POZNÁMKY:
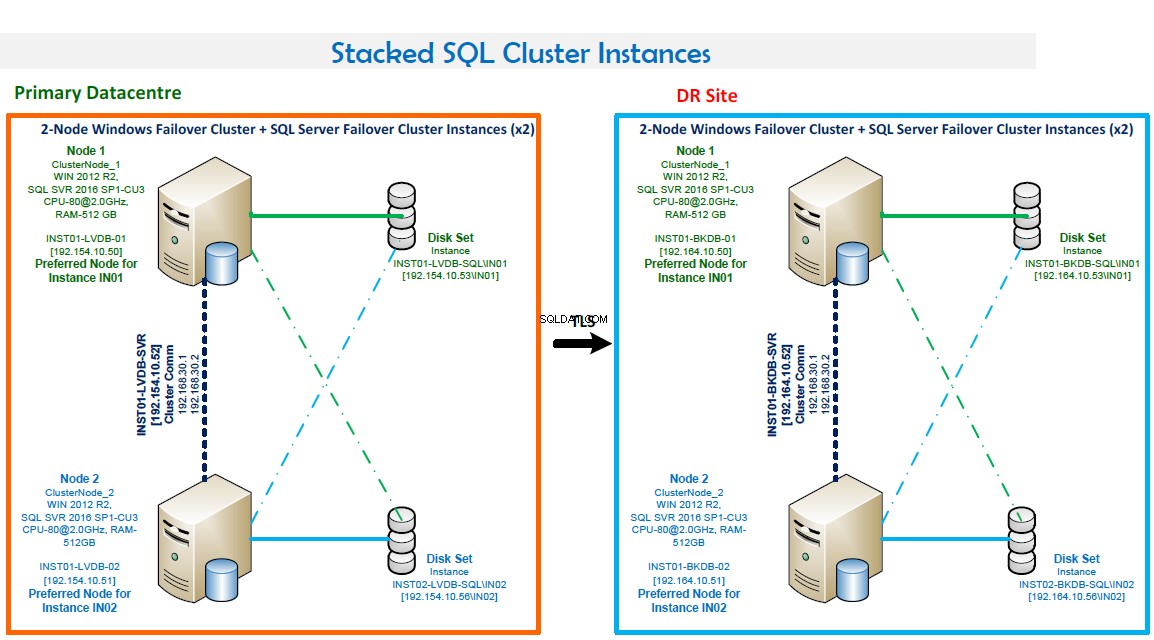
- Windows Failover Clustering obsahující dva uzly.
- Dvě instance SQL Server Failover Cluster. Tato konfigurace optimalizuje hardware. IN01 je preferován na Node1 a IN02 je preferován na Node2.
- Čísla portů:IN01 naslouchá na portu 1435 a IN02 naslouchá na portu 1436.
- Vysoká dostupnost. Oba uzly se vzájemně zálohují. Přepnutí při selhání je v případě selhání automatické.
- Režim kvora je většinový uzel a disk.
- Zálohování LAN na místě a rutinní zálohování nakonfigurované pomocí Veritas
Úvod
Není neobvyklé, že vývojáři a projektoví manažeři požadují pro každou novou aplikaci nebo službu novou instanci SQL Serveru. Zatímco díky technologiím jako virtualizace a cloud je vytváření nových instancí hračkou, některé letité techniky zabudované do SQL Serveru umožňují dosáhnout nízkých časů obratu, když je potřeba poskytnout novou databázi pro novou službu nebo aplikaci. Tento stav věcí může vytvořit DBA, který může navrhnout a nasadit velký cluster SQL Server schopný podporovat většinu databází SQL Server požadovaných organizací. Tento druh konsolidace má další výhody, jako jsou nižší náklady na licence, lepší správa a snadná správa. V článku zdůrazníme některé úvahy, které jsme měli možnost zažít při používání clusterů a stohování jako prostředku ke konsolidaci databází SQL Server.
