Rozdělení tabulek na SQL Server je v podstatě způsob, jak zajistit, aby více fyzických tabulek (sady řádků) vypadalo jako jedna tabulka. Tuto abstrakci provádí výhradně procesor dotazů, což je návrh, který uživatelům zjednodušuje věci, ale klade složité požadavky na optimalizátor dotazů. Tento příspěvek se zabývá dvěma příklady, které přesahují schopnosti optimalizátoru v SQL Server 2008 a dále.
Připojte se k záležitosti objednávky sloupce
Tento první příklad ukazuje, jak je textové pořadí ON podmínky klauzule mohou ovlivnit plán dotazů vytvořený při spojování dělených tabulek. Pro začátek potřebujeme rozdělovací schéma, rozdělovací funkci a dvě tabulky:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); Dále načteme obě tabulky se 150 000 řádky. Na datech příliš nezáleží; tento příklad používá jako zdroj dat standardní tabulku Numbers obsahující všechny celočíselné hodnoty od 1 do 150 000. Obě tabulky jsou načteny stejnými daty.
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
Náš testovací dotaz provede jednoduché vnitřní spojení těchto dvou tabulek. Opět platí, že dotaz není důležitý ani není zamýšlen jako zvlášť realistický, používá se k demonstraci zvláštního efektu při spojování dělených tabulek. První forma dotazu používá ON klauzule zapsaná ve sloupcovém pořadí c3, c2, c1:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1; Plán provádění vytvořený pro tento dotaz (na SQL Server 2008 a novějších) obsahuje paralelní spojení hash s odhadovanými náklady 2,6953 :
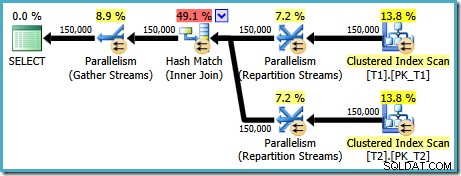
To je trochu nečekané. Obě tabulky mají seskupený index v pořadí (c1, c2, c3), rozdělený podle c1, takže bychom očekávali slučovací spojení s využitím uspořádání indexu. Zkusme napsat ON klauzule v pořadí (c1, c2, c3):
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; Plán provádění nyní používá očekávané spojení sloučení s odhadovanými náklady 1,64119 (pokles z 2,6953 ). Optimalizátor také rozhodne, že nemá cenu používat paralelní spouštění:
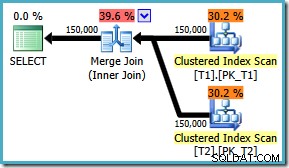
Všimněte si, že plán spojení sloučení je jasně efektivnější, můžeme se pokusit vynutit sloučení spojení pro původní ON pořadí klauzulí pomocí nápovědy dotazu:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); Výsledný plán používá slučovací spojení, jak je požadováno, ale také obsahuje řazení na obou vstupech a vrací se k použití paralelismu. Odhadovaná cena tohoto plánu je neuvěřitelných 8,71063 :
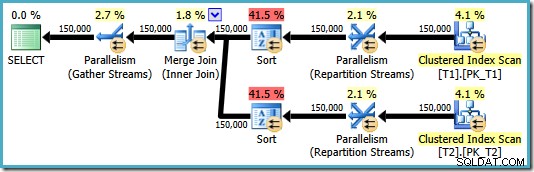
Oba operátory řazení mají stejné vlastnosti:
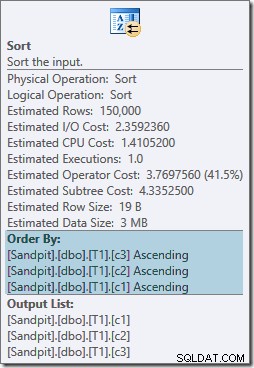
Optimalizátor se domnívá, že sloučení spojení potřebuje své vstupy seřazené v přísném písemném pořadí ON klauzule, která jako výsledek zavádí explicitní druhy. Optimalizátor si je vědom toho, že slučovací spojení vyžaduje jeho vstupy seřazené stejným způsobem, ale také ví, že na pořadí sloupců nezáleží. Sloučit spojení na (c1, c2, c3) je stejně spokojené se vstupy seřazenými na (c3, c2, c1), jako se vstupy seřazenými na (c2, c1, c3) nebo jakoukoli jinou kombinací.
