SQL Server 2014 SP2 a novější vytvářejí runtime („skutečné“) plány provádění, které mohou zahrnovat uplynulý čas a Využití CPU pro každý operátor plánu provádění (viz KB3170113 a tento blogový příspěvek od Pedra Lopese).
Interpretace těchto čísel není vždy tak jednoduchá, jak by se dalo očekávat. Mezi režimem řádků jsou důležité rozdíly a dávkový režim provedení a také složité problémy s paralelností v režimu řádků . SQL Server provádí určité úpravy časování v paralelních plánech na podporu konzistence, ale nejsou dokonale implementovány. To může ztížit vyvozování závěrů pro ladění zvuku.
Cílem tohoto článku je pomoci vám porozumět tomu, odkud v jednotlivých případech pocházejí načasování a jak je lze nejlépe interpretovat v kontextu.
Nastavení
Následující příklady používají veřejné Stack Overflow 2013 databáze (podrobnosti ke stažení), s přidaným jediným indexem:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
Testovací dotazy vrátí počet otázek s přijatou odpovědí, seskupené podle měsíce a roku. Jsou provozovány na SQL Server 2019 CU9 , na notebooku s 8 jádry a 16 GB paměti přidělené instanci SQL Server 2019. Úroveň kompatibility 150 se používá výhradně.
Sériové spouštění v dávkovém režimu
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Prováděcí plán je (kliknutím zvětšíte):
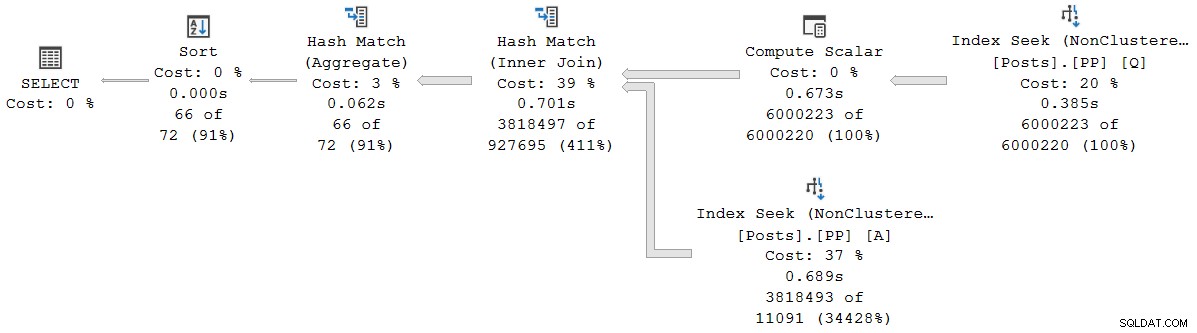
Každý operátor v tomto plánu běží v dávkovém režimu díky dávkovému režimu na rowstore Funkce inteligentního zpracování dotazů v SQL Server 2019 (není potřeba žádný index columnstore). Dotaz běží 2 523 ms s 2 522 ms využitého času CPU, když jsou všechna potřebná data již ve fondu vyrovnávací paměti.
Jak poznamenává Pedro Lopes v dříve odkazovaném příspěvku na blogu, uplynulé časy a časy CPU hlášené pro jednotlivé dávkové režimy operátory představují čas, který používá samotný operátor .
SSMS zobrazuje uplynulý čas v grafickém znázornění. Chcete-li zobrazit časy CPU , vyberte operátora plánu a poté se podívejte do Vlastnosti okno. Tento podrobný pohled ukazuje jak uplynulý čas, tak čas CPU, na operátora a na vlákno.
Časy showplanu (včetně reprezentace XML) jsou zkráceny na milisekundy. Pokud potřebujete větší přesnost, použijte query_thread_profile rozšířená událost, která se hlásí v mikrosekundách . Výstup z této události pro plán provádění uvedený výše je:
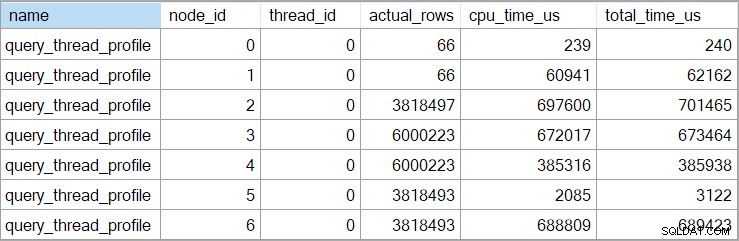
To ukazuje, že uplynulý čas pro spojení (uzel 2) je 701 465 µs (zkráceno na 701 ms v plánu zobrazení). Uplynulý čas agregátu je 62 162 µs (62 ms). Hledání indexu „otázek“ se zobrazuje jako běžící po dobu 385 ms, zatímco rozšířená událost ukazuje, že skutečná hodnota pro uzel 4 byla 385 938 µs (velmi téměř 386 ms).
