Loni v říjnu jsme vyzvali publikum našeho PyBites, aby vytvořilo webovou aplikaci pro lepší orientaci ve zdroji Daily Python Tip. V tomto článku se podělím o to, co jsem vybudoval a naučil se na cestě.
V tomto článku se dozvíte:
- Jak naklonovat repo projektu a nastavit aplikaci.
- Jak používat Twitter API prostřednictvím modulu Tweepy k načítání tweetů.
- Jak používat SQLAlchemy k ukládání a správě dat (tipy a hashtagy).
- Jak vytvořit jednoduchou webovou aplikaci pomocí Bottle, mikrowebového rámce podobného Flask.
- Jak používat rámec pytest k přidávání testů.
- Jak vedení Better Code Hub vedla k lépe udržovatelnému kódu.
Pokud chcete následovat a podrobně si přečíst kód (a případně přispět), doporučuji vám rozdělit repo. Začněme.
Nastavení projektu
Za prvé, Jmenné prostory jsou skvělý nápad dělejme tedy naši práci ve virtuálním prostředí. Pomocí Anacondy ji vytvořím takto:
$ virtualenv -p <path-to-python-to-use> ~/virtualenvs/pytip
Vytvořte produkční a testovací databázi v Postgres:
$ psql
psql (9.6.5, server 9.6.2)
Type "help" for help.
# create database pytip;
CREATE DATABASE
# create database pytip_test;
CREATE DATABASE
K připojení k databázi a Twitter API budeme potřebovat přihlašovací údaje (nejprve vytvořte novou aplikaci). Podle osvědčených postupů by konfigurace měla být uložena v prostředí, nikoli v kódu. Vložte následující proměnné env na konec ~/virtualenvs/pytip/bin/activate , skript, který se stará o aktivaci/deaktivaci vašeho virtuálního prostředí a ujistěte se, že aktualizujete proměnné pro vaše prostředí:
export DATABASE_URL='postgres://postgres:password@localhost:5432/pytip'
# twitter
export CONSUMER_KEY='xyz'
export CONSUMER_SECRET='xyz'
export ACCESS_TOKEN='xyz'
export ACCESS_SECRET='xyz'
# if deploying it set this to 'heroku'
export APP_LOCATION=local
Ve funkci deaktivace stejného skriptu jsem je zrušil, takže při deaktivaci (opuštění) virtuálního prostředí držíme věci mimo rozsah shellu:
unset DATABASE_URL
unset CONSUMER_KEY
unset CONSUMER_SECRET
unset ACCESS_TOKEN
unset ACCESS_SECRET
unset APP_LOCATION
Nyní je vhodná doba na aktivaci virtuálního prostředí:
$ source ~/virtualenvs/pytip/bin/activate
Naklonujte repo a s povoleným virtuálním prostředím nainstalujte požadavky:
$ git clone https://github.com/pybites/pytip && cd pytip
$ pip install -r requirements.txt
Dále importujeme kolekci tweetů pomocí:
$ python tasks/import_tweets.py
Poté ověřte, že byly vytvořeny tabulky a přidány tweety:
$ psql
\c pytip
pytip=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | hashtags | table | postgres
public | tips | table | postgres
(2 rows)
pytip=# select count(*) from tips;
count
-------
222
(1 row)
pytip=# select count(*) from hashtags;
count
-------
27
(1 row)
pytip=# \q
Nyní spusťte testy:
$ pytest
========================== test session starts ==========================
platform darwin -- Python 3.6.2, pytest-3.2.3, py-1.4.34, pluggy-0.4.0
rootdir: realpython/pytip, inifile:
collected 5 items
tests/test_tasks.py .
tests/test_tips.py ....
