Být odpovědný za výkon SQL Server může být skličující úkol. Existuje mnoho oblastí, které musíme sledovat a chápat. Očekává se také, že budeme schopni mít přehled o všech těchto metrikách a budeme neustále vědět, co se děje na našich serverech. Rád se ptám správců databází, co je první věc, která je napadne, když slyší frázi „tuning SQL Server“; ohromující odpověď, kterou dostávám, je „ladění dotazů“. Souhlasím s tím, že ladění dotazů je velmi důležité a je to nikdy nekončící úkol, kterému čelíme, protože pracovní zátěž se neustále mění.
Existuje však mnoho dalších aspektů, které je třeba vzít v úvahu při přemýšlení o výkonu SQL Server. Existuje mnoho nastavení na úrovni instance, operačního systému a databáze, které je třeba vyladit z výchozích hodnot. Být konzultantem mi umožňuje pracovat v mnoha různých oblastech podnikání a dostat se do kontaktu se všemi druhy problémů s výkonem. Při práci s novým klientem se snažím vždy provést zdravotní audit serveru, abych věděl, s čím mám co do činění. Při provádění těchto auditů byla jednou z věcí, které jsem opakovaně zjistil, nadměrné latence čtení a zápisu na discích, kde jsou uložena data a soubory protokolu SQL Server.
Ltence čtení/zápisu
Chcete-li zobrazit latence disku na serveru SQL Server, můžete rychle a snadno zadat dotaz na DMV sys.dm_io_virtual_file_stats . Tento DMV přijímá dva parametry:database_id a id_souboru . Úžasné je, že můžete předat NULL jako obě hodnoty a vrátí latence pro všechny soubory pro všechny databáze. Mezi výstupní sloupce patří:
- database_id
- id_souboru
- sample_ms
- počet_přečtení
- num_of_bytes_read
- io_stall_read_ms
- počet_zápisů
- num_of_bytes_written
- io_stall_write_ms
- io_stall
- size_on_disk_bytes
- file_handle
Jak můžete vidět ze seznamu sloupců, tento DMV načítá opravdu užitečné informace, stačí však spustit SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); moc nepomůže, pokud si nezapamatujete databázová_id a nedokážete si v hlavě spočítat.
Když se dotazuji na statistiky souborů, používám dotaz z blogového příspěvku Paula Randala „Jak zkoumat latence IO subsystému ze serveru SQL Server“. Tento skript usnadňuje čtení názvů sloupců, zahrnuje jednotku, na které se soubor nachází, název databáze a cestu k souboru.
Dotazováním tohoto DMV můžete snadno zjistit, kde jsou I/O aktivní místa pro vaše soubory. Můžete vidět, kde jsou nejvyšší latence zápisu a čtení a které databáze jsou na vině. Když to budete vědět, umožní vám to začít hledat možnosti ladění pro tyto konkrétní databáze. To může zahrnovat ladění indexu, kontrolu, zda je fond vyrovnávacích pamětí pod tlakem paměti, případné přesunutí databáze do rychlejší části I/O subsystému nebo případně rozdělení databáze a rozložení skupin souborů mezi další LUN.
Takže spustíte dotaz a vrátí spoustu hodnot v ms pro latenci – které hodnoty jsou v pořádku a které jsou špatné?
Jaké hodnoty jsou dobré nebo špatné?
Pokud se zeptáte SQLskills, řekneme vám něco ve smyslu:
- Výborně:<1 ms
- Velmi dobré:<5 ms
- Dobrá:5–10 ms
- Špatná:10–20 ms
- Špatné:20–100 ms
- Opravdu špatné:100 – 500 ms
- OMG!:> 500 ms
Pokud provedete vyhledávání na Bingu, najdete články od společnosti Microsoft s doporučeními podobnými:
- Dobrá:<10 ms
- Dobře:10–20 ms
- Špatné:20–50 ms
- Vážně špatné:> 50 ms
Jak můžete vidět, existují určité mírné odchylky v číslech, ale konsensus je, že cokoli nad 20 ms může být považováno za problematické. S tím, co bylo řečeno, vaše průměrná latence zápisu může být 20 ms, což je pro vaši organizaci 100% přijatelné a to je v pořádku. Potřebujete znát obecné I/O latence pro váš systém, abyste, když se věci zhorší, věděli, co je normální.
Moje latence čtení/zápisu jsou špatné, co mám dělat?