Shlukování
Windows Server Failover Clustering je velmi dobře známé řešení s vysokou dostupností, které přežilo mnoho verzí systému Windows Server a do kterého hodlá společnost Microsoft nadále investovat a vylepšovat jej. Instance SQL Server Failover Cluster se spoléhají na WSFC. Standardní i Enterprise Edition serveru SQL Server podporují instance SQL Server Failover Cluster Instance, ale Standard Edition je omezena pouze na dva uzly. Konsolidace databází do jediného SQL Server FCI poskytuje výhody jako:
- HA ve výchozím nastavení — Všechny databáze nasazené na clusterové instanci SQL Serveru jsou ve výchozím nastavení vysoce dostupné! Jakmile je vytvořena klastrovaná instance, o nová nasazení je postaráno z hlediska HA s předstihem.
- Snadná administrace – Méně správců databází může trávit čas konfigurací, monitorováním a v případě potřeby řešením problémů JEDNA klastrovaná instance podporující mnoho aplikací. Správně je dokumentování instance také mnohem snazší při práci s jedním velkým prostředím. Konfigurace řešení Enterprise Backup pro zpracování všech databází ve vašem prostředí je snazší díky skutečnosti, že při použití konsolidovaných instancí musíte provést tuto konfiguraci pouze u jedné.
- Soulad – Takové klíčové požadavky, jako je záplatování a dokonce i zpevnění, lze provést jednou s minimálními prostoji na velkém počtu databází v jediném administrativním úsilí. V našem obchodě jsme použili Transaction Log Shipping mezi clusterovanými instancemi ve dvou datových centrech, abychom zajistili ochranu databází před rizikem katastrof.
- Standardizace – Prosazování takových standardů, jako jsou konvence pojmenování, správa přístupu, ověřování systému Windows, auditování a správa založená na zásadách, je mnohem snazší, když se zabýváte pouze jedním nebo dvěma prostředími v závislosti na velikosti vašeho obchodu
Zápis 1: Extrahujte informace o vaší instanci
-- Extrahujte podrobnosti instance-- Zahrnuje sloupec pro kontrolu, zda je instance klastrovaná SELECT SERVERPROPERTY('MachineName') AS [MachineName], SERVERPROPERTY('ServerName') AS [ServerName], SERVERPROPERTY('InstanceName') AS [ Instance], SERVERPROPERTY('IsClustered') AS [IsClustered], SERVERPROPERTY('ComputerNamePhysicalNetBIOS') AS [ComputerNamePhysicalNetBIOS] , SERVERPROPERTY('Edition') AS [Edition], SERVERPROductLevel'LEPERTYProvel], SERVERLEVERTYProduct(PROVEL) ProductVersion') JAKO [ProductVersion], SERVERPROPERTY('ProcessID') JAKO [ProcessID], SERVERPROPERTY('Collation') JAKO [Collation], SERVERPROPERTY('IsFullTextInstalled') AS [IsFullTextInstalled], SERVERIngratedlyOnly'SgratedlySecuredly ], SERVERPROPERTY('IsHadrEnabled') JAKO [IsHadrEnabled], SERVERPROPERTY('HadrManagerStatus') JAKO [HadrManagerStatus], SERVERPROPERTY('IsXTPSupported') JAKO [IsXTPSupported]; Skládání
SQL Server podporuje až padesát jednotlivých instancí na jednom serveru a až 25 instancí clusteru s podporou převzetí služeb při selhání na clusteru s podporou převzetí služeb při selhání systému Windows. Různé verze SQL Serveru lze naskládat do stejného prostředí, aby bylo zajištěno robustní prostředí, které bude podporovat různé aplikace. V takové konfiguraci může mít upgrade databází formu jejich jednoduchého povýšení z jedné instance SQL Serveru na další verzi ve stejném clusteru, dokud hardware nezestárne. Jedním z klíčových aspektů, které je třeba mít na paměti při stohování SQL Server, je to, že musíte přidělit paměť každé instanci takovým způsobem, aby celkové množství přidělené paměti nepřekročilo dostupnou paměť v operačním systému. Dalším bodem v tomto směru je zajistit, aby účet služby SQL Server pro každou instanci měl oprávnění k uzamčení stránek v paměti. Přiřazení zamykacích stránek v paměti zajišťuje, že když SQL Server získá paměť, operační systém se nepokusí takovou paměť obnovit, když paměť potřebují jiné procesy na serveru. Nastavení definovaného účtu služby SQL Server, konfigurace MAX_SERVER_MEMORY a udělení oprávnění Uzamknout stránky v paměti jsou nezbytnou trojicí při skládání instancí SQL Serveru.