SQL Server používá vysokou přesnost QueryPerformanceCounter API pro zachycení časových dat. To využívá hardware, typicky krystalový oscilátor, který produkuje tikání velmi vysokou konstantní rychlostí bez ohledu na rychlost procesoru, nastavení napájení nebo cokoliv podobného. Hodiny běží stále stejným tempem i během spánku. Pokud vás zajímají všechny jemnější detaily, podívejte se na odkazovaný velmi podrobný článek. Krátké shrnutí je, že můžete důvěřovat číslům v mikrosekundách, že jsou přesné.
V tomto čistě dávkovém režimu je celková doba provádění velmi blízko součtu uplynulých časů jednotlivých operátorů. Rozdíl je z velké části způsoben prací po příkazu, která není spojena s operátory plánu (které do té doby všechny skončily), i když svou roli hraje také milisekundové zkrácení.
V plánech čistě dávkového režimu musíte ručně sečíst aktuální časy a časy podřízeného operátora, abyste získali kumulativní uplynulý čas v libovolném daném uzlu.
Paralelní spuštění v dávkovém režimu
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Prováděcí plán je:
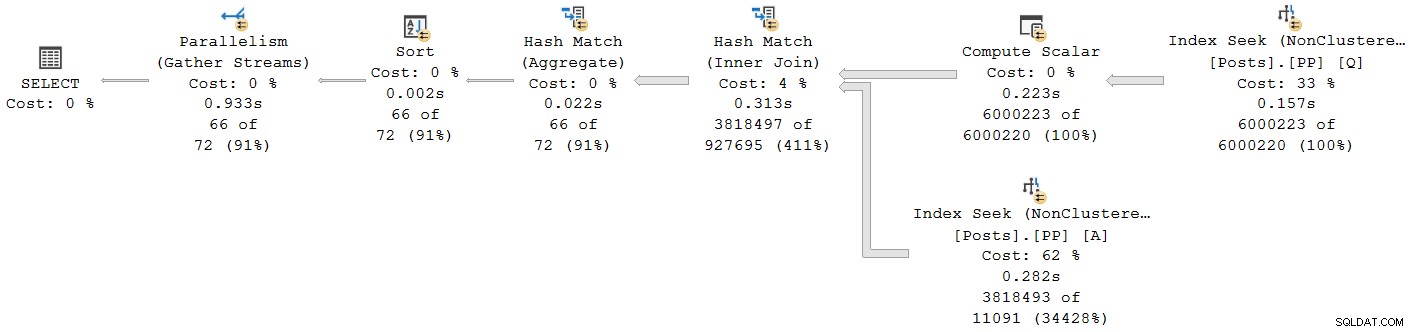
Každý operátor kromě poslední výměny streamu shromažďování běží v dávkovém režimu. Celkový uplynulý čas je 933 ms s 6 673 ms procesorového času s teplou mezipamětí.
Vyberte spojení hash a vyhledejte Vlastnosti SSMS okno, vidíme uplynulý čas a CPU na vlákno pro daného operátora:
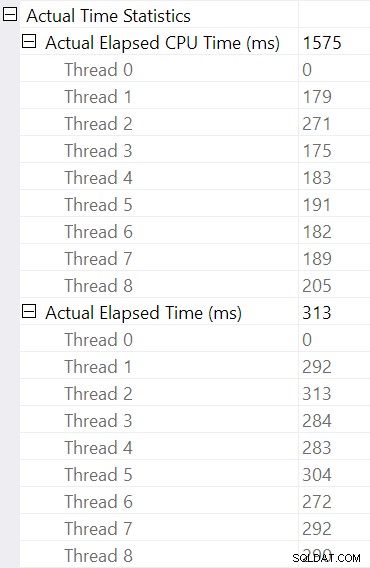
Čas CPU hlášená pro operátora je součet časů CPU jednotlivých vláken. Nahlášený operátor uplynulý čas je maximální uplynulých časů na vlákno. Oba výpočty se provádějí přes zkrácené hodnoty milisekund na vlákno. Stejně jako dříve je celková doba provádění velmi blízko součtu uplynulých časů jednotlivých operátorů.
Paralelní plány v dávkovém režimu nepoužívají výměny k distribuci práce mezi vlákna. Dávkové operátory jsou implementovány tak, aby více vláken mohlo efektivně pracovat na jedné sdílené struktuře (např. hash tabulka). V paralelních plánech v dávkovém režimu je stále vyžadována určitá synchronizace mezi vlákny, ale synchronizační body a další podrobnosti nejsou ve výstupu showplanu viditelné.
