SQL Server nám poskytuje různá řešení pro replikaci nebo archivaci databázové tabulky nebo tabulek do jiné databáze nebo do stejné databáze s různými názvy. Jako vývojář serveru SQL Server nebo správce databáze můžete čelit situacím, kdy potřebujete zkontrolovat, zda jsou data v těchto dvou tabulkách identická, a pokud se omylem data mezi těmito dvěma tabulkami nereplikují, budete muset data synchronizovat. mezi stoly. Pokud navíc obdržíte chybovou zprávu, která přeruší proces synchronizace nebo replikace dat, kvůli rozdílům ve schématech mezi zdrojovou a cílovou tabulkou, musíte najít snadný a rychlý způsob, jak rozdíly ve schématech identifikovat, ZMĚNIT tabulky, aby schéma identické na obou stranách a pokračujte v procesu synchronizace dat.
V jiných situacích potřebujete snadný způsob, jak získat odpověď ANO nebo NE, pokud jsou data a schéma dvou tabulek totožné nebo ne. V tomto článku si projdeme různé způsoby porovnání dat a schématu mezi dvěma tabulkami. Metody uvedené v tomto článku porovnají tabulky, které jsou hostovány v různých databázích, což je složitější scénář, a lze je také snadno použít k porovnání tabulek umístěných ve stejné databázi s různými názvy.
Před popisem různých metod a nástrojů, které lze použít k porovnání dat a schémat v tabulkách, připravíme naše demo prostředí vytvořením dvou nových databází a vytvořením jedné tabulky v každé databázi s jedním malým rozdílem v datovém typu mezi těmito dvěma tabulkami. zobrazené v příkazech T-SQL CREATE DATABASE a CREATE TABLE níže:
CREATE DATABASE TESTDBCREATE DATABASE TESTDB2CREATE TABLE TESTDB.dbo.FirstComTable( ID INT IDENTITY (1,1) PRIMÁRNÍ KLÍČ, Jméno VARCHAR (50), Příjmení VARCHAR (50), Adresa VARCHAR (500.boTADBTABLE.GOC) FirstComTable( ID INT IDENTITY (1,1) PRIMÁRNÍ KLÍČ, Jméno VARCHAR (50), Příjmení VARCHAR (50), Adresa NVARCHAR (400))GO
Po vytvoření databází a tabulek vyplníme dvě tabulky pěti stejnými řádky a poté vložíme další nový záznam pouze do první tabulky, jak je znázorněno v příkazech INSERT INTO T-SQL níže:
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('AAA','BBB','CCC')GO 5INSERT INTO TESTDB2.dbo.FirstComTable VALUES ('AAA','BBB','CCC')GO 5INSERT INTO TESTDB .dbo.FirstComTable VALUES ('DDD','EEE','FFF')GO Nyní je testovací prostředí připraveno začít popisovat metody porovnání dat a schémat.
Porovnání dat tabulek pomocí LEVÉHO PŘIPOJENÍ
Klíčové slovo LEFT JOIN T-SQL se používá k načtení dat ze dvou tabulek vrácením všech záznamů z levé tabulky a pouze odpovídajících záznamů z pravé tabulky a hodnot NULL z pravé tabulky, když mezi těmito dvěma tabulkami neexistuje žádná shoda.
Pro účely porovnání dat lze klíčové slovo LEFT JOIN použít k porovnání dvou tabulek na základě společného jedinečného sloupce, jako je v našem případě sloupec ID, jako v příkazu SELECT níže:
SELECT *FROM TESTDB.dbo.FirstComTable FLEFT JOIN TESTDB2.dbo.FirstComTable SON F.ID =S.ID
Předchozí dotaz vrátí běžných pět řádků existujících ve dvou tabulkách, navíc k řádku, který existuje v první tabulce a chybí ve druhé, zobrazením hodnot NULL na pravé straně výsledku, jak je uvedeno níže:
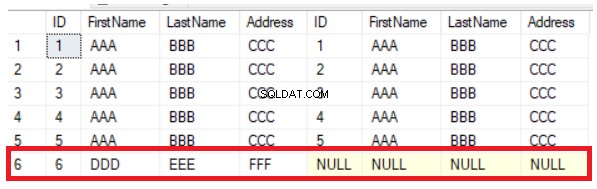
Z předchozího výsledku můžete snadno odvodit, že šestý sloupec, který existuje v první tabulce, chybí ve druhé tabulce. Chcete-li synchronizovat řádky mezi tabulkami, musíte nový záznam vložit do druhé tabulky ručně. Metoda LEFT JOIN je užitečná při ověřování nových řádků, ale nepomůže v případě aktualizace hodnot sloupců. Pokud změníte hodnotu sloupce Adresa v 5. řádku, metoda LEFT JOIN tuto změnu nezjistí, jak je jasně uvedeno níže:
Porovnání dat tabulek pomocí klauzule EXCEPT
Příkaz EXCEPT vrátí řádky z prvního dotazu (levý dotaz), které nejsou vráceny z druhého dotazu (pravý dotaz). Jinými slovy, příkaz EXCEPT vrátí rozdíl mezi dvěma příkazy SELECT nebo tabulkami, což nám pomáhá snadno porovnávat data v těchto tabulkách.
