Aktualizace:2. čtvrtletí 2016 :Kromě průvodce profilováním databáze ve skupině nabídek zjišťování dat v IRI Workbench popsaném níže zavedlo IRI robustní klasifikaci dat, která umožňuje použití pravidel pole pro transformaci dat z více zdrojů a ochranu prostřednictvím knihoven tříd dat. Aktualizace Q2’18 :Společnost IRI také zavedla průvodce vyhledáváním vzorů v celém schématu, aby našel PII odpovídající RegEx nebo doslovné hodnoty ve více tabulkách najednou. Aktualizace Q2’19 :IRI nyní také poskytuje vyhledávání datových tříd mezi/v rámci schématu amaskování pro uživatele IRI FieldShield nebo Voracity. A společnost IRI právě zveřejnila tento článek, aby ukázala, jak se níže uvedené výsledky profilování DB zobrazují ve Splunk.
Vzhledem k tomu, že se dnes shromažďuje více dat z více aspektů podnikání, je snadné povědomí o jejich obsahu a povaze zásadní pro zajištění kvality, množství a zabezpečení těchto sbírek. Profilování dat je základní proces zjišťování, který vám pomáhá analyzovat, klasifikovat, čistit, integrovat, maskovat a hlásit data ve vašich úložištích.
Kromě průvodců zjišťováním tmavých a strukturovaných dat (a definicí metadat) spolu s diagramy cross-DB E-R v Eclipse umožňuje nový nástroj pro profilování cross-DB v IRI Workbench uživatelům prozkoumat strukturu a úplnost databázových dat a ověřit je. správná data jsou uložena na správných místech. V tomto článku tento nástroj prozkoumáme a ukážeme si, jak poskytuje výsledky vyhledávání s hodnotami tabulky a statistická metadata.
Chcete-li získat přístup k nástroji Database Profiler, přejděte v Průzkumníku zdrojů dat k tabulce, ke které chcete přistupovat. Klikněte pravým tlačítkem na tabulku a přesuňte kurzor na možnost IRI. V nabídce, která se zobrazí, vyberte Nový profil databáze .
Na první stránce průvodce nastavte umístění a cíl úlohy a vyberte výstup sestavy profilu, jako soubor .csv nebo .txt nebo obojí.
- Formát .csv je užitečný pro import do nových tabulek a databází, zatímco
- Formát .txt je předem naformátovaný přehled, užitečný pro rychlou kontrolu výsledků.
Statistické profilovací informace
Zobrazí se další část průvodce se dvěma tabulkami:
- Horní tabulka je seznam všech tabulek v databázi, přičemž tabulka, která spustila průvodce, je ve výchozím nastavení zvýrazněna.
- Toto zaškrtávací políčko vám umožňuje jedním kliknutím prohledat každou tabulku a řádek v databázi.

- V dolní tabulce jsou uvedeny možnosti profilování, za nimiž následují sloupce zvýrazněné tabulky, ve kterých se rozhodnete možnosti provést.

Klikněte na libovolnou tabulku v seznamu, kterou chcete zobrazit a profilovat. Matice možností se automaticky změní, aby reprezentovala sloupce vybrané tabulky. Existuje několik způsobů, jak zacházet s možnostmi zobrazení:
- U všech možností klikněte na horní zaškrtávací políčko v tabulce označené Vše a všechna metadata budou hlášena.
- Pouze pro základní možnosti (počítání a hodnoty) zaškrtněte políčko Základy.
- Pouze pro možnosti délky (délky hodnot) zaškrtněte políčko Délky.
Pokud máte v tabulce mnoho sloupců a chcete pro všechny vybrat stejnou možnost, klikněte na samotný název možnosti a všechny sloupce budou mít tuto možnost vybranou. V rámci této možnosti můžete zrušit výběr sloupců.
Jakmile je vše nastaveno, klikněte na Dokončit a poté vám bude vygenerován profil.
