V části 1 této série jste pomocí Flask a Connexion vytvořili REST API poskytující operace CRUD jednoduché struktuře v paměti nazvané PEOPLE . To fungovalo jako ukázka toho, jak vám modul Connexion pomáhá vytvořit pěkné REST API spolu s interaktivní dokumentací.
Jak někteří poznamenali v komentářích k 1. části, PEOPLE struktura se znovu inicializuje při každém restartu aplikace. V tomto článku se dozvíte, jak uložit PEOPLE struktura a akce, které API poskytuje, do databáze pomocí SQLAlchemy a Marshmallow.
SQLAlchemy poskytuje Object Relational Model (ORM), který ukládá objekty Pythonu do databázové reprezentace dat objektu. To vám může pomoci pokračovat v uvažování v Pythonicu a nestarat se o to, jak budou data objektu reprezentována v databázi.
Marshmallow poskytuje funkce pro serializaci a deserializaci objektů Pythonu, když proudí z a do našeho REST API založeného na JSON. Marshmallow převádí instance třídy Python na objekty, které lze převést na JSON.
Kód Pythonu pro tento článek naleznete zde.
Box zdarma: Kliknutím sem si stáhnete kopii příručky "Příklady rozhraní REST API" a získáte praktický úvod do principů rozhraní Python + REST API s praktickými příklady.
Pro koho je tento článek určen
Pokud se vám líbila část 1 této série, tento článek ještě více rozšiřuje váš opasek na nářadí. Budete používat SQLAlchemy pro přístup k databázi více pythonickým způsobem než přímo SQL. Marshmallow také použijete k serializaci a deserializaci dat spravovaných rozhraním REST API. K tomu budete využívat základní funkce objektově orientovaného programování dostupné v Pythonu.
SQLAlchemy budete také používat k vytvoření databáze a také k interakci s ní. To je nezbytné pro zprovoznění REST API s PEOPLE údaje použité v části 1.
Webová aplikace představená v 1. části bude mít své soubory HTML a JavaScript drobně upraveny, aby také podporovala změny. Konečnou verzi kódu z části 1 si můžete prohlédnout zde.
Další závislosti
Než začnete budovat tuto novou funkci, budete muset aktualizovat virtuální prostředí, které jste vytvořili, abyste mohli spustit kód části 1, nebo vytvořit nový pro tento projekt. Nejjednodušší způsob, jak to udělat po aktivaci vašeho virtualenv, je spustit tento příkaz:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
To přidává další funkce do vašeho virtuálního prostředí:
-
Flask-SQLAlchemypřidává SQLAlchemy spolu s některými vazbami na Flask, což umožňuje programům přístup k databázím. -
flask-marshmallowpřidává Flask části Marshmallow, které umožňují programům převádět objekty Pythonu do a ze serializovatelných struktur. -
marshmallow-sqlalchemypřidává do SQLAlchemy několik háčků Marshmallow, které umožňují programům serializovat a deserializovat objekty Pythonu generované SQLAlchemy. -
marshmallowpřidává většinu funkcí Marshmallow.
Údaje o lidech
Jak je uvedeno výše, PEOPLE datová struktura v předchozím článku je in-memory Python slovník. V tomto slovníku jste jako vyhledávací klíč použili příjmení osoby. Struktura dat vypadala v kódu takto:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
Úpravy, které v programu provedete, přesunou všechna data do databázové tabulky. To znamená, že data budou uložena na váš disk a budou existovat mezi spuštěními server.py program.
Protože příjmení bylo klíčem slovníku, kód omezoval změnu příjmení osoby:změnit bylo možné pouze křestní jméno. Přesunutí do databáze vám navíc umožní změnit příjmení, protože již nebude používáno jako vyhledávací klíč pro osobu.
Koncepčně lze databázovou tabulku chápat jako dvourozměrné pole, kde řádky jsou záznamy a sloupce jsou pole v těchto záznamech.
Databázové tabulky mají obvykle automaticky se zvyšující celočíselnou hodnotu jako vyhledávací klíč k řádkům. To se nazývá primární klíč. Každý záznam v tabulce bude mít primární klíč, jehož hodnota je jedinečná v celé tabulce. Primární klíč nezávislý na datech uložených v tabulce vám umožňuje upravovat jakékoli další pole v řádku.