Příkaz EXCEPT lze použít k porovnání dat v dříve vytvořených tabulkách, rozdílem mezi dotazem SELECT * z první tabulky a dotazem SELECT * z druhé tabulky pomocí příkazů T-SQL níže:
SELECT * FROM TESTDB.dbo.FirstComTable FEXCEPT SELECT * FROM TESTDB2.dbo. FirstComTable S
Výsledkem předchozího dotazu bude řádek, který je dostupný v první tabulce a není dostupný ve druhé, jak je znázorněno níže:
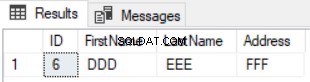
Použití příkazu EXCEPT k porovnání dvou tabulek je lepší než příkaz LEFT JOIN v tom, že aktualizované záznamy budou zachyceny ve výsledku rozdílů v datech. Předpokládejme, že jsme aktualizovali adresu řádku číslo 5 ve druhé tabulce a znovu zkontrolovali rozdíl pomocí příkazu EXCEPT, uvidíte, že řádek číslo 5 bude vrácen s výsledkem rozdílů, jak je uvedeno níže:
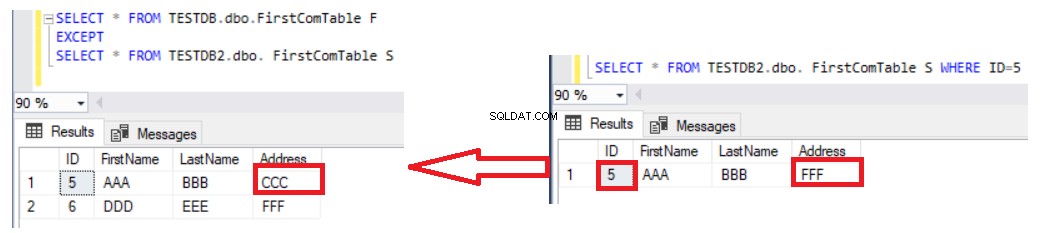
Jedinou nevýhodou použití příkazu EXCEPT k porovnání dat ve dvou tabulkách je, že je potřeba data synchronizovat ručně zápisem příkazu INSERT pro chybějící záznamy ve druhé tabulce. Vezměte v úvahu, že dvě porovnávané tabulky jsou klíčové tabulky, aby bylo dosaženo správného výsledku, s jedinečným klíčem použitým pro porovnání. Pokud odstraníme jedinečný sloupec ID z příkazu SELECT na obou stranách příkazu EXCEPT a vypíšeme zbytek neklíčových sloupců, jako v příkazu níže:
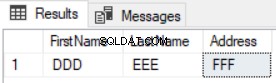
VYBERTE jméno, příjmení, adresu Z TESTDB.dbo. FirstComTable FEXCEPT SELECT Jméno, Příjmení, Adresa Z TESTDB2.dbo. FirstComTable S
Výsledek ukáže, že jsou vráceny pouze nové záznamy a aktualizované nebudou uvedeny, jak ukazuje výsledek níže:
Porovnání dat tabulek pomocí UNION ALL … GROUP BY
Příkaz UNION ALL lze také použít k porovnání dat ve dvou tabulkách na základě sloupce jedinečného klíče. Chcete-li použít příkaz UNION ALL k vrácení rozdílu mezi dvěma tabulkami, musíte uvést seznam sloupců k porovnání v příkazu SELECT a použít tyto sloupce v klauzuli GROUP BY, jak je znázorněno v dotazu T-SQL níže:
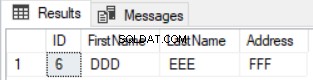
SELECT DISTINCT * FROM ( SELECT * FROM ( SELECT * FROM TESTDB.dbo. FirstComTable UNION ALL SELECT * FROM TESTDB2.dbo. FirstComTable) Tbls GROUP BY ID,FirstName, LastName, Address HAVING COUNT(*)<2) Rozdíl
A pouze řádek, který existuje v první tabulce a chybí ve druhé tabulce, bude vrácen, jak je uvedeno níže:
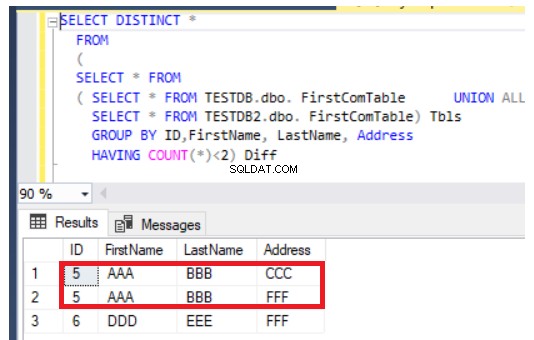
Předchozí dotaz bude také fungovat dobře v případě aktualizace záznamů, ale jiným způsobem. Vrátí nově vložené záznamy navíc k aktualizovaným sloupcům z obou tabulek, jako v případě řádku číslo 5, který je zobrazen níže:
Porovnání dat tabulek pomocí datových nástrojů SQL Server
SQL Server Data Tools, také známé jako SSDT, postavené nad Microsoft Visual Studio, lze snadno použít k porovnání dat ve dvou tabulkách se stejným názvem na základě jedinečného sloupce klíče, hostovaných ve dvou různých databázích a synchronizaci dat v těchto tabulkách. nebo vygenerujte synchronizační skript pro pozdější použití.