Bohužel tato úvaha je v optimalizátoru dotazů narušena, když se jedná o rozdělení. Toto je chyba optimalizátoru který byl opraven v SQL Server 2008 R2 a novějších, ačkoli příznak trasování 4199 je vyžadováno k aktivaci opravy:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
Tento příznak trasování byste normálně povolili pomocí DBCC TRACEON nebo jako možnost spuštění, protože QUERYTRACEON nápověda není zdokumentována pro použití s 4199. Příznak trasování je vyžadován v SQL Server 2008 R2, SQL Server 2012 a SQL Server 2014 CTP1.
Bez ohledu na to, zda je příznak povolen, dotaz nyní vytváří optimální slučovací spojení bez ohledu na to, zda je ON řazení doložek:
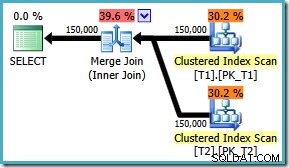
Pro SQL Server 2008 neexistuje žádná oprava , řešením je napsat ON doložka ve „správném“ pořadí! Pokud na SQL Server 2008 narazíte na dotaz, jako je tento, zkuste vynutit slučovací spojení a podívejte se na řazení, abyste určili „správný“ způsob, jak zapsat dotaz ON doložka.
Tento problém se nevyskytuje v SQL Server 2005, protože toto vydání implementovalo dělené dotazy pomocí APPLY model:

Plán dotazů SQL Server 2005 spojuje vždy jeden oddíl z každé tabulky pomocí tabulky v paměti (Constant Scan) obsahující čísla oddílů ke zpracování. Každý oddíl je sloučen samostatně na vnitřní straně spojení a optimalizátor 2005 je dostatečně chytrý, aby viděl, že ON na pořadí sloupců klauzule nezáleží.
Tento nejnovější plán je příkladem kolokovaného sloučení , zařízení, které bylo ztraceno při přechodu ze serveru SQL Server 2005 na novou implementaci rozdělení na SQL Server 2008. Návrh na Connect pro obnovení kolokovaných sloučení spojení byl uzavřen jako Neopraví.
Seskupit podle záležitostí objednávky
Druhá zvláštnost, na kterou se chci podívat, sleduje podobné téma, ale týká se pořadí sloupců v GROUP BY klauzule spíše než ON klauzule vnitřního spojení. K demonstraci budeme potřebovat novou tabulku:
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; Tabulka má zarovnaný neseskupený index, kde „zarovnaný“ jednoduše znamená, že je rozdělena stejným způsobem jako seskupený index (nebo halda):
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
Náš testovací dotaz seskupuje data do tří neshlukovaných indexových sloupců a vrací počet pro každou skupinu:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
Plán dotazů prohledá neclusterovaný index a použije Hash Match Aggregate k počítání řádků v každé skupině:
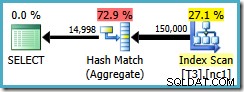
Hash Aggregate má dva problémy:
- Je to operátor blokování. Klientovi nejsou vráceny žádné řádky, dokud nebudou všechny řádky agregovány.
- K uložení hashovací tabulky vyžaduje přidělení paměti.
V mnoha scénářích reálného světa bychom zde preferovali Stream Aggregate, protože tento operátor blokuje pouze skupinu a nevyžaduje přidělení paměti. Při použití této možnosti by klientská aplikace začala přijímat data dříve, nemusela by čekat na přidělení paměti a SQL Server by mohl paměť používat pro jiné účely.
Můžeme požadovat, aby optimalizátor dotazů použil pro tento dotaz agregát streamu přidáním OPTION (ORDER GROUP) nápověda k dotazu. Výsledkem je následující plán provádění:

Operátor řazení je plně blokován a také vyžaduje přidělení paměti, takže tento plán se zdá být horší než pouhé použití hash agregátu. Ale proč je takový druh potřeba? Vlastnosti ukazují, že řádky jsou seřazeny v pořadí určeném naším GROUP BY klauzule:
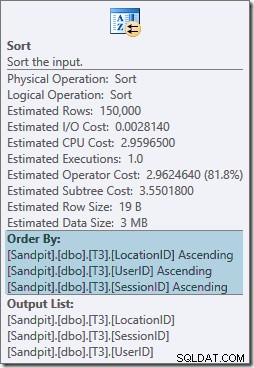
Toto řazení je očekávané protože zarovnání indexu podle oddílu (v SQL Server 2008 a novější) znamená, že číslo oddílu je přidáno jako úvodní sloupec indexu. Ve skutečnosti jsou klíče indexu bez klastrů (oddíl, uživatel, relace, umístění) způsobeny rozdělením. Řádky v indexu jsou stále seřazeny podle uživatele, relace a umístění, ale pouze v rámci každého oddílu.