Poznámka:
Automaticky se zvyšující primární klíč znamená, že databáze se stará o:
- Zvýšení největšího existujícího pole primárního klíče pokaždé, když je do tabulky vložen nový záznam
- Použití této hodnoty jako primárního klíče pro nově vložená data
To zaručuje jedinečný primární klíč, jak tabulka roste.
Budete postupovat podle konvence databáze pojmenování tabulky jako jednotného čísla, takže tabulka se bude nazývat person . Překlad našeho PEOPLE struktury výše do databázové tabulky s názvem person vám dává toto:
| person_id | jméno | jméno | časové razítko |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Velikonoce | Zajíček | 2018-08-08 21:16:01.886834 |
Každý sloupec v tabulce má název pole takto:
person_id: pole primárního klíče pro každou osobulname: příjmení osobyfname: křestní jméno osobytimestamp: časové razítko spojené s akcemi vložení/aktualizace
Interakce s databází
Budete používat SQLite jako databázový stroj pro ukládání PEOPLE data. SQLite je nejrozšířenější databáze na světě a je dodávána s Pythonem zdarma. Je rychlý, veškerou svou práci provádí pomocí souborů a je vhodný pro mnoho projektů. Je to kompletní RDBMS (Relational Database Management System), který zahrnuje SQL, jazyk mnoha databázových systémů.
Pro tuto chvíli si představte person tabulka již v databázi SQLite existuje. Pokud máte nějaké zkušenosti s RDBMS, pravděpodobně znáte SQL, strukturovaný dotazovací jazyk, který většina RDBMS používá k interakci s databází.
Na rozdíl od programovacích jazyků, jako je Python, SQL nedefinuje jak získat data:popisuje co data jsou požadována, ponecháme jak až po databázový stroj.
SQL dotaz získávající všechna data v naší person tabulka seřazená podle příjmení by vypadala takto:
SELECT * FROM person ORDER BY 'lname';
Tento dotaz říká databázovému stroji, aby získal všechna pole z tabulky osob a seřadil je ve výchozím, vzestupném pořadí pomocí lname pole.
Pokud byste tento dotaz spustili proti databázi SQLite obsahující person tabulkou, výsledky by byly množinou záznamů obsahujících všechny řádky v tabulce, přičemž každý řádek obsahuje data ze všech polí tvořících řádek. Níže je uveden příklad použití nástroje příkazového řádku SQLite, který spouští výše uvedený dotaz proti person databázová tabulka:
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
Výstup výše je seznam všech řádků v person databázová tabulka se svislými znaky (‚|‘) oddělujícími pole v řádku, což pro účely zobrazení provádí SQLite.
Python je zcela schopen propojit se s mnoha databázovými stroji a provádět výše uvedený SQL dotaz. Výsledkem by byl s největší pravděpodobností seznam n-tic. Vnější seznam obsahuje všechny záznamy v person stůl. Každá jednotlivá vnitřní n-tice by obsahovala všechna data představující každé pole definované pro řádek tabulky.
Získávání dat tímto způsobem není příliš Pythonic. Seznam záznamů je v pořádku, ale každý jednotlivý záznam je jen množina dat. Je na programu, aby znal index každého pole, aby mohl načíst konkrétní pole. Následující kód Pythonu používá SQLite k ukázce, jak spustit výše uvedený dotaz a zobrazit data:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
Výše uvedený program dělá následující:
-
Řádek 1 importuje
sqlite3modul. -
Řádek 3 vytvoří připojení k souboru databáze.
-
Řádek 4 vytvoří kurzor ze spojení.
-
Řádek 5 používá kurzor ke spuštění
SQLdotaz vyjádřený jako řetězec. -
Řádek 6 získá všechny záznamy vrácené
SQLdotaz a přiřadí jepeopleproměnná. -
Řádek 7 a 8 iterujte přes
peopleseznam a vytiskněte jméno a příjmení každé osoby.
people proměnná z Řádek 6 výše by v Pythonu vypadala takto:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
Výstup výše uvedeného programu vypadá takto:
Kent Brockman
Bunny Easter
Doug Farrell
Ve výše uvedeném programu musíte vědět, že křestní jméno osoby je na indexu 2 a příjmení osoby je na indexu 1 . Horší je, že vnitřní struktura person musí být také znám vždy, když předáváte iterační proměnnou person jako parametr funkce nebo metody.