========================== 5 passed in 0.61 seconds ==========================
A nakonec spusťte aplikaci Bottle pomocí:
$ python app.py
Přejděte na https://localhost:8080 a voilà:měli byste vidět tipy seřazené sestupně podle popularity. Kliknutím na odkaz hashtag vlevo nebo pomocí vyhledávacího pole je můžete snadno filtrovat. Zde vidíme pandy tipy například:
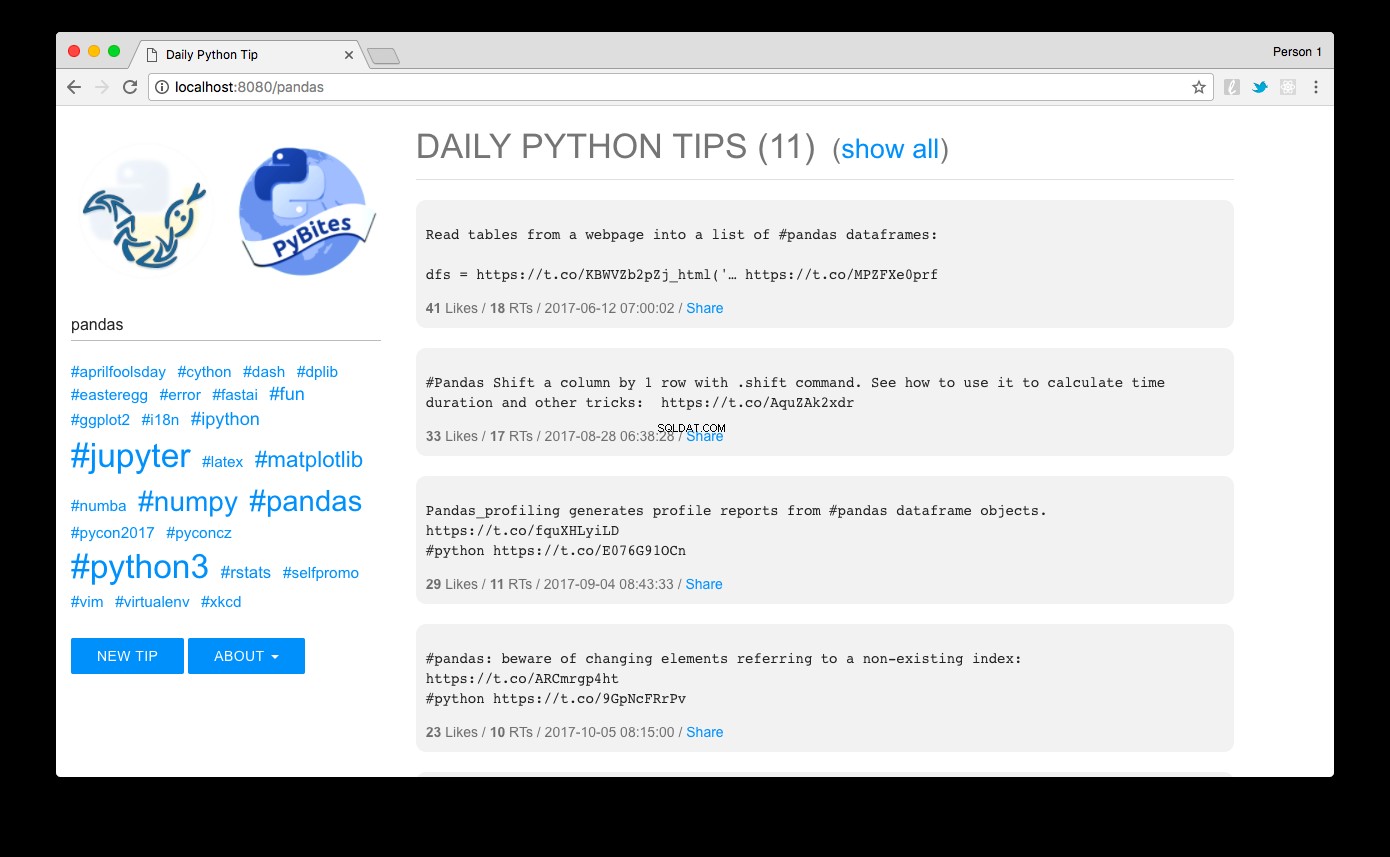
Návrh, který jsem vytvořil pomocí MUI – lehkého CSS frameworku, který se řídí pokyny Google Material Design.
