Dodatek: SQL Server 2012 vykazuje v této oblasti určitý zlepšený výkon, ale nezdá se, že by řešil konkrétní problémy uvedené níže. To by zřejmě mělo být opraveno v další hlavní verzi po SQL Server 2012!
Váš plán ukazuje, že jednotlivé vložky používají parametrizované procedury (možná automaticky parametrizované), takže doba jejich analýzy/kompilace by měla být minimální.
Myslel jsem, že se na to podívám trochu víc, takže jsem nastavil smyčku (skript) a zkusil upravit počet VALUES klauzule a záznam času kompilace.
Poté jsem vydělil dobu kompilace počtem řádků, abych získal průměrnou dobu kompilace na klauzuli. Výsledky jsou níže
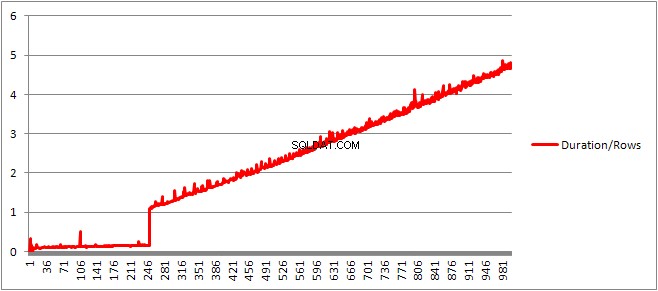
Až do 250 VALUES klauzule představují čas kompilace / počet klauzulí má mírně rostoucí trend, ale není to příliš dramatické.
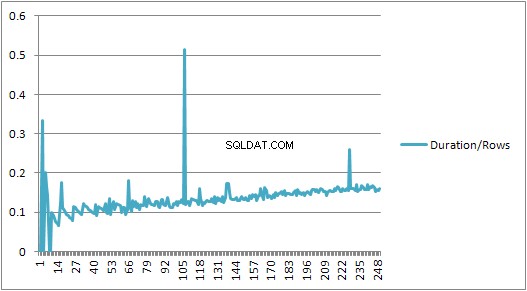
Ale pak dojde k náhlé změně.
Tato část dat je uvedena níže.
+------+----------------+-------------+---------------+---------------+
| Rows | CachedPlanSize | CompileTime | CompileMemory | Duration/Rows |
+------+----------------+-------------+---------------+---------------+
| 245 | 528 | 41 | 2400 | 0.167346939 |
| 246 | 528 | 40 | 2416 | 0.162601626 |
| 247 | 528 | 38 | 2416 | 0.153846154 |
| 248 | 528 | 39 | 2432 | 0.157258065 |
| 249 | 528 | 39 | 2432 | 0.156626506 |
| 250 | 528 | 40 | 2448 | 0.16 |
| 251 | 400 | 273 | 3488 | 1.087649402 |
| 252 | 400 | 274 | 3496 | 1.087301587 |
| 253 | 400 | 282 | 3520 | 1.114624506 |
| 254 | 408 | 279 | 3544 | 1.098425197 |
| 255 | 408 | 290 | 3552 | 1.137254902 |
+------+----------------+-------------+---------------+---------------+
Velikost plánu uloženého v mezipaměti, která rostla lineárně, náhle poklesne, ale CompileTime se zvýší 7krát a CompileMemory vystřelí nahoru. Toto je hraniční bod mezi plánem, který je automaticky parametrizovaný (s 1 000 parametry) a neparametrickým plánem. Poté se zdá být lineárně méně efektivní (z hlediska počtu hodnotových klauzulí zpracovaných za daný čas).
Nejste si jisti, proč by to mělo být. Pravděpodobně při sestavování plánu pro konkrétní doslovné hodnoty musí provádět nějakou činnost, která se neškáluje lineárně (jako je třídění).
Nezdá se, že by to ovlivnilo velikost plánu dotazů uložených v mezipaměti, když jsem zkoušel dotaz sestávající výhradně z duplicitních řádků, a ani to neovlivňuje pořadí výstupu tabulky konstant (a když vkládáte do hromady čas strávený tříděním by stejně bylo zbytečné, i kdyby ano).
Navíc pokud je do tabulky přidán seskupený index, plán stále zobrazuje explicitní krok řazení, takže se nezdá, že by třídil v době kompilace, aby se zabránilo řazení za běhu.

Zkoušel jsem se na to podívat v debuggeru, ale zdá se, že veřejné symboly pro mou verzi SQL Server 2008 nejsou dostupné, takže jsem se musel podívat na ekvivalentní UNION ALL konstrukce v SQL Server 2005.