V otevřeném okně SSDT klikněte na nabídku Nástroje -> seznam SQL Server a vyberte Porovnání nových dat možnost, jak je uvedeno níže:
V zobrazeném okně připojení si můžete vybrat z dříve připojených relací nebo vyplnit okno Vlastnosti připojení názvem serveru SQL, přihlašovacími údaji a názvem databáze a poté kliknout na Připojit , jak je uvedeno níže:

V zobrazeném průvodci porovnáním nových dat zadejte názvy zdrojových a cílových databází a možnosti porovnání použité v procesu porovnávání tabulek a poté klikněte na Další , jak je uvedeno níže:
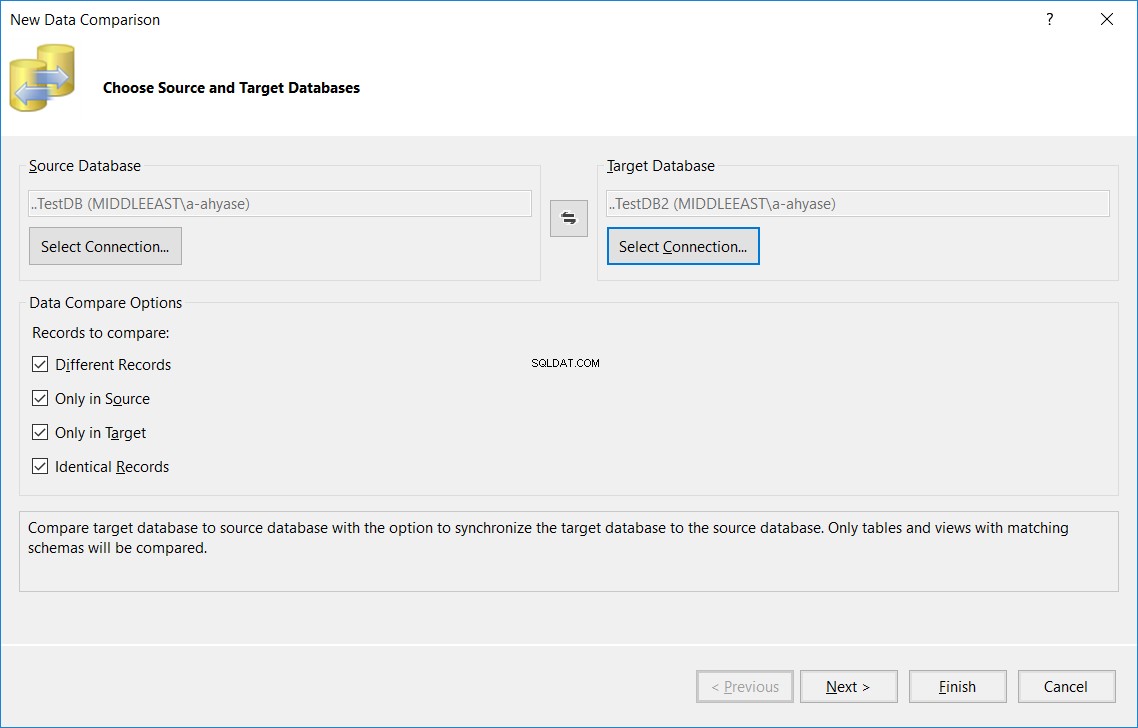
V dalším okně zadejte název tabulky, který by měl být stejný ve zdrojové i cílové databázi, která bude porovnána v obou databázích, a klikněte naDokončit , jak je uvedeno níže:
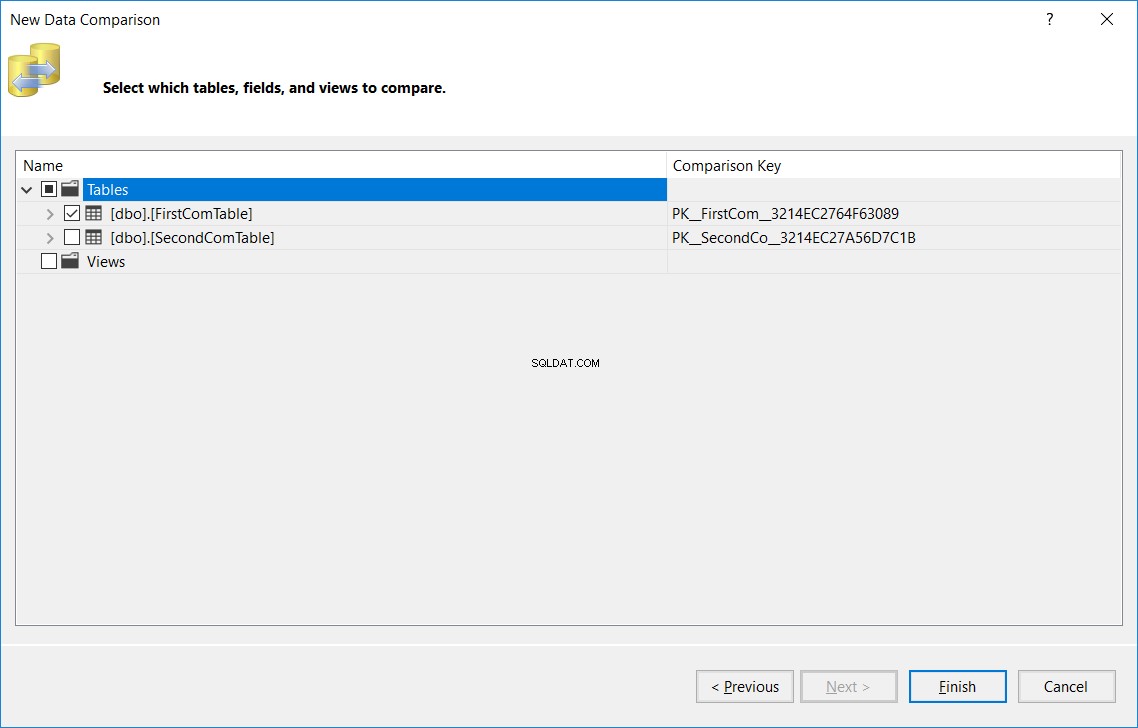
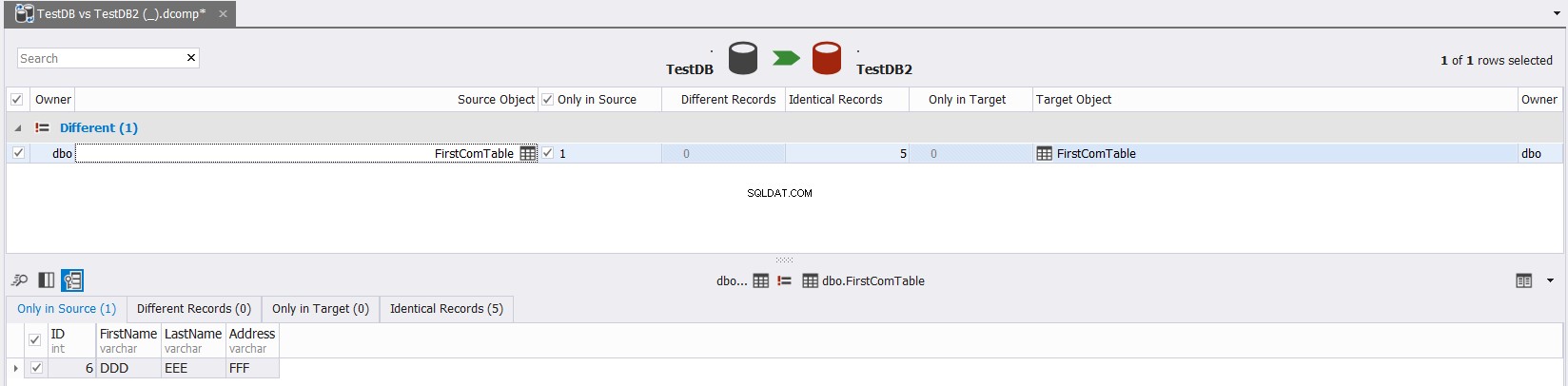
Zobrazený výsledek vám ukáže počet záznamů nalezených ve zdroji a vynechaných od cílového, nalezených v cíli a vynechaných ze zdroje, počet aktualizovaných záznamů se stejným klíčem a různými hodnotami sloupců (Different Records) a nakonec počet identických záznamů nalezených v obou tabulkách, jak je uvedeno níže:
Klikněte na název tabulky v předchozím výsledku, zobrazí se podrobný pohled na tato zjištění, jak je uvedeno níže:

Stejný nástroj můžete použít ke generování skriptu pro synchronizaci zdrojové a cílové tabulky nebo přímo aktualizovat cílovou tabulku s chybějícími nebo jinými změnami, jak je uvedeno níže:
Pokud kliknete na možnost Generovat skript, zobrazí se příkaz INSERT s chybějícím sloupcem v cílové tabulce, jak je znázorněno níže:
BEGIN TRANSACTION
ZAČÁTE TRANSACTIONSET IDENTITY_INSERT [dbo].[FirstComTable] ONINSERT DO [dbo].[FirstComTable] ([ID], [Jméno], [Příjmení], [Adresa]) HODNOTY (6, N'DDD', N' EEE', N'FFF')SET IDENTITY_INSERT [dbo].[FirstComTable] OFFCOMMIT TRANSACTION
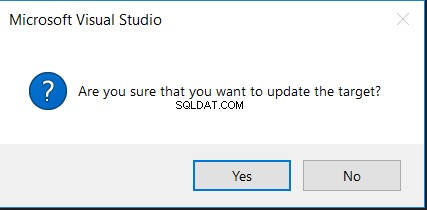
Výběrem možnosti Aktualizovat cíl budete nejprve požádáni o potvrzení provedení změny, jak je uvedeno ve zprávě níže:
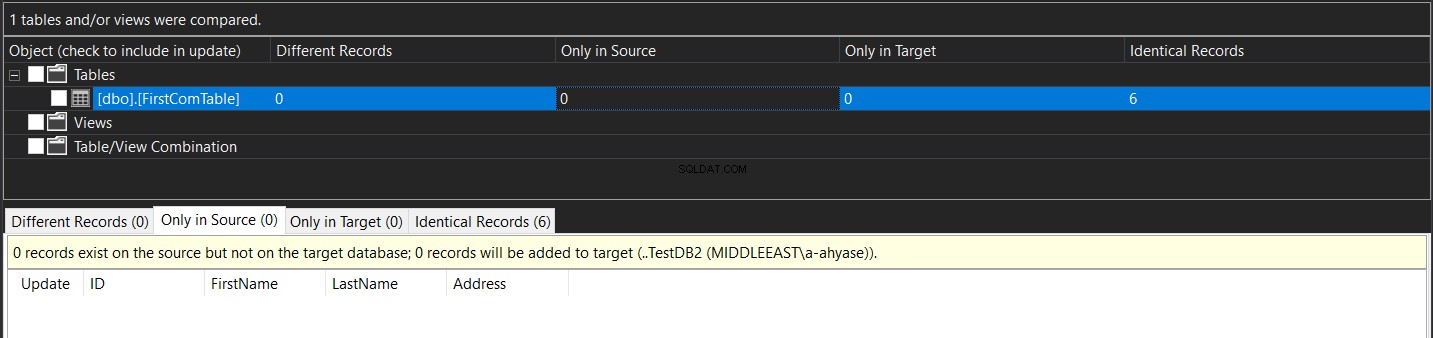
Po synchronizaci uvidíte, že data ve dvou tabulkách budou identická, jak je uvedeno níže:
Porovnání dat tabulek pomocí nástroje třetí strany „dbForge Studio for SQL Server“
Ve světě SQL Serveru můžete najít velké množství nástrojů třetích stran, které usnadňují život správcům databází a vývojářům. Jedním z těchto nástrojů, díky kterému jsou úlohy správy databáze hračkou, je dbForge Studio pro SQL Server, který nám poskytuje snadné způsoby provádění úloh správy a vývoje databáze. Tento nástroj nám také může pomoci při porovnávání dat v databázových tabulkách a synchronizaci těchto tabulek.