Pokud zjistíte, že latence čtení a zápisu jsou na vašem serveru špatné, existuje několik míst, kde můžete začít hledat problémy. Toto není úplný seznam, ale určitý návod, kde začít.
- Analyzujte svou pracovní zátěž. Je vaše strategie indexování správná? Neexistence správných indexů povede k načtení mnohem více dat z disku. Skenuje místo hledání.
- Jsou vaše statistiky aktuální? Špatné statistiky mohou způsobit špatné volby pro prováděcí plány.
- Máte problémy se sledováním parametrů, které způsobují špatné plány provádění?
- Je fond vyrovnávacích pamětí pod tlakem paměti, například kvůli přeplněné mezipaměti plánu?
- Nějaké problémy se sítí? Funguje vaše tkanina SAN správně? Nechte svého technika úložiště ověřit cestu a síť.
- Přesuňte aktivní body do různých úložných polí. V některých případech to může být jedna databáze nebo jen několik databází, které způsobují všechny problémy. Nejlepším logickým řešením může být jejich izolace na jinou sadu disků nebo rychlejší špičkové disky, jako jsou SSD.
- Můžete rozdělit databázi a přesunout problematické tabulky na jiný disk a rozložit tak zátěž?
Statistika čekání
Stejně jako sledování statistik souborů, sledování statistik čekání vám může hodně říct o úzkých místech ve vašem prostředí. Máme štěstí, že máme další úžasný DMV (sys.dm_os_wait_stats ), že se můžeme dotázat, že vytáhne všechny dostupné informace o čekání shromážděné od posledního restartu nebo od posledního vynulování čekání; existují také čekání související s výkonem disku. Tento DMV vrátí důležité informace včetně:
- wait_type
- waiting_task_count
- wait_time_ms
- max_wait_time_ms
- signal_wait_time_ms
Dotaz na tento DMV na mém počítači SQL Server 2014 vrátil 771 typů čekání. SQL Server vždy na něco čeká, ale existuje spousta čekání, se kterými bychom si neměli dělat starosti. Z tohoto důvodu používám další dotaz od Paula Randala; jeho blogový příspěvek „Čekejte statistiky, nebo mi prosím řekněte, kde to bolí“ má vynikající scénář, který vylučuje spoustu čekání, o která se ve skutečnosti nezajímáme. Paul také vyjmenovává mnoho běžných problematických čekání a nabízí návod pro běžná čekání.
Proč jsou statistiky čekání důležité?
Monitorování dlouhých čekacích dob na určité události vám řekne, kdy se vyskytnou problémy. Potřebujete základní linii, abyste věděli, co je normální a kdy věci překročí práh nebo úroveň bolesti. Pokud máte opravdu vysokou hodnotu PAGEIOLATCH_XX pak víte, že SQL Server musí čekat na načtení datové stránky z disku. Může to být disk, paměť, změna pracovní zátěže nebo řada dalších problémů.
Nedávný klient, se kterým jsem pracoval, zaznamenal velmi neobvyklé chování. Když jsem se připojil k databázovému serveru a mohl jsem pozorovat server pod pracovní zátěží, okamžitě jsem začal kontrolovat statistiky souborů, statistiky čekání, využití paměti, využití databáze tempdb atd. Jedna věc, která okamžitě vynikla, byla WRITELOG je nejčastějším čekáním. Vím, že toto čekání souvisí s vyprázdněním logu na disk a připomnělo mi to Paulovu sérii o Trimming the Transaction Log Fat. Vysoká WRITELOG čekání lze obvykle identifikovat podle vysoké latence zápisu do souboru protokolu transakcí. Takže jsem pak použil svůj skript pro statistiky souborů ke kontrole latence čtení a zápisu na disk. Pak jsem viděl vysokou latenci zápisu v datovém souboru, ale ne v mém souboru protokolu. Při pohledu na WRITELOG bylo to vysoké čekání, ale doba čekání v ms byla extrémně nízká. Nicméně něco z druhého příspěvku Paulovy série mi stále leželo v hlavě. Měl bych se podívat na nastavení automatického růstu pro databázi, abych vyloučil „Smrt tisíci řezy“. Při pohledu na databázové vlastnosti databáze jsem viděl, že datový soubor byl nastaven na automatický růst o 1 MB a protokol transakcí nastaven na automatický růst o 10 %. Oba soubory měly téměř 0 nevyužitého místa. Sdílel jsem s klientem, co jsem našel a jak to zabíjelo jeho výkon. Rychle jsme provedli příslušnou změnu a testování pokračovalo, mimochodem mnohem lépe. Bohužel to není jediný případ, kdy jsem se setkal s tímto konkrétním problémem. Jindy měla databáze velikost 66 GB a narostla tam o 1 MB.