Bylo by mnohem lepší, kdyby to, co jste dostali zpět, za person byl objekt Pythonu, kde každé z polí je atributem objektu. To je jedna z věcí, kterou SQLAlchemy dělá.
Tabulky malého Bobbyho
Ve výše uvedeném programu je příkaz SQL jednoduchý řetězec předaný přímo do databáze k provedení. V tomto případě to není problém, protože SQL je řetězcový literál zcela pod kontrolou programu. Případ použití vašeho REST API však vezme uživatelský vstup z webové aplikace a použije jej k vytvoření SQL dotazů. To může otevřít vaši aplikaci k útoku.
Z části 1 si pamatujete, že pomocí REST API získáte jednu person z PEOPLE data vypadala takto:
GET /api/people/{lname}
To znamená, že vaše API očekává proměnnou lname , v cestě koncového bodu URL, kterou používá k nalezení jedné person . Úprava kódu Python SQLite shora za tímto účelem by vypadala asi takto:
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
Výše uvedený fragment kódu dělá následující:
-
Řádek 1 nastaví
lnameproměnná na'Farrell'. To by pocházelo z cesty koncového bodu REST API URL. -
Řádek 2 používá formátování řetězce Python k vytvoření řetězce SQL a jeho spuštění.
Aby to bylo jednoduché, výše uvedený kód nastavuje lname proměnná na konstantu, ale ve skutečnosti by to pocházelo z cesty koncového bodu API URL a mohlo by to být cokoliv dodané uživatelem. SQL generovaný formátováním řetězce vypadá takto:
SELECT * FROM person WHERE lname = 'Farrell'
Když databáze spustí tento SQL, vyhledá person tabulka pro záznam, kde se příjmení rovná 'Farrell' . To je zamýšleno, ale jakýkoli program, který přijímá uživatelské vstupy, je také otevřený uživatelům se zlými úmysly. V programu výše, kde je lname je nastavena uživatelem zadaným vstupem, to otevře váš program tomu, co se nazývá útok SQL injection. To je to, co je láskyplně známé jako stoly malého Bobbyho:
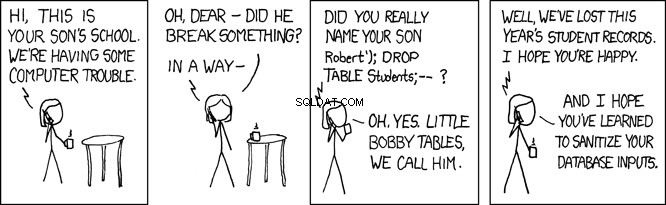
Představte si například uživatele se zlými úmysly, který nazývá vaše REST API tímto způsobem:
GET /api/people/Farrell');DROP TABLE person;
Výše uvedený požadavek REST API nastavuje lname proměnná na 'Farrell');DROP TABLE person;' , který by ve výše uvedeném kódu vygeneroval tento SQL příkaz:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
Výše uvedený SQL příkaz je platný a při spuštění databází najde jeden záznam, kde lname odpovídá 'Farrell' . Poté najde oddělovací znak SQL příkazu ; a půjde přímo dopředu a shodí celý stůl. To by v podstatě zničilo vaši aplikaci.
Svůj program můžete chránit dezinfekcí všech dat, která získáte od uživatelů vaší aplikace. Dezinfekce dat v tomto kontextu znamená nechat váš program prozkoumat data dodaná uživatelem a ujistit se, že neobsahují nic nebezpečného pro program. To může být složité udělat správně a muselo by se to dělat všude, kde uživatelská data interagují s databází.
Existuje další způsob, který je mnohem jednodušší:použijte SQLAlchemy. Před vytvořením příkazů SQL za vás vyčistí uživatelská data. Je to další velká výhoda a důvod, proč používat SQLAlchemy při práci s databázemi.
Modelování dat pomocí SQLAlchemy
SQLAlchemy je velký projekt a poskytuje spoustu funkcí pro práci s databázemi pomocí Pythonu. Jednou z věcí, které poskytuje, je ORM, neboli Object Relational Mapper, a to je to, co budete používat k vytváření a práci s person databázová tabulka. To vám umožňuje namapovat řadu polí z databázové tabulky na objekt Pythonu.