Pokud omezíme dotaz na jeden oddíl, měl by být optimalizátor schopen použít index k naplnění agregátu streamu bez řazení. V případě, že to vyžaduje nějaké vysvětlení, určení jednoho oddílu znamená, že plán dotazů může odstranit všechny ostatní oddíly z neklastrovaného indexového skenování, což má za následek proud řádků seřazených podle (uživatele, relace, umístění).
Tohoto odstranění oddílu můžeme dosáhnout explicitně pomocí $PARTITION funkce:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
Bohužel tento dotaz stále používá hash Aggregate s odhadovanou cenou plánu 0,287878 :
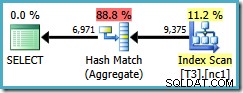
Skenování nyní probíhá těsně nad jedním oddílem, ale řazení (uživatel, relace, umístění) nepomohlo optimalizátoru použít agregát streamu. Můžete namítnout, že řazení (uživatel, relace, umístění) není užitečné, protože GROUP BY klauzule je (umístění, uživatel, relace), ale pro operaci seskupení nezáleží na pořadí klíčů.
Pojďme přidat ORDER BY klauzule v pořadí indexových klíčů k prokázání bodu:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
Všimněte si, že ORDER BY klauzule odpovídá pořadí indexových klíčů bez seskupení, ačkoli GROUP BY doložka ne. Plán provádění tohoto dotazu je:
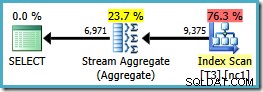
Nyní máme Stream Aggregate, o který jsme usilovali, s odhadovanou cenou plánu 0,0423925 (ve srovnání s 0,287878 pro plán Hash Aggregate – téměř 7krát více).
Dalším způsobem, jak zde dosáhnout agregátu streamů, je změnit pořadí GROUP BY sloupců, aby odpovídaly neklastrovaným indexovým klíčům:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
Tento dotaz vytvoří stejný plán Stream Aggregate zobrazený bezprostředně výše s přesně stejnými náklady. Tato citlivost na GROUP BY pořadí sloupců je specifické pro dotazy dělené tabulky v SQL Server 2008 a novějších.
Možná uznáte, že hlavní příčina problému je zde podobná předchozímu případu zahrnujícímu sloučení spojení. Jak Merge Join, tak Stream Aggregate vyžadují vstup seřazený podle klíčů spojení nebo agregace, ale ani jeden se nestará o pořadí těchto klíčů. Sloučení spojení na (x, y, z) je stejně šťastné přijímání řádků uspořádaných podle (y, z, x) nebo (z, y, x) a totéž platí pro agregaci streamů.
Toto omezení optimalizátoru platí také pro DISTINCT za stejných okolností. Výsledkem následujícího dotazu je plán Hash Aggregate s odhadovanou cenou 0,286539 :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
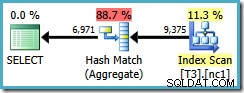
Pokud napíšeme DISTINCT sloupce v pořadí neklastrovaných indexových klíčů…
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
…jsme odměněni plánem Stream Aggregate s cenou 0,041455 :

Abych to shrnul, toto je omezení optimalizátoru dotazů v SQL Server 2008 a novějších (včetně SQL Server 2014 CTP 1), které není vyřešeno pomocí příznaku trasování 4199 jako tomu bylo u příkladu Merge Join. Problém nastává pouze u dělených tabulek s GROUP BY nebo DISTINCT přes tři nebo více sloupců pomocí zarovnaného rozděleného indexu, kde se zpracovává jeden oddíl.
Stejně jako v příkladu Merge Join to představuje krok zpět od chování SQL Server 2005. SQL Server 2005 nepřidal implicitní úvodní klíč k rozděleným indexům pomocí APPLY technika místo toho. V SQL Server 2005 jsou zde všechny dotazy prezentovány pomocí $PARTITION k určení výsledku jednoho oddílu v plánech dotazů, které provádějí eliminaci oddílů, a použití agregací proudu bez jakéhokoli přeuspořádání textu dotazu.
Změny ve zpracování dělených tabulek v SQL Server 2008 zlepšily výkon v několika důležitých oblastech, především souvisejících s efektivním paralelním zpracováním oddílů. Bohužel tyto změny měly vedlejší účinky, které nebyly všechny vyřešeny v pozdějších verzích.