Sériové spuštění v režimu řádků
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); Plán provádění je vizuálně stejný jako sériový plán v dávkovém režimu, ale každý operátor nyní běží v režimu řádků:
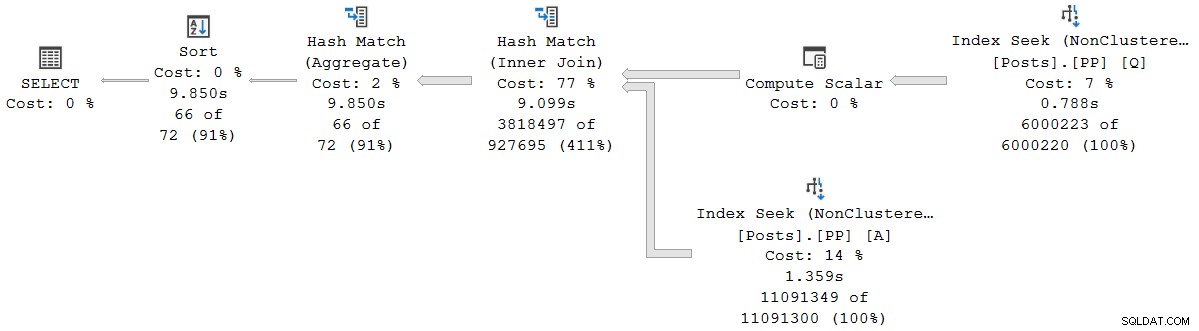
Dotaz běží 9 850 ms s 9 845 ms CPU časem. To je podle očekávání mnohem pomalejší než dotaz sériového dávkového režimu (2523 ms/2522 ms). Pro současnou diskusi je důležitější režim řádků uplynulý operátor a časy CPU představují čas použitý aktuálním operátorem a všemi jeho potomky .
Rozšířená událost také ukazuje kumulativní CPU a uplynulé časy v každém uzlu (v mikrosekundách):
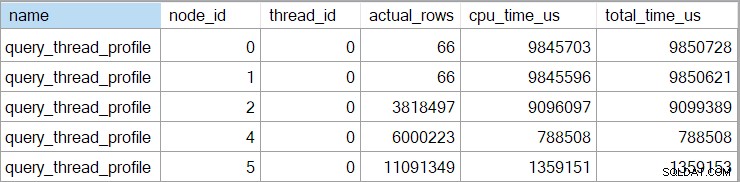
Nejsou k dispozici žádná data pro výpočetní skalární operátor (uzel 3), protože spuštění v režimu řádku může odložit většinu výrazových výpočtů operátorovi, který spotřebovává výsledek. Toto není aktuálně implementováno pro spuštění v dávkovém režimu.
Nahlášené kumulativní uplynulý čas pro operátory v režimu řádků znamená, že čas zobrazený pro operátor konečného řazení se přesně shoduje s celkovou dobou provádění dotazu (v každém případě s rozlišením milisekund). Uplynulý čas pro spojení hash rovněž zahrnuje příspěvky ze dvou hledání indexu pod ním a také svůj vlastní čas. K výpočtu uplynulého času pro samotné spojení hash v režimu řádků bychom od něj museli odečíst oba vyhledávací časy.
Obě prezentace mají své výhody a nevýhody (kumulativní pro řádkový režim, individuální operátor pouze pro dávkový režim). Ať už dáváte přednost čemukoli, je důležité si uvědomit rozdíly.
Plány smíšeného režimu provádění
Obecně mohou moderní prováděcí plány obsahovat jakoukoli kombinaci operátorů v režimu řádků a v dávkovém režimu. Operátoři dávkového režimu budou hlásit časy jen pro sebe. Operátoři režimu řádků zahrnou kumulativní součet do tohoto bodu v plánu, včetně všech dětské operátory. Aby bylo jasno:kumulativní časy operátora v režimu řádků zahrnují jakékoli podřízené operátory dávkového režimu.
Viděli jsme to dříve v plánu paralelního dávkového režimu:Operátor konečného (řádkového) shromažďování streamů měl zobrazený (kumulativní) uplynulý čas 0,933 s – včetně všech jeho podřízených operátorů dávkového režimu. Všichni ostatní operátoři byli v dávkovém režimu, a tak hlásili časy pouze pro jednotlivého operátora.
Tato situace, kdy někteří operátoři plánu ve stejném plánu mají kumulativní časy a ostatní ne, budou nepochybně považovány za matoucí mnoha lidmi.
Paralelní spuštění v režimu řádků
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); Prováděcí plán je:

Každý operátor je v režimu řádků. Dotaz běží 4 677 ms s 23 311 ms CPU (součet všech vláken).
Vzhledem k tomu, že plán výhradně v režimu řádků, očekáváme, že všechny časy budou kumulativní . Přesunutím od dítěte k rodiči (zprava doleva) by se doba měla tímto směrem prodloužit.