Objektově orientované programování vám umožňuje propojit data s chováním, funkcemi, které s těmito daty pracují. Vytvořením tříd SQLAlchemy můžete propojit pole z řádků databázové tabulky s chováním, což vám umožní interagovat s daty. Zde je definice třídy SQLAlchemy pro data v person databázová tabulka:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
Třída Person dědí z db.Model , ke kterému se dostanete, když začnete vytvářet programový kód. Prozatím to znamená, že dědíte ze základní třídy s názvem Model , poskytující atributy a funkce společné všem třídám z něj odvozeným.
Zbytek definic jsou atributy na úrovni třídy definované takto:
-
__tablename__ = 'person'spojuje definici třídy spersondatabázová tabulka. -
person_id = db.Column(db.Integer, primary_key=True)vytvoří databázový sloupec obsahující celé číslo, které funguje jako primární klíč pro tabulku. To také říká databázi, žeperson_idbude automaticky se zvyšující celočíselnou hodnotou. -
lname = db.Column(db.String)vytvoří pole příjmení, sloupec databáze obsahující hodnotu řetězce. -
fname = db.Column(db.String)vytvoří pole křestního jména, sloupec databáze obsahující hodnotu řetězce. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)vytvoří pole časového razítka, databázový sloupec obsahující hodnotu data/času.default=datetime.utcnowparametr nastaví výchozí hodnotu časového razítka na aktuálníutcnowhodnotu při vytvoření záznamu.onupdate=datetime.utcnowparametr aktualizuje časové razítko aktuálnímutcnowhodnotu při aktualizaci záznamu.
Poznámka:Časová razítka UTC
Možná se divíte, proč je časové razítko ve výše uvedené třídě výchozí a aktualizováno pomocí datetime.utcnow() metoda, která vrací UTC nebo koordinovaný světový čas. Toto je způsob, jak standardizovat zdroj vašeho časového razítka.
Zdroj neboli nulový čas je čára vedoucí na sever a na jih od zemského severního k jižnímu pólu přes Spojené království. Toto je nulové časové pásmo, od kterého jsou všechna ostatní časová pásma posunuta. Při použití tohoto jako zdroje nulového času jsou vaše časová razítka posunuta od tohoto standardního referenčního bodu.
Pokud je vaše aplikace přístupná z různých časových pásem, máte způsob, jak provádět výpočty data/času. Vše, co potřebujete, je časové razítko UTC a cílové časové pásmo.
Pokud byste jako zdroj časových razítek použili místní časová pásma, nemohli byste provádět výpočty data/času bez informací o posunutí místních časových pásem od nulového času. Bez informací o zdroji časových razítek byste nemohli provádět žádné porovnávání data/času ani matematiku.
Práce s časovými razítky založenými na UTC je dobrým standardem. Zde je stránka se sadou nástrojů, se kterou můžete pracovat a lépe jim porozumět.
Kam s touto person míříte definice třídy? Konečným cílem je umět spustit dotaz pomocí SQLAlchemy a získat zpět seznam instancí Person třída. Jako příklad se podívejme na předchozí příkaz SQL:
SELECT * FROM people ORDER BY lname;
Ukažte stejný malý příklad programu shora, ale nyní s použitím SQLAlchemy:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
Pokud v tuto chvíli ignorujete řádek 1, chcete pouze person záznamy seřazené vzestupně podle lname pole. Co získáte zpět z příkazů SQLAlchemy Person.query.order_by(Person.lname).all() je seznam Person objektů pro všechny záznamy v person databázovou tabulku v tomto pořadí. Ve výše uvedeném programu jsou people proměnná obsahuje seznam Person objektů.
Program iteruje přes people proměnná, přičemž každá person obratem a vytištěním jména a příjmení osoby z databáze. Všimněte si, že program nemusí k získání fname používat indexy nebo lname hodnoty:používá atributy definované v Person objekt.
Použití SQLAlchemy vám umožňuje uvažovat v pojmech objektů s chováním spíše než v surovém SQL . To se stane ještě výhodnějším, když se vaše databázové tabulky zvětší a interakce budou složitější.
Serializace/deserializace modelovaných dat
Práce s daty modelovanými SQLAlchemy uvnitř vašich programů je velmi pohodlná. To je zvláště výhodné v programech, které manipulují s daty, například provádějí výpočty nebo je používají k vytváření prezentací na obrazovce. Vaše aplikace je rozhraní REST API, které v podstatě poskytuje operace CRUD s daty, a jako takové neprovádí mnoho manipulace s daty.