Z nabídky Porovnání zvolte Nové porovnání dat možnost, jak je uvedeno níže:
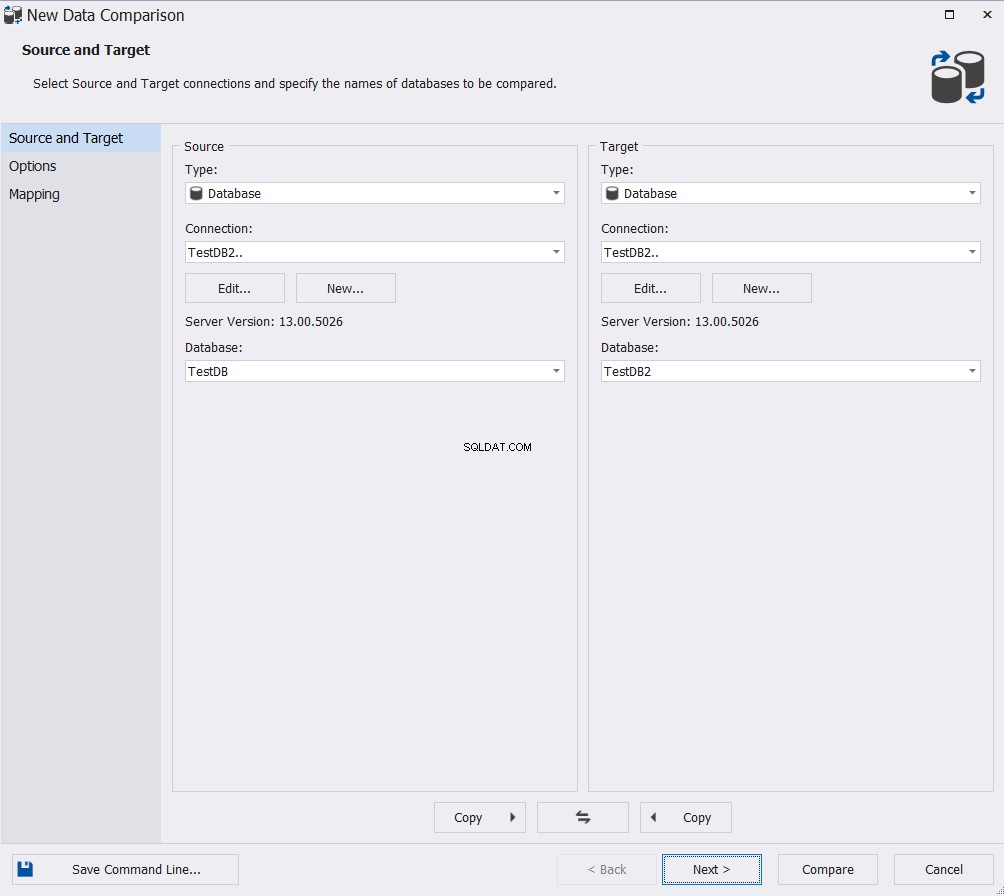
V průvodci Novým porovnáním dat určete zdrojovou a cílovou databázi a klikněte na Další :
Vyberte si vhodné možnosti ze široké škály dostupných možností mapování a porovnání a klikněte na Další :
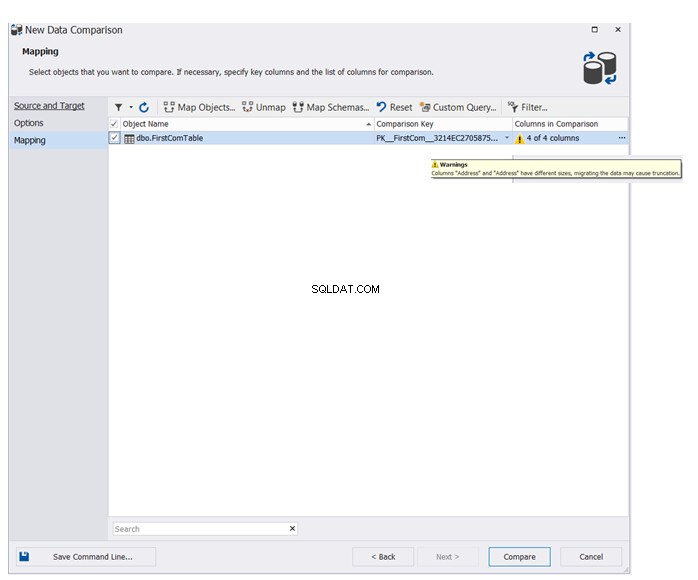
Zadejte název tabulky nebo tabulek, které se budou účastnit procesu porovnávání dat. Průvodce zobrazí varovnou zprávu v případě, že existují rozdíly ve schématu mezi zdrojovou a cílovou databázovou tabulkou. Klikněte na Porovnat pokračovat:
Konečný výsledek vám podrobně ukáže rozdíly v datech mezi zdrojovou a cílovou tabulkou s možností kliknutí  pro synchronizaci zdrojových a cílových tabulek, jak je uvedeno níže:
pro synchronizaci zdrojových a cílových tabulek, jak je uvedeno níže:
Porovnání schématu tabulek pomocí sys.columns
Jak bylo zmíněno na začátku tohoto článku, pro replikaci nebo archivaci tabulky se musíte ujistit, že schéma zdrojové a cílové tabulky je totožné. SQL Server nám poskytuje různé způsoby, jak porovnat schéma tabulek ve stejné databázi nebo v různých databázích. První metodou je dotaz na pohled systémového katalogu sys.columns, který vrací jeden řádek pro každý sloupec objektu, který má sloupec, s vlastnostmi každého sloupce.
Chcete-li porovnat schéma tabulek umístěných v různých databázích, musíte poskytnout sys.columns název tabulky pod aktuální databází, aniž byste mohli poskytnout tabulku hostovanou v jiné databázi. Abychom toho dosáhli, dvakrát se dotazujeme na sys.columns, uložíme výsledek každého dotazu do dočasné tabulky a nakonec porovnáme výsledek těchto dvou dotazů pomocí příkazu EXCEPT T-SQL, jak je jasně znázorněno níže:
POUŽÍVEJTE název TESTDBSELECT, system_type_id, user_type_id, max_length, precision, scale, is_nullable, is_identity INTO #DBSchema FROM sys.columnsWHERE object_id =OBJECT_ID(N'dbo.FirstComTable')GOUSE TestDB2GO_SELECT název_id, max_typ_uživatele, délka_systému scale, is_nullable, is_identity INTO #DB2Schema FROM sys.columnsWHERE object_id =OBJECT_ID(N'dbo.FirstComTable ');GO SELECT * FROM #DBSchemaEXCEPT SELECT * FROM #DB2Schema
Výsledek nám ukáže, že definice sloupce Adresa se v těchto dvou tabulkách liší, bez konkrétních informací o přesném rozdílu, jak je uvedeno níže:

Porovnejte schéma tabulek pomocí INFORMATION_SCHEMA.COLUMNS
Systémový pohled INFORMATION_SCHEMA.COLUMNS lze také použít k porovnání schématu různých tabulek zadáním názvu tabulky. Opět, abychom porovnali dvě tabulky hostované v různých databázích, zadáme dotaz INFORMATION_SCHEMA.COLUMNS dvakrát, výsledek každého dotazu ponecháme v dočasné tabulce a nakonec porovnáme výsledek těchto dvou dotazů pomocí příkazu EXCEPT T-SQL, jak je znázorněno jasně níže:
A výsledek bude nějak podobný předchozímu, což ukazuje, že definice sloupce Adresa se v těchto dvou tabulkách liší, bez konkrétních informací o přesném rozdílu, jak je uvedeno níže:

Porovnání schématu tabulek pomocí dm_exec_describe_first_result_set
Schémata tabulek lze také porovnat dotazem na funkci dynamické správy dm_exec_describe_first_result_set, která jako parametr bere příkaz Transact-SQL a popisuje metadata první sady výsledků pro daný příkaz.