Podívejme se na část plánu úplně vpravo:
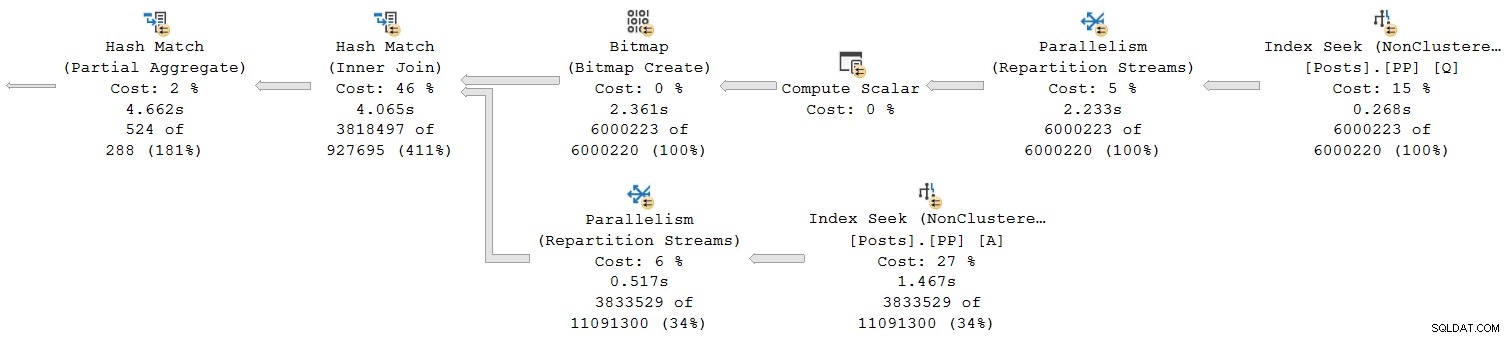
Při práci zprava doleva na horním řádku se zdá, že kumulativní časy jsou určitě případ. Existuje však výjimka na spodním vstupu hašovacího spojení:Vyhledávání indexu má uplynulý čas 1,467 s , zatímco jeho rodič toky přerozdělení mají uplynulý čas pouze 0,517 s .
Jak může rodič provoz operátora kratší dobu než jeho dítě jsou-li uplynulé časy v plánech režimu řádků kumulativní?
Nekonzistentní časy
Odpověď na tuto hádanku má několik částí. Vezměme to kousek po kousku, protože je to docela složité:
Nejprve si připomeňme, že výměna (operátor paralelismu) má dvě části. Levá ruka (spotřebitel ) je připojena k jedné sadě vláken, na kterých běží operátory v paralelní větvi vlevo. Pravá ruka (výrobce ) strana výměny je připojena k jiné sadě vláken, na kterých běží operátory v paralelní větvi vpravo.
Řádky ze strany výrobce jsou sestaveny do paketů a poté převedeny na stranu spotřebitele. To poskytuje určitý stupeň vyrovnávací paměti a řízení toku mezi dvěma sadami spojených závitů. (Pokud si potřebujete osvěžit informace o burzách a větvích paralelních plánů, přečtěte si můj článek Plány paralelního provádění – větve a vlákna.)
Rozsah kumulativních časů
Při pohledu na paralelní větev na producent strana výměny:
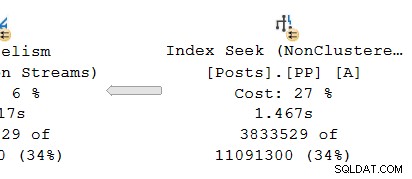
Jako obvykle další pracovní vlákna DOP (stupeň paralelismu) provozují nezávislý sériový kopii operátorů plánu v této pobočce. Takže na DOP 8 existuje 8 nezávislých hledání sériového indexu, které spolupracuje na provádění části skenování rozsahu celkové (paralelní) operace hledání indexu. Každé jednovláknové vyhledávání je připojeno k jinému vstupu (portu) na straně producenta jednotného sdíleného operátor výměny.
Podobná situace je u spotřebitele straně výměny. Na DOP 8 existuje 8 samostatných jednovláknových kopií této větve, které všechny běží nezávisle:
Každý z těchto jednovláknových podplánů běží obvyklým způsobem, přičemž každý operátor shromažďuje uplynulý a celkový čas CPU v každém uzlu. Jelikož se jedná o operátory v režimu řádků, každý součet představuje čas strávený kumulativním součtem pro aktuální uzel a každý z jeho potomků.
Rozhodující je, že kumulativní součty zahrnout operátory pouze ve stejném vláknu a pouze v rámci aktuální pobočky . Doufejme, že to dává intuitivní smysl, protože každé vlákno nemá ponětí, co by se mohlo odehrávat jinde.
Jak se shromažďují metriky režimu řádků
Druhá část hádanky se týká způsobu, jakým se shromažďují metriky počtu řádků a časování v plánech režimu řádků. Když jsou vyžadovány informace o plánu runtime („skutečné“), prováděcí modul přidá neviditelný operátor profilování okamžitě vlevo (rodič) každého operátora v plánu, který bude spuštěn za běhu.
Tento operátor může zaznamenat (mimo jiné) rozdíl mezi časem, kdy předal řízení svému podřízenému operátorovi, a časem, kdy bylo řízení vráceno. Tento časový rozdíl představuje uplynulý čas pro sledovaného operátora a všechny jeho děti , protože dítě volá do svého vlastního potomka v řadě a tak dále. Operátor může být volán mnohokrát (pro inicializaci, pak jednou na řádek a nakonec pro uzavření), takže čas shromážděný operátorem profilování je akumulace přes potenciálně mnoho iterací na řádek.