REST API pracuje s daty JSON a zde můžete narazit na problém s modelem SQLAlchemy. Protože data vrácená SQLAlchemy jsou instance třídy Python, Connexion nemůže serializovat tyto instance třídy na data ve formátu JSON. Pamatujte z části 1, že Connexion je nástroj, který jste použili k návrhu a konfiguraci REST API pomocí souboru YAML a k připojení metod Pythonu k němu.
V tomto kontextu serializace znamená převod objektů Pythonu, které mohou obsahovat jiné objekty Pythonu a komplexní datové typy, na jednodušší datové struktury, které lze analyzovat do datových typů JSON, které jsou uvedeny zde:
string: typ řetězcenumber: čísla podporovaná Pythonem (celá čísla, floats, longs)object: objekt JSON, který je zhruba ekvivalentní pythonskému slovníkuarray: zhruba ekvivalentní seznamu Pythonboolean: reprezentováno v JSON jakotruenebofalse, ale v Pythonu jakoTrueneboFalsenull: v podstatěNonev Pythonu
Například vaše Person třída obsahuje časové razítko, což je Python DateTime . V JSON není žádná definice data/času, takže časové razítko musí být převedeno na řetězec, aby existovalo ve struktuře JSON.
Vaše person třída je dostatečně jednoduchá, takže získání datových atributů z ní a ruční vytvoření slovníku pro návrat z našich koncových bodů REST URL by nebylo příliš těžké. Ve složitější aplikaci s mnoha většími modely SQLAlchemy by tomu tak nebylo. Lepším řešením je použít modul s názvem Marshmallow, který to udělá za vás.
Marshmallow vám pomůže vytvořit PersonSchema třída, která je jako SQLAlchemy Person třídu, kterou jsme vytvořili. Zde však namísto mapování databázových tabulek a názvů polí na třídu a její atributy, PersonSchema class definuje, jak budou atributy třídy převedeny do formátů vhodných pro JSON. Zde je definice třídy Marshmallow pro data v naší person tabulka:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
Třída PersonSchema dědí z ma.ModelSchema , ke kterému se dostanete, když začnete vytvářet programový kód. Prozatím to znamená PersonSchema dědí ze základní třídy Marshmallow s názvem ModelSchema , poskytující atributy a funkce společné všem třídám z něj odvozeným.
Zbytek definice je následující:
-
class Metadefinuje třídu s názvemMetave vaší třídě.ModelSchematřídaPersonSchematřída dědí z hledá toto interníMetatřídy a používá ji k nalezení modelu SQLAlchemyPersonadb.session. Tímto způsobem Marshmallow nachází atributy vPersonclass a typ těchto atributů, aby věděl, jak je serializovat/deserializovat. -
modelříká třídě, jaký model SQLAlchemy má použít k serializaci/deserializaci dat do az. -
db.sessionříká třídě, jakou databázovou relaci má použít k introspekci a určení atributových datových typů.
Kam míříte touto definicí třídy? Chcete mít možnost serializovat instanci Person třídy do dat JSON a deserializovat data JSON a vytvořit Person instance třídy z něj.
Vytvořte inicializovanou databázi
SQLAlchemy zpracovává mnoho interakcí specifických pro konkrétní databáze a umožňuje vám zaměřit se na datové modely a také na to, jak je používat.
Nyní, když se skutečně chystáte vytvořit databázi, jak již bylo zmíněno, použijete SQLite. Děláte to z několika důvodů. Dodává se s Pythonem a nemusí se instalovat jako samostatný modul. Ukládá všechny databázové informace do jediného souboru, a proto se snadno nastavuje a používá.
Instalace samostatného databázového serveru, jako je MySQL nebo PostgreSQL, by fungovala dobře, ale vyžadovala by instalaci těchto systémů a jejich uvedení do provozu, což je nad rámec tohoto článku.
Protože SQLAlchemy zpracovává databázi, v mnoha ohledech opravdu nezáleží na tom, jaká je podkladová databáze.
Chystáte se vytvořit nový obslužný program s názvem build_database.py k vytvoření a inicializaci SQLite people.db databázový soubor obsahující vaši person databázová tabulka. Během toho vytvoříte dva moduly Pythonu, config.py a models.py , kterou bude používat build_database.py a upravený server.py z části 1.
