Změny v interní reprezentaci dělených tabulek mezi SQL Server 2005 a SQL Server 2008 vedly ve většině případů ke zlepšení plánů dotazů a výkonu (zejména při paralelním provádění). Bohužel stejné změny způsobily, že některé věci, které fungovaly dobře v SQL Server 2005, najednou nefungovaly tak dobře v SQL Server 2008 a novějších. Tento příspěvek se zabývá jedním příkladem, kdy optimalizátor dotazů SQL Server 2005 vytvořil lepší plán provádění ve srovnání s novějšími verzemi.
Vzorová tabulka a data
Příklady v tomto příspěvku používají následující rozdělenou tabulku a data:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Rozvržení rozdělených dat
Naše tabulka má rozdělený seskupený index. V tomto případě slouží klastrovací klíč také jako rozdělovací klíč (i když to obecně není požadavek). Výsledkem rozdělení jsou samostatné fyzické úložné jednotky (sady řádků), které procesor dotazů představuje uživatelům jako jednu entitu.
Níže uvedený diagram ukazuje první tři oddíly naší tabulky (kliknutím zvětšíte):
Neklastrovaný index je rozdělen stejným způsobem (je „zarovnán“):

Každý oddíl neklastrovaného indexu pokrývá rozsah hodnot RowID. V rámci každého oddílu jsou data řazena podle SomeData (ale hodnoty RowID nebudou řazeny obecně).
Problém MIN/MAX
Je poměrně dobře známo, že MIN a MAX agregace se neoptimalizují dobře na dělených tabulkách (pokud agregovaný sloupec není také dělicím sloupcem). O tomto omezení (které stále existuje v SQL Server 2014 CTP 1) se v průběhu let psalo mnohokrát; moje oblíbené pokrytí je v tomto článku od Itzika Ben-Gana. Pro stručnou ilustraci problému zvažte následující dotaz:
SELECT MIN(SomeData) FROM dbo.T4;
Plán provádění na serveru SQL Server 2008 nebo vyšším je následující:

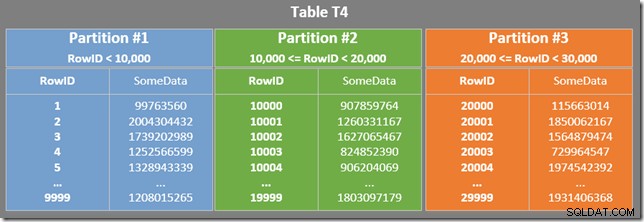
Tento plán přečte všech 150 000 řádků z indexu a Stream Aggregate vypočítá minimální hodnotu (plán provádění je v podstatě stejný, pokud místo toho požadujeme maximální hodnotu). Plán provádění SQL Server 2005 je mírně odlišný (i když ne lepší):
Tento plán iteruje přes čísla diskových oddílů (uvedených v neustálém prohledávání) a plně prohledává oddíly najednou. Všech 150 000 řádků je stále nakonec přečteno a zpracováno agregátem streamů.
Podívejte se zpět na diagramy rozdělené tabulky a indexu a přemýšlejte o tom, jak by bylo možné dotaz zpracovat efektivněji na naší datové sadě. Neklastrovaný index se zdá být dobrou volbou pro vyřešení dotazu, protože obsahuje hodnoty SomeData v pořadí, které by mohlo být zneužito při výpočtu agregace.
Skutečnost, že index je rozdělený na oddíly, nyní situaci trochu komplikuje:každý oddíl indexu je uspořádáno podle sloupce SomeData, ale nemůžeme jednoduše přečíst nejnižší hodnotu z žádné konkrétní oddíl, abyste získali správnou odpověď na celý dotaz.
Jakmile pochopíme podstatu problému, lidská bytost pochopí, že účinnou strategií by bylo najít jedinou nejnižší hodnotu SomeData v každém oddílu indexu a poté vezměte nejnižší hodnotu z výsledků na oddíl.