Další podrobnosti o údajích profilování shromážděné pomocí různých metod sběru, viz produktová dokumentace pokrývající infrastrukturu profilování dotazů. Pro zájemce o takové věci je název neviditelného profilovacího operátora používaného standardní infrastrukturou sqlmin!CQScanProfileNew . Stejně jako všechny iterátory v režimu řádků má Open , GetRow a Close metod, mimo jiné. Každá metoda obsahuje volání QueryPerformanceCounter systému Windows API pro shromažďování aktuální hodnoty časovače s vysokým rozlišením.
Protože operátor profilování je vlevo cílového operátora měří pouze spotřebitele straně výměny. Neexistuje žádný operátor profilování pro výrobce straně výměny (bohužel). Pokud by tomu tak bylo, odpovídalo by to nebo překročilo uplynulý čas zobrazený při hledání indexu, protože strana hledání indexu a strana producenta provozují stejnou sadu vláken a strana producenta burzy je nadřazeným operátorem hledání indexu.
Načasování znovu navštíveno

Se vším, co bylo řečeno, můžete mít stále potíže s načasováním uvedeným výše. Jak může hledání indexu trvat 1,467 s pro předávání řádků na stranu výrobce burzy, ale strana spotřebitele trvá pouze 0,517 s přijímat je? Bez ohledu na samostatná vlákna, ukládání do vyrovnávací paměti a podobně, určitě výměna by měla běžet (od konce ke konci) déle než vyhledávání?
Ano, je, ale to je jiné měření od uplynulého času nebo času CPU. Buďme přesní v tom, co zde měříme.
Pro režim řádků uplynulý čas , představte si stopky na vlákno u každého operátora. Stopky spustí když SQL Server zadá kód pro operátora od svého rodiče a zastaví se (ale neresetuje se), když tento kód opustí operátora, aby vrátil řízení zpět rodiči (nikoli dítěti). Uplynulý čas zahrnuje jakékoli čekání nebo zpoždění při plánování – ani jeden z nich nezastaví hodinky.
Pro režim řádků Čas CPU , představte si stejné stopky se stejnými vlastnostmi, až na to, že se zastaví během čekání a zpoždění při plánování. Akumuluje čas pouze tehdy, když operátor nebo jeden z jeho potomků aktivně spouští na plánovači (CPU). Celkový čas na stopkách podle vlákna na operátora se skládá z cyklu start-stop pro každý řádek.
Aplikujme to na současnou situaci se spotřebitelskou stranou burzy a hledáním indexu:
Pamatujte, že spotřebitelská strana burzy a vyhledávání indexu jsou v samostatných větvích, takže běží na oddělených vláknech . Strana spotřebitele nemá žádné potomky ve stejném vláknu. Vyhledávání indexu má produkční stranu burzy jako svého rodiče stejného vlákna, ale nemáme tam stopky.
Každé spotřebitelské vlákno spustí své sledování, když jeho nadřazený operátor (strana sondy hash spojení) předá řízení (např. pro načtení řádku). Hodinky běží, zatímco spotřebitel načte řádek z aktuálního výměnného paketu. Hodinky se zastaví když kontrola opustí spotřebitele a vrátí se na stranu sondy hash join. Další nadřazené položky (částečný agregát a jeho nadřazená burza) budou také pracovat na tomto řádku (a mohou čekat), než se kontrola vrátí na spotřebitelskou stranu naší burzy, aby načetla další řádek. V tu chvíli začne spotřebitelská strana naší ústředny znovu shromažďovat uplynulý a CPU čas.
Mezitím, nezávisle na tom, co by vlákna větve spotřebitele dělala, hledání indexu vlákna nadále vyhledávají řádky v indexu a vkládají je do výměny. Vlákno hledání indexu spustí své stopky, když ho produkční strana burzy požádá o řádek. Stopky se pozastaví, když je řada předána výměně. Když burza požádá o další řádek, stopky vyhledávání indexu se obnoví.
Všimněte si, že na straně producenta výměny může dojít k CXPACKET čeká, až se zaplní vyrovnávací paměti výměny, ale to se nepřičte k uplynulým časům zaznamenaným při hledání indexu, protože jeho stopky neběží, když k tomu dojde. Pokud bychom měli stopky pro producentskou stranu burzy, chybějící uplynulý čas by se tam ukázal.