Zde najdete zdrojový kód pro moduly, které se chystáte vytvořit a které jsou představeny zde:
-
config.pyzíská potřebné moduly importované do programu a nakonfigurované. To zahrnuje Flask, Connexion, SQLAlchemy a Marshmallow. Protože jej budou používat obabuild_database.pyaserver.py, některé části konfigurace se budou vztahovat pouze naserver.pyaplikace. -
models.pyje modul, ve kterém vytvořítePersonSQLAlchemy aPersonSchemaVýše popsané definice třídy Marshmallow. Tento modul je závislý naconfig.pypro některé tam vytvořené a nakonfigurované objekty.
Konfigurační modul
Soubor config.py modul, jak název napovídá, je místem, kde se vytvářejí a inicializují všechny konfigurační informace. Tento modul budeme používat pro oba naše build_database.py program a brzy bude aktualizován server.py soubor z článku 1. části. To znamená, že zde nakonfigurujeme Flask, Connexion, SQLAlchemy a Marshmallow.
I když build_database.py program nevyužívá Flask, Connexion nebo Marshmallow, ale používá SQLAlchemy k vytvoření našeho připojení k databázi SQLite. Zde je kód pro config.py modul:
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Výše uvedený kód dělá toto:
-
Řádky 2–4 importujte Connexion jako v
server.pyprogram z části 1. Také importujeSQLAlchemyzflask_sqlalchemymodul. To dává vašemu programu přístup k databázi. Nakonec importujeMarshmallowzflask_marshamllowmodul. -
Řádek 6 vytvoří proměnnou
basedirukazující na adresář, ve kterém program běží. -
Řádek 9 používá
basedirproměnnou k vytvoření instance aplikace Connexion a přidělte jí cestu kswagger.ymlsoubor. -
Řádek 12 vytvoří proměnnou
app, což je instance Flask inicializovaná Connexion. -
Řádky 15 používá
appproměnnou pro konfiguraci hodnot používaných SQLAlchemy. Nejprve nastavíSQLALCHEMY_ECHOnaTrue. To způsobí, že SQLAlchemy odešle příkazy SQL, které provede, do konzoly. To je velmi užitečné pro ladění problémů při vytváření databázových programů. Nastavte toto naFalsepro produkční prostředí. -
Řádek 16 nastaví
SQLALCHEMY_DATABASE_URInasqlite:////' + os.path.join(basedir, 'people.db'). To říká SQLAlchemy, aby použila SQLite jako databázi a soubor s názvempeople.dbv aktuálním adresáři jako databázový soubor. Různé databázové stroje, jako je MySQL a PostgreSQL, budou mít různéSQLALCHEMY_DATABASE_URIřetězce pro jejich konfiguraci. -
Řádek 17 nastaví
SQLALCHEMY_TRACK_MODIFICATIONSnaFalse, vypnutí systému událostí SQLAlchemy, který je ve výchozím nastavení zapnutý. Systém událostí generuje události užitečné v programech řízených událostmi, ale zvyšuje značnou režii. Protože nevytváříte program řízený událostmi, vypněte tuto funkci. -
Řádek 19 vytvoří
dbproměnnou volánímSQLAlchemy(app). Tím se SQLAlchemy inicializuje předánímappprávě nastavené konfigurační informace.dbproměnná je to, co je importováno dobuild_database.pyprogram, který mu umožní přístup k SQLAlchemy a databázi. Bude sloužit stejnému účelu vserver.pyprogram apeople.pymodul. -
Řádek 23 vytvoří
maproměnnou volánímMarshmallow(app). Tím se Marshmallow inicializuje a umožní mu prohlédnout si komponenty SQLAlchemy připojené k aplikaci. To je důvod, proč je Marshmallow inicializován po SQLAlchemy.