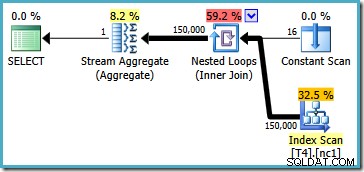
Toto je v podstatě řešení, které Itzik představuje ve svém článku; přepište dotaz tak, aby vypočítal agregaci na oddíl (pomocí APPLY syntaxe) a poté znovu agregovat přes výsledky pro jednotlivé oddíly. Pomocí tohoto přístupu přepsaný MIN dotaz vytvoří tento plán provádění (přesnou syntaxi najdete v Itzikově článku):
Tento plán čte čísla oddílů ze systémové tabulky a načítá nejnižší hodnotu SomeData v každém oddílu. Konečný agregát streamů pouze vypočítá minimum z výsledků na oddíl.
Důležitou funkcí tohoto plánu je, že čte jeden řádek z každého oddílu (s využitím pořadí řazení indexu v rámci každého oddílu). Je mnohem efektivnější než plán optimalizátoru, který zpracoval všech 150 000 řádků v tabulce.
MIN a MAX v rámci jednoho oddílu
Nyní zvažte následující dotaz, abyste našli minimální hodnotu ve sloupci SomeData pro rozsah hodnot RowID, které jsou obsaženy v rámci jednoho oddílu :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
Viděli jsme, že optimalizátor má potíže s MIN a MAX přes více oddílů, ale očekávali bychom, že se tato omezení nevztahují na dotaz na jeden oddíl.
Jediný oddíl je ten, který je ohraničen hodnotami RowID 10 000 a 20 000 (viz definice rozdělovací funkce). Funkce rozdělení byla definována jako RANGE RIGHT , takže hodnota hranice 10 000 patří oddílu #2 a hranice 20 000 patří oddílu #3. Rozsah hodnot RowID specifikovaný naším novým dotazem je proto obsažen v samotném oddílu 2.
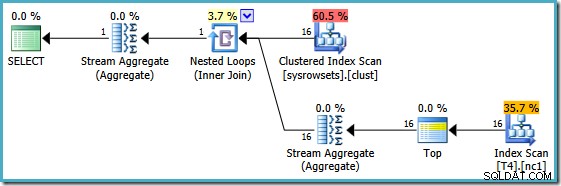
Grafické spouštěcí plány pro tento dotaz vypadají stejně na všech verzích SQL Serveru od roku 2005:
Analýza plánu
Optimalizátor použil rozsah RowID zadaný v WHERE klauzuli a porovnal ji s definicí funkce oddílu, aby určil, že je potřeba přistupovat pouze k oddílu 2 neklastrovaného indexu. Vlastnosti plánu SQL Server 2005 pro prohledávání indexu jasně ukazují přístup z jednoho oddílu:
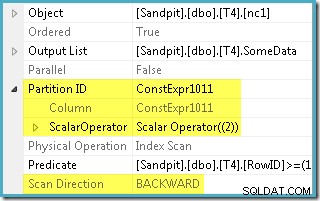
Další zvýrazněnou vlastností je Směr skenování. Pořadí skenování se liší v závislosti na tom, zda dotaz hledá minimální nebo maximální hodnotu SomeData. Neshlukovaný index je uspořádán (na oddíl, pamatujte) na vzestupných hodnotách SomeData, takže směr skenování indexu je FORWARD pokud dotaz požaduje minimální hodnotu, a BACKWARD pokud je potřeba maximální hodnota (výše uvedený snímek obrazovky byl převzat z MAX plán dotazů).
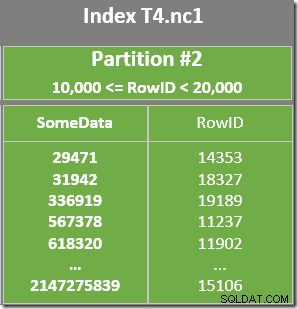
Na skenování indexu je také zbytkový predikát, který kontroluje, zda hodnoty RowID naskenované z oddílu 2 odpovídají WHERE větný predikát. Optimalizátor předpokládá, že hodnoty RowID jsou distribuovány docela náhodně prostřednictvím indexu bez klastrů, takže očekává, že najde první řádek, který odpovídá WHERE větný predikát docela rychle. Diagram rozvržení rozdělených dat ukazuje, že hodnoty RowID jsou skutečně zcela náhodně distribuovány v indexu (který je uspořádán podle sloupce SomeData pamatujte):
Operátor Top v plánu dotazů omezuje skenování indexu na jeden řádek (buď od spodního nebo horního konce indexu v závislosti na směru skenování). Skenování indexu může být problematické v plánech dotazů, ale operátor Top z něj dělá efektivní možnost:skenování může vždy vytvořit pouze jeden řádek, pak se zastaví. Kombinace Skenování horního a uspořádaného indexu efektivně provádí vyhledávání na nejvyšší nebo nejnižší hodnotu v indexu, která také odpovídá WHERE větné predikáty. V plánu se také objevuje Aggregate streamů, aby bylo zajištěno, že NULL se generuje v případě, že index Scan nevrací žádné řádky. Skalární MIN a MAX agregace jsou definovány tak, aby vracely NULL když je vstupem prázdná množina.