Podrobnosti o implementaci
DB a SQLAlchemy
Použil jsem SQLAlchemy k propojení s DB, abych nemusel psát velké množství (nadbytečných) SQL.
Na stránce tips/models.py , definujeme naše modely - Hashtag a Tip - že SQLAlchemy se bude mapovat na tabulky DB:
from sqlalchemy import Column, Sequence, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Hashtag(Base):
__tablename__ = 'hashtags'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
name = Column(String(20))
count = Column(Integer)
def __repr__(self):
return "<Hashtag('%s', '%d')>" % (self.name, self.count)
class Tip(Base):
__tablename__ = 'tips'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
tweetid = Column(String(22))
text = Column(String(300))
created = Column(DateTime)
likes = Column(Integer)
retweets = Column(Integer)
def __repr__(self):
return "<Tip('%d', '%s')>" % (self.id, self.text)
V tips/db.py , importujeme tyto modely a nyní je snadné pracovat s DB, například pro rozhraní s Hashtag model:
def get_hashtags():
return session.query(Hashtag).order_by(Hashtag.name.asc()).all()
A:
def add_hashtags(hashtags_cnt):
for tag, count in hashtags_cnt.items():
session.add(Hashtag(name=tag, count=count))
session.commit()
Dotaz na Twitter API
Potřebujeme získat data z Twitteru. Za tímto účelem jsem vytvořil tasks/import_tweets.py . Zabalil jsem to do úkolů protože by se měl spouštět v denním cronjob, aby se hledaly nové tipy a aktualizovaly statistiky (počet lajků a retweetů) u stávajících tweetů. Pro jednoduchost nechávám tabulky denně znovu vytvářet. Pokud se začneme spoléhat na vztahy FK s jinými tabulkami, měli bychom rozhodně zvolit aktualizační příkazy před delete+add.
Tento skript jsme použili v nastavení projektu. Podívejme se, co to dělá podrobněji.
Nejprve vytvoříme objekt relace API, který předáme tweepy.Cursor. Tato funkce API je opravdu pěkná:zabývá se stránkováním, iterací přes časovou osu. Na množství tipů – 222 v době, kdy to píšu – je to opravdu rychlé. Hodnota exclude_replies=True a include_rts=False argumenty jsou vhodné, protože chceme pouze vlastní tweety Daily Python Tip (nikoli opětovné tweety).
Extrahování hashtagů z tipů vyžaduje velmi málo kódu.
Nejprve jsem definoval regulární výraz pro značku:
TAG = re.compile(r'#([a-z0-9]{3,})')
Potom jsem použil findall získat všechny značky.
Předal jsem je do collections.Counter, který vrací objekt podobný diktátu se značkami jako klíči a počítá jako hodnoty, seřazené v sestupném pořadí podle hodnot (nejběžnější). Vyloučil jsem příliš běžnou značku python, která by zkreslila výsledky.
def get_hashtag_counter(tips):
blob = ' '.join(t.text.lower() for t in tips)
cnt = Counter(TAG.findall(blob))
if EXCLUDE_PYTHON_HASHTAG:
cnt.pop('python', None)
return cnt
Nakonec import_* funkce v tasks/import_tweets.py proveďte skutečný import tweetů a hashtagů voláním add_* DB metody tipů adresář/balík.
Vytvořte jednoduchou webovou aplikaci pomocí Bottle
S touto předběžnou prací je vytvoření webové aplikace překvapivě snadné (nebo ne tak překvapivé, pokud jste dříve používali Flask).
Nejprve se seznamte s Bottle:
Bottle je rychlý, jednoduchý a lehký WSGI mikro webový rámec pro Python. Je distribuován jako modul s jedním souborem a nemá žádné jiné závislosti než Python Standard Library.
Pěkný. Výsledná webová aplikace obsahuje <30 LOC a lze ji nalézt v app.py.
Pro tuto jednoduchou aplikaci stačí jediná metoda s volitelným argumentem značky. Podobně jako u Flask je směrování řešeno dekorátory. Pokud je voláno s tagem, filtruje tipy na tag, jinak je zobrazí všechny. Dekorátor pohledu definuje šablonu, která se má použít. Stejně jako Flask (a Django) vracíme diktát pro použití v šabloně.