Zachycení dat
Mnoho datových profesionálů vytvořilo procesy pro pravidelné zachycování statistik souborů a čekání na analýzu. Vzhledem k tomu, že statistiky čekání jsou kumulativní, měli byste je zachytit a porovnat delty mezi různými denními dobami nebo před a po spuštění určitých procesů. Není to příliš složité a existuje mnoho blogových příspěvků, kde lidé sdílejí, jak toho dosáhli. Důležitou součástí je měření těchto dat, abyste je mohli sledovat. Jak dnes víte, že je na vašem databázovém serveru situace lepší nebo horší, pokud neznáte data ze včerejška?
Jak může SQL Sentry pomoci?
Jsem rád, že ses zeptal! SQL Sentry Performance Advisor přináší latenci a čeká vepředu a uprostřed řídicího panelu. Jakékoli anomálie jsou snadno rozpoznatelné; můžete přepnout do historického režimu a vidět předchozí trend a porovnat jej také s předchozími obdobími. To se může ukázat jako neocenitelné při analýze toho „co se stalo? momenty. Každému se ozvalo:"Včera kolem 15:00 se zdálo, že systém zamrzl, můžete nám říct, co se stalo?" Um, jistě, vytáhnu Profiler a vrátím se v čase. Pokud máte monitorovací nástroj, jako je Performance Advisor, budete mít tyto historické informace na dosah ruky.
Kromě tabulek a grafů na řídicím panelu máte možnost používat vestavěná upozornění na podmínky, jako jsou vysoké čekání na disku, vysoké počty VLF, vysoký CPU, nízká očekávaná životnost stránky a mnoho dalších. Máte také možnost vytvořit si své vlastní podmínky a můžete se učit z příkladů na webu SQL Sentry nebo prostřednictvím Condition Exchange (Aaron Bertrand o tom napsal blog). Strany upozornění jsem se dotkl ve svém posledním článku o SQL Server Agent Alerts.
Na kartě Místo na disku nástroje Performance Advisor je velmi snadné vidět věci, jako je nastavení automatického růstu a vysoké počty VLF. Měli byste to vědět, ale pokud ne, automatický růst o 1 MB nebo 10 % není nejlepší nastavení. Pokud tyto hodnoty uvidíte (Poradce pro výkon je zvýrazní), můžete si je rychle poznamenat a naplánovat čas na provedení správných úprav. Líbí se mi, jak zobrazuje také celkové VLF; příliš mnoho VLF může být velmi problematické. Měli byste si přečíst příspěvek Kimberly „VLF protokolu transakcí – příliš mnoho nebo příliš málo?“ pokud jste to ještě neudělali.
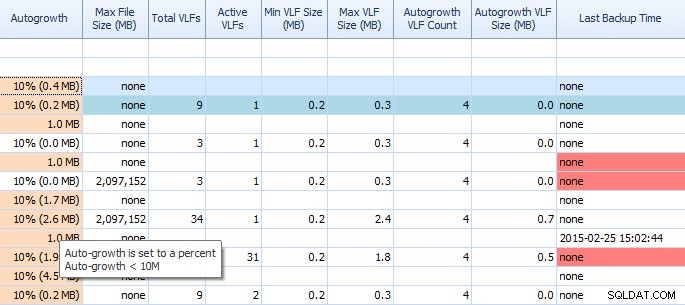 Částečná mřížka na kartě Místo na disku Performance Advisor
Částečná mřížka na kartě Místo na disku Performance Advisor
Dalším způsobem, jak může Performance Advisor pomoci, je jeho patentovaný modul Disk Activity. Zde můžete vidět, že tempdb na F:zažívá značnou latenci zápisu; poznáte to podle tlustých červených čar pod grafikou disku. Můžete si také všimnout, že F:je jediné písmeno jednotky, jejíž disk je znázorněn červeně; toto je vizuální narážka, že disk má špatně zarovnaný oddíl, což může přispívat k problémům s I/O.