Chcete-li porovnat schéma dvou tabulek, musíte spojit dm_exec_describe_first_result_set DMF se sebou samým a poskytnout příkaz SELECT z každé tabulky jako parametr, jako v dotazu T-SQL níže:
SELECT FT.name , ST.name , FT.system_type_name , ST.system_type_name ,FT.max_length , ST.max_length ,FT.precision , ST.precision ,FT.scale , ST.scale ,FT.is_nullable , ST. is_nullable , FT.is_identity_column , ST.is_identity_column FROM sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB.DBO.FirstComTable', NULL, 0) FTLEFT OUTER JOIN *BTT_ult_soubor JOIN sys'resscribe_firstDROMC , 0) STON FT.Name =ST.NameGO
Výsledek bude tentokrát jasnější, protože můžete pohledem porovnat rozdíl mezi těmito dvěma tabulkami, tedy velikost a typ sloupce Adresa, jak je znázorněno níže:

Porovnání schématu tabulek pomocí datových nástrojů SQL Server
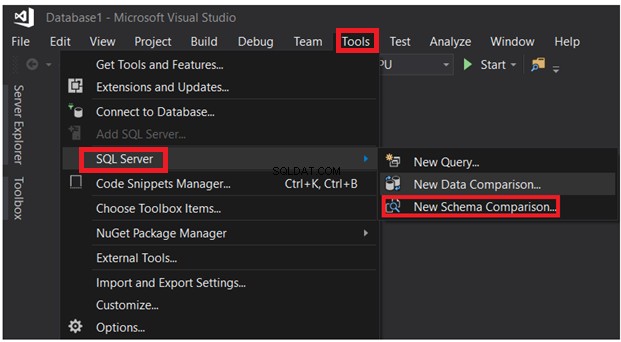
SQL Server Data Tools lze také použít k porovnání schématu tabulek umístěných v různých databázích. V nabídce Nástroje vyberte možnost Porovnání nového schématu možnost ze seznamu možností serveru SQL, jak je uvedeno níže:
Po zadání parametrů připojení klikněte na tlačítko Porovnat:

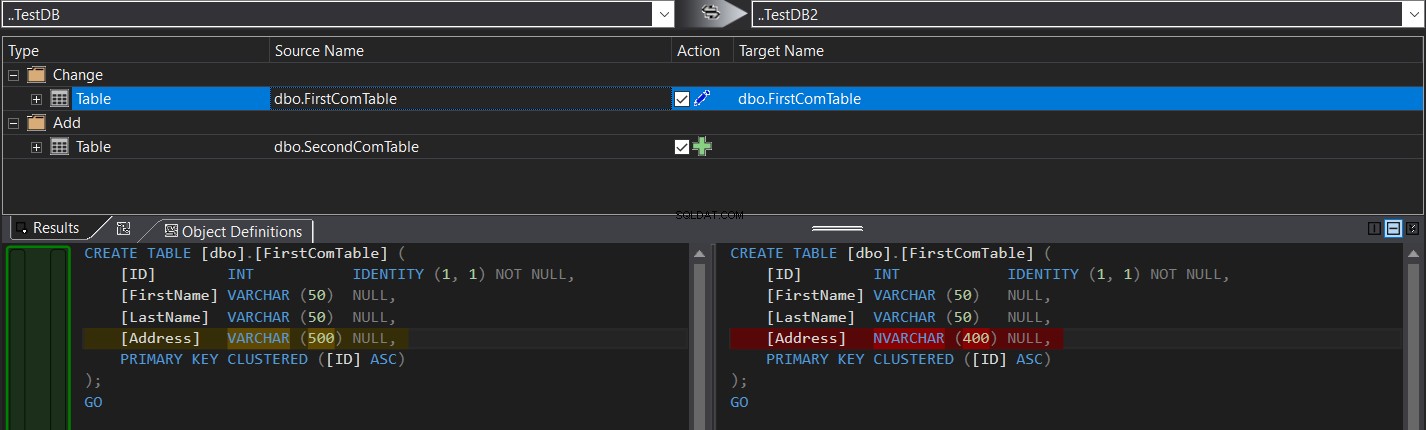
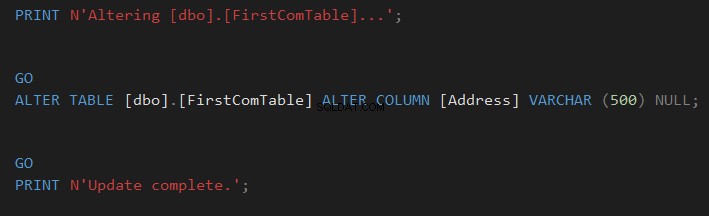