Microsoft si účtuje pár tisíc dolarů za pár jader CPU. Skládání instancí SQL Server vám umožňuje využít tento model licencování tím, že instance sdílejí stejnou sadu procesorů (vytváření aktiv). Již jsme zmínili, že můžete skládat různé verze SQL Serveru, a tak se starat o starší aplikace, které stále běží na verzích starších než SQL Server 2016, například. Při používání různých edic SQL Server můžete zvážit použití Processor Affinity, jak je popsáno Glenem Berrym v tomto článku. Processor Affinity lze také použít k řízení toho, jak jsou prostředky CPU sdíleny mezi instancemi, stejně jako ovládáte paměť. Stohování také řeší problémy se zabezpečením aplikací, které musí například používat účet SA, nebo problémy s konfigurací pro aplikace, které vyžadují vyhrazenou instanci, nebo takové možnosti představují specifické řazení. Obavy o výkon sdílené TempDB jsou dalším důvodem, proč možná budete chtít skládat databáze místo hromadění všech databází do jedné klastrované instance.
Stojí za zmínku, že hodnota shlukování, jak bylo zdůrazněno dříve, se skládáním ještě dále rozšiřuje. Například při záplatování instance SQL Serveru s několika FCI lze všechny FCI opravit najednou.
Upozornění
Při použití klastrování určité konvence trochu usnadní správu a správu prostředí a lépe pocení aktiva. Několika z nich se krátce dotkneme:
- Aktuální klientské nástroje – Při pokusu o správu instance SQL Server 2016 pomocí SQL Server Management Studio 2012 se mohou objevit neobvyklé chyby. Chyby konkrétně neříkají, že problémem je verze klientského nástroje. Na klientovi, kterého chceme použít k připojení k našim instancím, máme obvykle instanci SQL Server Management Studio 17.3.
- Konvence názvů – Konvence názvů vám usnadní jistotu, na které instanci v kterémkoli okamžiku pracujete. Pomocí aliasů můžete u koncových uživatelů, kteří potřebují přístup k databázi, dále snížit zátěž související s zapamatováním dlouhého názvu instance.
- Preferovaný uzel – Nastavení preferovaného uzlu pro každou roli serveru SQL ve Správci klastrů s podporou převzetí služeb při selhání je dobrý nápad, dobrý způsob, jak zajistit využití výpočetního výkonu všech vašich uzlů klastru. V našem obchodě jsme po nastavení preferovaných uzlů nakonfigurovali roli tak, aby se v případě neúmyslného selhání vrátila mezi 05:00 a 06:00 HRS.
- Doprava protokolu transakcí – Při konfiguraci zotavení po havárii pro FCI má smysl identifikovat všechny cesty UNC pomocí virtuálních názvů, nikoli názvů nebo IP adres uzlů clusteru. To zajišťuje, že věci budou nadále správně fungovat, pokud dojde k převzetí služeb při selhání. Je také velmi důležité zajistit, aby účty SQL Server Agent na obou stránkách měly plnou kontrolu nad těmito cestami.