Aby bylo možné vizuálně přiblížit shrnutí situace, následující diagram ukazuje, kdy každý operátor shromažďuje uplynulý čas ve dvou paralelních větvích:
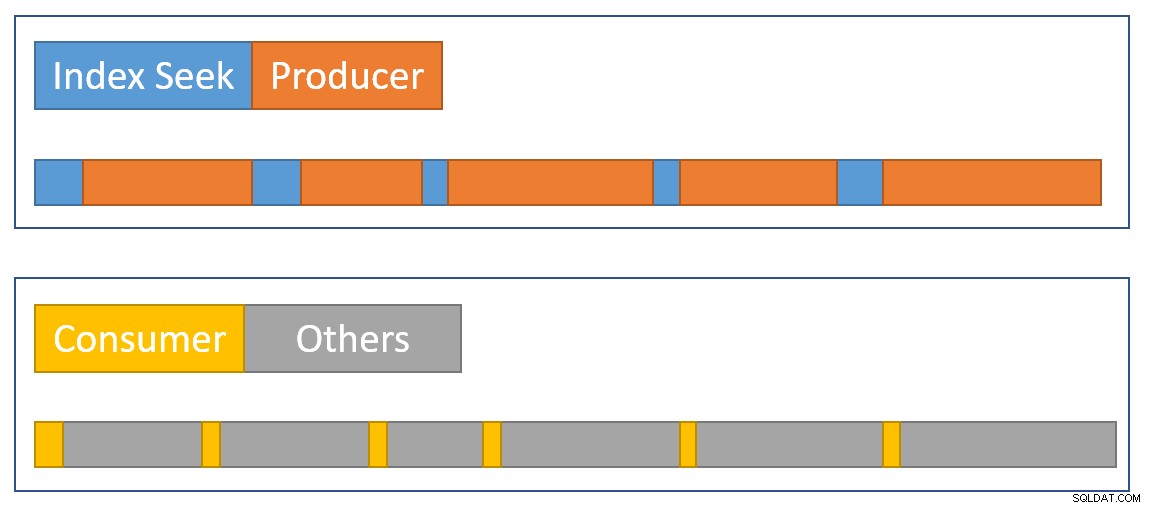
Modrá Časové úsečky vyhledávání indexu jsou krátké, protože načítání řádku z indexu je rychlé. oranžová časy producentů mohou být dlouhé kvůli CXPACKET čeká. žlutá spotřebitelské časy jsou krátké, protože je rychlé načíst řádek z burzy, když jsou k dispozici data. Šedá časové segmenty představují čas využívaný ostatními operátory (strana sondy hash join, částečný agregát a strana producenta mateřské burzy) nad spotřebitelskou stranou burzy.
Očekáváme, že výměnné pakety budou rychle naplněny pomocí hledání indexu, ale vyprazdňuje se pomalu (relativně řečeno) operátory na straně spotřebitelů, protože mají více práce. To znamená, že pakety ve výměně budou obvykle plné nebo téměř plné. Spotřebitel bude moci rychle načíst čekací řádek, ale výrobce možná bude muset počkat, až se objeví prostor pro pakety.
Je škoda, že na straně výrobce burzy nevidíme uplynulé časy. Dlouhodobě zastávám názor, že výměna by měla být zastoupena dvami různých operátorů v prováděcích plánech. Ztížilo by to CXPACKET /CXCONSUMER čekací analýza je mnohem méně nutná a prováděcí plány jsou mnohem srozumitelnější. Provozovatel burzy by přirozeně získal svého vlastního profilovacího operátora.
Alternativní návrhy
Existuje mnoho způsobů, jak může SQL Server dosáhnout konzistentní kumulativní uplynulý a CPU čas napříč paralelními větvemi v principu . Namísto profilování operátorů by každý řádek mohl nést informace o tom, kolik uplynulo a kolik času CPU na jeho cestě plánem dosud nasbíral. S historií spojenou s každým řádkem by nezáleželo na tom, jak burzy přerozdělují řádky mezi vlákna a tak dále.
Takto produkt nebyl navržen, takže takový nemáme (a stejně to může být neefektivní). Abychom byli spravedliví, původní návrh režimu řádků se zabýval pouze věcmi, jako je shromažďování skutečných počtů řádků a počtu iterací u každého operátora. Přidání uplynulého času na operátora do plánů bylo velmi žádanou funkcí , ale nebylo snadné jej začlenit do stávajícího rámce.
Když bylo k produktu přidáno zpracování v dávkovém režimu, mohl být v rámci původního vývoje implementován jiný přístup (načasování pouze pro současného operátora), aniž by se cokoli porušilo. Opět v zásadě Operátory režimu řádků mohly být upraveny tak, aby fungovaly stejným způsobem jako operátory dávkového režimu, ale to by vyžadovalo mnoho práce přepracování každého stávajícího operátora režimu řádků. Přidání nového datového bodu ke stávajícím operátorům profilování v režimu řádků bylo mnohem jednodušší. Vzhledem k omezeným technickým zdrojům a dlouhému seznamu požadovaných vylepšení produktu je často nutné dělat kompromisy, jako je tento.