@route('/')
@route('/<tag>')
@view('index')
def index(tag=None):
tag = tag or request.query.get('tag') or None
tags = get_hashtags()
tips = get_tips(tag)
return {'search_tag': tag or '',
'tags': tags,
'tips': tips}
Podle dokumentace pro práci se statickými soubory přidáte tento úryvek nahoře po importech:
@route('/static/<filename:path>')
def send_static(filename):
return static_file(filename, root='static')
Nakonec se chceme ujistit, že na localhost běží pouze v režimu ladění, proto APP_LOCATION env proměnná, kterou jsme definovali v Project Setup:
if os.environ.get('APP_LOCATION') == 'heroku':
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))
else:
run(host='localhost', port=8080, debug=True, reloader=True)
Šablony lahví
Bottle přichází s rychlým, výkonným a snadno naučitelným vestavěným šablonovým enginem s názvem SimpleTemplate.
V podadresáři views jsem definoval header.tpl , index.tpl a footer.tpl . Pro cloud tagů jsem použil jednoduchý inline CSS, který zvětšil velikost tagu podle počtu, viz header.tpl :
% for tag in tags:
<a style="font-size: {{ tag.count/10 + 1 }}em;" href="/{{ tag.name }}">#{{ tag.name }}</a>
% end
V index.tpl projdeme tipy:
% for tip in tips:
<div class='tip'>
<pre>{{ !tip.text }}</pre>
<div class="mui--text-dark-secondary"><strong>{{ tip.likes }}</strong> Likes / <strong>{{ tip.retweets }}</strong> RTs / {{ tip.created }} / <a href="https://twitter.com/python_tip/status/{{ tip.tweetid }}" target="_blank">Share</a></div>
</div>
% end
Pokud znáte Flask a Jinja2, mělo by to vypadat velmi povědomě. Vkládání Pythonu je ještě snazší, s méně psaním — (% ... vs {% ... %} ).
Všechny css, obrázky (a JS, pokud bychom je použili) jdou do statické podsložky.
A to je vše k vytvoření základní webové aplikace s Bottle. Jakmile budete mít datovou vrstvu správně definovanou, je to docela jednoduché.
Přidat testy pomocí pytest
Nyní udělejme tento projekt o něco robustnějším přidáním několika testů. Testování DB vyžadovalo trochu více prozkoumání rámce pytest, ale nakonec jsem použil dekorátor pytest.fixture k nastavení a odstranění databáze s několika testovacími tweety.
Místo volání Twitter API jsem použil některá statická data poskytnutá v tweets.json .A místo použití živé databáze v tips/db.py , zkontroluji, zda je volajícím pytest (sys.argv[0] ). Pokud ano, používám testovací DB. Pravděpodobně to předělám, protože Bottle podporuje práci s konfiguračními soubory.
Testování části hashtag bylo snazší (test_get_hashtag_counter ), protože jsem mohl přidat nějaké hashtagy do víceřádkového řetězce. Nejsou potřeba žádná příslušenství.