Typické trasování zásobníku je níže
sqlservr.exe!FastDBCSToUnicode() + 0xac bytes
sqlservr.exe!nls_sqlhilo() + 0x35 bytes
sqlservr.exe!CXVariant::CmpCompareStr() + 0x2b bytes
sqlservr.exe!CXVariantPerformCompare<167,167>::Compare() + 0x18 bytes
sqlservr.exe!CXVariant::CmpCompare() + 0x11f67d bytes
sqlservr.exe!CConstraintItvl::PcnstrItvlUnion() + 0xe2 bytes
sqlservr.exe!CConstraintProp::PcnstrUnion() + 0x35e bytes
sqlservr.exe!CLogOp_BaseSetOp::PcnstrDerive() + 0x11a bytes
sqlservr.exe!CLogOpArg::PcnstrDeriveHandler() + 0x18f bytes
sqlservr.exe!CLogOpArg::DeriveGroupProperties() + 0xa9 bytes
sqlservr.exe!COpArg::DeriveNormalizedGroupProperties() + 0x40 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x18a bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!CQuery::PqoBuild() + 0x3cb bytes
sqlservr.exe!CStmtQuery::InitQuery() + 0x167 bytes
sqlservr.exe!CStmtDML::InitNormal() + 0xf0 bytes
sqlservr.exe!CStmtDML::Init() + 0x1b bytes
sqlservr.exe!CCompPlan::FCompileStep() + 0x176 bytes
sqlservr.exe!CSQLSource::FCompile() + 0x741 bytes
sqlservr.exe!CSQLSource::FCompWrapper() + 0x922be bytes
sqlservr.exe!CSQLSource::Transform() + 0x120431 bytes
sqlservr.exe!CSQLSource::Compile() + 0x2ff bytes
Takže když vynecháte názvy ve trasování zásobníku, zdá se, že strávíte spoustu času porovnáváním řetězců.
Tento článek znalostní báze uvádí, že DeriveNormalizedGroupProperties je spojen s tím, co se dříve nazývalo normalizační fáze zpracování dotazů
Tato fáze se nyní nazývá vazba nebo algebrizace a přebírá výstup stromu analýzy výrazů z předchozí fáze analýzy a vydává algebrizovaný strom výrazů (strom procesoru dotazů), aby pokračoval k optimalizaci (v tomto případě triviální optimalizace plánu) [ref].
Zkusil jsem ještě jeden experiment (Skript), který měl znovu spustit původní test, ale zkoumal jsem tři různé případy.
- Řetězce jména a příjmení o délce 10 znaků bez duplicit.
- Řetězce jména a příjmení o délce 50 znaků bez duplicit.
- Řetězce jména a příjmení o délce 10 znaků se všemi duplikáty.
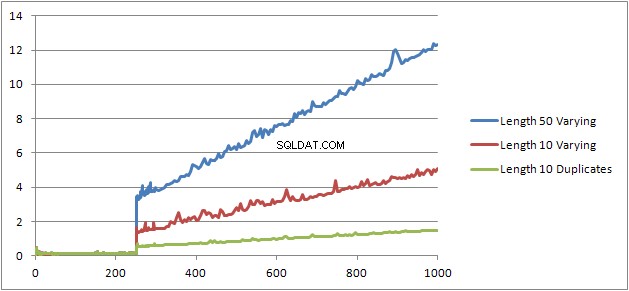
Je jasně vidět, že čím delší struny, tím horší věci a naopak čím více duplikátů, tím lepší věci. Jak již bylo zmíněno, duplikáty neovlivňují velikost plánu uloženého v mezipaměti, takže předpokládám, že při vytváření samotného algebrizovaného stromu výrazů musí existovat proces duplicitní identifikace.
Upravit
Jedno místo, kde se tyto informace využívají, ukazuje @Lieven zde
SELECT *
FROM (VALUES ('Lieven1', 1),
('Lieven2', 2),
('Lieven3', 3))Test (name, ID)
ORDER BY name, 1/ (ID - ID)
Protože v době kompilace může určit, že Name sloupec nemá žádné duplikáty, přeskakuje řazení podle sekundárního 1/ (ID - ID) výraz za běhu (řazení v plánu má pouze jeden ORDER BY sloupec) a nevznikne chyba dělení nulou. Pokud jsou do tabulky přidány duplikáty, operátor řazení zobrazí dva sloupce a očekávaná chyba je vyvolána.