Vyhledávání výrazů
Jedinečnou volbou v tabulce možností je -Vyhledávání výrazů-. Tato možnost vám umožňuje prohledávat sloupce s různými možnostmi vyhledávání. Tyto možnosti jsou:
- Regulární výrazy (vyhledávání vzorů). Toto vyhledá a spočítá, kolikrát se hodnota shoduje s formátem vyhledávacího vzoru.
- Fuzzy řetězec. Tato možnost vám umožňuje vyhledávat řetězce podobné těm, které zadáváte, a vybírat nebo specifikovat podmínky vyhledávání.
- Soubor hodnot. Tato možnost vám umožňuje porovnat řetězec s každým řetězcem v souboru sady a spočítat každý řetězec, který se shoduje.
Stránka Vyhledávání výrazů má 6 důležitých sekcí
- Rozbalovací pole Typ vyhledávání pro výběr typu vyhledávání.
- Skupina možností, která se mění v závislosti na vybraném typu vyhledávání
- Regulární výraz:má dvě tlačítka; procházet, která prohlíží existující regulární výrazy, a Vytvořit…, která umožňuje vytváření nových regulárních výrazů.
- Fuzzy řetězec:obsahuje pole pro počítání, které určuje práh fuzzy vyhledávání (jak blízko musí být řetězce, aby byly považovány za shodu), a pole se seznamem pro výběr algoritmu fuzzy vyhledávání, který se má použít.
- Soubor hodnot:má tlačítko Procházet…, které vám umožní vyhledat soubor sady, který chcete použít pro hledání hodnot.
- Textové pole, do kterého zadáte data pro vyhledávání.
- Rozbalovací seznam tabulek, na které můžete použít vyhledávání výrazů.
- Rozbalovací seznam sloupců, na které můžete použít vyhledávání výrazu.
- Tabulka se seznamem vámi vytvořených vyhledávání, která provede profiler.
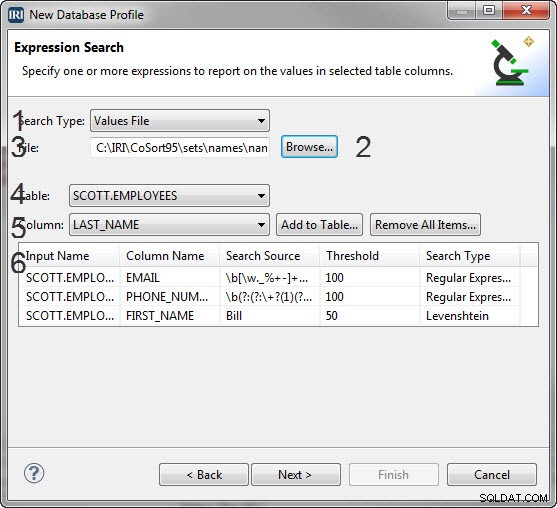
Chcete-li vytvořit filtr regulárních výrazů:
- Z rozbalovacího seznamu Typ vyhledávání vyberte Regulární výraz .
- Klikněte na Procházet do (vaše knihovna uložených výrazů), nebo klikněte na Vytvořit k určení regulárního výrazu, který se má použít při hledání hodnot sloupců.
- V nabídce Tabulka vyberte tabulku obsahující sloupec, který chcete filtrovat.
- V nabídce Sloupec vyberte sloupec, na který se má použít regulární výraz.
- Klikněte na tlačítko Přidat do tabulky a v tabulce níže se zobrazí položka obsahující název souboru, název sloupce, zdroj vyhledávání, prahovou hodnotu a štítek regulárního výrazu, který tvoří filtr.
- Tento postup opakujte pro každý sloupec, do kterého chcete přidat filtr. Pokud máte příliš mnoho sloupců na to, aby byl tento proces praktický, můžete stále automaticky skenovat více sloupců a tabulek – pro data odpovídající vašim vzorům v celém schématu databáze – pomocí tohoto průvodce.
Chcete-li vytvořit hledání fuzzy řetězců:
- Z rozbalovacího seznamu Typ vyhledávání vyberte Nezkreslený řetězec .
