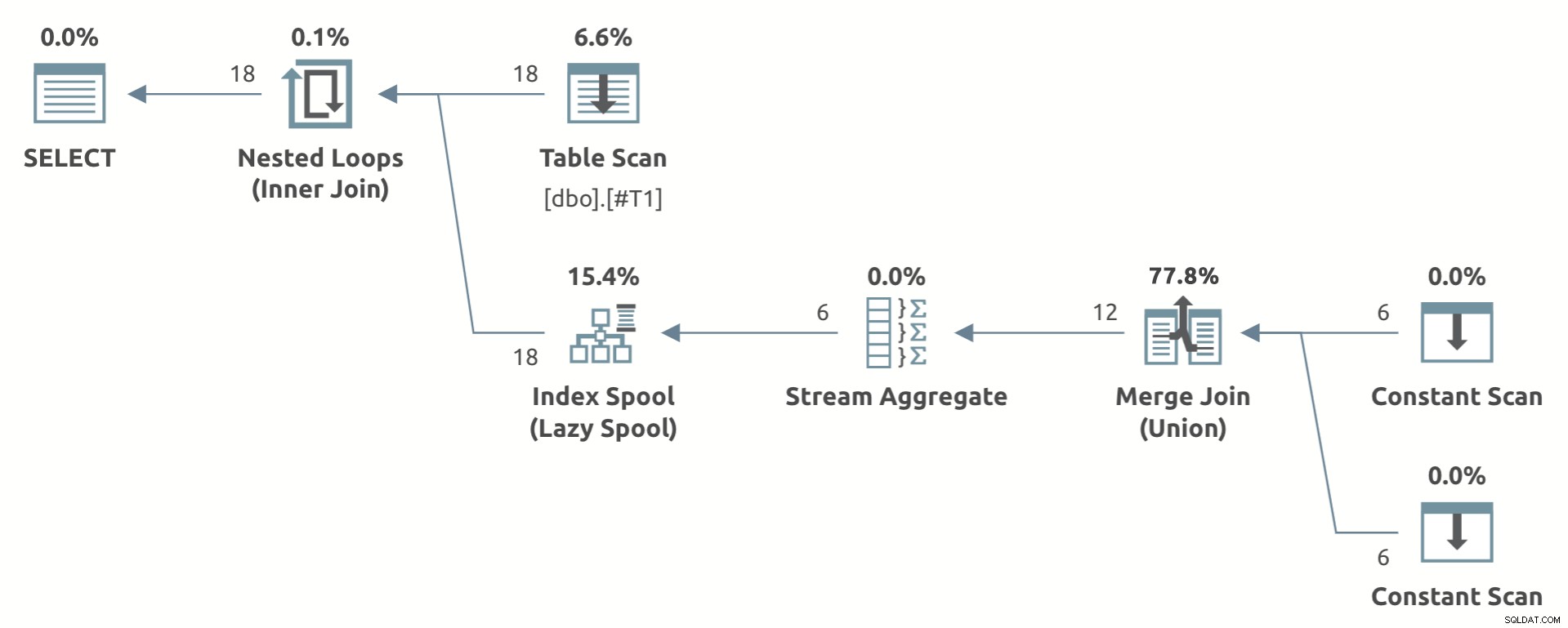
Všimněte si Agregace streamů pod Lazy Index Spool .
Pokud jsou splněny požadavky na tvar plánu, optimalizátor často vygeneruje alternativu líného indexu (s výhradou výše zmíněných upozornění). Zda konečný plán zahrnuje cívku líného indexu nebo ne, závisí na kalkulaci.
Spool indexů versus tabulka spool
Odhadovaný počet přetočení a znovu sváže pro líné indexové zařazování je stejné jako u líného stolu cívka bez seřazeno použít vnější vstup.
To se může zdát jako poněkud nešťastný stav. Primární výhodou indexového zařazování je to, že ukládá všechny dříve zobrazené výsledky do mezipaměti. To by mělo způsobit přetočení indexové cívky pravděpodobnější než u tabulkové cívky (bez třídění podle vnějšího vstupu) za stejných okolností. Chápu to tak, že tato zvláštnost existuje, protože bez ní by optimalizátor příliš často vybíral zařazování indexů.
Bez ohledu na to se nákladový model do určité míry přizpůsobí výše uvedenému pomocí různých počátečních a následných řádků I/O a nákladů na CPU pro indexové a tabulkové spooly. Čistým efektem je, že indexová cívka má obvykle nižší cenu než tabulková cívka bez tříděného vnějšího vstupu, ale pamatujte na omezující požadavky na tvar plánu, díky kterým jsou líné indexové cívky relativně vzácné.