Na kvalitě kódu záleží – Lepší centrum kódu
Better Code Hub vás provede psaním, dobře, lepší kód. Před napsáním testů získal projekt 7:
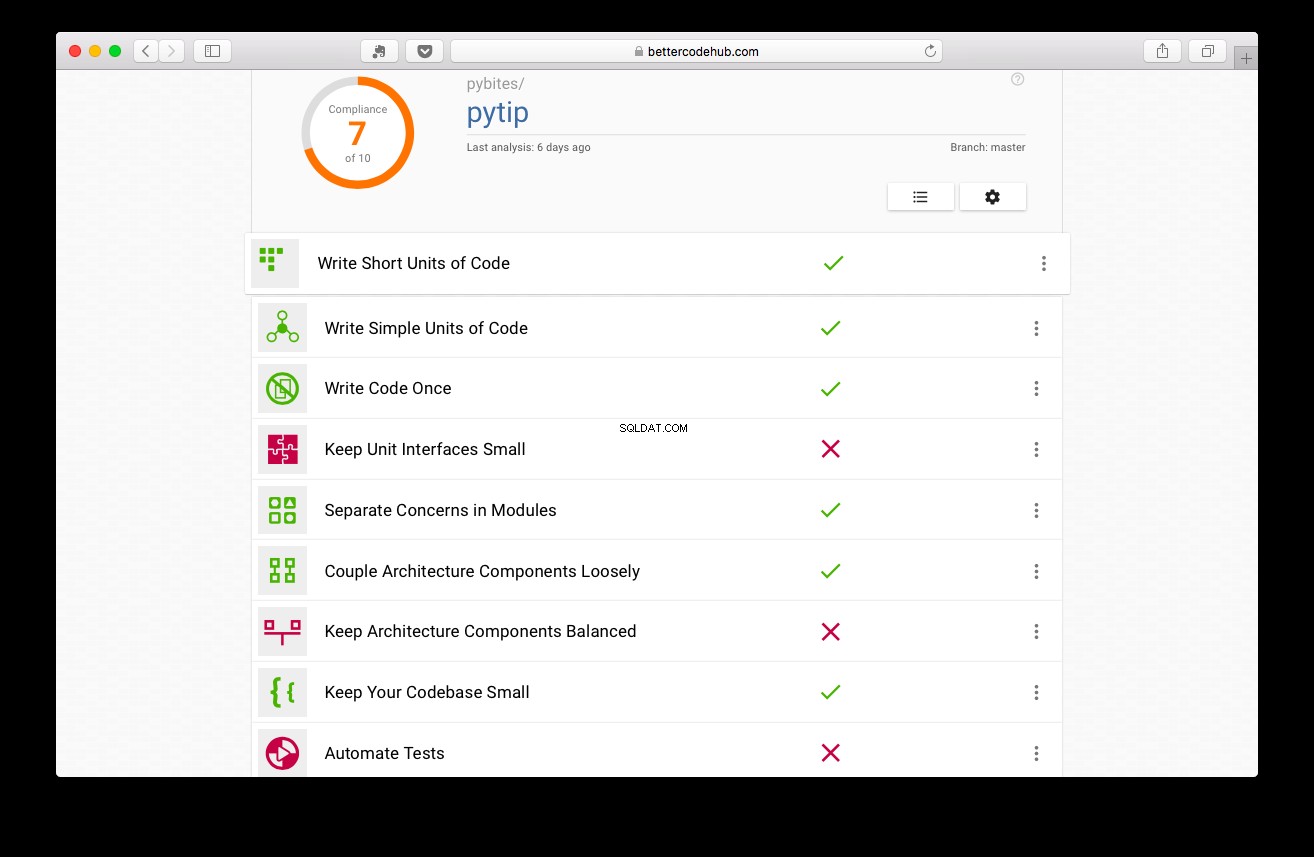
Není to špatné, ale můžeme to udělat lépe:
-
Narazil jsem na 9 tím, že jsem udělal modulárnější kód, vyjmul logiku DB z app.py (webová aplikace) a umístil ji do složky tipů/balíčku (refaktoringy 1 a 2)
-
Poté, co byly testy provedeny, projekt získal 10:
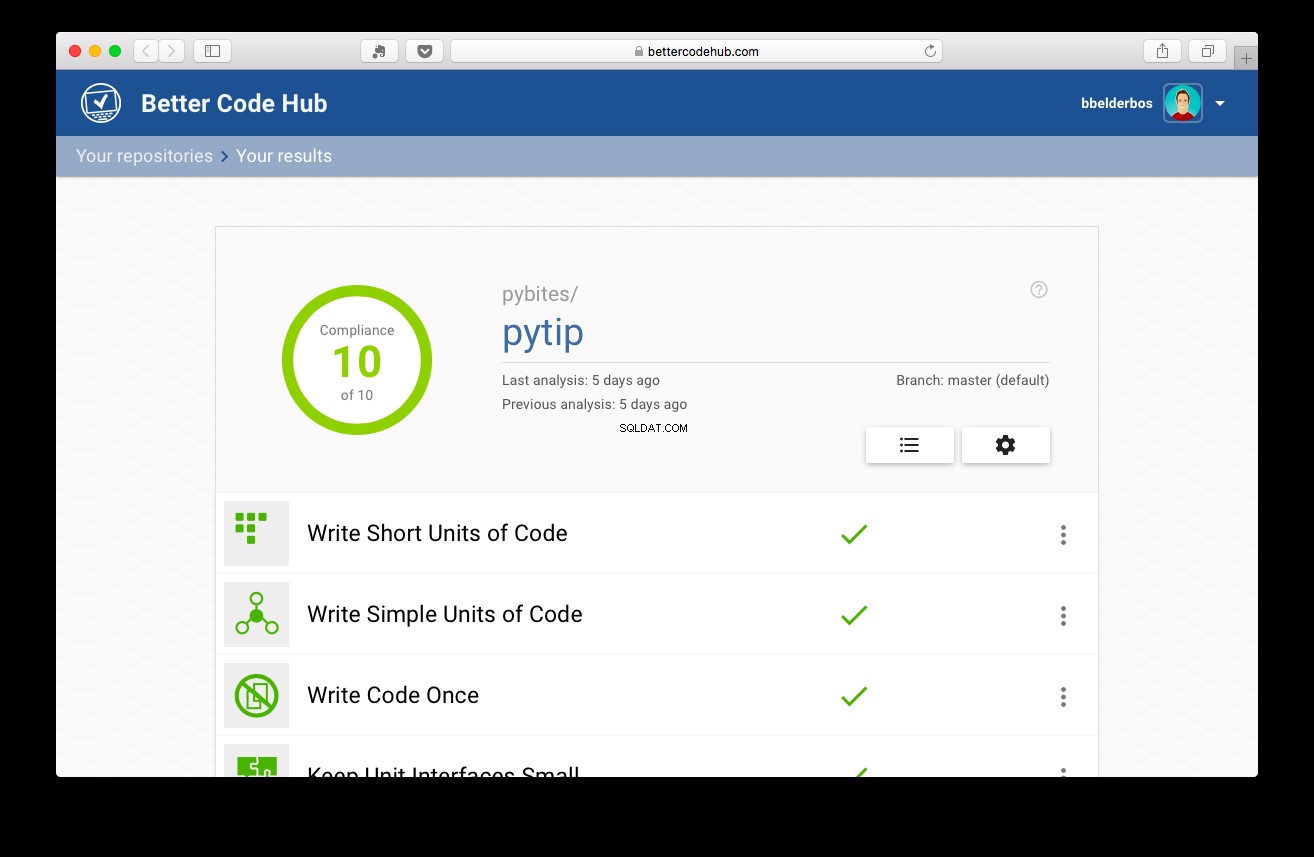
Závěr a poučení
Naše výzva ke kódu č. 40 nabídla několik osvědčených postupů:
- Vytvořil jsem užitečnou aplikaci, kterou lze rozšířit (chci přidat API).
- Použil jsem několik skvělých modulů, které stojí za to prozkoumat:Tweepy, SQLAlchemy a Bottle.
- Naučil jsem se více pytestů, protože jsem potřeboval přípravky pro testování interakce s DB.
- Především tím, že bylo nutné kód testovat, se aplikace stala modulárnější, což usnadnilo její údržbu. Better Code Hub byl v tomto procesu velkou pomocí.
- Aplikaci jsem nasadil do Heroku pomocí našeho podrobného průvodce.
Vyzýváme vás
Nejlepší způsob, jak se naučit a zlepšit své kódovací dovednosti, je cvičit. V PyBites jsme tento koncept upevnili organizováním výzev pro kód Python. Prohlédněte si naši rostoucí sbírku, rozvětvte repo a získejte kódování!
Pokud vytvoříte něco skvělého, dejte nám vědět tím, že zadáte požadavek na stažení vaší práce. Viděli jsme lidi, kteří se těmito výzvami skutečně protahovali, a my také.
Hodně štěstí při kódování!