- Zadejte řetězec, který chcete použít pro vyhledávání.
- Vyberte počet výsledků, které se mají vrátit (tato možnost se zobrazí, když je vybráno Fuzzy Search).
- Vyberte typ fuzzy vyhledávání, který chcete použít (tato možnost se zobrazí, když vyberete fuzzy řetězec).
- V nabídce Tabulka vyberte soubor, který obsahuje sloupec pro neostré vyhledávání.
- V nabídce Sloupec vyberte sloupec, ve kterém se má provádět fuzzy vyhledávání.
- Klikněte na tlačítko Přidat do tabulky a v tabulce níže se objeví položka obsahující název souboru, název sloupce, zdroj vyhledávání, práh a typ vyhledávání fuzzy vyhledávání, které má být provedeno.
- Tento proces zopakujte pro každý sloupec, ve kterém chcete provést vyhledávání fuzzy řetězců.
Chcete-li vytvořit soubor hodnot, vyhledejte:
- Z kombinace Typ vyhledávání vyberte Soubor hodnot .
- Klikněte na Procházet vyberte soubor, se kterým se bude sloupec kontrolovat.
- V nabídce Tabulka vyberte tabulku obsahující sloupec, který chcete filtrovat.
- V nabídce Sloupec vyberte sloupec, na který má být regulární výraz použit.
- Klikněte na tlačítko Přidat do tabulky a v tabulce níže se zobrazí položka obsahující název souboru, název sloupce, zdroj vyhledávání, prahovou hodnotu a štítek vyhledávání seznamu hodnot, který tvoří filtr.
Kontrola integrity reference
Další možností v tabulce možností je -Check Reference Integrity-. Tato možnost umožňuje nástroji profilování porovnat jeden nebo více sloupců s jiným sloupcem a určit, zda mají sloupce referenční integritu. Chcete-li tuto funkci použít, zaškrtněte ve sloupcích políčka –Check Reference Integrity – a porovnejte referenční integritu. Tlačítko Další se aktivuje a umožní vám zadat parametry pro kontrolu referenční integrity (podrobnosti viz níže).
Pokud jste pro některý ze svých sloupců vybrali možnost Zkontrolovat integritu referenčních údajů, klikněte na Další přejděte na stránku Kontrola integrity referenčních údajů. Tato stránka má následující funkce:
- Dvě pole se seznamem, jedno pro výběr tabulky, ve které je primární klíč, a druhé pro určení sloupce primárního klíče.
- Dvě pole se seznamem, jedno pro výběr tabulky, ve které je cizí klíč, a druhé pro zadání sloupce cizího klíče. K dispozici je také tlačítko pro přidání cizího klíče do seznamu cizích klíčů pro porovnání s primárním klíčem.
- Tlačítko Vytvořit kontrolu integrity pro přidání primárních a cizích sloupců do seznamu níže.
- Seznam, který ukládá všechny kontroly referenční integrity, které bude provádět profiler.

Vytvoření kontroly referenční integrity:
- V rozbalovacím seznamu tabulky ve sloupci Primární klíč vyberte tabulku, ve které je primární klíč.
- V rozbalovacím seznamu sloupců v části Sloupec primárního klíče vyberte primární klíč.
- V rozbalovacím seznamu tabulky ve sloupci Cizí klíč vyberte tabulku, ve které se cizí klíč nachází.
- V rozbalovacím seznamu sloupců ve sloupci Cizí klíč vyberte cizí klíč.
- Klikněte na tlačítko Přidat do seznamu cizích klíčů…
- Opakujte kroky 3–5 pro každý cizí klíč, který má být porovnán s primárním klíčem
- Klikněte na tlačítko Vytvořit kontrolu integrity…
- Opakujte výše uvedené procesy pro každou kontrolu referenční integrity, kterou chcete provést.
Ukázkové výstupy profilu

.csv zobrazený v LibreOffice / .txt zobrazený v EditPad Lite