Výsledek porovnání vám konkrétně ukáže rozdíl ve schématu mezi dvěma tabulkami ve tvaru příkazů CREATE TABLE T-SQL, stínovaných jako na snímku níže:
Můžete snadno kliknout  pro synchronizaci schématu tabulky nebo klikněte na
pro synchronizaci schématu tabulky nebo klikněte na  pro skriptování změny a její provedení později, jak je uvedeno níže:
pro skriptování změny a její provedení později, jak je uvedeno níže:
Porovnání schématu tabulek pomocí nástroje dbForge Studio pro SQL Server třetí strany
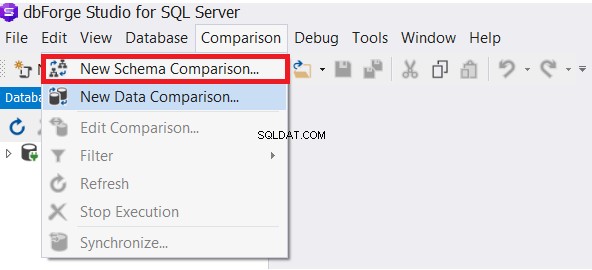
Nástroj dbForge Studio pro SQL Server nám poskytuje možnost porovnávat schémata různých databázových tabulek. Z nabídky Porovnání vyberte Porovnání nového schématu možnost, jak je uvedeno níže:
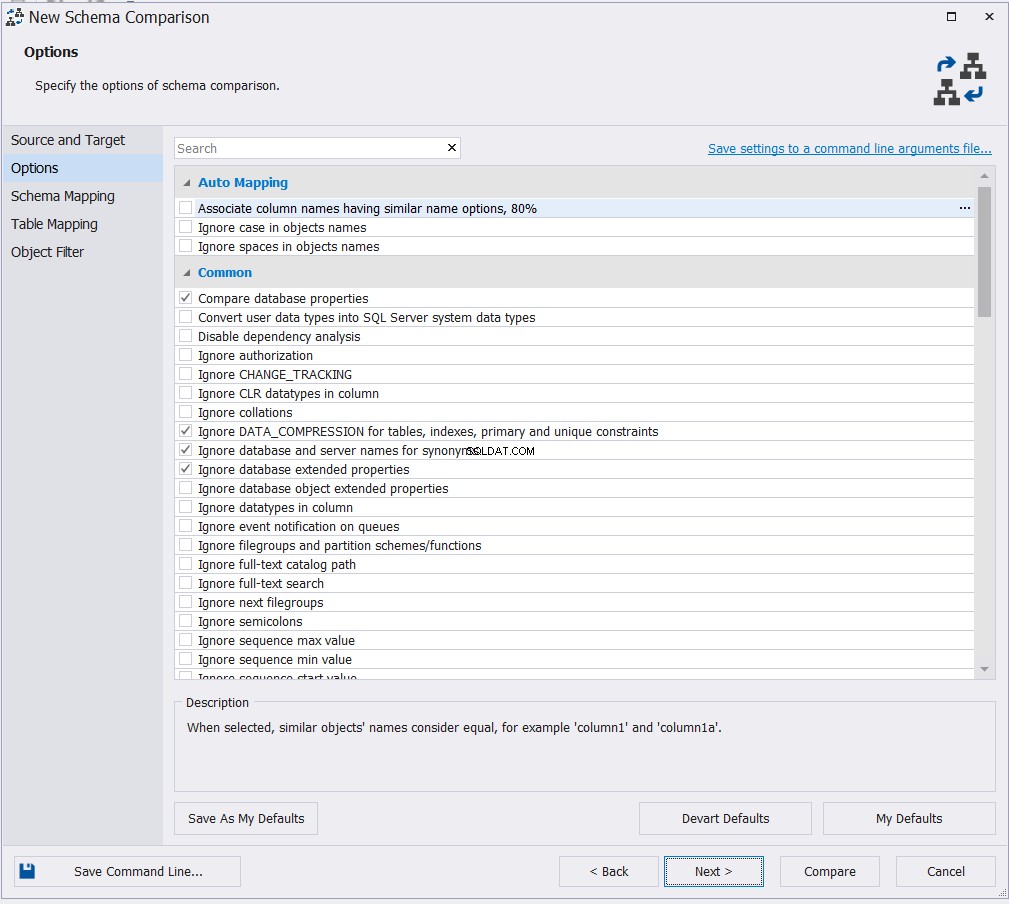
Po zadání vlastností připojení zdrojové i cílové databáze vyberte z dostupných možností vhodnou možnost mapování a klikněte na Další :
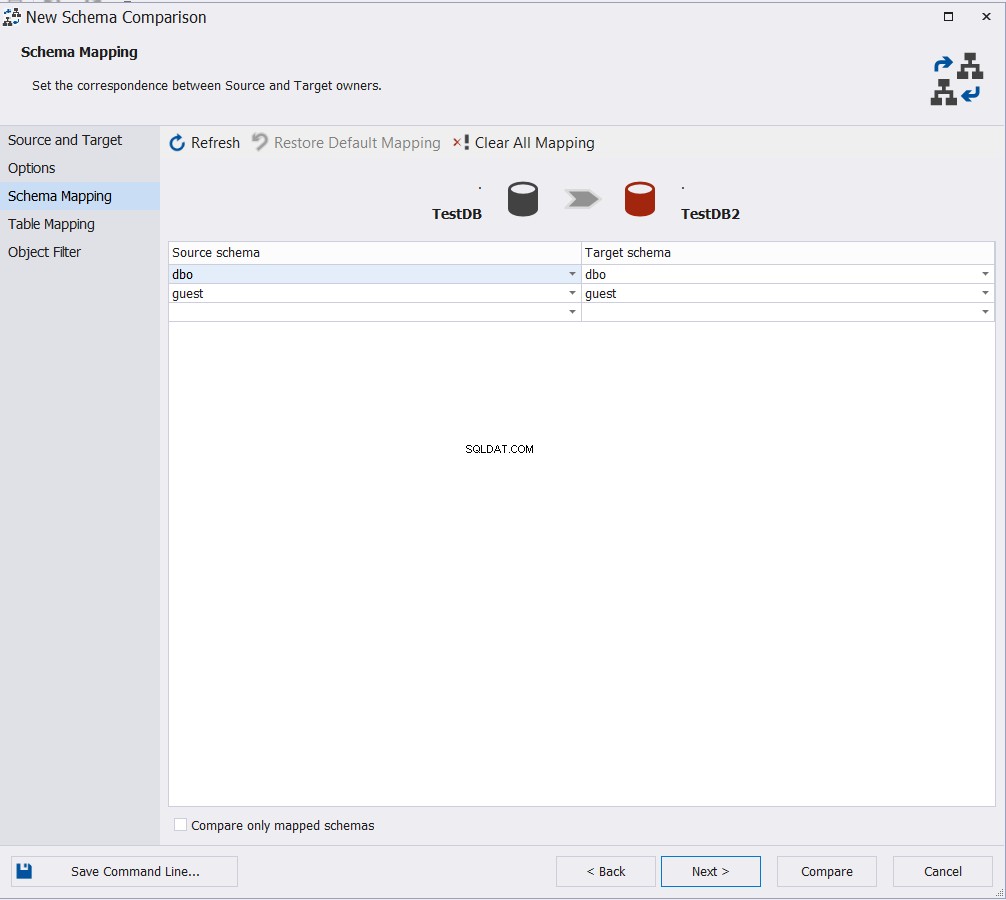
Vyberte schémata, u kterých budete porovnávat jejich objekt, a klikněte na Další :
Zadejte tabulku nebo tabulky, které se zúčastní procesu porovnání schématu, a klikněte na Porovnat , pokud chcete přeskočit změnu výchozího nastavení v okně Objektový filtr, jak je uvedeno níže:
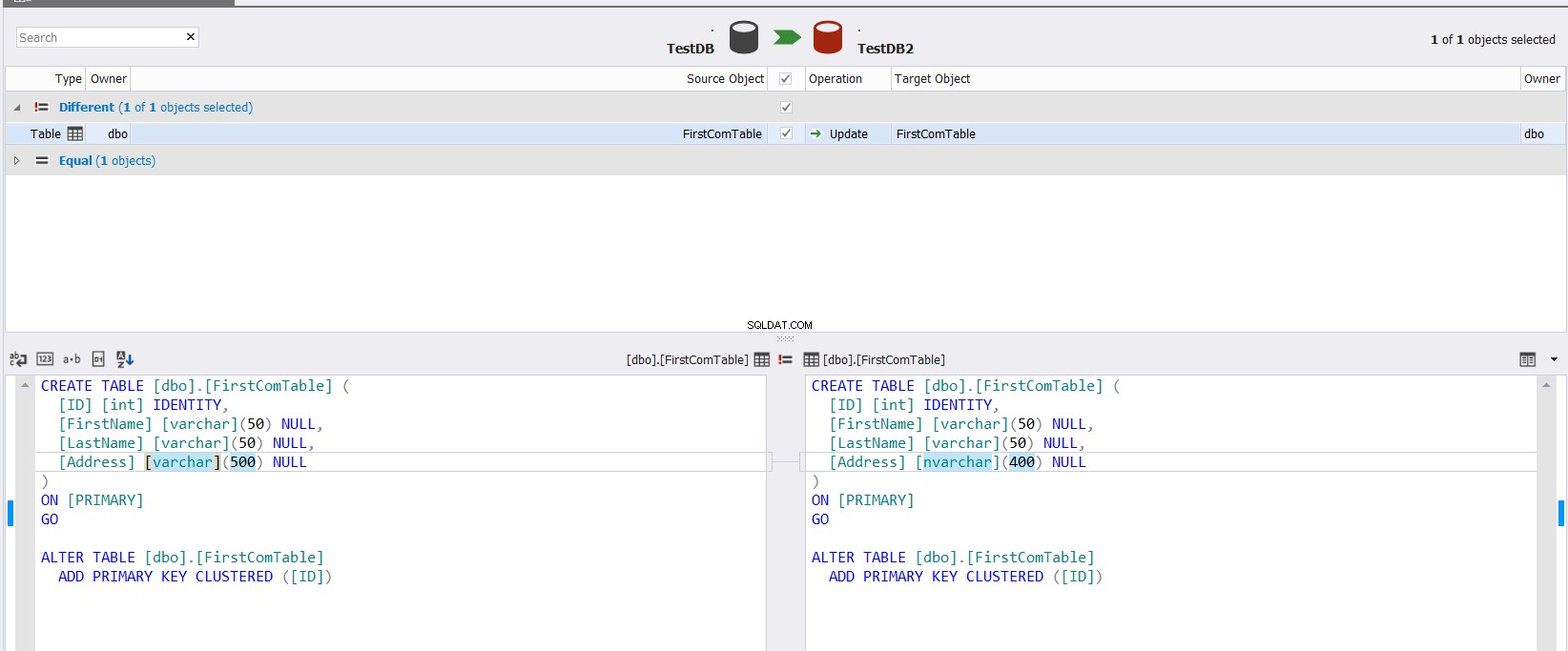
Zobrazený výsledek porovnání vám ukáže rozdíl mezi schématem dvou tabulek přesným zvýrazněním části datového typu, která se mezi dvěma sloupci liší, s možností určit, jaká akce by měla být provedena pro synchronizaci dvou tabulek, jak je uvedeno níže. :
Pokud zařídíte synchronizaci schématu dvou tabulek, klikněte na tlačítko a v Průvodci synchronizací schématu určete, zda se vám podaří provést změnu přímo v cílové tabulce, nebo ji pouze naskriptovat pro budoucí použití, jak je uvedeno níže:
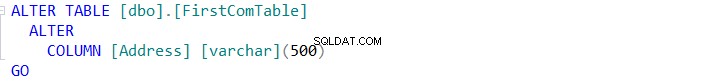
Užitečné odkazy:
- Nastavte operátory – EXCEPT a INTERSECT (Transact-SQL)
- Nastavte operátory – UNION (Transact-SQL)
- Stáhněte si SQL Server Data Tools (SSDT)
- Porovnejte a synchronizujte data v jedné nebo více tabulkách s daty v referenční databázi
- sys.dm_exec_describe_first_result_set (Transact-SQL)
- sys.columns (Transact-SQL)
- Zobrazení schématu systémových informací (Transact-SQL)
Užitečné nástroje:
dbForge Schema Compare for SQL Server – spolehlivý nástroj, který šetří váš čas a úsilí při porovnávání a synchronizaci databází na SQL Server.
dbForge Data Compare for SQL Server – výkonný nástroj pro porovnání SQL schopný pracovat s velkými daty.