Celkově se jedná o velmi efektivní strategii a plány mají odhadovanou cenu pouhých 0,0032921 jednotky jako výsledek. Zatím je to dobré.
Problém s hraniční hodnotou
Tento další příklad upravuje horní konec rozsahu RowID:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
Všimněte si, že dotaz vylučuje hodnotu 20 000 pomocí operátoru „menší než“. Připomeňme, že hodnota 20 000 patří oddílu 3 (ne oddílu 2), protože funkce oddílu je definována jako RANGE RIGHT . SQL Server2005 optimalizátor tuto situaci řeší správně a vytváří optimální plán dotazů s jednou oblastí s odhadovanými náklady 0,0032878 :
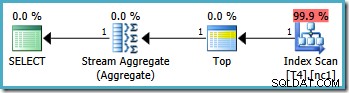
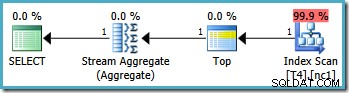
Stejný dotaz však vytvoří jiný plán na SQL Server2008 a novějších (včetně SQL Server 2014 CTP 1):
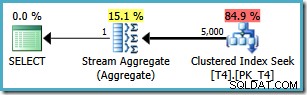
Nyní máme Clustered Index Seek (místo požadované kombinace Index Scan a Top operátor). Všech 5 000 řádků, které odpovídají WHERE klauzule jsou v tomto novém prováděcím plánu zpracovávány prostřednictvím Stream Aggregate. Odhadovaná cena tohoto plánu je 0,0199319 jednotek – více než šestkrát náklady na plán SQL Server 2005.
Příčina
Optimalizátory SQL Server 2008 (a novější) nezískají zcela správnou vnitřní logiku, když interval odkazuje, ale vyloučí , hraniční hodnota patřící jinému oddílu. Optimalizátor se nesprávně domnívá, že bude přístup k více oddílům, a dojde k závěru, že nemůže použít optimalizaci pro jeden oddíl pro MIN a MAX agregáty.
Řešení
Jednou z možností je přepsat dotaz pomocí operátorů>=a <=, abychom neodkazovali na hraniční hodnotu z jiného oddílu (ani abychom ji vyloučili!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
Výsledkem je optimální plán dotýkající se jednoho oddílu:
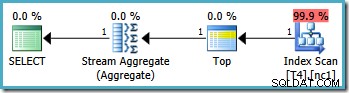
Bohužel ne vždy je možné tímto způsobem určit správné hraniční hodnoty (v závislosti na typu rozdělovacího sloupce). Příkladem jsou typy data a času, kde je nejlepší použít intervaly napůl otevřené. Další námitka proti tomuto řešení je subjektivnější:rozdělovací funkce vylučuje jednu hranici z rozsahu, takže se zdá nejpřirozenější napsat dotaz také pomocí syntaxe polootevřeného intervalu.
Druhým řešením je explicitně zadat číslo oddílu (a zachovat interval polovičního otevření):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
To vytváří optimální plán, který je nákladný na vyžadování dalšího predikátu a spoléhání se na uživatele, aby zjistil, jaké by mělo být číslo oddílu.
Samozřejmě by bylo lepší, kdyby optimalizátory z roku 2008 a novější vytvořily stejný optimální plán jako SQL Server 2005. V dokonalém světě by komplexnější řešení také řešilo případ s více oddíly, takže řešení, které Itzik popisuje, je také zbytečné.