Primárním cenovým konkurentem indexu líného spoolu je však stolní cívka s tříděný vnější vstup. Intuice je v tomto směru poměrně jednoduchá:Setříděný vnější vstup znamená, že cívka tabulky zaručeně uvidí všechny duplicitní vnější reference postupně. To znamená, že se znovu sváže pouze jednou za odlišnou hodnotu a přetočit zpět pro všechny duplikáty. To je stejné jako očekávané chování indexového zařazování (alespoň logicky vzato).
V praxi je pravděpodobnější, že bude upřednostňováno zařazování indexů před zařazováním tabulek optimalizovaných pro řazení, aby bylo méně duplicitních hodnot klíče pro použití. Menší počet duplicitních klíčů snižuje přetáčení zpět výhoda řazení tabulek optimalizovaných pro řazení ve srovnání s „nešťastnými“ odhady zařazování indexů zmíněnými dříve.
Možnost zařazování indexů také přináší výhody jako odhadované náklady na Řazení vnější strany zařazování tabulky zvyšuje. To by bylo nejčastěji spojeno s více (nebo širšími) řádky v daném bodě plánu.
Trace Flags and Hints
-
Zařazování výkonu lze zakázat s lehce zdokumentovaným příznakem trasování 8690 nebo zdokumentovaná nápověda k dotazu
NO_PERFORMANCE_SPOOLna SQL Server 2016 nebo novějším. -
Nezdokumentovaný příznak trasování 8691 lze použít (na testovacím systému) k vždy přidání výkonové cívky Pokud to bude možné. Typ lazy spool, který získáte (počet řádků, tabulka nebo index), nelze vynutit; stále to závisí na odhadu nákladů.
-
Nezdokumentovaný příznak trasování 2363 lze použít s novým modelem odhadu mohutnosti a zobrazit odvození odlišného odhadu na vnějším vstupu aplikace a odhad mohutnosti obecně.
-
Nezdokumentovaný příznak trasování 9198 lze použít k vypnutí zařazování výkonu líného indexu konkrétně. Stále můžete místo toho získat línou tabulku nebo zařazování počtu řádků (s optimalizací řazení nebo bez ní), v závislosti na kalkulaci.
-
Nezdokumentovaný příznak trasování 2387 lze použít ke snížení nákladů na CPU čtení řádků z líného indexového zařazování . Tento příznak ovlivňuje obecné odhady nákladů na CPU pro čtení řady řádků z b-stromu. Tento příznak zvyšuje pravděpodobnost výběru zařazování indexu z cenových důvodů.
Další příznaky trasování a metody k určení, která pravidla optimalizátoru byla aktivována během kompilace dotazu, lze nalézt v mé sérii Deep Dive nástroje Query Optimizer.
Závěrečné myšlenky
Existuje velké množství interních podrobností, které ovlivňují, zda konečný plán provádění používá zařazování výkonu nebo ne. Pokusil jsem se pokrýt hlavní úvahy v tomto článku, aniž bych zacházel příliš daleko do extrémně složitých detailů vzorců pro kalkulaci operátorů cívky. Doufejme, že je zde dostatek obecných rad, které vám pomohou určit možné důvody pro konkrétní typ zařazování výkonu v plánu provádění (nebo chybí).
Myslím, že je třeba říci, že výkonové cívky často špatně rapují. Něco z toho je bezpochyby zasloužené. Mnozí z vás viděli demo, kde se plán provádí rychleji bez „výkonové cívky“ než s. Do jisté míry to není neočekávané. Existují okrajové případy, model kalkulace není dokonalý a dema bezpochyby často obsahují plány se špatnými odhady mohutnosti nebo jinými problémy omezujícími optimalizaci.
To znamená, že si někdy přeji, aby SQL Server poskytl nějaké varování nebo jinou zpětnou vazbu, když se uchýlí k přidání líné tabulky spool do spojení vnořených smyček (nebo aplikace bez použitého podpůrného indexu na vnitřní straně). Jak bylo zmíněno v hlavní části, toto jsou situace, které se mi nejčastěji vyvíjejí špatně, když se odhady mohutnosti ukáží jako strašně nízké.
Možná jednoho dne optimalizátor dotazů zohlední určitou koncepci rizika při plánování voleb nebo poskytne více „adaptivních“ schopností. Mezitím se vyplatí podporovat vaše spojení vnořených smyček pomocí užitečných indexů a vyhnout se psaní dotazů, které lze implementovat pouze pomocí vnořených smyček, kde je to možné. Samozřejmě zobecňuji, ale optimalizátor má tendenci pracovat lépe, když má více možností, rozumné schéma, dobrá metadata a spravovatelné příkazy T-SQL. Stejně jako já o tom přemýšlím.
Jiné spoolové články
Nevýkonné zařazování se v rámci serveru SQL Server používají k mnoha účelům, včetně:
- Halloweenská ochrana
- Některé funkce okna v režimu řádků
- Výpočet více agregátů
- Optimalizace příkazů, které mění data