Druhý problém
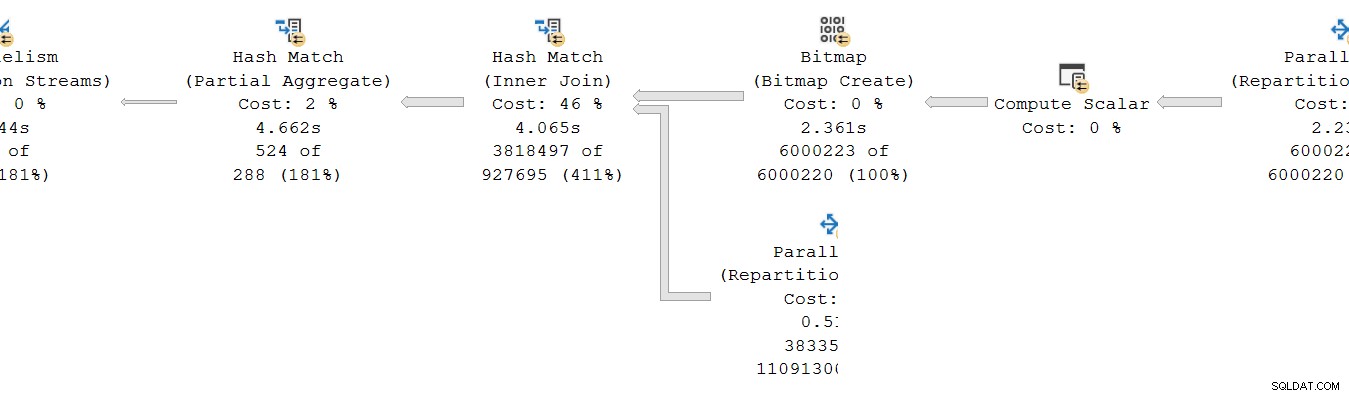
Další kumulativní časová nekonzistence se vyskytuje v současném plánu na levé straně:

Na první pohled to vypadá jako stejný problém:Částečný agregát má uplynulý čas 4,662 s , ale výměna nad ním běží pouze za 2,844 s . Ve hře jsou samozřejmě stejné základní mechaniky jako dříve, ale je tu ještě jeden důležitý faktor. Jedno vodítko spočívá v podezřele stejných časech hlášených pro výměnu agregace, řazení a přerozdělování proudu.
Pamatujete na „úpravy načasování“, které jsem zmínil v úvodu? Zde přicházejí na řadu. Podívejme se na jednotlivé uplynulé časy pro vlákna na spotřebitelské straně výměny toků přerozdělení:
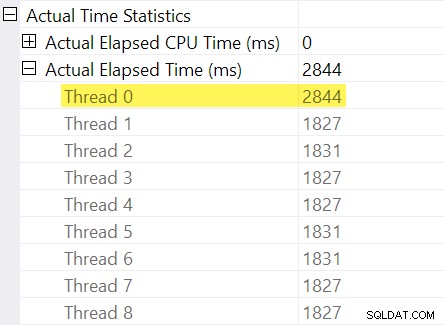
Připomeňme, že plány ukazují uplynulý čas pro paralelní operátor jako maximum časů na vlákno. Všech 8 vláken mělo uplynutý čas kolem 1 830 ms, ale existuje další položka pro „Vlákno 0“ s 2 844 ms. Vlastně každý operátor v této paralelní větvi (spotřebitel burzy, řazení a agregát proudu) mají stejné Příspěvek 2 844 ms z „vlákna 0“.
Vlákno nula (neboli nadřazený úkol nebo koordinátor) pouze přímo spouští operátory nalevo od operátora konečného shromáždění streamů. Proč je mu zde přiřazena práce v paralelní větvi?
Vysvětlení
K tomuto problému může dojít, když je v paralelní větvi níže operátor blokování (vpravo od) aktuálního. Bez této úpravy by operátoři v aktuální pobočce podcenili uplynulý čas podle množství času potřebného k otevření podřízené pobočky (tam jsou složité architektonické důvody pro to).
SQL Server to vysvětluje tím, že zaznamená zpoždění podřízené větve na burze v operátoru neviditelného profilování. Časová hodnota je zaznamenána proti nadřazenému úkolu („Vlákno 0“) v rozdílu mezi jeho prvním aktivním a naposledy aktivní časy. (Může se zdát zvláštní zaznamenat číslo tímto způsobem, ale v době, kdy je nutné číslo zaznamenat, ještě nebyla vytvořena další paralelní pracovní vlákna.
V aktuálním případě úprava 2 844 ms převážně vzniká kvůli času, který potřebuje hash spojení k vytvoření své hashovací tabulky. (Upozorňujeme, že tento čas se liší od celkového čas provedení spojení hash, který zahrnuje čas potřebný ke zpracování testovací strany spojení).
Potřeba úpravy vzniká, protože spojení hash blokuje vstup sestavení. (Zajímavé je, že hash částečný agregát v plánu se v tomto kontextu nepovažuje za blokování, protože je mu přiděleno pouze minimální množství paměti, nikdy se nepřesype do tempdb a jednoduše zastaví agregaci, pokud dojde paměť (a tím se vrátí do režimu streamování). Craig Freedman to vysvětluje ve svém příspěvku Částečná agregace).