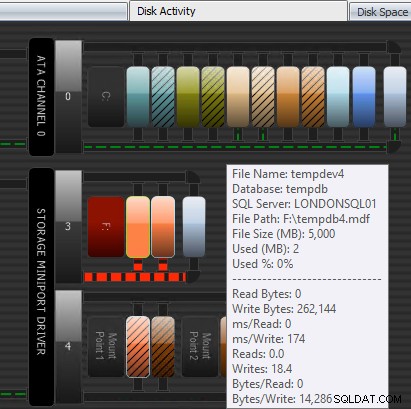 Modul Performance Advisor Disk Activity
Modul Performance Advisor Disk Activity
A tyto informace můžete porovnat v níže uvedených mřížkách – problémy jsou v mřížkách také zvýrazněny a podívejte se na ms/Write sloupec:
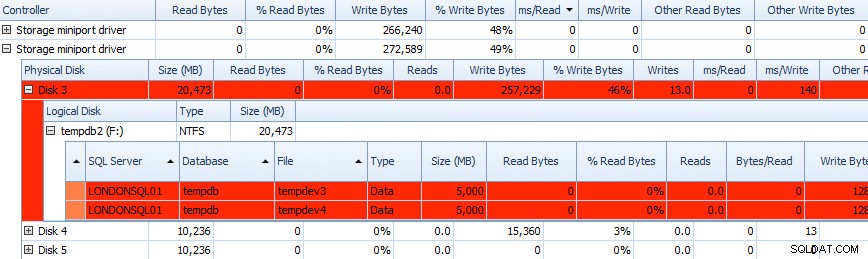 Částečná mřížka dat aktivity disku Performance Advisor
Částečná mřížka dat aktivity disku Performance Advisor
Na tyto informace se můžete podívat i zpětně; pokud si někdo včera odpoledne nebo minulé úterý stěžuje na vnímané úzké místo disku, můžete se jednoduše vrátit zpět pomocí nástroje pro výběr data na panelu nástrojů a zobrazit průměrnou propustnost a latenci pro jakýkoli rozsah. Další informace o modulu Disk Activity naleznete v Uživatelské příručce.
Performance Advisor má také mnoho vestavěných sestav v kategoriích Výkon, Blokování, Nejlepší SQL, Místo na disku/souborech a Zablokování. Obrázek níže ukazuje, jak se dostat k sestavám Disk/Souborový prostor. Mít přehledy vzdálené jen pár kliknutí myší je velmi cenné, abyste se mohli okamžitě ponořit a zobrazit, co se děje (nebo dělo) na vašem serveru.
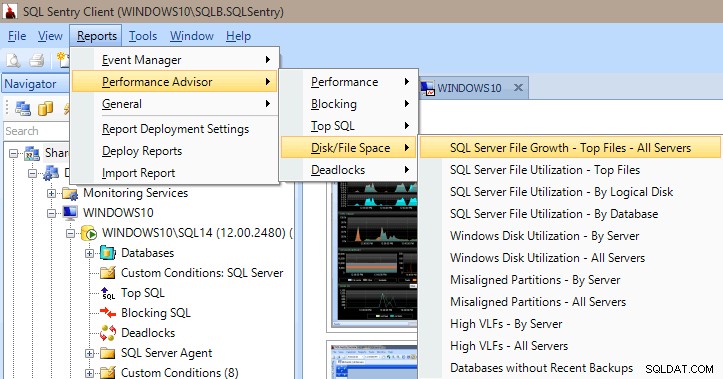 Zprávy Poradce pro výkon
Zprávy Poradce pro výkon
Shrnutí
Důležitým poznatkem z tohoto příspěvku je znát své metriky výkonu. Mezi odborníky na data je běžné prohlášení, že disk je naše úzké místo číslo 1. Znalost statistik souborů vašeho serveru vám pomůže porozumět bolestivým bodům na vašem serveru. Ve spojení se statistikami souborů jsou vaše statistiky čekání také skvělým místem, kam se můžete podívat. Mnoho lidí, včetně mě, tam začíná. Nástroj, jako je SQL Sentry Performance Advisor, vám může výrazně pomoci při odstraňování problémů a hledání problémů s výkonem dříve, než se stanou příliš problematickými; pokud však takový nástroj nemáte, seznamte se s sys.dm_os_wait_stats a sys.dm_io_virtual_file_stats vám dobře poslouží k zahájení ladění serveru.