Model Modely
Soubor models.py modul je vytvořen, aby poskytoval Person a PersonSchema třídy přesně tak, jak je popsáno v oddílech výše o modelování a serializaci dat. Zde je kód pro tento modul:
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Výše uvedený kód dělá toto:
-
Řádek 1 importuje
datetimeobjekt zdatetimemodul, který je dodáván s Pythonem. To vám dává způsob, jak vytvořit časové razítko vPersontřída. -
Řádek 2 importuje
dbamaproměnné instance definované vconfig.pymodul. To dává modulu přístup k atributům a metodám SQLAlchemy připojeným kdbproměnná a atributy a metody Marshmallow připojené kmaproměnná. -
Řádky 4–9 definovat
Persontřídy, jak je popsáno v sekci datového modelování výše, ale nyní víte, kde jedb.Modelze kterého třída dědí pochází. Tím získátePersontřídy SQLAlchemy, jako je připojení k databázi a přístup k jejím tabulkám. -
Řádky 11–14 definovat
PersonSchematřídy, jak bylo diskutováno v části serializace dat výše. Tato třída dědí zma.ModelSchemaa poskytnePersonSchemafunkce třídy Marshmallow, jako je introspekcePersonclass to help serialize/deserialize instances of that class.
Creating the Database
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People data. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports the
dbinstance from theconfig.pymodul. -
Line 3 imports the
Personclass definition from themodels.pymodul. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()volání. This creates the database by using thedbinstance imported from theconfigmodul.dbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate aPersonclass. After it is instantiated, you call thedb.session.add(p)funkce. This uses the database connection instancedbto access thesessionobjekt. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionobjekt. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
Poznámka: At Line 22, no data has been added to the database. Everything is being saved within the session objekt. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py soubor. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname value.
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Action | HTTP Verb | URL Path | Popis |
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people stůl. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT responses. You can check out the updated swagger.yml soubor.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pymodul. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeopleseznam. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
Poznámka: The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person databáze. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()instance. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person objekt. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personisNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} sekce. This section of the UI gets a single person from the database and looks like this:
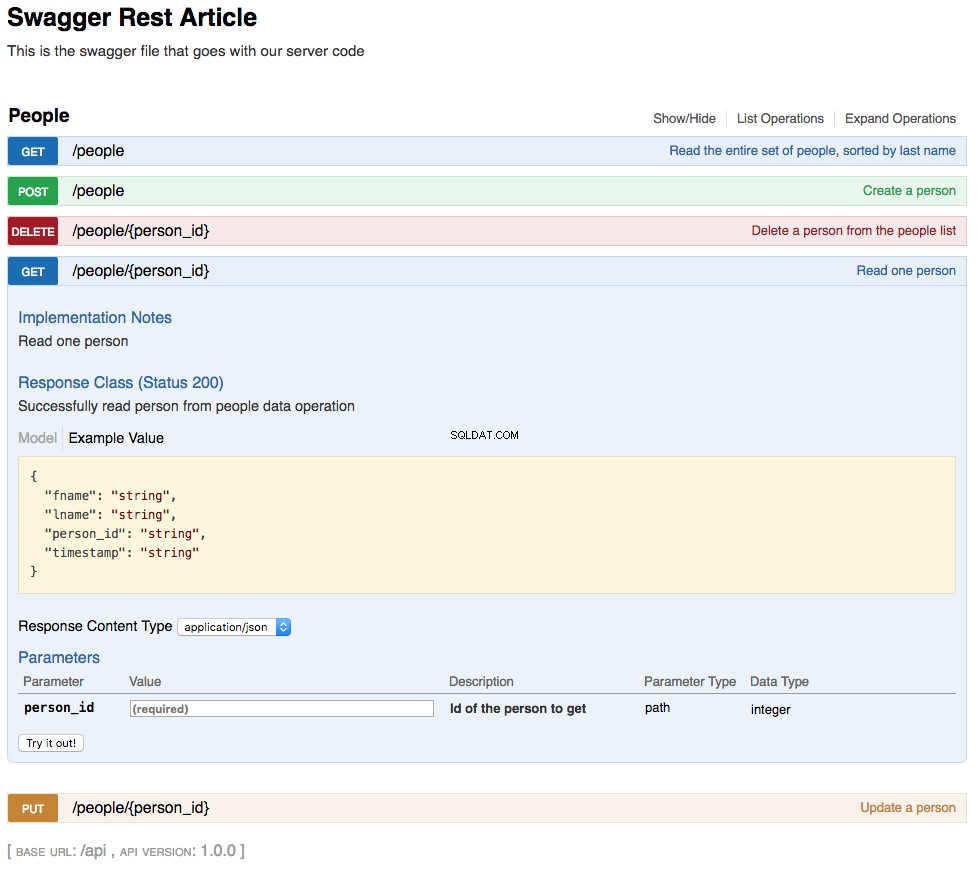
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
Závěr
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.