Vzhledem k tomu, že úprava uplynulého času představuje zpoždění inicializace v podřízené větvi, SQL Server měl zacházet s hodnotou „Vlákno 0“ jako s offsetem pro měřená čísla uplynulého času na vlákno v rámci aktuální větve. Využití maximum všech vláken, protože uplynulý čas je obecně rozumný, protože vlákna mají tendenci začínat ve stejnou dobu. není má smysl to dělat, když jedna z hodnot vlákna je offset pro všechny ostatní hodnoty!
Můžeme provést správný výpočet offsetu ručně pomocí dat dostupných v plánu. Na spotřebitelské straně burzy máme:
Maximální uplynulý čas mezi dalšími pracovními vlákny je 1 831 ms (s výjimkou hodnoty offsetu uložené v „vlákně 0“). Přidání offsetu 2 844 ms dává celkem 4 675 ms .
V každém plánu, kde jsou časy na vlákno menší než offset, operátor nesprávně zobrazit posun jako celkový uplynulý čas. K tomu pravděpodobně dojde, když je dřívější blokující operátor pomalý (možná třídění nebo globální agregace přes velkou sadu dat) a provozovatelé pozdějších poboček jsou méně časově nároční.
Opětovná návštěva této části plánu:
Nahrazení 2 844 ms offsetu chybně přiřazeného operátorům přerozdělovacích proudů, řazení a streamování agregací našimi vypočítanými 4 675 ms hodnota uvádí jejich kumulativní uplynulé časy úhledně mezi 4 662 ms v částečném souhrnu a 4 676 ms na závěrečných shromažďovacích proudech. (Řazení a agregace fungují na malém počtu řádků, takže jejich výpočty uplynulého času vycházejí stejně jako řazení, ale obecně by se často lišily):

Všichni operátoři ve výše uvedeném fragmentu plánu mají 0 ms uplynulého času CPU ve všech vláknech (kromě částečného souhrnu, který má 14 891 ms). Plán s našimi vypočítanými čísly tedy dává mnohem větší smysl než ten zobrazený:
- 4 675 ms – 4 662 ms =13 ms elapsed je mnohem rozumnější číslo pro dobu spotřebovanou proudy přerozdělení samotnými . Tento operátor nespotřebovává žádný čas CPU a zpracovává pouze 524 řádků.
- 0 ms elapsed (na milisekundové rozlišení) je rozumné pro malý agregát řazení a streamů (opět s výjimkou jejich potomků).
- 4 676 ms – 4 675 ms =1 ms Zdá se, že pro finální shromažďovací proudy je dobré shromáždit 66 řádků do vlákna nadřazené úlohy pro návrat ke klientovi.
Kromě zjevné nekonzistence v daném plánu mezi dílčím agregovaným (4 662 ms) a přerozdělovacím tokem (2 844 ms) je nerozumné se domnívat, že konečné shromažďovací toky o 66 řádcích by mohly být odpovědné za 4 676 ms – 2 844 ms = 1 832 ms uplynulého času. Opravené číslo (1 ms) je mnohem přesnější a neuvede ladiče dotazů v omyl.
Nyní, i když byl tento výpočet offsetu proveden správně, plány režimu paralelních řádků nemusí ne ukazovat konzistentní kumulativní časy ve všech případech z důvodů diskutovaných výše. Dosažení úplné konzistence může být obtížné, nebo dokonce nemožné bez velkých architektonických změn.
Abychom předjímali otázku, která by v tomto bodě mohla vyvstat:Ne, dřívější analýza burzy a hledání indexu nezahrnovala chybu výpočtu offsetu „vlákno 0“. Pod touto výměnou není žádný blokující operátor, takže nedochází k žádnému zpoždění inicializace.
Poslední příklad
Tento další příklad dotazu používá stejnou databázi a index jako dříve. Nebudu to zkoumat příliš podrobně, protože slouží pouze k rozšíření bodů, které jsem již uvedl, pro zainteresovaného čtenáře.
Funkce této ukázky jsou:
- Bez
ORDER GROUPnápověda, ukazuje, že částečný agregát není považován za blokující operátor, takže při výměně přerozdělovacích toků nedochází k žádné úpravě „vlákna 0“. Uplynulé časy jsou konzistentní. - S nápovědou jsou zavedena blokující řazení namísto částečného agregace hash. Dva různé Úpravy „vlákna 0“ se objeví na dvou výměnách rozdělení. Uplynulé časy jsou na obou větvích nekonzistentní, a to různými způsoby.
Dotaz:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
Plán provádění bez ORDER GROUP (žádná úprava, konzistentní časy):

Plán provádění s ORDER GROUP (dvě různé úpravy, nekonzistentní časy):

Shrnutí a závěry
Operátoři plánu režimu řádků hlásí kumulativní times inclusive of all child operators in the same thread. Batch mode operators record the time used inside that operator alone .
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.