Jednoduchá definice mediánu je:
Medián je střední hodnota v seřazeném seznamu číselAbychom to trochu přiblížili, můžeme najít medián seznamu čísel pomocí následujícího postupu:
- Seřaďte čísla (ve vzestupném nebo sestupném pořadí, nezáleží v jakém).
- Prostřední číslo (podle pozice) v seřazeném seznamu je medián.
- Pokud existují dvě „stejně střední“ čísla, je medián průměrem dvou středních hodnot.
Aaron Bertrand již dříve výkonnostně testoval několik způsobů, jak vypočítat medián na serveru SQL:
- Jaký je nejrychlejší způsob výpočtu mediánu?
- Nejlepší přístupy pro seskupený medián
Rob Farley nedávno přidal další přístup zaměřený na instalace před rokem 2012:
- Medians před SQL 2012
Tento článek představuje novou metodu využívající dynamický kurzor.
Metoda 2012 OFFSET-FETCH
Začneme tím, že se podíváme na nejvýkonnější implementaci, kterou vytvořil Peter Larsson. Používá SQL Server 2012 OFFSET rozšíření na ORDER BY klauzule k efektivnímu nalezení jednoho nebo dvou prostředních řádků potřebných k výpočtu mediánu.
POSUN Single Medián
Aaronův první článek testoval výpočet jednoho mediánu přes desetimilionovou tabulku řádků:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
Řešení Petera Larssona pomocí OFFSET přípona je:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Výše uvedený kód pevně zakóduje výsledek počítání řádků v tabulce. Všechny testované metody pro výpočet mediánu potřebují tento počet pro výpočet mediánových čísel řádků, takže jde o konstantní náklady. Vynecháním operace počítání řádků z načasování se vyhnete jednomu možnému zdroji odchylek.
Plán provádění pro OFFSET řešení je uvedeno níže:

Operátor Top rychle přeskakuje nepotřebné řádky a předá pouze jeden nebo dva řádky potřebné k výpočtu mediánu do agregátu toku. Při spuštění s vypnutou teplou mezipamětí a shromažďováním plánů provádění běží tento dotaz po dobu 910 ms v průměru na mém notebooku. Toto je stroj s procesorem Intel i7 740QM běžícím na 1,73 GHz s deaktivovaným Turbo (kvůli konzistenci).
POSUN seskupený medián
Aaronův druhý článek testoval výkon výpočtu mediánu na skupinu pomocí tabulky s milionem řádků Prodej s deseti tisíci položkami pro každého ze sta prodejců:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Opět platí, že nejvýkonnější řešení používá OFFSET :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Důležitá část prováděcího plánu je uvedena níže:

Horní řádek plánu se zabývá zjištěním počtu řádků skupiny pro každého prodejce. Spodní řádek používá k výpočtu mediánu pro každého prodejce stejné prvky plánu jako u řešení mediánu jedné skupiny. Při spuštění s teplou mezipamětí a vypnutými plány provádění se tento dotaz spustí za 320 ms v průměru na mém notebooku.
Použití dynamického kurzoru
Mohlo by se zdát bláznivé vůbec přemýšlet o použití kurzoru k výpočtu mediánu. Kurzory Transact SQL mají (většinou zaslouženou) pověst pomalé a neefektivní. Často se také předpokládá, že dynamické kurzory jsou nejhorším typem kurzoru. Tyto body jsou platné za určitých okolností, ale ne vždy.
Kurzory Transact SQL jsou omezeny na zpracování jednoho řádku najednou, takže mohou být skutečně pomalé, pokud je třeba načíst a zpracovat mnoho řádků. To však neplatí pro výpočet mediánu:vše, co musíme udělat, je najít a načíst jednu nebo dvě střední hodnoty efektivně . Dynamický kurzor je pro tento úkol velmi vhodný, jak uvidíme.
Jeden střední dynamický kurzor
Řešení dynamického kurzoru pro výpočet jednoho mediánu se skládá z následujících kroků:
- Vytvořte dynamický posuvný kurzor nad seřazeným seznamem položek.
- Vypočítejte polohu prvního středního řádku.
- Přemístěte kurzor pomocí
FETCH RELATIVE. - Rozhodněte, zda je k výpočtu mediánu potřeba druhý řádek.
- Pokud ne, okamžitě vraťte jednu střední hodnotu.
- V opačném případě načtěte druhou hodnotu pomocí
FETCH NEXT. - Vypočítejte průměr těchto dvou hodnot a vraťte se.
Všimněte si, jak přesně tento seznam odráží jednoduchý postup pro nalezení mediánu uvedený na začátku tohoto článku. Kompletní implementace kódu Transact SQL je zobrazena níže:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Plán provádění pro FETCH RELATIVE zobrazuje dynamický kurzor efektivní přemístění na první řádek požadovaný pro výpočet mediánu:
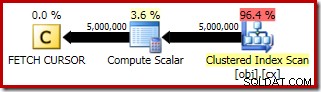
Plán pro FETCH NEXT (povinné pouze v případě, že existuje druhý prostřední řádek, jako v těchto testech) je načtení jednoho řádku z uložené pozice kurzoru:
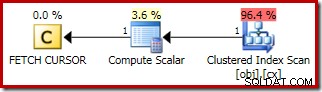
Výhody použití dynamického kurzoru jsou následující:
- Vyhne se procházení celé sady (čtení se zastaví po nalezení středních řádků); a
- V tempdb se nevytváří žádná dočasná kopie dat , jako by tomu bylo u statického kurzoru nebo kurzoru sady klíčů.
Všimněte si, že nemůžeme zadat FAST_FORWARD kurzor zde (výběr statického nebo dynamického plánu ponecháte na optimalizátoru), protože kurzor musí být rolovatelný, aby podporoval FETCH RELATIVE . Dynamic je zde každopádně optimální volbou.
Při spuštění s vypnutou teplou mezipamětí a shromažďováním plánů provádění běží tento dotaz po dobu 930 ms v průměru na mém testovacím stroji. To je o něco pomalejší než 910 ms pro OFFSET řešení, ale dynamický kurzor je výrazně rychlejší než ostatní metody, které testovali Aaron a Rob, a nevyžaduje SQL Server 2012 (nebo novější).
Nebudu zde opakovat testování ostatních metod před rokem 2012, ale jako příklad velikosti mezery ve výkonu, následující řešení číslování řádků trvá 1550 ms v průměru (o 70 % pomalejší):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