Zápis 2: Nakonfigurujte sledování pro odesílání protokolu transakcí pomocí e-mailu
-- Create Table to Store Log Shipping DataCreate tabulky msdb dbo log_shipping_report (stavový bit, is_primary bit, server sysname, database_name sysname, time_since_last_backup int, last_backup_file nvarchar (500), backup_threshold int, is_primary bit int, is_primary bit, sysname ), time_since_last_restore int, last_restored_file nvarchar(500), last_restored_latency int, restore_threshold int, is_restore_alert_enabled bit); go-- Vytvořte úlohu agenta SQL pomocí následujícího skriptu-- Toto odešle e-mail v intervalech určených plánem úlohy-- Úloha by měla být vytvořena v protokolu Odesílání Sekundární klastrovaná instance-- Tato úloha vyžaduje, aby Database Mail byla povolena. tabulka msdb dbo log_shipping_report jde vložit do msdb dbo log_shipping_report EXEC sp_help_log_shipping_monitor; go/*select [server], database_name [database], time_since_last_copy [Time Last Copy Time], last_copied_file [Last Copied File], time_since_last_restore [Last Restore Time], last_restored_file [Last Restored File], restore_threshold_threshold] -last_threshold_restore_threshold [Restore_threshold_threshold] [Obnovit latenci] z msdb.dbo.log_shipping_report; go */DECLARE @tableHTML NVARCHAR(MAX);DECLARE @SecServer SYSNAME;SET @SecServer =@@SERVERNAMESET @tableHTML =N'Stav protokolu transakce ze sekundárního serveru ' + @SecServer + N'
' +N'Níže najdete stav sekundárních databází:
' +N'
| Sekundární server | Sekundární databáze | Čas poslední kopie | ' +N'Poslední zkopírovaný soubor | Čas posledního obnovení | ' +N'Poslední obnovený soubor | Práh obnovení | Restore Latency | ' + CAST ( ( SELECT td =lsr.server, '',td =lsr [název_databáze], td =lsr time_since_last_copy '',td =lsr last_copied_file td_sincela_time) , td =lsr last_restored_file, '', td =lsr restore_threshold '', td =casewhen lsr restore_thresholdlsr time_since_last_restore <0 then + '#FFBB3 ' + 'WARNING' + ' | 'když lsr restore_thresholdlsr time_since_last_restore> 20 pak + '' + 'OK' + ' | 'end , ''OD msdb dbo log_shipping_report as lsrORDER BY lsr .[database_name]PRO XML PATH('tr'), TYPE ) AS NVARCHAR(MAX) ) +N'
|---|
Diskové jednotky
Jedním z vedlejších efektů skládání instance SQL Server a vytváření rezerv pro několik databází je tendence docházet písmena jednotek. Tento problém jsme obešli konfigurací Volume Mount Points. Každý disk přiřazený k roli clusteru je nakonfigurován jako bod připojení s písmenem jednotky, které je nutné pouze pro jednu nebo dvě jednotky na instanci. Při používání přípojných bodů svazku v clusteru je důležité poznamenat, že v budoucnu, když budete potřebovat přidat další přípojné body k provádění podobných úloh údržby, bude nutné umístit OBA primární disk, který vlastní písmeno jednotky, i přípojný bod v režimu údržby na clusteru.
V našem případě jsme našli název každého přípojného bodu svazku na základě role clusteru, ke které byl přiřazen. S tolika jednotkami, se kterými se musíte vypořádat, budete určitě muset vymyslet způsob, jak vy i správce úložiště identifikovat jedinečný disk, takže například údržba disků na úrovni úložiště by nebyla příliš obtížná.
Zápis 3: Sledování využití místa na disku při použití přípojných bodů svazku
-- Následující skript ukáže využití místa na disku ze serveru SQL Server -- To je zvláště užitečné při použití přípojných bodů svazku -- Využití místa přípojného bodu svazku lze také monitorovat ze správy počítače (úroveň operačního systému) SELECT DISTINCT vs volume_mount_point , vs file_system_type , vs logical_volume_name, CONVERT(DECIMAL!18 2 vs total_bytes 1073741824.0) AS [Celková velikost (GB)], CONVERT(DECIMAL(18 2 vs. dostupné_bajty 1073741824GBCAST) Cv(ASAtilable 1073741824GBCAST) available_bytes AS FLOAT)/ CAST (vs total_bytes AS FLOAT) AS DECIMAL (18,2)) * 100 AS [Space Free %]OD sys.master_files AS f S (NOLOCK)CROSS APPLY sys.dm_os_volume_stats f database_id, f [file] i AS vs OPTION (RECOMPILE);
Nasazení databáze
V našem případě bylo naší strategií zajistit, aby nové databáze odpovídaly našemu standardu. Se staršími databázemi se zacházelo s trochou větší opatrnosti, protože jsme je nějak konsolidovali a upgradovali zároveň. Database Migration Assistant nám pomohl říci, které databáze by rozhodně nebyly kompatibilní s naší posvěcenou instancí SQL Server 2016, a nechali jsme je v klidu (některé s úrovní kompatibility jsou až 100). Každá nasazená databáze by měla mít své vlastní svazky pro data a soubory protokolu v závislosti na její velikosti. Použití samostatných svazků pro každou databázi je dalším krokem k vytvoření velmi dobře organizovaného prostředí, což je důležité s ohledem na potenciální složitost tohoto konsolidovaného prostředí. Poslední prohlášení také implikuje, že když aplikaci povolíte vytvářet vlastní databáze, musíte jako DBA po dokončení nasazení přemístit datové soubory, protože aplikace bude používat stejné umístění souborů, jaké používá modelová databáze.