Test seskupeného středního dynamického kurzoru
Je jednoduché rozšířit řešení dynamického kurzoru s jedním mediánem na výpočet seskupených mediánů. Kvůli konzistenci budu používat vnořené kurzory (ano, opravdu):
- Otevřete statický kurzor nad prodejci a počty řádků.
- Vypočítejte medián pro každou osobu pokaždé pomocí nového dynamického kurzoru.
- Za pochodu ukládejte každý výsledek do proměnné tabulky.
Kód je zobrazen níže:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Vnější kurzor je záměrně statický, protože se dotkne všech řádků v této sadě (také dynamický kurzor není k dispozici kvůli operaci seskupení v podkladovém dotazu). Tentokrát není v prováděcích plánech nic nového nebo zajímavého k vidění.
Zajímavostí je výkon. Navzdory opakovanému vytváření a dealokaci vnitřního dynamického kurzoru funguje toto řešení na testovací sadě dat opravdu dobře. Při vypnuté teplé mezipaměti a plánech provádění se skript kurzoru dokončí za 330 ms v průměru na mém testovacím stroji. To je opět o něco málo pomalejší než 320 ms zaznamenané pomocí OFFSET seskupený medián, ale s velkým náskokem překonává ostatní standardní řešení uvedená v Aaronových a Robových článcích.
Opět jako příklad mezery ve výkonu oproti jiným metodám mimo rok 2012, následující řešení číslování řádků běží po dobu 485 ms v průměru na mém testovacím zařízení (o 50 % horší):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

Shrnutí výsledků
V testu s jedním mediánem běžel dynamický kurzor po dobu 930 ms oproti 910 ms pro OFFSET metoda.
V testu seskupeného mediánu běžel vnořený kurzor po dobu 330 ms oproti 320 ms pro OFFSET .
V obou případech byla kurzorová metoda výrazně rychlejší než jiná metoda než OFFSET metody. Pokud potřebujete vypočítat jeden nebo seskupený medián na instanci před rokem 2012, optimální volbou by skutečně mohl být dynamický kurzor nebo vnořený kurzor.
Výkon studené mezipaměti
Někteří z vás se možná ptají na výkon studené mezipaměti. Před každým testem spusťte následující:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Toto jsou výsledky testu s jedním mediánem:
OFFSET metoda:940 ms
Dynamický kurzor:955 ms
Pro seskupený medián:
OFFSET metoda:380 ms
Vnořené kurzory:385 ms
Poslední myšlenky
Řešení dynamického kurzoru jsou skutečně výrazně rychlejší než řešení bez OFFSET metody pro jednotlivé i seskupené mediány, alespoň s těmito vzorovými soubory dat. Záměrně jsem se rozhodl znovu použít Aaronova testovací data, aby datové sady nebyly záměrně vychýleny směrem k dynamickému kurzoru. možná být jiné distribuce dat, pro které není dynamický kurzor dobrou volbou. Nicméně ukazuje, že stále existují situace, kdy kurzor může být rychlým a efektivním řešením správného druhu problému. Dokonce i dynamické a vnořené kurzory.
Čtenáři s orlíma očima si možná všimli PAGLOCK nápověda v OFFSET skupinový test mediánu. To je vyžadováno pro nejlepší výkon, z důvodů, kterým se budu věnovat v příštím článku. Bez něj řešení z roku 2012 ve skutečnosti ztrácí na vnořený kurzor se slušnou rezervou (590 ms oproti 330 ms ).