Zápis 4: Přemístění uživatelských databází
-- 1. Nastavte databázi do režimu offline-- Nezapomeňte nahradit DB_NAME skutečným názvem databáze ALTER DATABASE DB_NAME SET OFFLINE-- 2. Přesuňte soubor nebo soubory do nového umístění.-- To znamená ve skutečnosti zkopírovat datové soubory na Úroveň OS-- Možná budete muset udělit účtu SQL Server Service úplná oprávnění k datovému souboru-- 3. Pro každý přesunutý soubor spusťte následující příkaz.ALTER DATABASE DB_NAME MODIFY FILE ( NAME =logical_name FILENAME ='new_path\os_file_name' )-- 4. Vraťte databázi zpět onlineSpráva přístupu
Souhlasíte s tím, že v našem konsolidovaném prostředí bychom mohli skončit s velmi dlouhým seznamem objektů na úrovni serveru, jako jsou přihlášení. Použití skupin Windows pomůže zkrátit tento seznam a zjednodušit správu přístupu na každé klastrované instanci. Obvykle budete potřebovat skupiny vytvořené v Active Directory pro správce aplikací, kteří potřebují přístup, účty aplikačních služeb, podnikové uživatele, kteří potřebují stahovat sestavy, a samozřejmě správce databází. Jednou z klíčových výhod používání skupin Windows je to, že přístup lze udělit nebo zrušit jednoduše správou členství v těchto skupinách přímo ve službě Active Directory.
Už je asi zřejmé, že tato výhoda v oblasti Access Management je možná pouze s Windows Authentication. Přihlášení k serveru SQL nelze spravovat ve skupinách.
Zápis 5: Přihlášení k instancím, uživatelé databáze a jejich role
vytvořit tabulku #userlist ([Název serveru] varchar(20),[Název databáze] varchar(50),[Uživatel databáze] varchar(50), [Role databáze] varchar(50), [Přihlášení k instanci] varchar( 50), [Stav] varchar(15))goinsert do #userlistexec sp_MSforeachdb @command1 ='USE [?]IF ''?'' NENÍ V ("tempdb","model"J"msdb"J"master")BEGINvybrat @@název_serveru jako název_instance, ''?'' jako název_databáze, rp.name jako uživatel_databáze, mp.name jako role_databáze, sp.name jako přihlášení_instance, casewhen sp.is_disabled =1 potom ''Zakázáno'', když sp.is_disabled =0 potom ''Enabled'' end[login_status]from sys.database_principals rpleft vnější spojení sys.database_role_members DRM on (drm.member_principal_id =rp.principal_id)levý vnější spoj sys.database_principals mp on (drm.ftternal_role_principal_id) připojit se k sys.server_principals sp on (rp.sid=sp.sid) kde rp.type_desc v (''WINDOWS_GROUP'',''WINDOWS_USER'',''SQL_USER'')END' goselect * z #userlist tabulky Godrop #userlistZávěr
Na velmi vysoké úrovni jsme prozkoumali výhody, které lze získat shlukováním a vrstvením instancí SQL Serveru jako prostředku k dosažení konsolidace, optimalizace nákladů a snadné správy. Pokud zjistíte, že jste schopni zakoupit velký hardware, můžete tuto možnost prozkoumat a využít výhod, které jsme popsali výše.